
一、为什么你需要关注插件
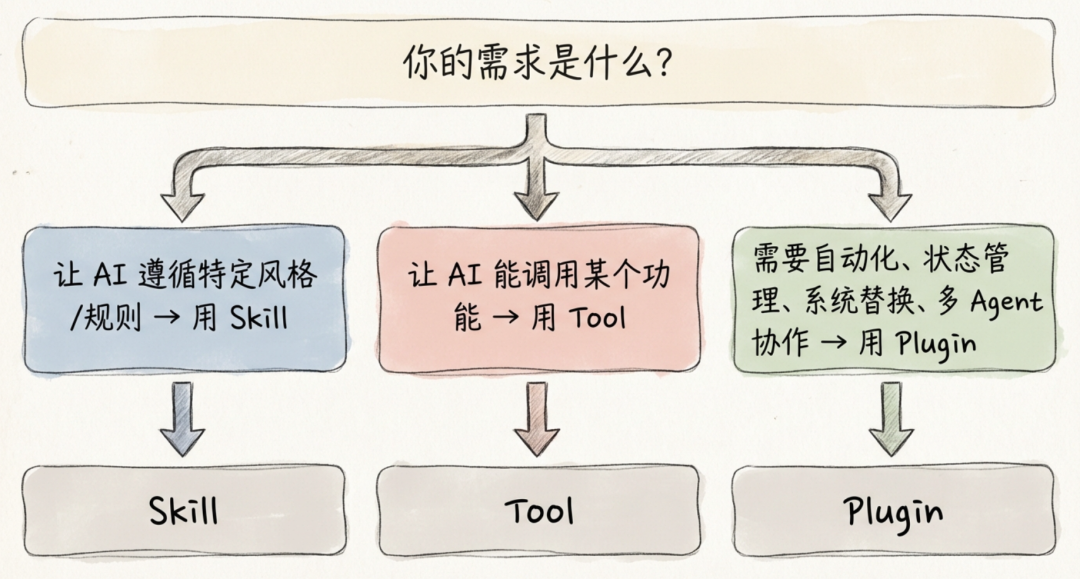
大多数 OpenClaw 用户在实现自定义功能时,第一反应是编写 Skill 或注册自定义 Tool。这两种方式简单直接,但在面对需要深度介入 Agent 生命周期的场景时,往往力不从心。
1.1 三种扩展机制对比
| 维度 |
Skill |
Tool |
Plugin |
| 本质 |
Markdown 文本,注入到系统提示词 |
一个可被 AI 调用的函数 |
完整的扩展程序,可访问 Agent 全生命周期 |
| 执行时机 |
系统提示词构建阶段被注入 |
AI 主动决策调用 |
可以借助“钩子”在任意生命周期中执行 |
| 能否主动介入 |
否,只能被动提供指令 |
否,依赖 AI 判断是否调用 |
是,依赖钩子机制主动介入 |
| 适用场景 |
行为指导、回答风格、领域知识补充 |
搜索、计算、文件操作等工具性任务 |
记忆管理、知识注入、数据持久化、多 Agent 协作 |
1.2 关键差异:被动 vs 主动
当你的需求是 「在生命周期中某个阶段总应该自动发生某件事」 (而非等 AI 判断后才执行),插件是唯一选择。
1.3 应用插件的常见场景
- 需要在每次对话开始前自动检索和注入外部知识(RAG)
- 需要在每次对话结束后自动提取和持久化记忆
- 需要替换 OpenClaw 的默认行为(如替换内置记忆系统)
- 需要在多个 Agent 之间共享数据管道
二、深入理解 OpenClaw 插件
2.1 核心概念
OpenClaw 插件是一个 npm 包(或本地目录),包含以下核心文件:
my-plugin/
├── package.json # npm 包元数据 + openclaw.extensions 入口声明
├── openclaw.plugin.json # 插件清单(id、描述、配置模式)
├── index.ts # 插件入口,导出 { id, register } 对象
└── ... # 其他源码文件
插件清单 (openclaw.plugin.json) 定义了插件的身份和配置模式:
{
"id": "my-plugin",
"name": "My Plugin",
"description": "Does something useful",
"configSchema": {
"type": "object",
"required": ["apiKey"],
"properties": {
"apiKey": { "type": "string" }
}
}
}
包声明 (package.json) 中的 openclaw.extensions 字段告诉 OpenClaw 从哪个文件加载插件逻辑:
{
"openclaw": {
"extensions": ["./index.ts"]
}
}
2.2 插件在 Agent 生命周期中的作用点
OpenClaw 的 Agent 生命周期是一条从消息接收到回复发送的管线。插件可以通过“钩子(Hooks)”在管线的关键节点介入。OpenClaw 共提供 24 个钩子,覆盖 Agent 运行、消息处理、工具调用、会话管理等全部阶段。
核心生命周期流程
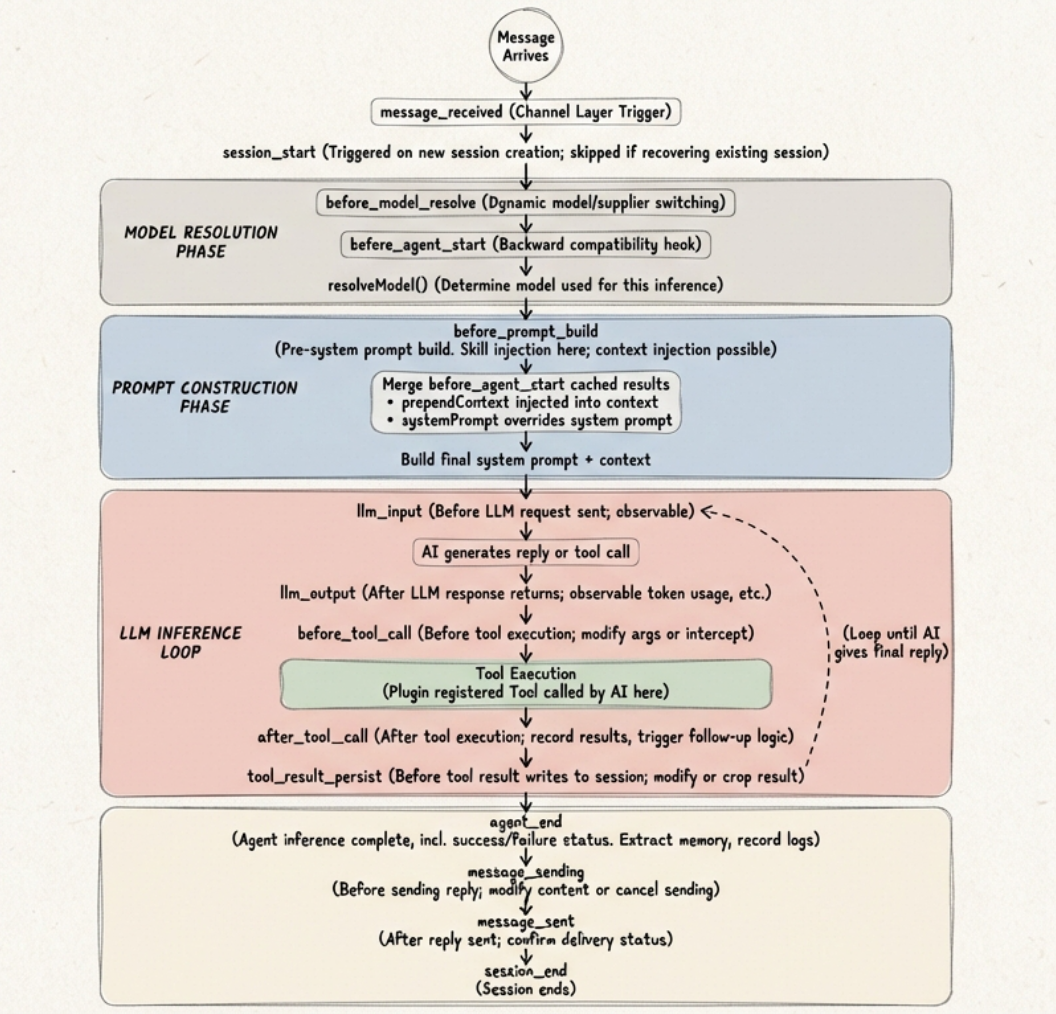
钩子分类总览
Agent 阶段钩子:
| 钩子 |
触发时机 |
可干预 |
典型用途 |
before_model_resolve |
模型选择前 |
是(切换模型/供应商) |
按场景动态路由到不同模型 |
before_prompt_build |
系统提示词构建前 |
是(注入上下文/覆盖提示词) |
知识注入、动态指令生成 |
before_agent_start |
模型解析 + 提示词构建阶段 |
是(注入上下文 + 切换模型) |
向后兼容钩子;模型覆盖优先级低于 before_model_resolve,上下文注入在提示词构建阶段生效 |
llm_input |
LLM 请求发出前 |
仅观测 |
请求日志、审计 |
llm_output |
LLM 响应返回后 |
仅观测 |
token 用量统计、质量监控 |
