
作为 VCF(VMware Cloud Foundation)管理员,你是否经历过这种深夜紧急呼叫?
凌晨三点,电话响起。你挣扎着接听,电话那头的同事语气焦急:“生产集群的一个Dell节点挂了,紫屏,疑似硬盘物理故障,赶紧上来看一下!”
你强打精神登录系统,在 VCF Operations 里检查了一圈软件层监控,一切正常。切换到 iDRAC 界面,翻查了半天日志,才最终确认:一块长期被忽略的物理硬盘因“介质磨损”彻底罢工了。
此时最让你崩溃的或许不是修复故障本身,而是不得不四处翻找那个不知丢在何处的 Excel 表格,或者致电 Dell 售后,只为了确认一个关键问题:这台服务器的保修过期了吗?
如果你是 VCF 管理员,一定对这种“软件监控全面,硬件监控靠天”的无力感深有体会。虚拟机、容器在软件层运行顺畅,但底层硬件却像一个“黑盒”,其健康状态全靠运气和偶然发现来维持。
问题根源在于,我们日常的监控大多停留在 ESXi 层级。对于服务器底层的风扇转速、电源功率,尤其是硬盘剩余寿命等关键信息,往往缺乏有效的监控手段。
我们投入巨资构建私有云,但底层硬件的管理方式却依然原始,这种反差实在令人无奈。今天,我想介绍一个能改变这一现状的工具——Hardware vCommunity Management Pack for VCF Operations。它不仅仅是一个插件,更像是运维人员的一根“救命稻草”。
告别复杂的 SNMP,拥抱标准化的 Redfish API
在深入了解这个插件之前,我们先回顾一下传统硬件监控的痛点。
以往,若想在 VROps(现称 VCF Ops)中查看硬件数据,标准操作是什么?配置 SNMP。
回想整个过程:你需要在 iDRAC 中配置团体字,在防火墙上开放 161/162 端口,然后在 VROps 中填写冗长的 OID。只要 IP 段写错一处,或者 DNS 解析稍有延迟,监控就会报错。
