
常有朋友问我:“想转行学数据科学,但没基础,报个几千块的培训班靠谱吗?” 这个问题其实很难回答,毕竟我没上过那些班,不能妄下定论。
对于初学者来说,想系统学习数据科学知识,挑战确实不少。市面上书籍、资料眼花缭乱,而更棘手的是,这个领域知识迭代速度极快。可能一年前别人用某个模型做出的成果还能发核心期刊,如今再用同样的方法,审稿人可能直接拒稿——不是你的错,只是更好的模型已经出现了。你刚学会的技术,可能已经落伍了。
那么问题来了:有没有一种学习方式,既省钱,又能紧跟技术前沿,还能随时更新?
听起来很贪心,像是骗子的承诺。但还真有这么一个被很多人忽视的宝藏:一套完全免费、且持续更新的系统化课程。它不在常见的慕课平台上,而是藏身于一个数据科学竞赛网站的角落里。这个网站叫 Kaggle,这套课程就是 Kaggle Courses。人们总觉得参加竞赛需要高深的知识,从而忽略了它作为学习平台的价值。

我第一次发现这套课程是在2018年4月,当时它还叫“Kaggle Learn”。及时做笔记的习惯,让我能准确追溯这个时间点。那时的课程门类很少,只有6门核心课。
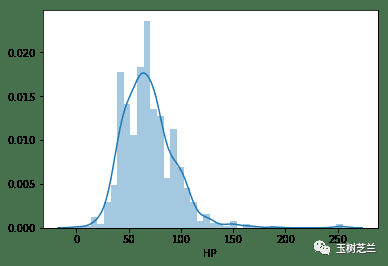
即便如此,它在当时就已显露出两大特色:完全免费,以及利用Jupyter Notebook的互动实例进行教学。以数据可视化部分为例,当时主推的工具是Seaborn。如今Seaborn教程随处可见,但在2018年初,很多教程还在用更基础的matplotlib,绘图相对繁琐。Seaborn能用极简的语句生成出版级质量的图表,让人眼前一亮。
例如,一个简单的变量分布直方图:
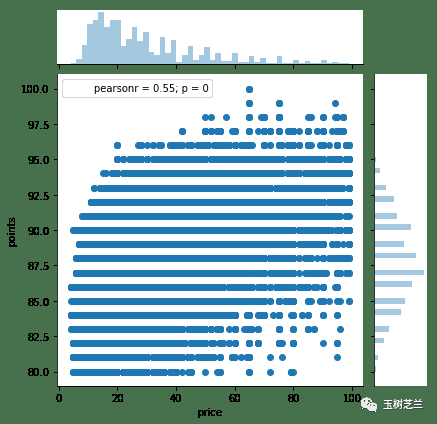
或者同时展示两个变量分布及其相关性的联合图:
这些图用Seaborn都能轻松实现。更厉害的是,当时的课程已不仅限于Seaborn,还包含了Plotly,用于制作交互式图表,比如下面这种可以拖拽旋转观察的三维图:
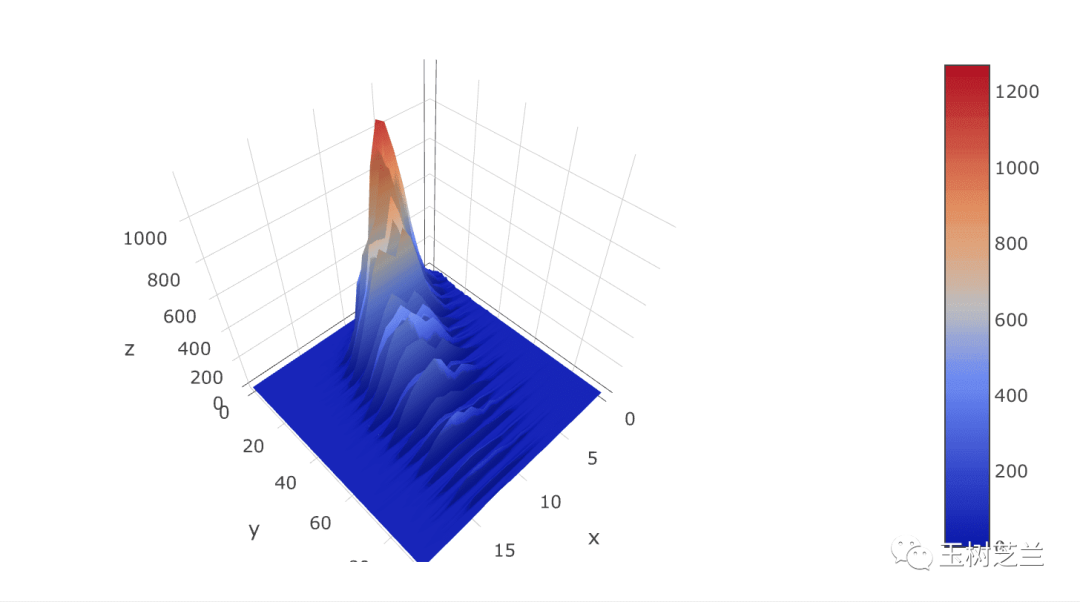
