前言
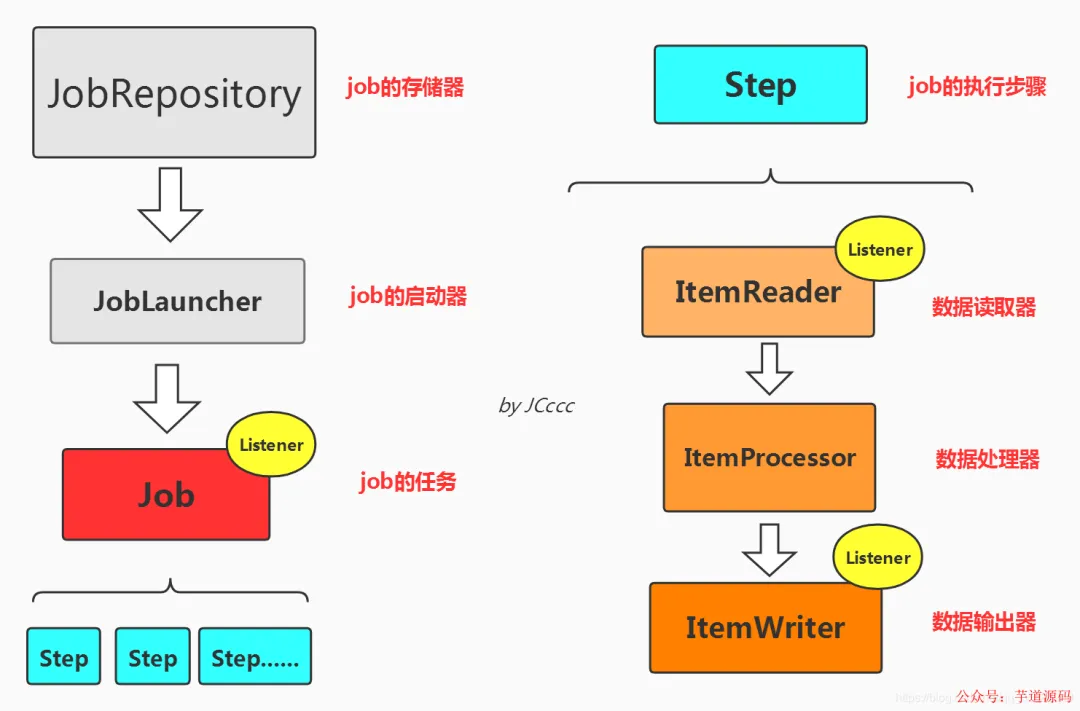
Spring Batch 是一个基于 Spring 的成熟、轻量级批处理框架,专为大规模数据处理场景设计。它不是定时调度框架(如 Quartz),但可与之协同;其核心价值在于提供可控执行、事务粒度管理、失败重试、跳过容错、进度追踪与状态持久化等企业级能力。
为什么说它“方便使用”?——深度集成 Spring 生态,配置即编码,组件职责清晰,学习曲线平缓。
为什么说它“较健全”?——开箱即用的 JobRepository、JobLauncher、Step、ItemReader/Processor/Writer 等抽象,覆盖了批处理全生命周期的关键痛点。
本文将结合真实业务场景,手把手带你完成两个典型任务:
- ✅ 从
bloginfo.csv 文件批量读取 8 万余条数据 → 业务逻辑处理 → 写入 MySQL 表
- ✅ 从数据库
bloginfo 表按条件查询 → 动态参数化处理 → 写入新表 bloginfonew
所有代码均基于 Spring Boot 2.7.x + MyBatis + HikariCP,兼容主流生产环境,拒绝“玩具示例”。
💡 提示:文中涉及的 druid 连接池与 MyBatisCursorItemReader 存在兼容性问题(详见后文排障章节),我们已给出可落地的 HikariCP 替代方案。
数据准备:建表与样例数据
首先创建用于存储和读取的数据库表 bloginfo:
CREATE TABLE `bloginfo` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`blogAuthor` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '博客作者标识',
`blogUrl` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '博客链接',
`blogTitle` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '博客标题',
`blogItem` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '博客栏目',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 89031 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
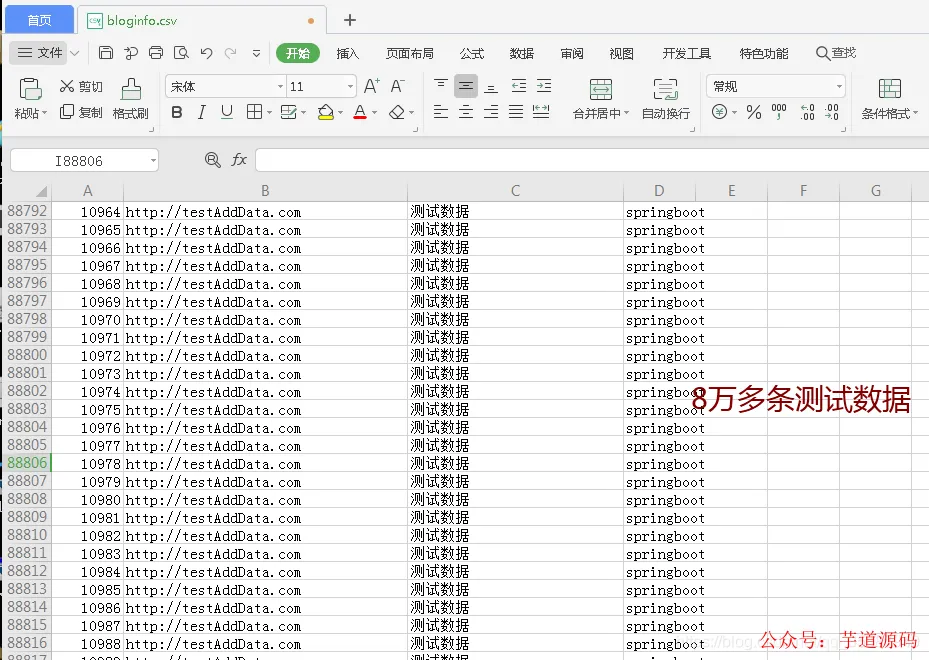
同时准备一份 bloginfo.csv 文件(约 8 万行),结构如下(Excel 截图示意):
项目依赖与基础配置
Maven 依赖(pom.xml)
确保引入以下核心依赖(注意版本兼容性):
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Spring Batch 核心 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<!-- Hibernate Validator(用于数据校验) -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>6.0.7.Final</version>
</dependency>
<!-- MyBatis 整合 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- ⚠️ 注意:druid 在 MyBatisCursorItemReader 场景下存在兼容问题,此处暂不启用 -->
<!--
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.18</version>
</dependency>
-->
Spring Boot 配置(application.yml)
关键点说明:
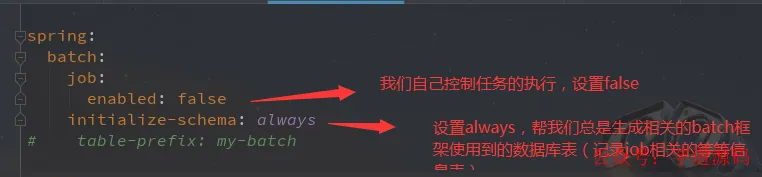
spring.batch.job.enabled: false:禁用自动启动 Job,由我们通过 JobLauncher.run() 显式触发;spring.batch.initialize-schema: always:每次启动自动初始化 Batch 元数据表(如 batch_job_execution);- 数据源使用 Spring Boot 2.x 默认推荐的 HikariCP(无需额外依赖,开箱即用);
