在大模型应用开发中,Text2SQL 的准确性始终是核心挑战。它高度依赖对数据库表结构和表间关系的精确理解。传统方法往往只能提供扁平的表结构描述,大模型在生成SQL时容易“猜错”关联关系,导致查询失败或结果偏差。
有没有一种方法,能让大模型直观地“看清”数据表之间的关联路径,就像我们看一张网络关系图一样?本文将介绍如何利用 Neo4j 图数据库,为MySQL数据库构建一个可视化的语义关系图谱,将抽象的外键约束和复杂的业务逻辑转化为大模型易于理解的“图结构”,从而显著提升 Text2SQL 的准确率与可控性。
核心思路非常清晰:提取MySQL的表结构(自动) + 补充人工定义的业务语义关系 -> 写入Neo4j图数据库 -> 为RAG或Agent提供精确的图谱检索能力 -> 生成更精准的SQL。
一、运行效果概览
在集成了这种语义图谱的问答系统中,当你提出“查询商品价格信息”时,系统会先从图谱中精准定位到t_products表,并结合其关联关系(如有)来构建查询,而不是盲目地扫描所有表。下图展示了在一个实际项目中的应用界面:
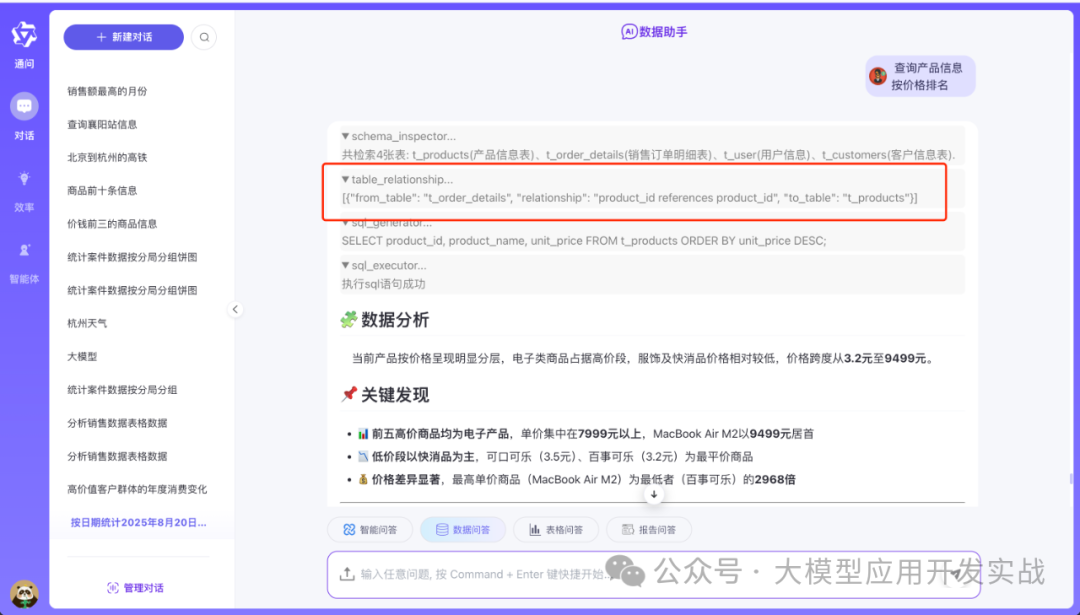
系统界面:左侧为历史查询,中间展示了SQL生成、执行及基于结果的数据分析全过程。

基于查询结果自动生成的数据分析报告与可视化图表,直接回答用户问题。
二、本文实践流程
- ✅ 环境配置 —— 安装 Docker、Neo4j 及 Python 依赖。
- 📊 自动提取表结构 —— 从 MySQL 动态获取字段、主键、外键。
- 🔗 人工定义表关系 —— 补充业务语义,构建完整图谱。
- 🧱 写入 Neo4j —— 创建节点、关系、约束。
- ▶️ 一键运行主函数 —— 自动化构建图谱。
- 🎁 项目集成参考 —— 如何应用到你的大模型项目中。
三、环境配置与依赖安装
3.1 使用 Docker 启动 Neo4j
我们使用带有 APOC 插件的 Neo4j 镜像,以方便未来扩展图算法功能。
docker run -d \
--name neo4j-apoc \
-p 7474:7474 \
-p 7687:7687 \
-v ./volume/neo4j/data:/data \
-v ./volume/neo4j/plugins:/plugins \
-e apoc.export.file.enabled=true \
-e apoc.import.file.enabled=true \
-e apoc.import.file.use_neo4j_config=true \
-e NEO4J_AUTH=neo4j/neo4j123 \
neo4j:5.26.11-ubi9
启动后,可通过浏览器访问 http://localhost:7474 使用 Neo4j Browser,默认用户名密码为 neo4j/neo4j123。
3.2 安装 Python 依赖
pip install pymysql py2neo
3.3 配置数据库连接信息
在 Python 脚本中配置你的 MySQL 和 Neo4j 连接信息。
# MySQL 配置
MYSQL_CONFIG = {
"host": "localhost",
"port": 13006,
"user": "root",
"password": "your_password", # ← 替换为你的密码
"database": "text2sql_db",
"charset": "utf8mb4",
}
# Neo4j 配置
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "your_password" # ← 替换为你的密码
3.4 数据库连接函数
from py2neo import Graph
import pymysql
def connect_mysql():
return pymysql.connect(**MYSQL_CONFIG)
def connect_neo4j():
return Graph(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
3.5 准备示例 MySQL 数据表
为了演示,我们需要创建一个示例数据库。这里以一个简单的电商销售数据模型为例,包含客户、产品、订单和订单明细表。
-- 创建客户表
CREATE TABLE `t_customers` (
`customer_id` int NOT NULL AUTO_INCREMENT COMMENT '客户ID',
`customer_name` varchar(100) NOT NULL COMMENT '客户姓名',
`phone` varchar(20) DEFAULT NULL COMMENT '联系电话',
`email` varchar(100) DEFAULT NULL COMMENT '电子邮箱',
`address` text COMMENT '地址',
`city` varchar(50) DEFAULT NULL COMMENT '城市',