当初因为课程不多,我并未深入跟进,但学习进度至今仍保留在Kaggle系统中。

焕然一新的课程体系
俗话说“士别三日,当刮目相看”。前段时间,我为了给学生找一个免费的GPU云环境上机器学习课,再次打开了Kaggle。这才发现,昔日的“Kaggle Learn”已大幅扩容,成为了网站内一个独立的“Courses”板块,课程列表丰富了许多。
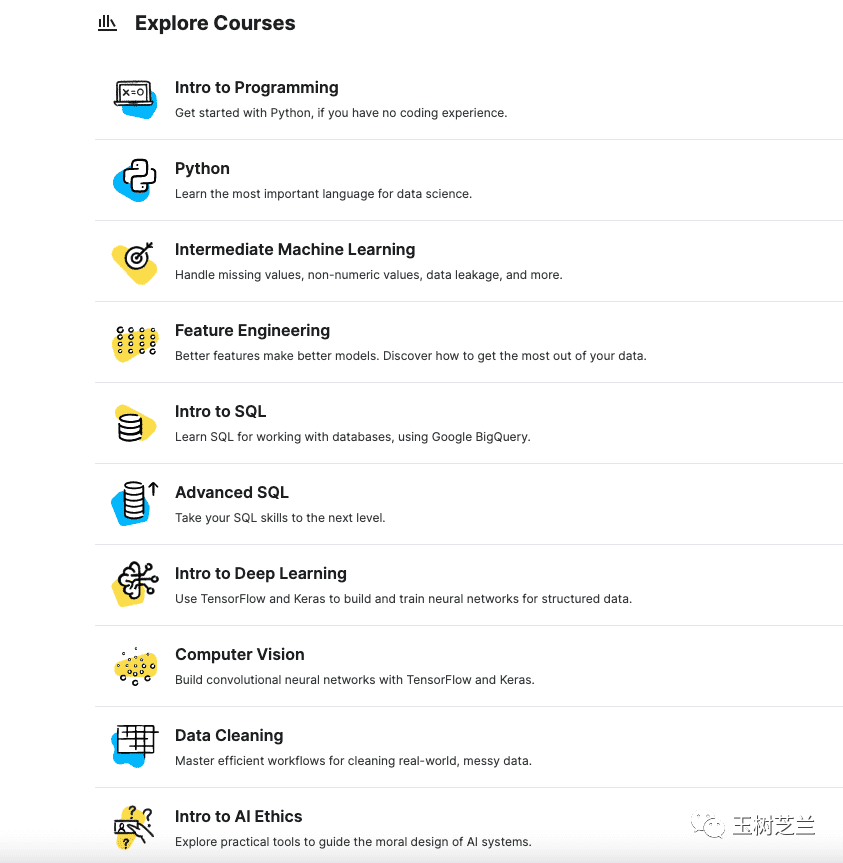
从这张不完全的列表就能看出,课程主题覆盖非常广,包括:
- 编程入门(针对零基础)
- Python (数据科学核心语言)
- 机器学习(初、中级)
- 特征工程
- SQL(初、高级,使用Google BigQuery)
- 深度学习与计算机视觉
- 数据清洗
- AI伦理
- ……
以Pandas课程为例:看教学如何设计
我们以Python数据操作库Pandas的教程为例,看看Kaggle课程的设计有多贴心。