agent_end |
Agent 推理完成 |
仅观测 |
记忆提取、对话归档、错误追踪 |
工具调用钩子:
| 钩子 |
触发时机 |
可干预 |
典型用途 |
before_tool_call |
工具执行前 |
是(修改参数/拦截调用) |
权限校验、参数审计、敏感操作拦截 |
after_tool_call |
工具执行后 |
仅观测 |
结果日志、耗时统计 |
tool_result_persist |
工具结果写入会话前 |
是(修改或裁剪结果) |
去除冗余字段以节约上下文空间 |
消息与会话钩子:
| 钩子 |
触发时机 |
可干预 |
典型用途 |
message_received |
消息到达时 |
仅观测 |
消息日志、计数统计 |
message_sending |
回复发送前 |
是(修改内容/取消发送) |
内容审核、格式转换 |
message_sent |
回复发送后 |
仅观测 |
送达确认、失败重试 |
session_start |
新会话创建时(恢复已有会话不触发) |
仅观测 |
会话级资源初始化 |
session_end |
会话结束 |
仅观测 |
会话级资源清理 |
记忆与会话管理钩子:
| 钩子 |
触发时机 |
可干预 |
典型用途 |
before_compaction |
会话压缩前 |
仅观测 |
压缩前归档完整会话 |
after_compaction |
会话压缩后 |
仅观测 |
压缩效果统计 |
before_reset |
会话重置前 |
仅观测 |
重置前保存状态 |
before_message_write |
消息写入会话记录前 |
是(修改/阻止写入) |
过滤敏感信息、自定义持久化 |
子 Agent 钩子:
| 钩子 |
触发时机 |
典型用途 |
subagent_spawning |
子 Agent 创建前 |
控制子 Agent 生成策略 |
subagent_spawned |
子 Agent 创建后 |
跟踪子 Agent 运行 |
subagent_ended |
子 Agent 结束 |
收集子 Agent 执行结果 |
subagent_delivery_target |
子 Agent 回复路由时 |
自定义回复投递目标 |
Gateway 钩子:
| 钩子 |
触发时机 |
典型用途 |
gateway_start |
Gateway 启动时 |
初始化外部连接 |
gateway_stop |
Gateway 关闭时 |
清理资源 |
2.3 插件的两种角色
通用插件(General Plugin):提供工具和钩子,与其他插件并行工作。
插槽插件(Slot Plugin):替换 OpenClaw 的某个核心功能。目前支持的插槽:
| 插槽 |
功能 |
默认实现 |
memory |
长期记忆存储与检索 |
内置 memory-core(本地文件 + SQLite) |
contextEngine |
上下文引擎(控制上下文编排策略) |
内置默认实现 |
当你在配置中指定 plugins.slots.memory = “your-plugin-id” 时,你的插件将完全替代默认的 memory-core 记忆系统。
2.4 插件的发现与安装
OpenClaw 从以下位置按优先级发现插件:
- 配置路径 (
plugins.load.paths):指向本地目录,适合开发调试
- 工作区目录 (
.openclaw/extensions/):项目级插件
- 内置插件目录:OpenClaw 自带的插件
- 全局扩展目录 (
~/.openclaw/extensions/):通过 openclaw plugins install 安装
开发阶段推荐使用 plugins.load.paths,直接指向源码目录:
{
"plugins": {
"load": {
"paths": ["/path/to/your/plugin"]
}
}
}
生产阶段推荐发布到 npm 后通过 CLI 安装:
openclaw plugins install your-plugin-name
2.5 插件配置
