缓存(例如:Redis)和数据库的数据一致性问题,是日常开发与面试中的经典难题。特别是在高并发场景下,这个问题会变得更加突出。
业内常见的解决方案
目前,业界主要有以下几种方案来应对缓存不一致的问题:
- 先更新数据库,再删缓存。
- 延迟双删:先删缓存,再更新数据库,延时一段时间,再删一次缓存。
- Canal/Maxwell订阅 binlog,异步删除缓存:基于中间件监听数据库变更日志,再触发缓存删除。
这三种方案基本可以覆盖大部分业务场景。
| 方案 |
优点 |
缺点 |
适用场景 |
| 先更新数据库,再删缓存 |
实现简单,对业务代码侵入小 |
若删除缓存失败,存在短时间不一致 |
95%的一般场景,尤其是并发量不大,或对一致性要求不高的业务。 |
| 延迟双删 |
数据一致性保障更好,能应对部分并发脏读 |
需预估延迟时间;第二次删除失败需重试 |
对数据一致性要求高,并发量大的热点数据场景。 |
| 监听binlog异步删除 |
与业务代码解耦,可靠性高 |
实现复杂,需引入中间件 |
基础建设完善,并发高且对一致性要求高的场景。 |
先写数据库,再删缓存
为什么是删除缓存,而不是更新缓存?
并发写冲突风险高
在高并发场景下,多个线程或服务可能同时更新同一份数据。如果采用更新缓存的策略,极易出现竞态条件,导致缓存中存留旧值或错误值。
假设有两个线程 A 和 B 同时操作:
| 时间 |
线程 A |
线程 B |
| T1 |
更新数据库为 100 |
|
| T2 |
|
更新数据库为 200 |
| T3 |
更新缓存为 100(A 的旧值) |
|
| T4 |
|
更新缓存为 200(B 的新值) |
最终缓存是 200,看似正常。但如果由于网络延迟或线程调度,导致 T3 发生在 T4 之后,缓存就会被 A 的旧值覆盖,变为 100,造成不一致。
删除缓存操作具有幂等性,多次执行无副作用,更适合高并发场景。
缓存更新逻辑复杂,容易出错
更新缓存通常需要:从库读取最新值、构造缓存对象、写入 Redis。其中任一环节出错,都可能导致缓存数据错误。而删除缓存仅需一个 DEL 指令,逻辑简单,出错概率低。
延迟加载(Lazy Loading)更自然
删除缓存后,下一次读取会触发“缓存未命中”,自动从数据库加载最新数据并回填。这种延迟加载机制保证了缓存数据总是最新的。
配合“先更新数据库,再删除缓存”更可靠
此策略在多数情况下能保证最终一致性。即使删除缓存失败,也可通过消息队列重试或定时任务补偿进行兜底。在极端情况下,为防止缓存击穿,可使用分布式锁保证只有一个线程去加载数据。
综上,删除缓存是比更新缓存更稳妥、更简单的选择。
先写数据库还是先删缓存?
既然删除缓存更优,那么顺序应如何选择?
先删缓存,再更新数据库
| 时刻 |
线程 A(写) |
线程 B(读) |