`country` varchar(50) DEFAULT '中国' COMMENT '国家',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`customer_id`),
UNIQUE KEY `email` (`email`)
) COMMENT='客户信息表';
-- 创建产品表
CREATE TABLE `t_products` (
`product_id` int NOT NULL AUTO_INCREMENT COMMENT '产品ID',
`product_name` varchar(200) NOT NULL COMMENT '产品名称',
`category` varchar(50) DEFAULT NULL COMMENT '产品类别',
`unit_price` decimal(10,2) NOT NULL COMMENT '标准单价',
`stock_quantity` int NOT NULL DEFAULT '0' COMMENT '库存数量',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`product_id`)
) COMMENT='产品信息表';
-- 创建销售订单表 (假设存在,用于定义关系)
CREATE TABLE `t_sales_orders` (
`order_id` int NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`customer_id` int NOT NULL COMMENT '客户ID',
`order_date` datetime NOT NULL COMMENT '订单日期',
`total_amount` decimal(12,2) NOT NULL COMMENT '订单总额',
`status` varchar(20) DEFAULT 'pending' COMMENT '订单状态',
PRIMARY KEY (`order_id`),
KEY `customer_id` (`customer_id`)
) COMMENT='销售订单表';
-- 创建订单明细表
CREATE TABLE `t_order_details` (
`detail_id` int NOT NULL AUTO_INCREMENT COMMENT '明细ID',
`order_id` int NOT NULL COMMENT '订单ID',
`product_id` int NOT NULL COMMENT '产品ID',
`quantity` int NOT NULL COMMENT '销售数量',
`unit_price` decimal(10,2) NOT NULL COMMENT '销售时的单价',
`line_total` decimal(12,2) NOT NULL COMMENT '行小计(quantity * unit_price)',
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`detail_id`),
UNIQUE KEY `uk_order_product` (`order_id`,`product_id`),
KEY `product_id` (`product_id`)
) COMMENT='销售订单明细表';
四、自动提取 MySQL 表结构
我们可以编写一个函数,动态地连接数据库,读取所有表名以及它们的字段信息,并智能识别出主键(PRI)和外键候选(MUL)。这保证了图谱能与数据库结构同步更新。
def get_tables_from_database(connection):
"""自动扫描数据库,提取表名、字段、主键/外键标记"""
tables = {}
with connection.cursor() as cursor:
cursor.execute("SHOW TABLES")
table_names = [row[0] for row in cursor.fetchall()]
for table_name in table_names:
cursor.execute(f"SHOW COLUMNS FROM {table_name}")
columns = cursor.fetchall()
fields = []
for col in columns:
field_name = col[0]
key_type = col[3] # PRI=主键, MUL=外键候选
if key_type == "PRI":
fields.append(f"{field_name} [主键]")
elif key_type == "MUL":
fields.append(f"{field_name} [外键]")
else:
fields.append(field_name)
tables[table_name] = {"name": table_name, "fields": fields}
return tables
