年前,各大AI模型厂商动作频频,新品接连发布。其中,阿里低调推出了通义千问最新的图像生成模型——Qwen-Image-2.0。这自然引起了技术社区的关注,我们对其核心能力进行了一系列深度测试,并与大家分享实测结果和详细提示词。
模型能力概览
用一句话概括Qwen-Image-2.0的升级要点:提示词长度翻倍提升至1K,指令遵循与文字渲染能力显著增强,支持2K分辨率直出,中文语义理解更为精准,可轻松生成信息图、PPT等复杂内容。

值得一提的是,该模型在中文文字渲染方面的表现尤为突出,实测效果相较于某些竞品模型更为稳定,文字不易出现变形或乱码问题。
实测案例与提示词分析
以下是我们通过具体案例对Qwen-Image-2.0进行的“拷打”测试,每个案例均附上使用的完整提示词。
1. 复杂图文编排:水煮肉片菜谱
首项测试是生成一份高度结构化的手账风格菜谱插画,涉及文字、图片、步骤说明等多种元素的精确编排。

提示词 (883字符):
生成一张水煮肉片的手账风格菜谱插画。
整体风格:画面以米色或淡黄色复古纸张为背景,呈现手绘、拼贴、复古手账的风格。整体色调温暖,细节丰富,充满生活气息,仿佛一本精心制作的家常菜谱。
顶部标题区域:
页面顶部居中,手写艺术字体标题:“麻辣鲜香:水煮肉片秘籍”。标题周围用手绘的红色辣椒、绿色花椒、姜蒜片等元素做装饰性边框。
中央主体插画:
画面中央是一幅 手绘风格的水煮肉片特写图。描绘一个盛满了红亮汤汁的宽口碗,碗中浮着嫩滑的猪肉片,翠绿的蒜苗段或香菜末撒在表面,底部隐约可见烫好的豆芽和白菜。强调汤汁的油亮感和食材的新鲜度,色彩鲜明但不失手绘的柔和质感。
左侧食材与用量清单(便利贴样式):
在主插画的左侧,用手撕纸或便利贴的形式,手写列出“食材清单”,并详细注明用量:主料: 猪里脊肉 300g,配菜:豆芽 200g,大白菜 200g
调料:干辣椒 10-15个 (剪段)花椒 1大勺 (15g)
郫县豆瓣酱 2大勺 (30g),蒜末 30g,姜末 20g,食用油 适量盐 适量料酒 1大勺淀粉 1大勺蛋清 1个高汤或清水 500ml香葱/蒜苗 适量 (切段)
右侧烹饪步骤:
在主插画的右侧,用3-4个手绘分格小插画(类似漫画格子或拍立得照片),清晰展示关键烹饪步骤,每个插画下方配有手写步骤说明:
1. 插画1: 准备工作- 砧板上猪肉切薄片,用碗装着肉片,旁边是盐、料酒、淀粉、鸡蛋清,肉片正在腌制。下方手写:“步骤1:腌制肉片 - 里脊肉切片,加盐、料酒、淀粉、鸡蛋清抓匀腌制15分钟。”
2. 插画2: 炒制底料 - 锅中热油,放入干辣椒段、花椒粒炒香,然后加入豆瓣酱、姜末、蒜末爆炒出红油。下方手写:“步骤2:炒香底料- 热油爆香干辣椒、花椒,加豆瓣酱、姜蒜末炒出红油。”
3. 插画3: 煮制配菜与肉片- 锅中加入高汤或清水,烧开后先下豆芽、白菜烫熟捞出铺底,再放入腌好的肉片烫熟。下方手写:“步骤3:煮熟烫片- 锅中加高汤,先烫熟配菜捞出铺碗底,再下肉片快速滑熟。”
4. 插画4: 泼油提香- 将煮好的肉片连汤倒入碗中,表面撒上蒜末和香葱/蒜苗段,另起锅烧热油,泼在蒜末葱段上,滋啦作响。下方手写:“步骤4:泼油增味- 将肉片汤汁倒入碗中,表面撒蒜末、蒜苗,烧热油淋泼其上,激发出香味。”
装饰元素:画面边缘点缀手绘的厨房小物件(如小砂锅、勺子、案板、切菜刀),或者零散的食材(如几颗花椒、几个辣椒、几片姜蒜)。可以有手撕感纸张边缘、仿旧胶带贴纸、或复古印章图案(如“Homemade Goodness”、“辣到过瘾”等)。
整体排版:采用手账常见的灵活排版,文字和图片错落有致,通过手绘线条、箭头或虚线将相关内容连接起来,增强视觉引导和趣味性。
从输出结果看,模型对长达883字的复杂指令理解到位,图文布局符合要求,最关键的是所有中文字符渲染准确、清晰,最终直出2K高清图。
2. 微缩场景构建:圣诞主题POP MART
测试模型对流行文化元素和精致细节的还原能力,目标是生成一个充满节日氛围的微缩场景。