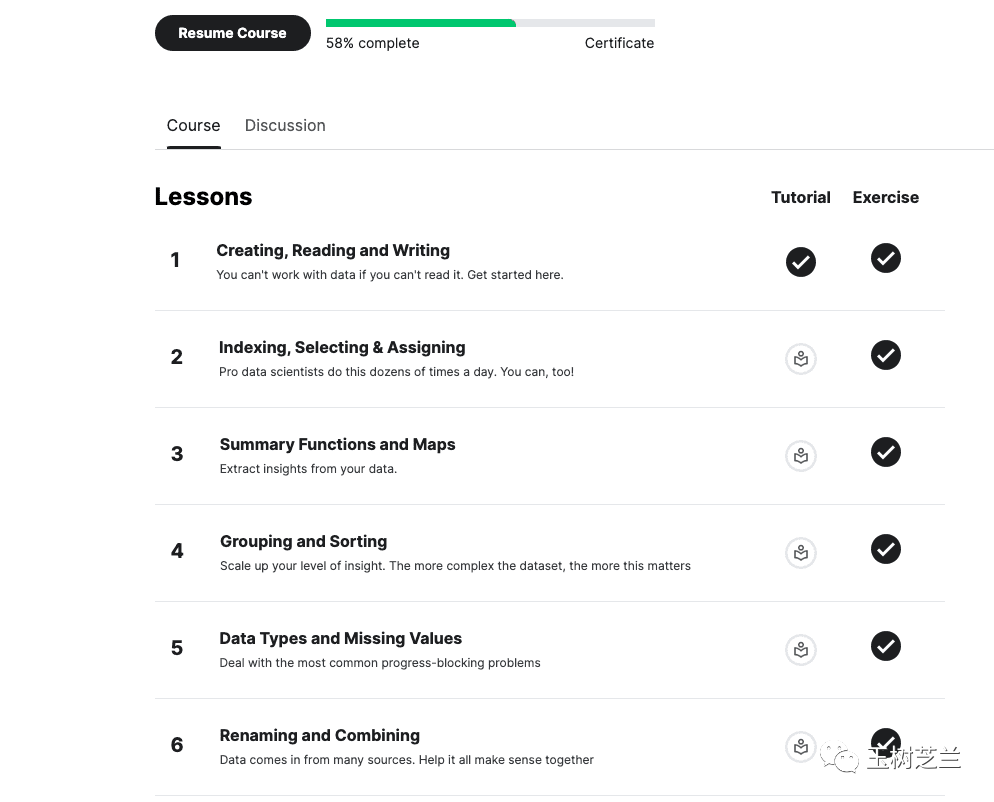
它将Pandas这个庞大的主题拆解成6个循序渐进的模块:
- 创建、读取和写入
- 索引、选择和赋值
- 汇总函数与映射
- 分组和排序
- 数据类型与缺失值处理
- 重命名与合并
这种设计避免了初学者一次性面对海量概念时的慌乱,遵循了“逐步迭代、高水平重复”的有效学习原则。每个模块都分为“教程”和“练习”两部分。
教程部分图文并茂,配有代码和即时运行结果,讲解清晰。
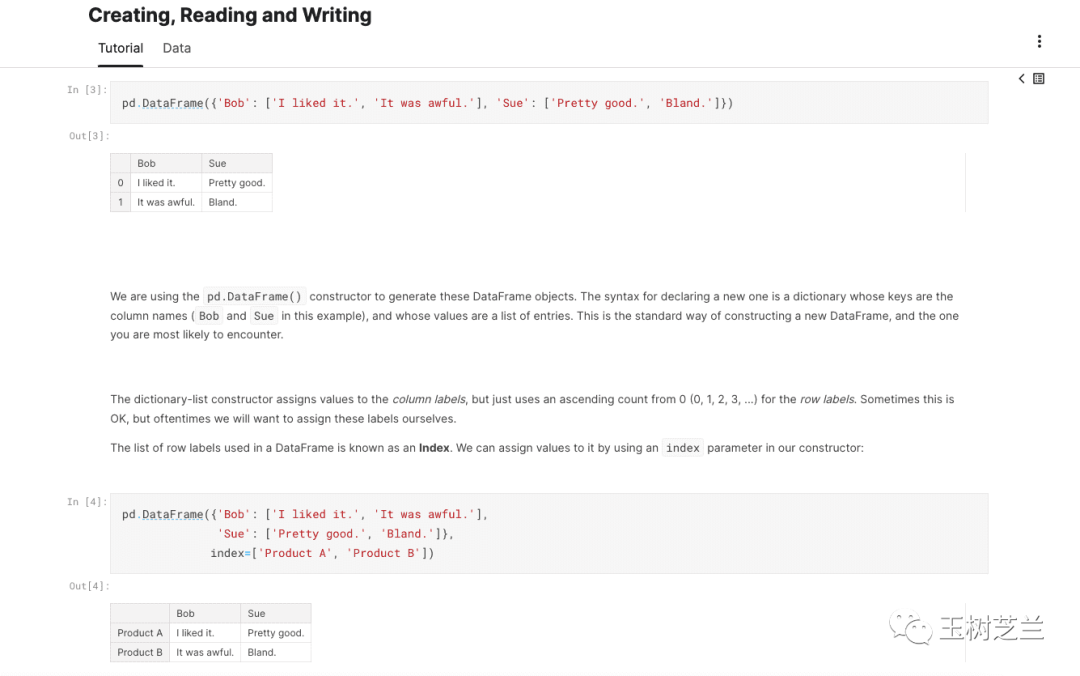
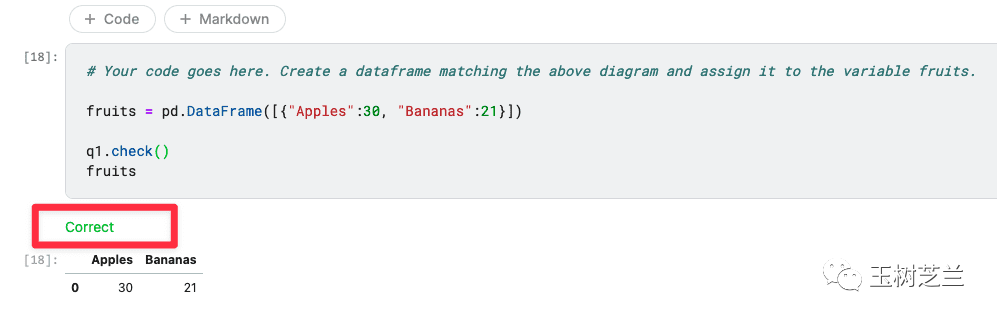
练习部分则更有趣。Kaggle使用了一个叫learntools的包,使得平台能提供自动化的即时反馈。它会检查你的代码,给出提示甚至判定对错。
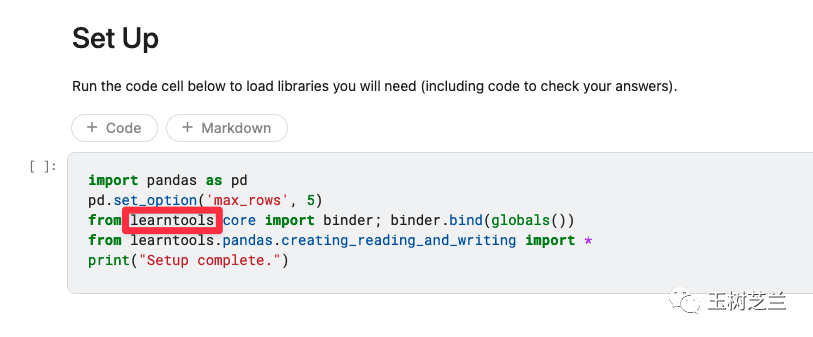
代码写对了,你会得到一个愉快的“Correct”提示。