spring:
batch:
job:
enabled: false
initialize-schema: always
# table-prefix: my-batch # 如需自定义前缀可取消注释
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/hellodemo?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&zeroDateTimeBehavior=convertToNull
driver-class-name: com.mysql.cj.jdbc.Driver
# HikariCP 默认配置已足够,无需显式声明;如需调优可参考:
# hikari:
# connection-timeout: 30000
# maximum-pool-size: 20
server:
port: 8665
核心实体与 Mapper 层
POJO:BlogInfo.java
/**
* @Author : JCccc
* @Description :
**/
public class BlogInfo {
private Integer id;
private String blogAuthor;
private String blogUrl;
private String blogTitle;
private String blogItem;
@Override
public String toString() {
return "BlogInfo{" +
"id=" + id +
", blogAuthor='" + blogAuthor + '\'' +
", blogUrl='" + blogUrl + '\'' +
", blogTitle='" + blogTitle + '\'' +
", blogItem='" + blogItem + '\'' +
'}';
}
public Integer getId() { return id; }
public void setId(Integer id) { this.id = id; }
public String getBlogAuthor() { return blogAuthor; }
public void setBlogAuthor(String blogAuthor) { this.blogAuthor = blogAuthor; }
public String getBlogUrl() { return blogUrl; }
public void setBlogUrl(String blogUrl) { this.blogUrl = blogUrl; }
public String getBlogTitle() { return blogTitle; }
public void setBlogTitle(String blogTitle) { this.blogTitle = blogTitle; }
public String getBlogItem() { return blogItem; }
public void setBlogItem(String blogItem) { this.blogItem = blogItem; }
}
MyBatis Mapper 接口(注解方式)
import com.example.batchdemo.pojo.BlogInfo;
import org.apache.ibatis.annotations.*;
import java.util.List;
import java.util.Map;
/**
* @Author : JCccc
* @Description :
**/
@Mapper
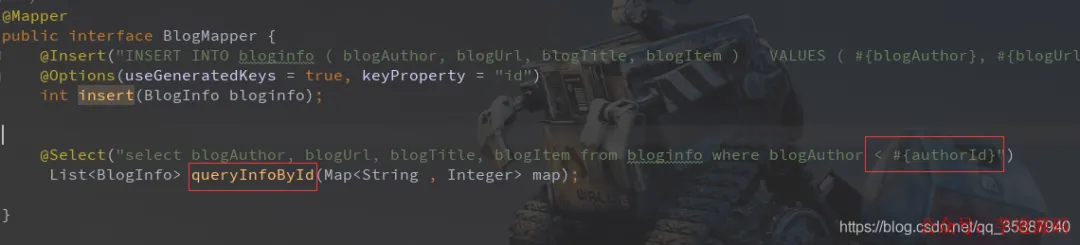
public interface BlogMapper {
@Insert("INSERT INTO bloginfo ( blogAuthor, blogUrl, blogTitle, blogItem ) VALUES ( #{blogAuthor}, #{blogUrl}, #{blogTitle}, #{blogItem}) ")