提示词:
参考神老师的提示词做了些改动:
一个透明亚克力展示盒内的微缩场景,呈现泡泡玛特(POP MART)精品店面。店面采用标志性的明亮黄色与白色拼接外立面, 装饰着带有迷你松枝、红色浆果和LED串灯的节日花环, 顶部有"POP MART"的标志性气泡字体大型标识, 以及No. 888闪耀的金色数字装饰。
店内温暖金色照明透过玻璃橱窗和玻璃门漫射出来, 橱窗内精心展示着微缩的Molly、Dimoo、Skullpanda经典盲盒公仔, 以及最新的圣诞限量系列特别版手办(如圣诞老人Molly和麋鹿Dimoo)。
店门前, 坐在一个积雪覆盖的复古木质长椅上, 有一个可爱的Q版卡通人物。她拥有大头身比例, 闪亮的kawaii动漫大眼睛, 正好奇地歪着头, 怀里紧紧抱着一个系着蝴蝶结的微型盲盒礼物。
人物穿着oversize的奶油色毛绒连帽衫搭配百褶短裙, 围着红绿相间的圣诞针织围巾, 下身搭配堆堆袜和圆头大头鞋。
模型成功输出了效果惊艳的图片,场景细节丰富,氛围感强,表明其在处理特定风格和复杂描述上具有不错的能力。
3. 旅行攻略海报
测试模型整合地图、图标、文字行程等多种信息,生成具有设计感的海报的能力。

提示词 (节选关键部分):
请帮我生成一张图
这是一张充满手绘温度与艺术感的哈尔滨七天旅游攻略海报。比例为9:16...
【地图内容与地标描绘】
地图上错落地标注着哈尔滨的标志性景点,均以小巧而精美的手绘图标呈现...
【七日行程与文字排版】
在地图的下方或左右两侧的空白区域...清晰地排列着“Day 1 - Day 7”的详细行程指南。每个行程旁都配有与之对应的迷你手绘图标,例如:
Day 1: 漫步冰城。 (配一个欧式建筑小图标)漫步中央大街,品尝马迭尔冰棍,看防洪纪念塔。
Day 2: 圣殿余晖。 (配一个教堂穹顶小图标)参观圣索菲亚大教堂,走过中东铁路大桥看冰上落日。
...
模型很好地遵循了冗长而具体的指令,将地图、行程文字和图标有机融合,最终海报的视觉呈现和信息传达都相当清晰。多模态与AIGC技术的结合,让此类复杂设计图的生成门槛大幅降低。
作为对比,将同样的长提示词输入给其他主流图像模型时,虽然在构图和美感上可能不相上下,但在中文文字渲染的准确性和稳定性上往往略逊一筹,细看文字部分容易出现模糊或变形。
4. 人物细节质感
测试模型在生成人物时对皮肤、毛发等细节的处理,目标是降低“AI假人感”。

提示词:
晒太阳的女孩,阳光撒在的身上,连脸上细小的绒毛都可见
输出图片在人物肤质、发丝光影等细节上刻画出色,显著提升了真实感,有效降低了传统AI生成图像中常见的“塑料感”或“油腻感”。
5. 专业PPT页面直出
测试模型生成符合商业设计规范的数据图表和PPT页面的能力。
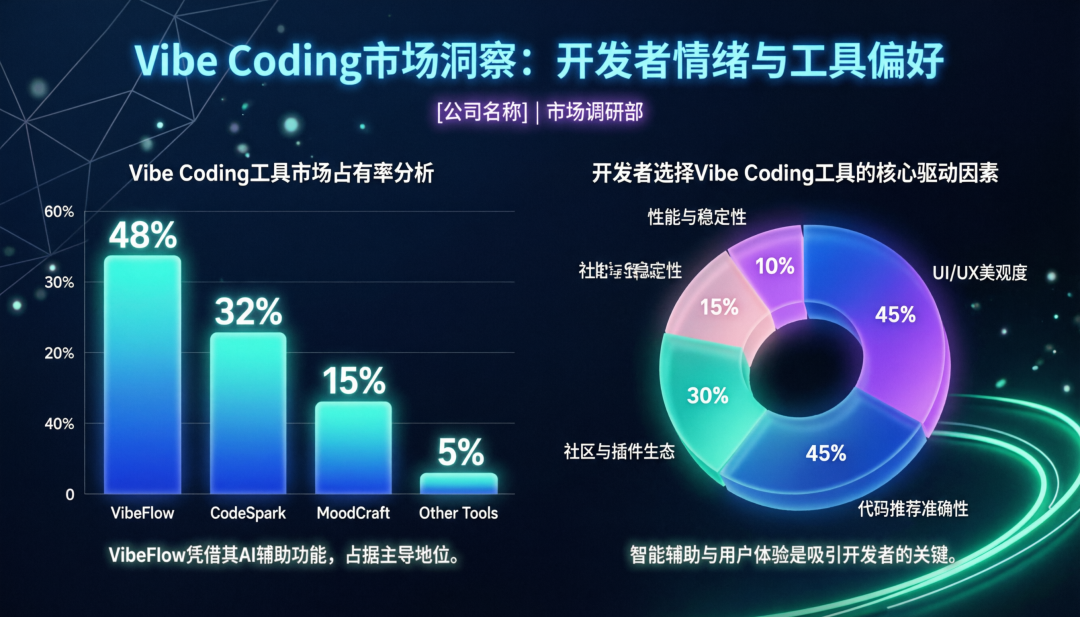
提示词 (节选):
生成一张关于“Vibe Coding市场调研”的PPT页面设计图,采用极简主义与未来科技感的风格...
左侧数据可视化区域(柱状图):
在页面左侧,设计一个垂直柱状图。标题为:“Vibe Coding工具市场占有率分析”...
右侧数据可视化区域(饼状图):
在页面右侧,设计一个饼状图。标题为:“开发者选择Vibe Coding工具的核心驱动因素”...
模型成功生成了包含柱状图和饼图的可视化页面,图表设计、数据标签、颜色搭配和整体排版都符合“专业PPT”的要求,展示了其处理复杂逻辑排版的能力。
6. 信息图与概念分解图
这两个案例进一步测试了模型的图文信息整合与结构化表达能力。
信息图的生成基于一段零散的技术要点描述(提示词较长,此处略),模型将其提炼并排版成美观的黑板报风格信息图,即本文开头展示的功能概览图。
概念分解图则要求对一个人物形象进行多维度拆解展示。