每个插件在 openclaw.json 的 plugins.entries 中拥有独立的配置空间:
{
"plugins": {
"entries": {
"your-plugin-id": {
"enabled": true,
"config": {
"apiKey": "${ENV_VAR}",
"option": "value"
}
}
},
"allow": ["your-plugin-id"]
}
}
配置值支持 ${ENV_VAR} 语法引用环境变量,避免敏感信息硬编码。
三、插件开发范式速览
3.1 最小可用插件示例
import { Type } from “@sinclair/typebox”;
import type { OpenClawPluginApi } from “openclaw/plugin-sdk”;
const plugin = {
id: “my-plugin”,
register(api: OpenClawPluginApi) {
const config = api.pluginConfig as { greeting: string };
// 注册工具
api.registerTool(
{
name: “say_hello”,
label: “Say Hello”,
description: “Greet the user”,
parameters: Type.Object({
name: Type.String({ description: “User name” }),
}),
async execute(_toolCallId, params) {
const { name } = params as { name: string };
return {
content: [{ type: “text”, text: `${config.greeting}, ${name}!` }],
};
},
},
{ name: “say_hello” },
);
// 注册生命周期钩子
api.on(“before_agent_start”, async (event, ctx) => {
api.logger.info(“Agent”, ctx.agentId, “starting…”);
return { prependContext: “Remember to be friendly!” };
});
// 注册服务(管理资源生命周期)
api.registerService({
id: “my-plugin”,
start: (ctx) => ctx.logger.info(“Plugin started”),
stop: async (ctx) => ctx.logger.info(“Plugin stopped”),
});
},
};
export default plugin;
3.2 核心 API 速查
| API |
用途 |
api.pluginConfig |
获取插件配置(来自 openclaw.json 中的 plugins.entries.<id>.config) |
api.logger |
日志输出(.info(), .warn(), .error()) |
ctx.agentId |
钩子回调第二个参数 ctx 中的当前 Agent ID(非 api 顶层属性) |
api.registerTool(def, opts) |
注册一个可被 AI 调用的工具 |
api.on(hook, handler) |
监听生命周期事件,handler 签名为 (event, ctx) => result,ctx 含 agentId 等上下文 |
api.registerService(svc) |
注册服务(管理启动/停止生命周期) |
四、最佳实践:用 RDS MySQL 生态插件解决原生 OpenClaw 的两大痛点
4.1 痛点分析:外源知识使用与长期记忆管理
痛点一:外源知识使用 —— AI 只能靠「问」来获取
原生 OpenClaw 获取外部知识的路径是:
用户提问 → AI 判断需要外部信息 → AI 调用 web_search / web_fetch → 获取结果 → 生成回答