这种感觉,就像在 2026 年试图用收音机接收 5G 信号,令人头疼不已。
这个新发布的插件彻底摒弃了 SNMP,转而采用 Redfish API。听起来很高深,但本质是让服务器硬件说上了“普通话”。
Redfish 基于标准的 HTTPS(443 端口)。你只需提供一个具备只读权限的账户,插件就能直接从 iDRAC 中抓取结构化的数据。没有复杂的 OID,没有玄学的团体字。只要网络能通 443 端口,监控数据即可秒级呈现。
这正是:别用战术上的勤奋(折腾复杂协议),去掩盖战略上的懒惰(拒绝拥抱标准)。
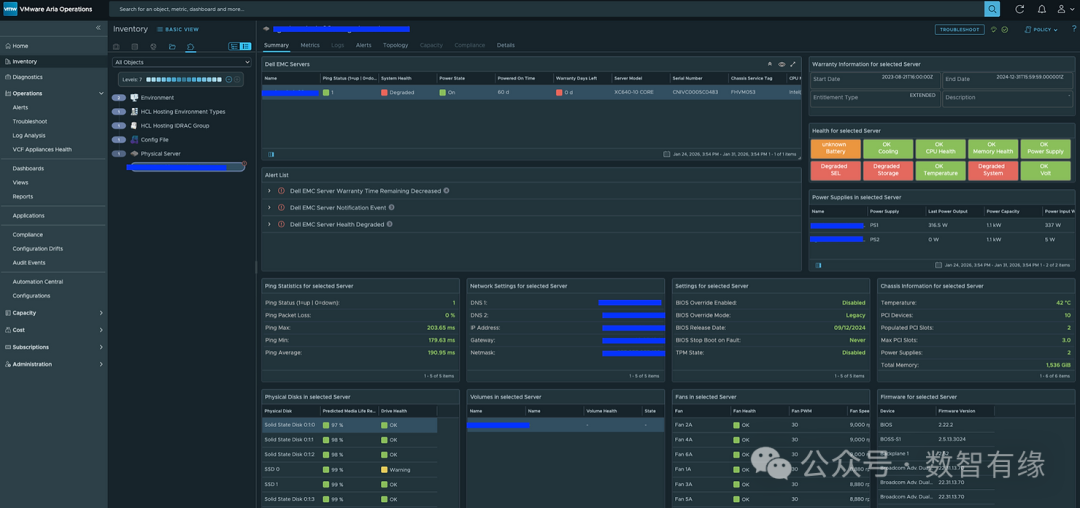
预测硬盘“死期”:看这个百分比倒计时就够了
对于运维人员而言,最可怕的不是硬盘损坏,而是“毫无征兆的突然死亡”。
传统告警流程通常是:硬盘损坏 -> 触发告警 -> 紧急更换。这属于被动应对。
但在这个插件中,有一个令人眼前一亮的指标:PredictedMediaLifeLeftPercent。
该指标通过 Redfish 直接从 Dell iDRAC 底层获取,专门针对 NVMe 和 SSD。它能告诉你:基于当前读写负载,这块硬盘还剩余百分之几的“寿命”。此数值在底层通常每小时更新一次,虽非秒级实时,但对于预测性维护而言已完全足够。
试想,如果在仪表盘上看到某台宿主机的硬盘寿命仅剩 5%,你是愿意等到它凌晨三点损坏将你唤醒,还是选择在下周一的例行维护窗口中,从容不迫地将其更换?
运维的最高境界并非修复迅速,而是防患于未然,根本无需修复。
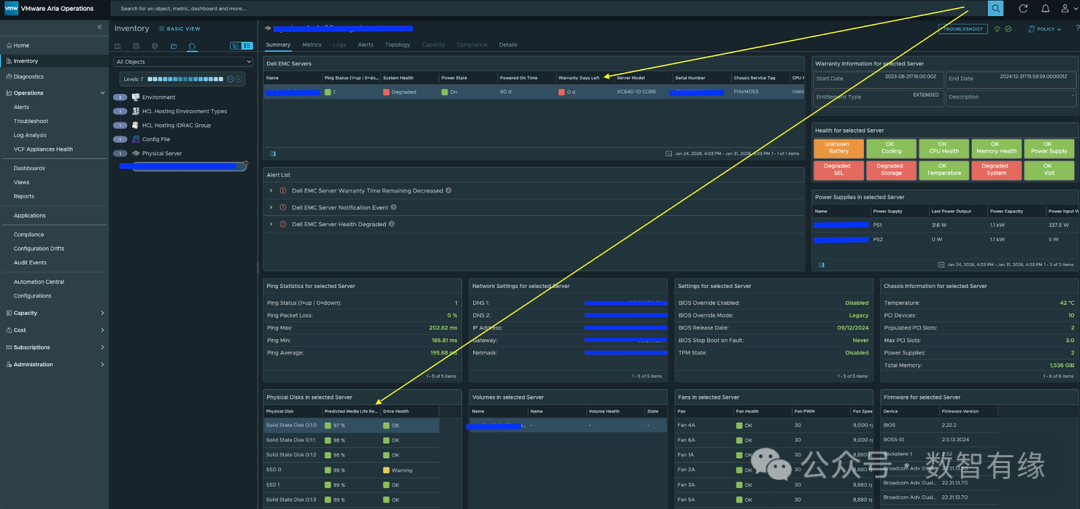
掌握了这个指标,你完全可以设置一个告警策略:当硬盘寿命低于 10% 时,自动创建一个运维工单。这才是现代私有云应具备的智能化管理能力。
自动保修查询:将 Dell 的数据库接入你的监控系统
还记得开头提到的翻找保修单的尴尬场景吗?
