
近期,阿里云的通义千问(Qwen)家族迭代动作频频。继面向开发者推出 Qwen3-Coder-Next 后,其最新力作 Qwen-2.0-Image 也正式亮相。
正如其名,这是 Qwen 图像 AI 模型的一次重大升级。之前的版本已在全球范围内凭借高质量的图像生成能力积累了众多用户,而 Qwen-2.0-Image 则试图突破单纯“画图”的边界,迈向更复杂的视觉创作领域。
本文将深入剖析其技术特性,解读它如何通过统一的“理解+生成”架构来解决行业痛点,并结合 Benchmark 数据与实战测试,探讨它是否真的具备重新定义“专业级 AI 绘图”的潜力。
核心定位:从“生成图片”到“生成设计”
首先,我们来明确 Qwen-2.0-Image 的定位。对于尚不熟悉的读者,Qwen 是阿里云开发的开源权重大型语言模型家族。而作为该家族的最新成员,Qwen-2.0-Image 的野心远不止于根据提示词生成一张漂亮的图片。
在官方描述中,团队明确将该模型定位为 专为“专业信息图表(Professional Infographics)”和高细节写实主义构建的 AI 图像模型。这标志着其技术路线的一个重要转折:它试图解决当前 AI 绘图工具普遍存在的痛点——难以处理复杂的视觉层级和精确嵌入文字。
模型强调了其更强的语义依从性和 原生 2K 分辨率 输出,并特别指出其在处理精细场景(如人物、自然、建筑)时的能力,同时承诺通过更轻量的架构实现更快的迭代速度。
技术特性拆解:五大核心亮点
如果你深度使用过主流 AI 图像生成器,可能会发现它们在涉及“排版”和“设计感”时往往表现不佳。生成的图表通常布局混乱,文字难以辨识,整体视觉层级缺乏专业感。
Qwen-2.0-Image 的核心竞争力,正是在于它试图填补“美观”与“可用”之间的鸿沟。以下是其五大核心技术特性:
1. 专业级排版渲染
官方将此作为首要特性并非偶然。多数图像模型在处理图文结合时颇为吃力,而 Qwen-2.0-Image 支持长达 1k-token 的指令,这意味着用户可以直接要求生成“专业信息图表”。
这一点至关重要。设计 PPT、海报或信息图不仅仅是画面的堆砌,更是布局、层级、留白与一致性的综合考量。如果一个模型能够遵循长文本的结构化指令,它就不再只是在描述一个场景,而是在 设计一个页面。
2. 原生 2K 极致写实