@Options(useGeneratedKeys = true, keyProperty = "id")
int insert(BlogInfo bloginfo);
@Select("select blogAuthor, blogUrl, blogTitle, blogItem from bloginfo where blogAuthor < #{authorId}")
List<BlogInfo> queryInfoById(Map<String, Integer> map);
}
Spring Batch 核心配置类(MyBatchConfig.java)
使用 @Configuration + @EnableBatchProcessing 启用批处理支持:
@Configuration
@EnableBatchProcessing
public class MyBatchConfig {
private Logger logger = LoggerFactory.getLogger(MyBatchConfig.class);
// ======== JobRepository:Job 元数据存储与事务管理 ========
@Bean
public JobRepository myJobRepository(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception {
JobRepositoryFactoryBean jobRepositoryFactoryBean = new JobRepositoryFactoryBean();
jobRepositoryFactoryBean.setDatabaseType("mysql");
jobRepositoryFactoryBean.setTransactionManager(transactionManager);
jobRepositoryFactoryBean.setDataSource(dataSource);
return jobRepositoryFactoryBean.getObject();
}
// ======== JobLauncher:Job 执行入口 ========
@Bean
public SimpleJobLauncher myJobLauncher(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(myJobRepository(dataSource, transactionManager));
return jobLauncher;
}
// ======== Job:定义一个完整批处理任务 ========
@Bean
public Job myJob(JobBuilderFactory jobs, Step myStep) {
return jobs.get("myJob")
.incrementer(new RunIdIncrementer())
.flow(myStep)
.end()
.listener(myJobListener())
.build();
}
// ======== Job 监听器 ========
@Bean
public MyJobListener myJobListener() {
return new MyJobListener();
}
// ======== Step:核心执行单元,串联 Reader → Processor → Writer ========
@Bean
public Step myStep(StepBuilderFactory stepBuilderFactory,
ItemReader<BlogInfo> reader,
ItemWriter<BlogInfo> writer,
ItemProcessor<BlogInfo, BlogInfo> processor) {
return stepBuilderFactory
.get("myStep")
.<BlogInfo, BlogInfo>chunk(6500) // 每次处理 6500 条后提交事务
.reader(reader)
.faultTolerant()
.retryLimit(3).retry(Exception.class)
.skip(Exception.class).skipLimit(2)
.listener(new MyReadListener())