| T1 |
删除缓存成功 |
|
| T2 |
|
缓存 miss,去库读旧值 100 |
| T3 |
|
把 100 回填缓存 |
| T4 |
数据库更新为 200 |
|
即便 T3 和 T4 顺序互换,结果都是:缓存中将在一段时间内保留旧值 100,直到下一次失效或更新。
先更新数据库,再删缓存
此方案优势在于:
- 数据库作为持久层先更新,确保了数据的可靠性。
- 缓存删除失败的概率相对较低(除非网络或服务器故障)。
| 时刻 |
线程 A(写) |
线程 B(读) |
| T1 |
更新数据库为 200(事务提交) |
|
| T2 |
删除缓存(DEL) |
|
| T3 |
|
缓存 miss,去库读 200 |
| T4 |
|
把 200 回填缓存 |
延迟双删
“先更新数据库,再删缓存”也存在不一致的概率,例如在更新后、删除前的极短时间窗口内,或有删除操作失败时。延迟双删是一种旨在缩小不一致窗口的折中策略。
其核心在于通过两次删除操作,应对并发读写中可能出现的脏数据回写问题。
基本流程
- 第一次删除缓存:在更新数据库前或后执行,目的是防止旧数据被立即读取。
- 更新数据库。
- 延迟一段时间后,再次删除缓存:这是关键步骤,目的是清除在并发过程中可能被错误写入缓存的旧数据。
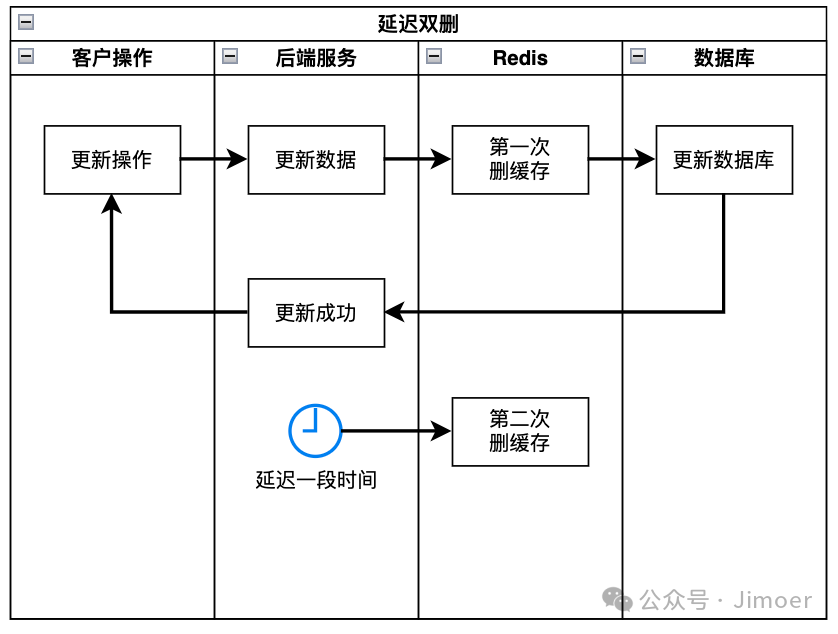
为什么需要两次删除?
- 第一次删除:防止后续读请求直接命中旧的缓存数据。
- 第二次延迟删除:在第一次删除后,可能有并发读请求在数据库更新完成前(或主从同步延迟期间)读取到旧数据,并将其写回缓存。延迟第二次删除就是为了清理这部分“脏数据”。
注意事项
- 延迟时间:这是一个经验值,通常需大于“主从同步延迟 + 一次完整读请求耗时 + 缓冲时间”,建议通过监控动态调整。
- 非强一致性:延迟双删不能100%避免不一致,只能降低其发生概率和影响时长。
- 失败兜底:第二次删除失败仍会导致不一致,因此常配合消息队列的重试机制作为保障。
这是一种追求最终一致性的策略,适用于对一致性要求较高,但无法承受强一致性开销的高并发场景。
Cache-Aside + 监听binlog删缓存
Cache-Aside(旁路缓存) 结合监听 binlog 异步删除缓存,是目前主流的最终一致性方案。它将业务代码与缓存失效逻辑彻底解耦,兼具简单性与可靠性。
基本流程
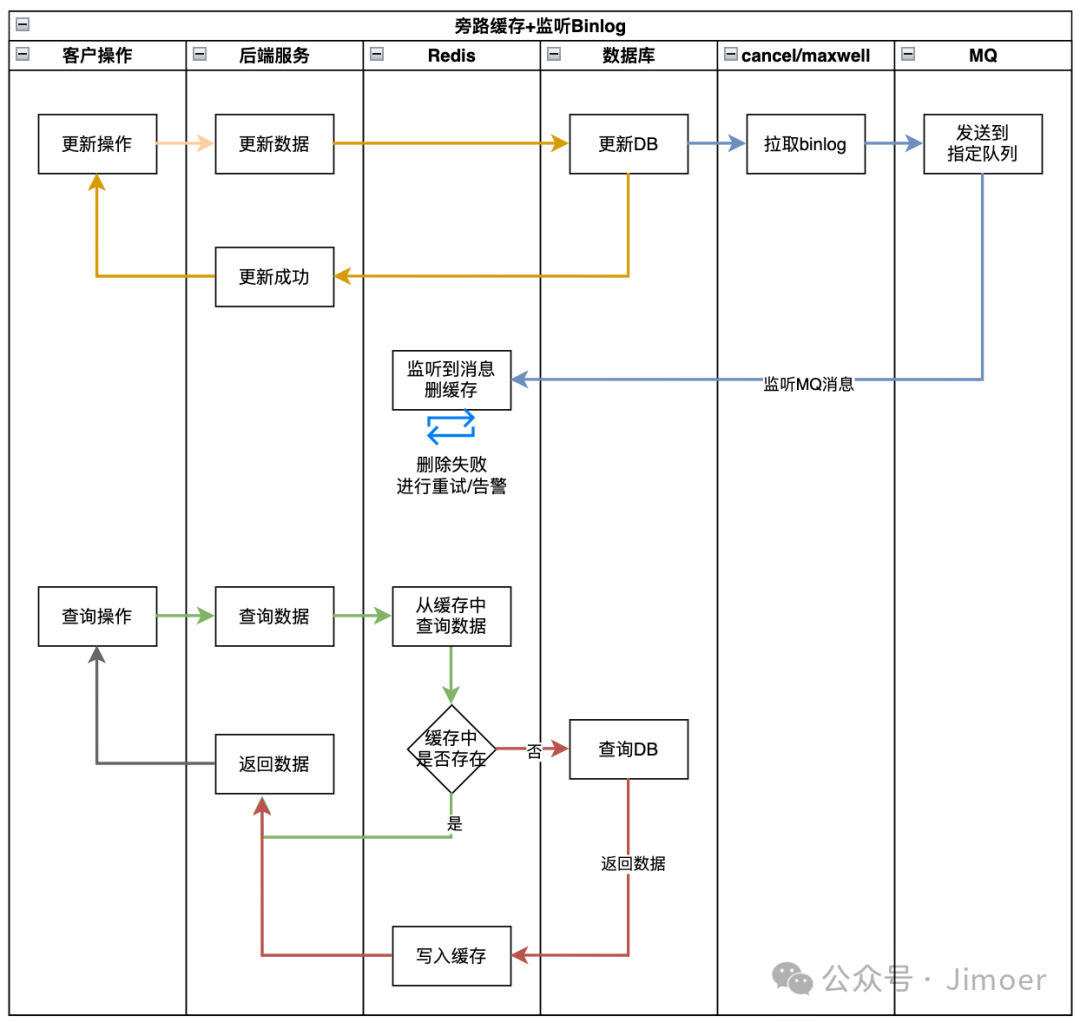
这种架构的优势在于:
- 写路径极简:应用只写数据库,不直接操作缓存,降低延迟和复杂度。
- 解耦与可靠:通过监听数据库的binlog来触发删缓存,即使中间件暂时不可用,binlog也保留了完整的操作记录,具备天然的重放与恢复能力。
代码示例
// 1. 业务层——只负责写库,代码纯净