如果写错了,它会明确指出问题所在,而不是让你对着报错信息瞎猜。
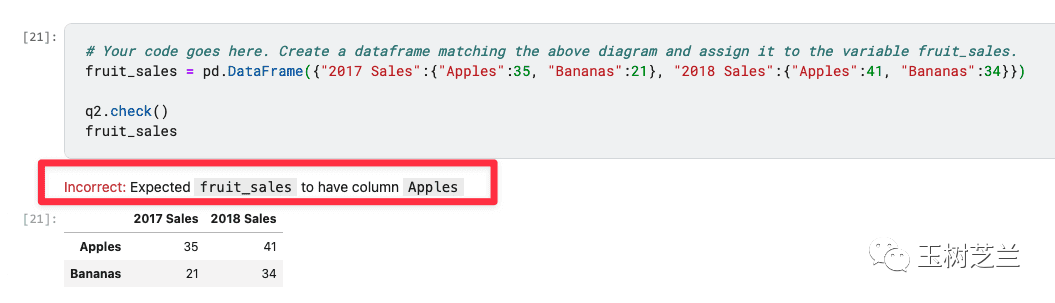
对于初学者,这种即时、明确的反馈极其宝贵。它能让你快速定位错误方向,避免在无效尝试中耗尽热情,真正告别“从入门到放弃”。即便你的答案正确,也可以查看官方提供的参考解法,对比不同实现方式的优劣,这也是一个重要的学习提升过程。
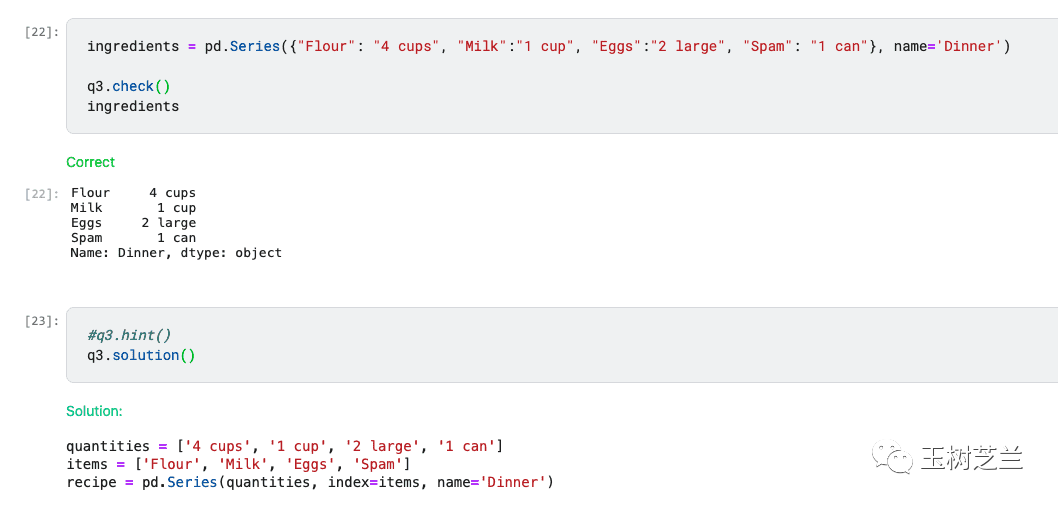
我曾经在探讨在线教育的文章中提过,反馈是慕课教学中最珍贵的一环。讲义视频可以复制,但个性化反馈成本高昂。而在编程学习上,利用自动化技术提供丰富反馈,恰恰是数据科学和编程类课程的巨大优势。
其他值得关注的特色课程
除了核心的Python和Pandas,Kaggle Courses还有很多亮点。篇幅所限,我挑三个说说:数据可视化、时间序列和AI伦理。
1. 数据可视化
Seaborn依然是教学主力,但内容比当年更细致、图表类型更丰富。