.processor(processor)
.writer(writer)
.faultTolerant()
.skip(Exception.class).skipLimit(2)
.listener(new MyWriteListener())
.build();
}
}

场景一:CSV 文件批处理(FlatFileItemReader)
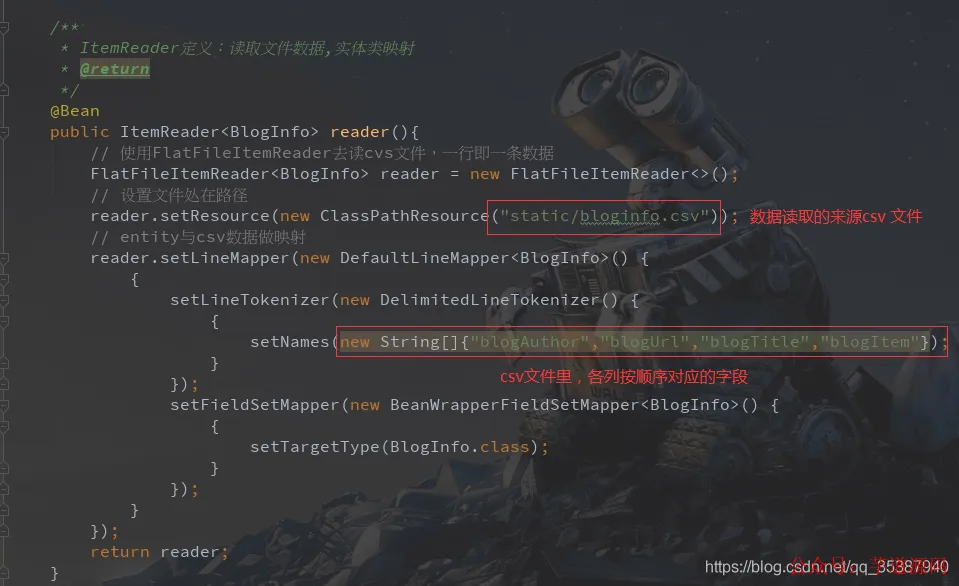
ItemReader:读取 CSV 并映射为 BlogInfo
@Bean
public ItemReader<BlogInfo> reader() {
FlatFileItemReader<BlogInfo> reader = new FlatFileItemReader<>();
// 指定 classpath 下文件路径
reader.setResource(new ClassPathResource("static/bloginfo.csv"));
// 定义字段映射规则
reader.setLineMapper(new DefaultLineMapper<BlogInfo>() {{
setLineTokenizer(new DelimitedLineTokenizer() {{
setNames(new String[]{"blogAuthor", "blogUrl", "blogTitle", "blogItem"});
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<BlogInfo>() {{
setTargetType(BlogInfo.class);
}});
}});
return reader;
}
ItemProcessor:简单业务处理(字符串替换)
@Bean
public ItemProcessor<BlogInfo, BlogInfo> processor() {
MyItemProcessor myItemProcessor = new MyItemProcessor();
myItemProcessor.setValidator(myBeanValidator());
return myItemProcessor;
}
// 自定义处理器逻辑
public class MyItemProcessor extends ValidatingItemProcessor<BlogInfo> {
@Override
public BlogInfo process(BlogInfo item) throws ValidationException {
super.process(item); // 触发校验器
if ("springboot".equals(item.getBlogItem())) {
item.setBlogTitle("springboot 系列还请看看我Jc");
} else {
item.setBlogTitle("未知系列");
}
return item;
}
}
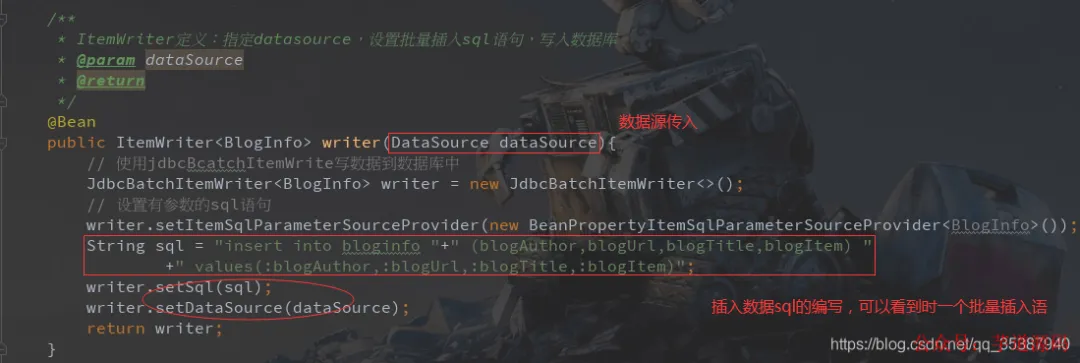
ItemWriter:批量插入数据库(JdbcBatchItemWriter)
@Bean
public ItemWriter<BlogInfo> writer(DataSource dataSource) {
JdbcBatchItemWriter<BlogInfo> writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
String sql = "insert into bloginfo " +
"(blogAuthor,blogUrl,blogTitle,blogItem) " +
"values(:blogAuthor,:blogUrl,:blogTitle,:blogItem)";
writer.setSql(sql);
writer.setDataSource(dataSource);
return writer;
}
场景二:数据库查询批处理(MyBatisCursorItemReader)
⚠️ 关键避坑:MyBatisCursorItemReader 与 Druid 连接池存在 SQLFeatureNotSupportedException 兼容问题(见后文日志)。解决方案:切换至 HikariCP(Spring Boot 2.x 默认)。