@Transactional
public void updateOrder(Order order) {
// 写操作不直接更新缓存
orderMapper.updateById(order);
}
// 2. 中间件适配层(如Canal客户端)——解析binlog并发出事件
@CanalEventListener
public class OrderHandler {
@KafkaSender(topic = "order_binlog")
public BinlogEvent onUpdate(CanalEntry.Entry entry) {
String orderId = parseOrderId(entry);
return new BinlogEvent("UPDATE", orderId);
}
}
// 3. 缓存清理服务——消费事件并删除缓存
@KafkaListener(topics = "order_binlog", groupId = "cache_clean")
public void cleanCache(BinlogEvent event) {
try {
// 删除缓存
redisTemplate.del("order:" + event.getOrderId());
// 只有成功才提交offset,失败则靠MQ重试
} catch (Exception e) {
throw new RuntimeException("DEL failed, trigger retry", e);
}
}
以上代码示例了分离的职责处理。核心在于:消费端只有成功执行 DEL 命令后才确认消息,否则依赖消息队列的重试机制保证最终执行。
Cache-Aside 机制确保了读操作的缓存回填逻辑,而 binlog监听 则保证了写操作后缓存的必然失效。两者结合,在读写分离、对一致性要求高的业务中,是一种扩展性强且均衡的方案。
总结
在实际工作中,如何选择这些方案?
- 轻量级场景:团队规模小,无复杂中间件。首选“先更新库,再删缓存”。容忍秒级脏读(如商品详情、用户资料)。
- 高热数据场景:读QPS极高,且数据被频繁热读(如秒杀库存)。考虑“延迟双删”,进一步压缩不一致时间窗口。
- 高要求金融场景:已具备消息队列或日志监听能力,且数据准确性要求严苛(如订单、支付)。推荐“监听binlog异步删除”,实现业务与缓存的解耦,并做好失败兜底。
所有的技术方案都是权衡的产物,需要在业务现状、实现复杂度、团队能力、可维护性等多方面取得平衡。不存在“完美”的方案,只有“适合”的方案。做出更优选择的关键,在于对业务场景和技术细节的深入理解。
 发表于 2025-12-6 00:27:24
|
查看: 191|
回复: 0
发表于 2025-12-6 00:27:24
|
查看: 191|
回复: 0