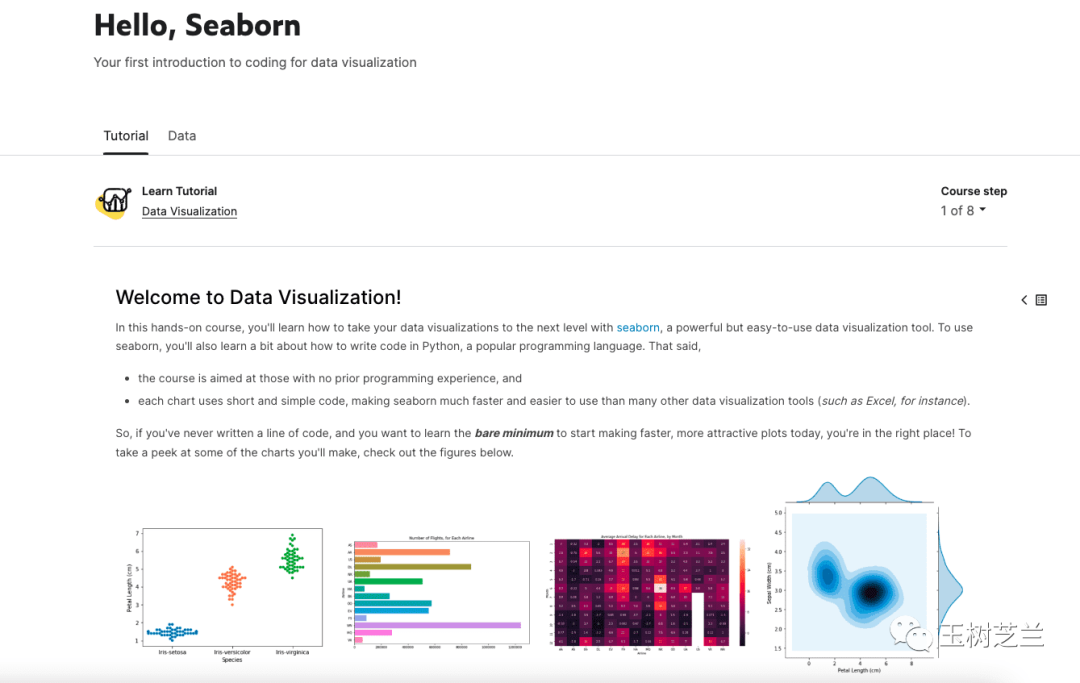
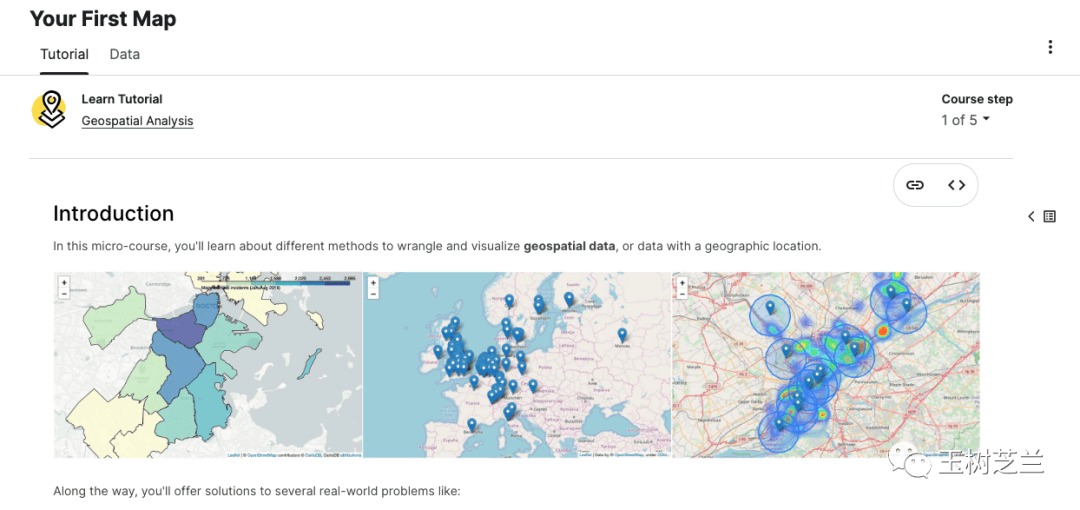
除了Seaborn和Plotly,还新增了“地理空间分析”课程。用几行代码就能将数据叠加到地图上,制作出信息一目了然的地图。
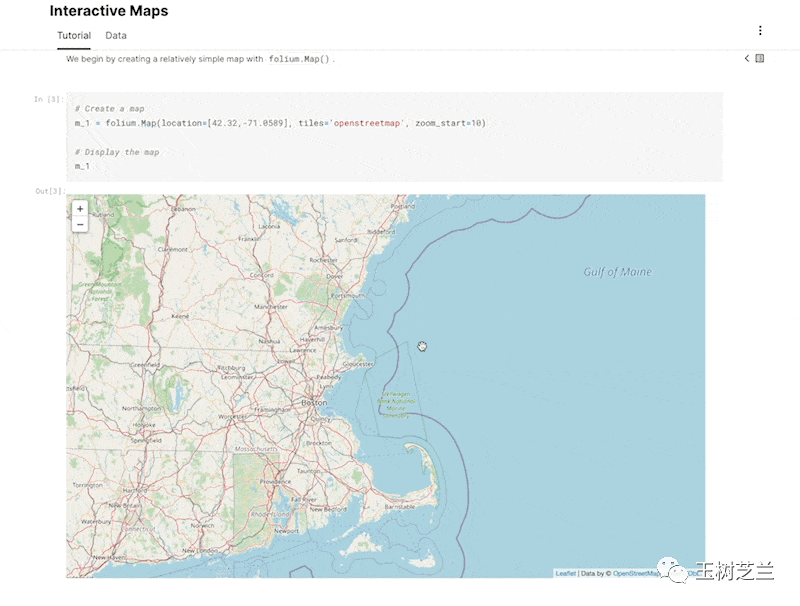
你甚至可以制作交互式地图,让读者自行缩放、探索。
2. 时间序列分析
处理时间序列数据(如销售记录、舆情指数)是常见需求。现在有了更成熟的工具包,可以更轻松地完成清洗、分析和预测。
例如,情感随时间变化的趋势可以这样可视化:
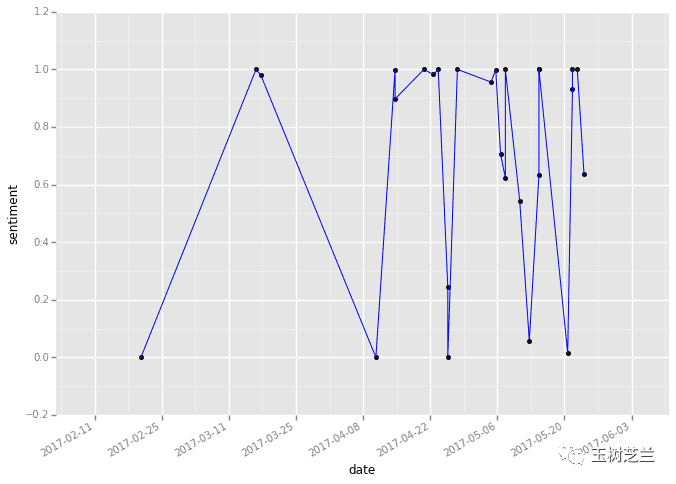
进行时间序列预测,无论是用传统统计方法还是机器学习模型,都变得更加方便。课程中有一个预测流感就诊人数的案例:
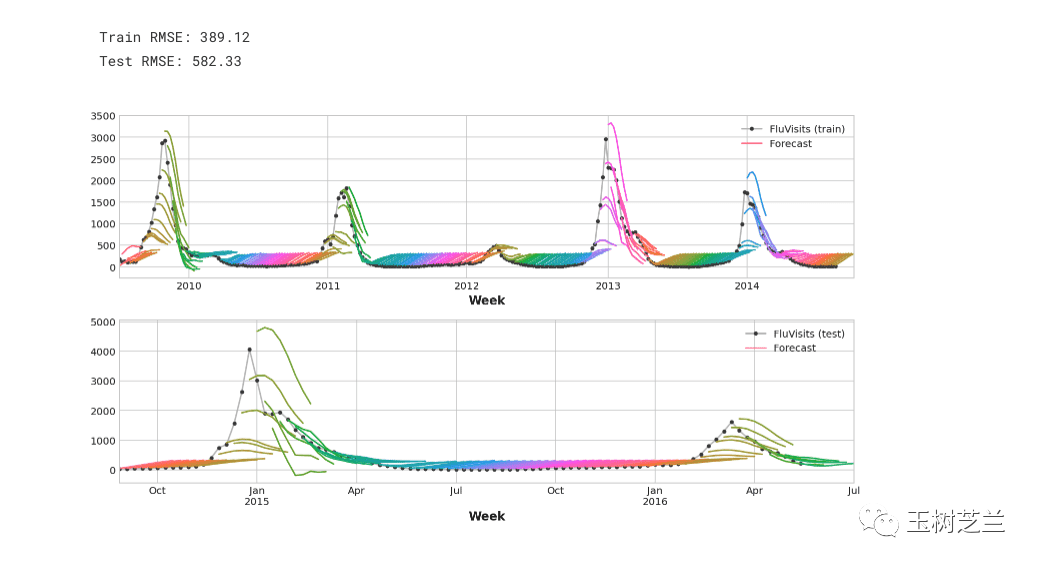