新增 Job 与 Step(复用大部分已有组件)
@Bean
public Job myJobNew(JobBuilderFactory jobs, Step stepNew) {
return jobs.get("myJobNew")
.incrementer(new RunIdIncrementer())
.flow(stepNew)
.end()
.listener(myJobListener())
.build();
}
@Bean
public Step stepNew(StepBuilderFactory stepBuilderFactory,
MyBatisCursorItemReader<BlogInfo> itemReaderNew,
ItemWriter<BlogInfo> writerNew,
ItemProcessor<BlogInfo, BlogInfo> processorNew) {
return stepBuilderFactory
.get("stepNew")
.<BlogInfo, BlogInfo>chunk(6500)
.reader(itemReaderNew)
.faultTolerant()
.retryLimit(3).retry(Exception.class)
.skip(Exception.class).skipLimit(10)
.listener(new MyReadListener())
.processor(processorNew)
.writer(writerNew)
.faultTolerant()
.skip(Exception.class).skipLimit(2)
.listener(new MyWriteListener())
.build();
}
ItemReader:动态参数化数据库查询
@Autowired
private SqlSessionFactory sqlSessionFactory;
@Bean
@StepScope // 必须!使 JobParameters 参数在 Step 启动时注入
public MyBatisCursorItemReader<BlogInfo> itemReaderNew(@Value("#{jobParameters[authorId]}") String authorId) {
System.out.println("开始查询数据库");
MyBatisCursorItemReader<BlogInfo> reader = new MyBatisCursorItemReader<>();
reader.setQueryId("com.example.batchdemo.mapper.BlogMapper.queryInfoById");
reader.setSqlSessionFactory(sqlSessionFactory);
Map<String, Object> map = new HashMap<>();
map.put("authorId", Integer.valueOf(authorId));
reader.setParameterValues(map);
return reader;
}
![代码截图:高亮 `@StepScope` 和 `@Value("#{jobParameters[authorId]}")`,右侧中文注释“从job处传参,实现动态SQL”](https://static1.yunpan.plus/attachment/727f164ae73eb8a5.webp)
对应 Mapper 方法:
@Select("select blogAuthor, blogUrl, blogTitle, blogItem from bloginfo where blogAuthor < #{authorId}")
List<BlogInfo> queryInfoById(Map<String, Integer> map);
ItemProcessor:按 authorId 分段处理标题
@Bean
public ItemProcessor<BlogInfo, BlogInfo> processorNew() {
MyItemProcessorNew csvItemProcessor = new MyItemProcessorNew();
csvItemProcessor.setValidator(myBeanValidator());
return csvItemProcessor;