这个插件最巧妙的功能之一是,它集成了对接 Dell TechDirect API 的能力。
效果非常出色。你只需前往 Dell 官网免费申请一个 Client ID 和 Secret,然后将其填入 VCF Ops 的适配器实例配置中。
接下来便是见证奇迹的时刻。
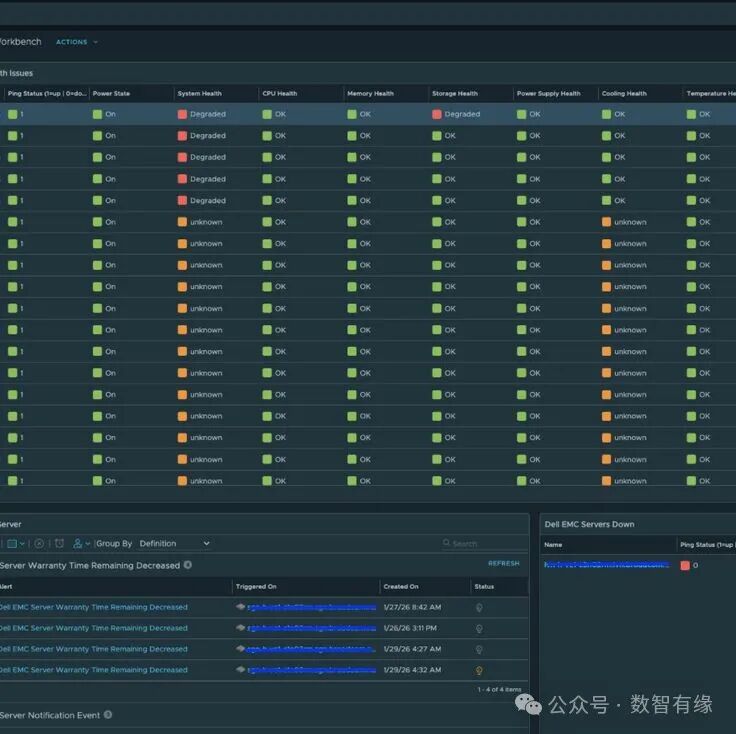
插件会自动查询 Dell 的后台数据库:这台服务器的型号是什么?出厂日期是哪天?保修究竟何时到期?你无需手动输入任何信息,系统会根据 Service Tag 自动匹配。
更强大的是,这套 API 支持单次批量查询多达 100 台服务器。这意味着即使你管理着数百个节点,也只需轻点几下鼠标,整个集群的保修状态全景图便清晰呈现。
随后,它会在 VCF Ops 中生成一条预警告警:“注意,某某宿主机将在 30 天后过保。”
这种感觉非常舒心。
你再也不必维护那个永远无法及时更新的 Excel 表格了。当老板询问今年有多少设备需要续保时,你只需点开 VCF Ops 中的相关仪表盘,导出一份报告,直接呈现在他面前。
这种全局掌控感,正是运维/DevOps/SRE人员职业发展的核心逻辑——你不仅仅是在修理机器,你更是在系统地管理资产风险。
部署指南:比你想象的更简单
我知道你在担心什么:“功能这么强大,安装一定很复杂吧?”
实际上并非如此。
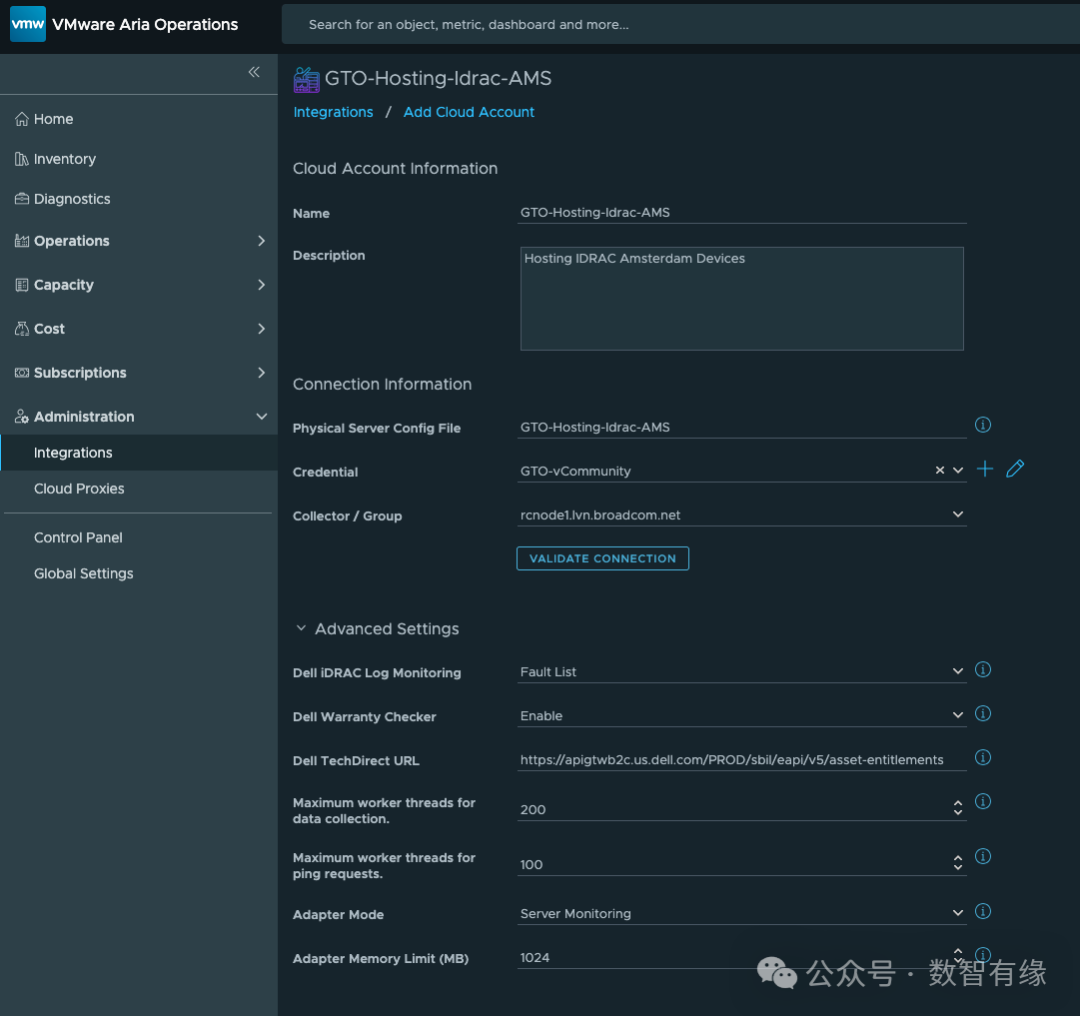
这套 Management Pack 的部署逻辑非常清晰。它的核心依赖是一个组件:Cloud Proxy。
如果你使用的是 VCF Ops,那么 Cloud Proxy 本就是必需的远程收集器。你只需要完成以下三个步骤:
- 导入 .pak 文件:就像安装其他插件一样简单。