提示词 (节选关键结构):
生成一张手绘的全景式角色深度概念分解图...
顶部区域: 图像正上方从左到右排列四个面部特写,头像下方依次标注 "平静" "微笑" "惊讶" "忧郁" 文字。
中央核心: 图像中央是图中的年轻女性...
细节拆解(右中侧): 右中侧展示一件提取出来的淡蓝色绸缎旗袍...
细节拆解(右下侧):右下侧展示旗袍面料的放大材质特写...
(其他细节拆解部分省略)...
模型精确地遵循了“中心主图+周围特写元素+箭头指示”的复杂构图指令,生成的设计稿逻辑清晰,颇具专业感。
7. 其他能力探索
我们还测试了模型在其他场景下的表现:
- 多图融合与编辑:能够根据指令将两张独立图片中的元素(女孩和狗)融合到新场景中,并完成简单的图像编辑(如更换宠物围兜颜色)。虽然在人物一致性上仍有提升空间,但基础能力已具备。
- 连环画生成:输入“以可爱大象为主题生成九宫格连环画”,模型可以输出情节连贯的系列小插画。
- 中国风书法长卷:测试了模型处理大量中文书法文字与画面结合的能力。

提示词 (节选):
一幅中国传统书画一体的横幅长卷作品...
在画面下方的留白区域,以苍劲有力的**草书或行草**完整书写毛泽东《沁园春·雪》全文:
“北国风光,千里冰封,万里雪飘...俱往矣,数风流人物,还看今朝。”
...
模型成功渲染了完整的《沁园春·雪》词文,书法笔画与画面意境结合得较好,展示了其在中文特色内容生成上的优势。
总结与思考
综合来看,Qwen-Image-2.0在多个维度上实现了显著提升:
- 强大的长文本理解与指令遵循:支持长达1K的提示词,能够消化并执行极其详尽的生成要求。
- 卓越的中文文字渲染能力:在生成海报、菜谱、PPT等包含大量中文的文字时,准确性和稳定性突出,这是其差异化优势之一。
- 复杂的图文结构生成:能够驾驭信息图、PPT、概念分解图等具有复杂逻辑和排版要求的任务。
- 细节质感提升:在人物皮肤、材质纹理等细节上表现更真实,减少了AI感。
当然,模型也有可优化之处。例如,在面对非常简短、模糊的提示词时,其“脑补”和审美设计能力,即根据简单意图推理出丰富、优美画面的能力,相较于某些以“推理”见长的模型尚有差距。简单指令可能难以一次性得到理想效果,需要用户提供更具体的描述。
这反映出当前深度学习模型在“精确执行”与“创意发散”之间的不同侧重。Qwen-Image-2.0显然在“精确执行”复杂指令方面下了更多功夫,特别适合对文字准确性、排版结构有明确要求的场景。
无论如何,模型的快速迭代令人鼓舞。Qwen-Image-2.0在实用性,尤其是在中文环境下的可用性方面迈出了一大步。对于需要频繁生成带中文的营销素材、教育课件、内部文档的用户来说,它是一个非常值得尝试的工具。
本文中使用的详细提示词可供参考,欢迎在云栈社区的AI技术板块与其他开发者进一步交流多模态模型的应用心得与技巧。
 发表于 2026-2-13 05:15:45
|
查看: 510|
回复: 0
发表于 2026-2-13 05:15:45
|
查看: 510|
回复: 0