这条路径存在三个问题:
| 问题 |
说明 |
| 决策依赖 AI |
AI 可能判断「我已经知道答案」而跳过搜索,导致使用过时信息 |
| 无法预加载 |
即使有现成的知识库,也必须等 AI 主动调用工具才能检索 |
| 无结构化存储 |
web_search 获取的信息是一次性的,下次对话需要重新搜索 |
用 Skill 指导 AI「每次都先搜索」可以缓解但无法根治 —— 因为 Skill 只是建议,AI 仍可能忽略。
痛点二:长期记忆管理 —— 默认记忆系统的局限
OpenClaw 的默认记忆方案是 memory-core,它基于本地文件系统运作:
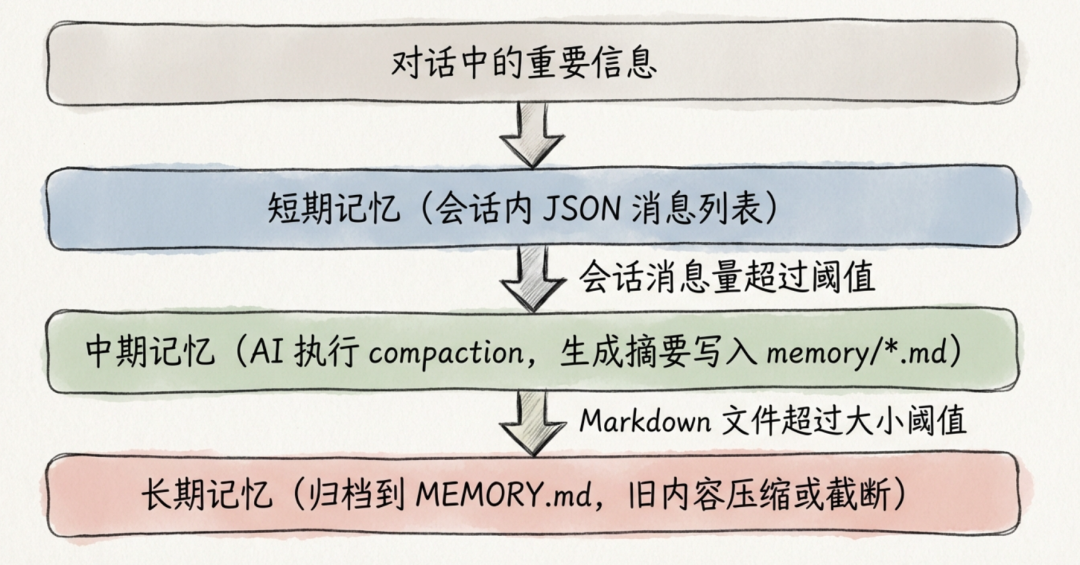
所有记忆都以 Markdown 文件(MEMORY.md、memory/*.md)和 SQLite 的形式存储在本地 ~/.openclaw/ 目录下。这套方案在单机个人使用场景下工作良好,但面临以下局限:
| 局限 |
说明 |
| 数据绑定宿主机 |
所有记忆存储在本地文件系统,无法跨设备访问 |
| 无备份与高可用 |
本地文件系统不具备自动备份、故障恢复能力 |
| 检索依赖全文匹配 |
memory-core 的检索基于关键词和 Markdown 全文,缺乏语义理解能力 |
| 记忆质量管理缺失 |
没有去重、归档、摘要等主动维护手段 |
4.2 实践一:外源知识注入案例 — 世界经济新闻知识库
场景描述
我们希望构建一个「世界经济新闻顾问」,它能够:
- 每天自动采集最新经济新闻,存入知识库
- 用户提问时,自动从知识库检索相关新闻并注入上下文
- 支持用户主动搜索知识库
这需要两个插件和两个 Agent 协作:
| 组件 |
职责 |
知识生成插件 (openclaw-knowledgebase-generate-alibaba-mysql) |
文本分块 → Embedding → 存入 MySQL 向量表 |
知识检索插件 (openclaw-knowledgebase-fetch-alibaba-mysql) |
每次对话前自动检索 → 注入上下文;提供 kb_search 工具 |
| news-crawler Agent |
新闻采集器,搜索互联网并调用插件存入知识库 |
| news-chat Agent |
新闻对话官,与用户交互,自动获得知识库上下文加持 |
从零搭建:完整步骤
前置条件
第一步:设置环境变量
将敏感信息配置为环境变量,避免硬编码到配置文件中。在 ~/.bashrc(或 ~/.zshrc)中添加:
export MYSQL_HOST=“rm-xxxxxxxxxxxx.mysql.rds.aliyuncs.com”
export MYSQL_USER=“your_username”
export MYSQL_PASSWORD=“your_password”
export DASHSCOPE_API_KEY=“sk-xxxxxxxxxxxxxxxx”
执行 source ~/.bashrc 使环境变量生效。
openclaw.json 中通过 ${ENV_VAR} 语法引用这些变量,OpenClaw 会在启动时自动解析替换。
第二步:安装插件
openclaw plugins install openclaw-knowledgebase-generate-alibaba-mysql
openclaw plugins install openclaw-knowledgebase-fetch-alibaba-mysql
安装完成后可验证:
openclaw plugins list
# 应能看到两个插件
第三步:配置 LLM 模型供应商
在 ~/.openclaw/openclaw.json 的 models 中注册 DashScope 模型。news-crawler 使用低成本的 qwen-flash,news-chat 使用高质量的 qwen3-max:
{
“models”: {
“mode”: “merge”,
“providers”: {
“dashscope”: {
“baseUrl”: “https://dashscope.aliyuncs.com/compatible-mode/v1”,