Qwen-2.0-Image 宣称支持 原生 2K 分辨率(2048×2048) 输出。这里的关键词是 “原生(Native)”。
这意味着图像的高保真度并非来自于生成低分辨率图像后的后期超分(Upscaling),而是直接生成。这使得模型在处理皮肤毛孔、织物纹理和建筑细节等“微观细节”时,能展现出更强的写实能力。
3. 基于“理解+生成”统一方法的文本渲染
这是技术实现上最有趣的部分。Qwen 团队采用了一种将图像生成与编辑统一的模式。这不仅是为了把字写对,更是将文本视为图像工作流中不可或缺的核心要素。模型在“理解”上下文的同时进行“生成”,从而保证文字与画面的自然融合。
4. 统一全能模型:生成与编辑合二为一
发布文档描述了一种 Unified Omni Model。Qwen-2.0-Image 将“全栈多模态理解与生成”集成在同一个模型中。
对于工程实践而言,这意味着 更少的工具切换。用户可以在同一个模式下完成生成、微调和迭代,而无需在不同工具或模式间反复跳转,这无疑提升了创作效率。
5. 更轻量的架构与更快的推理
随着 人工智能 生成在生产环境中的普及,效率成为关键指标。Qwen-2.0-Image 采用了更轻量的模型架构,旨在实现更小的模型体积和更快的推理速度。
这一点在实际应用中往往被低估。如果你的目标是生成海报或 PPT,必然需要进行大量的微调。推理速度直接决定了用户是继续在 AI 中迭代,还是放弃并转向传统设计工具。
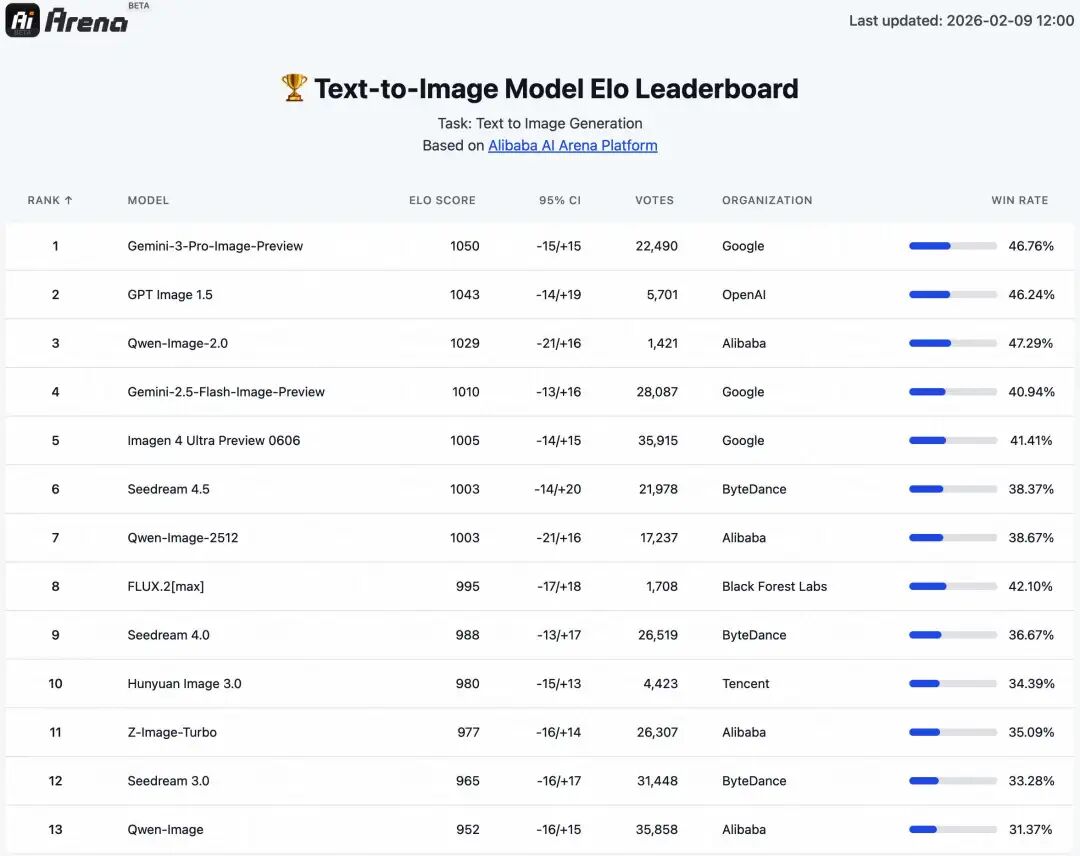
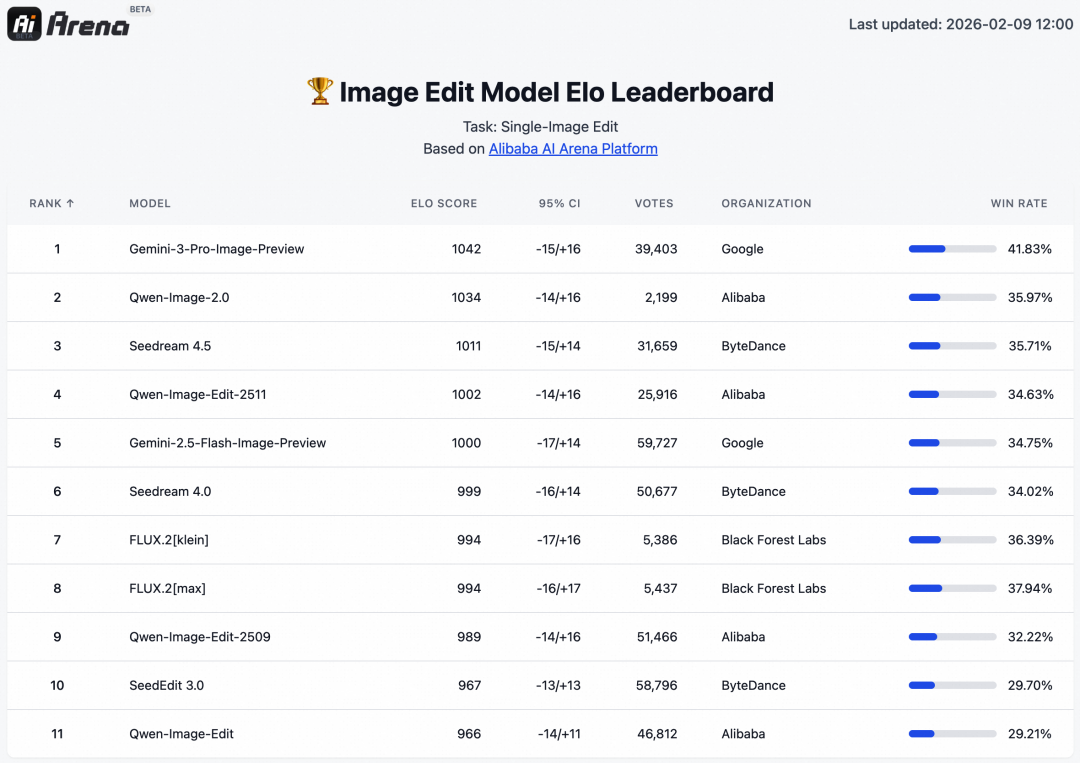
Benchmark 性能表现
为了佐证其技术实力,Qwen 团队公布了基于 Alibaba AI Arena 的测试结果。这是一个盲测评估平台,采用 ELO 评级系统(类似于竞技游戏的排名机制)。用户在不知道模型名称的情况下对图像进行对比打分。
- 文本生成图像: Qwen-2.0-Image 在 ELO 排行榜上名列前茅。
- 图像编辑: 在另一个针对图像编辑的排行榜中,它也与业界顶尖的 AI 图像编辑器表现相当。
具体的排名数据可参考以下官方榜单截图:
实战评测
纸面参数固然重要,但实际落地效果才是检验真理的唯一标准。为了测试 Qwen-2.0-Image 是否如宣传般强大,我们设计了三个不同维度的提示词进行实测。
测试 1:复杂信息图表设计