- 准备配置文件:将你需要监控的 Dell 服务器的 FQDN 或 IP 地址列在一个文本文件中并上传。
- 配置凭据:填入 iDRAC 的只读账户密码(强烈建议遵循安全最佳实践使用只读账户),以及 Dell TechDirect 的 API 密钥。
完成这些配置后,只需等待它运行几个收集周期即可。
目前该版本是社区版,但已经提供了 5 个设计精美的预设仪表盘。从全局硬件健康状态总览,到具体的磁盘寿命热力图,一应俱全。
虽然当前版本尚不能像官方插件那样自动将 ESXi 主机与物理服务器对象关联(这是未来版本的开发方向),但对于填补现有的硬件监控空白而言,这已是“久旱逢甘霖”了。
结语:监控的本质是信息同步
归根结底,监控的核心目的并非仅仅是发现错误。
监控的本质,在于实现“信息同步”。 它让底层硬件状态与上层软件管理保持同步,也让运维人员掌握的信息与设备的真实情况保持一致。
这套由社区贡献的 Management Pack,虽然目前主要支持 Dell PowerEdge 服务器(未来计划支持更多平台),但它代表了一个明确的趋势:硬件管理正逐渐走出“黑盒”时代。
如果你正在管理 VCF 环境,如果你也厌倦了在凌晨三点翻找保修单,我强烈建议你抽空尝试一下这个工具。毕竟,能用工具解决的焦虑,就不要再牺牲睡眠去硬扛。
项目源码与详细文档地址: https://github.com/vmbro/VCF-Operations-Hardware-vCommunity/tree/main
希望这篇分享能为你解决实际网络/系统层面的监控痛点带来启发。欢迎在技术社区交流相关的实践与心得,例如在云栈社区与同行们深入探讨。
 发表于 2026-2-12 16:54:45
|
查看: 221|
回复: 0
发表于 2026-2-12 16:54:45
|
查看: 221|
回复: 0