“api”: “openai-completions”,
“apiKey”: “${DASHSCOPE_API_KEY}”,
“models”: [
{
“id”: “qwen3-max”,
“name”: “Qwen3 Max”,
“input”: [“text”],
“reasoning”: false,
“contextWindow”: 128000,
“maxTokens”: 8192
},
{
“id”: “qwen-flash”,
“name”: “Qwen Flash”,
“input”: [“text”],
“reasoning”: false,
“contextWindow”: 128000,
“maxTokens”: 8192
}
]
}
}
}
}
第四步:配置插件
在 openclaw.json 的 plugins 中完成三部分配置:加载声明、允许列表、各插件参数。
{
“plugins”: {
“allow”: [
“openclaw-knowledgebase-generate-alibaba-mysql”,
“openclaw-knowledgebase-fetch-alibaba-mysql”
],
“entries”: {
“openclaw-knowledgebase-generate-alibaba-mysql”: {
“enabled”: true,
“config”: {
“mysql”: {
“host”: “${MYSQL_HOST}”,
“port”: 3306,
“user”: “${MYSQL_USER}”,
“password”: “${MYSQL_PASSWORD}”,
“database”: “openclaw_knowledge_base”,
“ssl”: false
},
“embedding”: {
“apiKey”: “${DASHSCOPE_API_KEY}”,
“model”: “text-embedding-v3”,
“baseUrl”: “https://dashscope.aliyuncs.com/compatible-mode/v1”,
“dimensions”: 1024
},
“defaultTable”: “kb_economy_news”,
“chunking”: {
“strategy”: “paragraph”,
“maxChunkSize”: 500,
“overlap”: 100
}
}
},
“openclaw-knowledgebase-fetch-alibaba-mysql”: {
“enabled”: true,
“config”: {
“mysql”: {
“host”: “${MYSQL_HOST}”,
“port”: 3306,
“user”: “${MYSQL_USER}”,
“password”: “${MYSQL_PASSWORD}”,
“database”: “openclaw_knowledge_base”,
“ssl”: false
},
“embedding”: {
“apiKey”: “${DASHSCOPE_API_KEY}”,
“model”: “text-embedding-v3”,
“baseUrl”: “https://dashscope.aliyuncs.com/compatible-mode/v1”,
“dimensions”: 1024
},
“sources”: [
{
“table”: “kb_economy_news”,
“label”: “世界经济新闻”,
“topK”: 5,
“minScore”: 0.3
}
],
“autoInject”: true,
“injectMaxChars”: 3000
}
}
}
}
}
关键配置说明:
| 配置项 |
说明 |
mysql.database |
必填。指定 MySQL 数据库名,需提前在 RDS 中创建 |
embedding.model |
Embedding 模型,DashScope 推荐 text-embedding-v3 |
embedding.dimensions |