目标: 测试模型对布局、文字渲染及结构化指令的理解能力。
提示词摘要: 要求生成一张关于印度板球世界杯的海报,包含四个版块(印度、澳大利亚、英国、新西兰),需具备清晰的统计数据、球星插画及专业配色。
结果分析: Qwen-2.0-Image 成功生成了一张结构清晰、外观专业的信息图表,基本满足了提示词中的布局要求。

- 优点: 视觉层级分明,色彩搭配符合“体育分析”的调性。
- 不足: 尽管整体效果出色,但内容存在“幻觉”。例如,生成的球员形象并非都手持球棒,且具体的统计数据存在事实性错误。
- 结论: 模型具备了极强的 形式设计能力,但在 领域知识 的精准度上仍需人工干预或后续微调。考虑到这是初次输出,其生成的结构具有很高的可编辑性。
测试 2:极致人像写实
目标: 测试“原生 2K”在微观纹理(皮肤、毛孔、光影)上的表现。
提示词摘要: 聚焦皮肤纹理、毛孔、细微面部毛发,要求柔和的侧光和电影感色调,背景虚化,追求 DSLR 微距摄影质感。
结果分析: 输出效果令人惊艳。图像精准地还原了指令中的每一个细节,皮肤质感自然,光影过渡柔和。

- 结论: 在写实摄影领域,Qwen-2.0-Image 的表现已经达到了难以分辨真伪的程度,完全兑现了关于“微观细节”的承诺。
测试 3:艺术风格迁移
目标: 测试模型对艺术风格、笔触及氛围的把控。
提示词摘要: 描绘雪山、河流、草甸的经典油画风格,要求可见的笔触感、厚涂法以及黄金时刻的光影。
结果分析: 模型成功捕捉了油画的厚重感与光影氛围,色彩丰富且不过度饱和,呈现出颇具艺术感的画面。

结语
综上所述,通过对 Qwen-2.0-Image 的 技术特性 分析与实战测试,我们可以得出一个明确的结论:这不仅仅是又一个图像生成器,而是向“AI 设计师”迈出的重要一步。
它在专业排版和原生高分辨率写实方面展现出的能力,为解决实际生产场景中的设计需求提供了新的可能。尽管在事实准确性上仍需完善,但其强大的形式构建能力和高效的统一工作流,已使其在众多多模态模型中脱颖而出。对于设计师、内容创作者和开发者而言,Qwen-2.0-Image 无疑是一个值得深入探索和尝试的强大工具。如果你想了解更多前沿的 AI 技术和开源实战案例,欢迎到 云栈社区 交流讨论。
 发表于 2026-2-12 15:09:36
|
查看: 182|
回复: 0
发表于 2026-2-12 15:09:36
|
查看: 182|
回复: 0