优势:这种方法无需手动维护表结构列表,实现了自动化感知数据库变更。
五、手动定义表间语义关系
自动提取能获得外键约束,但无法理解其中蕴含的业务逻辑。例如,customer_id 字段关联了客户和订单,但它的业务含义是“客户创建了订单”。这部分语义需要人工补充,这是提升大模型理解能力的关键。
RELATIONSHIPS = [
{
"from_table": "t_customers",
"to_table": "t_sales_orders",
"description": "客户创建销售订单",
"field_relation": "customer_id → order.customer_id",
},
{
"from_table": "t_sales_orders",
"to_table": "t_order_details",
"description": "订单包含多个明细项",
"field_relation": "order_id → detail.order_id",
},
{
"from_table": "t_products",
"to_table": "t_order_details",
"description": "产品属于订单明细",
"field_relation": "product_id → detail.product_id",
},
# 您可以继续添加其他业务关系,即使它们没有直接的数据库外键约束
# {
# "from_table": "t_user",
# "to_table": "t_user_qa_record",
# "description": "用户产生问答记录",
# "field_relation": "id → record.user_id",
# },
]
建议:description 字段使用自然语言描述,这能极大地帮助大模型理解关系的实际含义。这个过程是构建高质量语义图谱的人工智能部分,对最终效果影响显著。
六、将结构写入 Neo4j 图数据库
6.1 创建唯一性约束
首先,为确保数据一致性,为Table节点的name属性创建唯一约束,避免重复创建同名节点。
def create_constraints(graph):
graph.run("CREATE CONSTRAINT IF NOT EXISTS FOR (t:Table) REQUIRE t.name IS UNIQUE")
print("✅ 节点唯一约束已创建")
6.2 创建表节点
将每张数据表创建为一个Table节点,并将字段列表作为节点的一个属性存储起来。
def create_table_nodes(graph, tables):
for table_name, info in tables.items():
graph.run(
"""
MERGE (t:Table {name: $name})
SET t.label = $label, t.fields = $fields
""",
name=info["name"],
label=table_name,
fields=info["fields"]
)
print(f"✅ 表节点创建完成!共创建 {len(tables)} 个表节点")
6.3 创建表关系
根据我们定义的 RELATIONSHIPS 列表,在对应的Table节点之间创建带属性的 REFERENCES 关系。
def create_table_relationships(graph):
for rel in RELATIONSHIPS:
graph.run(
"""
MATCH (from:Table {name: $from_table})
MATCH (to:Table {name: $to_table})
MERGE (from)-[r:REFERENCES {
description: $description,
field_relation: $field_relation
}]->(to)
""",
from_table=rel["from_table"],
to_table=rel["to_table"],
description=rel["description"],
field_relation=rel["field_relation"]
)
print(f"✅ 表关系创建完成!共创建 {len(RELATIONSHIPS)} 条关系")
七、主函数:一键构建语义图谱
将所有步骤串联起来,形成一个完整的自动化构建流程。
def main():
print("🚀 开始构建 Text2SQL 语义图谱...")
mysql_conn = connect_mysql()
neo4j_graph = connect_neo4j()
try:
# 步骤1:获取表结构
tables = get_tables_from_database(mysql_conn)
print(f"📊 检测到 {len(tables)} 张数据表")
# 步骤2:清空旧数据(生产环境谨慎操作,建议按需更新)
print("🗑️ 清空 Neo4j 中的旧数据...")