向量维度,text-embedding-v3 支持 1024(默认)或 768 |
defaultTable |
知识生成插件的默认目标表名,AI 调用 kb_store 时若不指定表名则写入此表 |
chunking.strategy |
分块策略:paragraph(按段落)、fixed(固定长度)、none(不分块) |
sources |
知识检索插件的数据源列表,支持多个表并行检索 |
sources[ ].topK |
每次检索返回的最大条目数 |
sources[ ].minScore |
最低相似度阈值(0-1),低于此值的结果被过滤 |
autoInject |
是否在每次对话开始时自动注入知识(before_agent_start 钩子) |
injectMaxChars |
自动注入的最大字符数,防止上下文过长 |
两个插件的 mysql 和 embedding 配置必须一致(指向同一数据库、同一 Embedding 模型和维度),否则写入和检索时的向量空间不匹配。
第五步:定义 Agent
在 openclaw.json 的 agents 中定义两个 Agent。核心是通过 tools.allow 工具白名单控制每个 Agent 的能力边界:
{
“agents”: {
“defaults”: {
“model”: {
“primary”: “dashscope/qwen3-max”
}
},
“list”: [
{
“id”: “news-chat”,
“name”: “新闻对话官”,
“default”: true,
“identity”: {
“name”: “NewsBot”
},
“model”: {
“primary”: “dashscope/qwen3-max”
},
“tools”: {
“allow”: [
“memory_recall”, “memory_store”, “memory_forget”,
“kb_search”, “web_fetch”
]
}
},
{
“id”: “news-crawler”,
“name”: “新闻采集器”,
“identity”: {
“name”: “Crawler”
},
“model”: {
“primary”: “dashscope/qwen-flash”
},
“tools”: {
“allow”: [
“web_fetch”,
“kb_store”, “kb_store_batch”
]
},
“heartbeat”: {
“target”: “none”
}
}
]
}
}
第六步:验证配置
运行配置检查:
openclaw doctor
如果输出无报错,说明配置有效。
第七步:运行 news-crawler 写入知识
手动触发采集 Agent,验证知识写入流程(注意退出需要找到 pid 后 kill,也可以在 Gateway 中测试):
openclaw agent --agent news-crawler --message \
“使用 web_fetch 访问 https://www.baidu.com/s?wd=世界经济新闻 ,从搜索结果中提取 2 条新闻摘要,然后用 kb_store 逐条存入知识库”
成功时你会看到类似输出:
[plugins] kb-generate: registered (defaultTable=kb_economy_news, ...)
已成功从百度搜索结果中提取并存储两条新闻到知识库...
第八步:运行 news-chat 验证检索
手动触发chat Agent,验证知识写入流程(注意退出需要找到 pid 后 kill,也可以在 Gateway 中测试):
openclaw agent --agent news-chat --message “最近有什么世界经济方面的新闻?”
成功时你会看到类似输出:
[plugins] kb-fetch: registered (sources=世界经济新闻, autoInject=true, ...)
[plugins] kb-fetch: injected 3 entries (294 chars) ← 自动注入了知识
根据知识库中的信息,以下是近期重要的世界经济新闻...