你可能觉得这样的建模、预测、可视化需要几百行代码。但实际上,核心代码非常简洁:

所有的步骤都有配套讲解,带你一步步理解原理并动手实践。学完后,你就能在练习区独立完成类似任务。

3. AI伦理
这是最让我惊喜的部分。近年来,AI的偏见、歧视等问题日益受到关注。简单说,如果放任AI“自由发展”,我们很快会尝到恶果——人们可能因为种族、性别、相貌等因素受到算法的不公对待。
机器学习模型本身没有善恶,但它由人塑造并放大了数据中的模式。对数据科学从业者而言,学习AI伦理就像司机必须学习交规。只学技术不讲规则,无异于手握危险武器的扳机。
Kaggle的“初心”:构建生态闭环
如此详细地介绍这套课程,不仅因为它免费、提供证书,更因为它代表了一种可贵的分享精神。

我一度疑惑:研发课程、编写练习、维护更新都需要成本,Kaggle做这种“赔本买卖”图什么?更何况,它还为所有用户提供免费的GPU算力和海量开放数据集,这些都是真金白银的投入。
后来我想明白了。Kaggle这些看似“傻气”的举动,其实是在构建一个健康的生态系统闭环。作为一个数据科学竞赛平台,Kaggle需要数据、算力、赛题,但最需要的是人,是源源不断的高质量参与者。不是每个访客都具备扎实的基础,但他们中蕴藏着巨大潜力。
打造一套精品课程固然耗费成本,但如果它能帮助初学者快速上手,那么整个社区的参与者水平就会提升,竞赛产出的结果会更精彩,平台的活跃度和价值也随之增长。这是一种着眼于长期生态繁荣的智慧。
小结
想通这一点后,我更愿意把Kaggle Courses推荐给所有想入门数据科学的朋友。它是经过大量初学者实践、反馈和迭代的产物,质量更有保障。
希望这个推荐,能让你在探索数据科学世界的路上,少走弯路,多些信心和成就感。如果你还知道其他优质的免费学习资源,欢迎在云栈社区这样的技术论坛与大家分享交流。
 发表于 2026-2-12 12:22:13
|
查看: 283|
回复: 0
发表于 2026-2-12 12:22:13
|
查看: 283|
回复: 0