neo4j_graph.delete_all()
# 步骤3:创建约束
create_constraints(neo4j_graph)
# 步骤4:创建表节点
create_table_nodes(neo4j_graph, tables)
# 步骤5:创建表关系
create_table_relationships(neo4j_graph)
print("🎉 图谱构建完成!现在可用 Cypher 查询或供大模型调用")
except Exception as e:
print(f"❌ 构建失败: {str(e)}")
raise
finally:
mysql_conn.close()
print("🔌 数据库连接已关闭")
if __name__ == "__main__":
main()
八、应用:在图谱中查询关系
构建好图谱后,我们可以方便地使用 Cypher 查询语言来检索表间关系,并将这些结构化的关系信息作为上下文提供给大模型。
from py2neo import Graph
import os
def get_table_relationships():
"""
从 Neo4j 图数据库中查询预定义表之间的 REFERENCES 关系。
:return: list of dict,每个 dict 包含 from_table, relationship, to_table
"""
# 从环境变量读取数据库配置
NEO4J_URI = os.getenv("NEO4J_URI", "bolt://localhost:7687")
NEO4J_USER = os.getenv("NEO4J_USER", "neo4j")
NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD", "neo4j123")
# 指定要查询的表名
table_names = ["t_customers", "t_sales_orders", "t_products", "t_order_details"]
# 连接图数据库
graph = Graph(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
# Cypher 查询语句
query = """
MATCH (t1:Table)-[r:REFERENCES]->(t2:Table)
WHERE t1.name IN $table_names
AND t2.name IN $table_names
RETURN
t1.name AS from_table,
r.field_relation AS relationship,
t2.name AS to_table
ORDER BY t1.name
"""
# 执行查询
try:
result = graph.run(query, table_names=table_names).data()
print("查询结果:", result)
return result
except Exception as e:
print(f"[ERROR] 查询图数据库失败: {e}")
return []
# 调用函数
relationships = get_table_relationships()
执行上述函数后,你将获得类似下面的结构化输出,这些信息可以直接拼接到大模型的提示词中,作为“已知的数据库关系知识”:
[
{
"from_table": "t_customers",
"relationship": "customer_id → order.customer_id",
"to_table": "t_sales_orders"
},
{
"from_table": "t_products",
"relationship": "product_id → detail.product_id",
"to_table": "t_order_details"
},
{
"from_table": "t_sales_orders",
"relationship": "order_id → detail.order_id",
"to_table": "t_order_details"
}
]
九、如何集成到实际项目中?
本文演示了语义图谱的构建核心流程。在实际的大型应用中,这个图谱可以作为RAG(检索增强生成)系统背后的“结构化知识库”。
当用户提问时(例如“某客户买了哪些产品?”):
- 检索:首先从问题中提取关键实体(如“客户”、“产品”),或使用嵌入模型将问题向量化,在图谱中检索相关的
Table 节点和 REFERENCES 关系路径。
- 构建上下文:将检索到的表结构(字段)和精准的关系路径(如
客户 -> 创建 -> 订单 -> 包含 -> 明细 <- 属于 <- 产品)格式化后,作为上下文提供给大模型。
- 生成SQL:大模型基于这些精准、无歧义的结构信息,生成正确的 JOIN 查询,例如
SELECT p.product_name FROM t_customers c JOIN t_sales_orders o ON ...。
这种方式有效解决了传统Text2SQL中因表关系模糊导致的“幻觉”或“瞎猜”问题。
十、开源项目参考
如果你正在寻找一个已经集成了类似功能,且支持全链路开发的大模型应用框架,可以参考一些优秀的开源实战项目。这类项目通常提供了从后端到前端的完整解决方案,能帮助你快速搭建原型。
例如,一些项目可能具备以下亮点:
- ✅ 集成 MCP 多智能体架构
- ✅ 支持 LangChain / LlamaIndex / Ollama / vLLM / Neo4j
- ✅ 前后端分离,现代化技术栈(如Vue3 + TypeScript)
- ✅ 内置图表问答、表格问答等常见应用场景
- ✅ 支持对接主流 RAG 系统与 Text2SQL 引擎
- ✅ 轻量级高性能后端,便于二次开发和部署
你可以通过在数据库/中间件/技术栈相关的技术社区,如 云栈社区,搜索“Text2SQL”、“Neo4j”、“大模型应用”等关键词,发现更多实践讨论和开源项目资源。
总结
利用 Neo4j 构建语义图谱来优化 Text2SQL,其本质是为大模型注入结构化的领域知识。它将冰冷的数据库元数据(DDL)和隐含的业务逻辑,转化为了富含语义的、可被图算法检索和遍历的知识网络。
这种方法不仅提升了SQL生成的准确性,还增强了整个系统的可解释性——我们总能通过查询图谱来追溯大模型做出决策的依据。对于构建可靠、可控的企业级大模型数据应用来说,这是一个值得深入探索的技术方向。
 发表于 2026-4-21 21:49:36
|
查看: 196|
回复: 0
发表于 2026-4-21 21:49:36
|
查看: 196|
回复: 0