关键观察点:kb-fetch: injected N entries 表明知识检索插件在 before_agent_start 钩子中成功检索并注入了相关知识。AI 的回答直接引用了知识库中的内容,无需任何人工干预或 AI 主动调用工具。
插件工作原理详解
知识生成插件
- npm:
openclaw-knowledgebase-generate-alibaba-mysql
知识生成插件是一个纯工具插件,不使用任何生命周期钩子。它在 Agent 推理过程中被 AI 通过工具调用来使用。注意,MySQL 表在首次写入时自动创建,无需手动建表。
提供的工具:
| 工具 |
功能 |
kb_store |
存储单条文本,自动分块和 Embedding |
kb_store_batch |
批量存储多条文本 |
kb_scan |
查看知识库统计和最近条目 |
kb_dedupe |
时间窗口内语义去重 |
kb_summarize |
获取最近条目,供 AI 生成摘要 |
kb_archive |
软删除过期条目 |
知识检索插件
- npm:
openclaw-knowledgebase-fetch-alibaba-mysql
知识检索插件通过 before_agent_start 钩子实现自动检索,用户和 AI 都不需要做任何事,相关知识已经自动就位,这是它与普通 Tool 的根本区别:
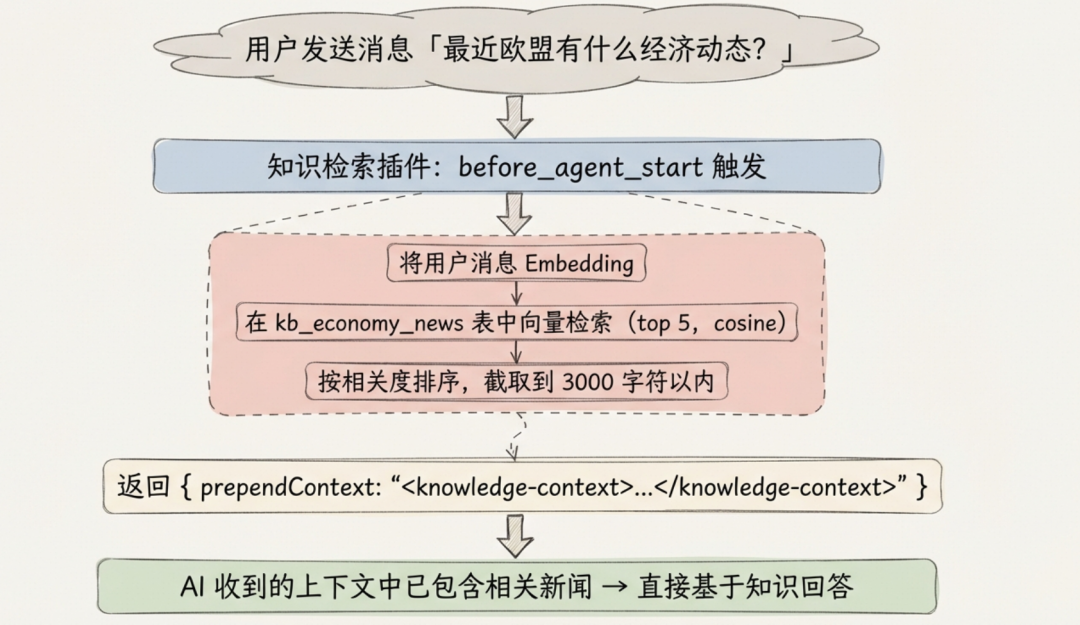
4.3 实践二:长期记忆云化 — RDS MySQL 替代本地方案
场景描述
将 OpenClaw 的长期记忆从默认的 memory-core(本地文件 + SQLite)迁移到阿里云 RDS MySQL,实现:
- 记忆数据云端持久化,不受宿主机限制
- 多 Agent / 多设备共享同一份记忆
- 自动备份与高可用(依托 RDS 能力)
为什么插件是更好的解决方案
| 需求 |
Skill/Tool 方案 |
插件方案 |
| 每次对话自动检索知识 |
❌ 需要 AI 主动调用 |
✅ before_agent_start 钩子自动执行 |
| 对话后自动提取记忆 |
❌ 需要 AI 主动调用 |
✅ agent_end 钩子自动执行 |
| 替换默认记忆系统 |
❌ 无法实现 |
✅ plugins.slots.memory 插槽机制 |
| 多 Agent 共享数据 |
❌ 无法实现 |
✅ 多个 Agent 配置同一插件,共享数据库 |
从零搭建:完整步骤
前置条件
与 4.2 相同:需要 OpenClaw、阿里云 RDS MySQL、DashScope API Key。如果你已经完成了 4.2 的环境搭建,此处可直接复用。
第一步:设置环境变量
如果尚未设置,参照 4.2 第一步配置 MYSQL_HOST、MYSQL_USER、MYSQL_PASSWORD、DASHSCOPE_API_KEY。
第二步:安装插件
openclaw plugins install openclaw-memory-alibaba-mysql
第三步:配置插件并声明插槽
这是记忆云化的关键步骤。需要在 ~/.openclaw/openclaw.json 中完成两件事:
- 在
plugins.entries 中配置插件参数
- 在
plugins.slots.memory 中将该插件声明为记忆插槽
{
“plugins”: {
“slots”: {
“memory”: “openclaw-memory-alibaba-mysql”
},
“allow”: [
“openclaw-memory-alibaba-mysql”
],
“entries”: {
“openclaw-memory-alibaba-mysql”: {
“enabled”: true,
“config”: {
“mysql”: {
“host”: “${MYSQL_HOST}”,
“port”: 3306,
“user”: “${MYSQL_USER}”,
“password”: “${MYSQL_PASSWORD}”,
“database”: “openclaw_memory”,
“ssl”: false
},
“embedding”: {
“apiKey”: “${DASHSCOPE_API_KEY}”,
“model”: “text-embedding-v3”,
“baseUrl”: “https://dashscope.aliyuncs.com/compatible-mode/v1”,
“dimensions”: 1024
},
“autoRecall”: true,
“autoCapture”: true,
“tableName”: “openclaw_memories”
}
}
}
}
}
plugins.slots.memory是生效的核心。设置后,OpenClaw 内置的 memory-core 会被完全禁用,所有记忆操作由 MySQL 插件接管。如果不设置此插槽,插件虽然会加载并注册工具,但 OpenClaw 的默认记忆系统仍然是 memory-core。
关键配置说明:
| 配置项 |
必填 |
说明 |
mysql.host |
是 |
RDS MySQL 实例地址 |
mysql.database |
是 |
数据库名,需提前在 RDS 中创建 |
mysql.ssl |
否 |
是否启用 SSL 连接,默认 false |
embedding.apiKey |
是 |
DashScope API Key |
embedding.model |
否 |
Embedding 模型,默认 text-embedding-v3 |
embedding.dimensions |
否 |
向量维度,默认根据模型自动推断(text-embedding-v3 为 1024) |
autoRecall |
否 |
每次对话前是否自动检索相关记忆,默认 true |
autoCapture |
否 |
每次对话后是否自动从用户消息中提取并存储记忆,默认 true |
tableName |
否 |
MySQL 表名,默认 openclaw_memories,首次使用时自动创建 |
第四步:确保 Agent 拥有记忆工具权限
如果你的 Agent 配置了 tools.allow 白名单,需要将记忆工具加入:
{
“agents”: {
“list”: [
{
“id”: “news-chat”,
“tools”: {
“allow”: [
“memory_recall”, “memory_store”, “memory_forget”,
“kb_search”, “web_fetch”
]
}
}
]
}
}
如果 Agent 没有设置 tools.allow(即使用默认配置),则所有工具自动可用,无需额外配置。
第五步:验证
运行配置检查:
openclaw doctor
然后在 Gateway 中与 Agent 对话验证记忆功能:
# 第一次对话:告诉 AI 一些信息
openclaw agent --message “我喜欢看科幻电影,最近在追三体电视剧”
# 观察日志:应出现 auto-capture 相关日志
# [plugins] openclaw-memory-alibaba-mysql: captured 1 new memory
# 第二次对话:验证 AI 能自动回忆
openclaw agent --message “你还记得我有什么爱好吗?”
# 观察日志:应出现 auto-recall 相关日志
# [plugins] openclaw-memory-alibaba-mysql: injecting N memories into context
关键观察点:
- auto-recall(自动召回):第二次对话启动时,日志出现
injecting N memories into context,说明记忆插件在 before_agent_start 钩子中成功检索了相关记忆并注入上下文
- auto-capture(自动捕获):第一次对话结束后,日志出现
captured N new memory,说明插件在 agent_end 钩子中自动从对话中提取了有价值的信息
- AI 回答中应能提到”科幻电影”和”三体”,尽管第二次对话是一个全新的会话
插件工作原理详解
- npm:
openclaw-memory-alibaba-mysql
提供的工具
| 工具 |
功能 |
memory_recall |
向量语义搜索历史记忆 |
memory_store |
存储新记忆(带分类、重要性) |
memory_forget |
删除指定记忆 |
自动化行为
记忆插件通过两个生命周期钩子实现全自动记忆管理:
before_agent_start(自动召回):
- 将用户当前消息生成 Embedding
- 在 MySQL 中向量检索相关历史记忆
- 将匹配的记忆注入到 AI 上下文中
- AI 无需调用任何工具即可获得历史背景
agent_end(自动捕获):
- 分析当前对话中的用户消息
- 过滤掉过短、无意义的内容
- 对有价值的信息生成 Embedding
- 与已有记忆去重(余弦相似度 > 0.95 则跳过)
- 存入 MySQL 并标注分类(偏好、事实、决策等)
对比:迁移前后
| 维度 |
memory-core (本地) |
RDS MySQL (云端) |
| 数据位置 |
~/.openclaw/ 本地文件 |
阿里云 RDS 实例 |
| 跨设备访问 |
❌ |
✅ |
| 自动备份 |
❌ 需手动 |
✅ RDS 自动备份 |
| 多 Agent 共享 |
❌ 各自本地文件 |
✅ 同一数据库 |
| 检索性能 |
数据量大时下降 |
HNSW 索引,稳定高效 |
| 可观测性 |
需读本地文件 |
SQL 直接查询 |
| 运维成本 |
低(但无保障) |
中(但有 SLA) |
五、整体总结
本文的实践经验来自真实的项目部署,旨在为 OpenClaw 的深度用户提供可复用的企业级方案。如果你在实施过程中遇到问题,欢迎在 云栈社区 的技术论坛板块与更多开发者交流探讨。
 发表于 2026-3-11 01:47:07
|
查看: 282|
回复: 0
发表于 2026-3-11 01:47:07
|
查看: 282|
回复: 0