}
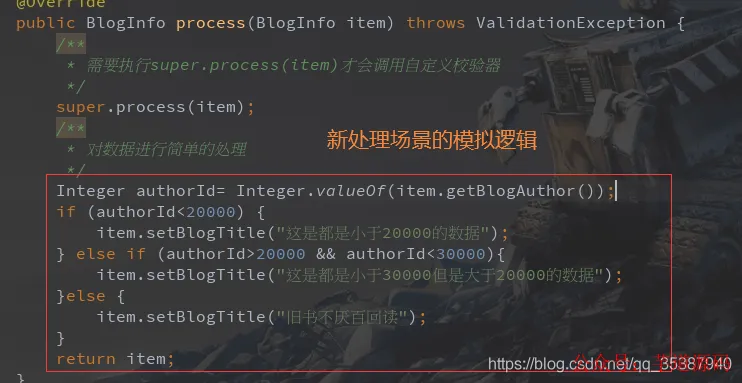
public class MyItemProcessorNew extends ValidatingItemProcessor<BlogInfo> {
@Override
public BlogInfo process(BlogInfo item) throws ValidationException {
super.process(item);
Integer authorId = Integer.valueOf(item.getBlogAuthor());
if (authorId < 20000) {
item.setBlogTitle("这是都是小于20000的数据");
} else if (authorId >= 20000 && authorId < 30000) {
item.setBlogTitle("这是都是小于30000但是大于20000的数据");
} else {
item.setBlogTitle("旧书不厌百回读");
}
return item;
}
}
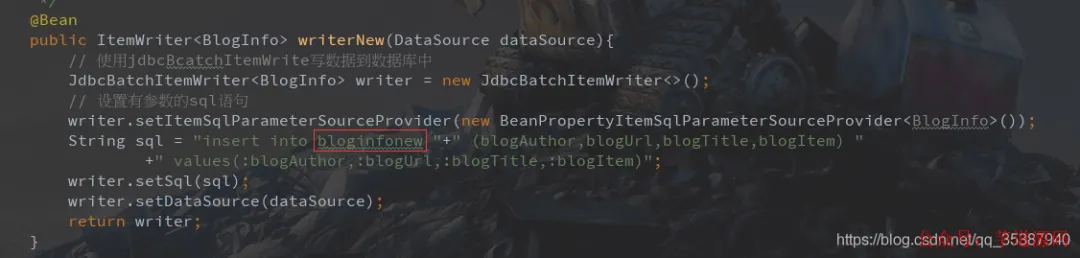
ItemWriter:写入新表 bloginfonew
@Bean
public ItemWriter<BlogInfo> writerNew(DataSource dataSource) {
JdbcBatchItemWriter<BlogInfo> writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
String sql = "insert into bloginfonew " +
"(blogAuthor,blogUrl,blogTitle,blogItem) " +
"values(:blogAuthor,:blogUrl,:blogTitle,:blogItem)";
writer.setSql(sql);
writer.setDataSource(dataSource);
return writer;
}
启动与调用接口
Controller 触发 Job
@RestController
public class TestController {
@Autowired
SimpleJobLauncher jobLauncher;
@Autowired
Job myJob;
@Autowired
Job myJobNew;
@GetMapping("testJob")
public void testJob() throws JobParametersInvalidException, JobExecutionException {
JobParameters jobParameters = new JobParametersBuilder().toJobParameters();
jobLauncher.run(myJob, jobParameters);
}
@GetMapping("testJobNew")
public void testJobNew(@RequestParam("authorId") String authorId)
throws JobParametersInvalidException, JobExecutionException {
JobParameters jobParametersNew = new JobParametersBuilder()
.addLong("timeNew", System.currentTimeMillis())
.addString("authorId", authorId)
.toJobParameters();
jobLauncher.run(myJobNew, jobParametersNew);
}
}
启动验证与结果查看
-
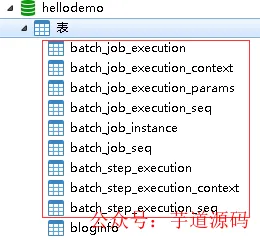
启动应用后,观察控制台日志,确认 batch_* 元数据表已自动创建:
-
调用 /testJob,查看日志是否输出 COMPLETED:
![终端日志截图:包含 `[COMPLETED]` 状态及 `Job [FlowJob] launched...` 信息](https://static1.yunpan.plus/attachment/5d7fc28bd5528664.webp)
-
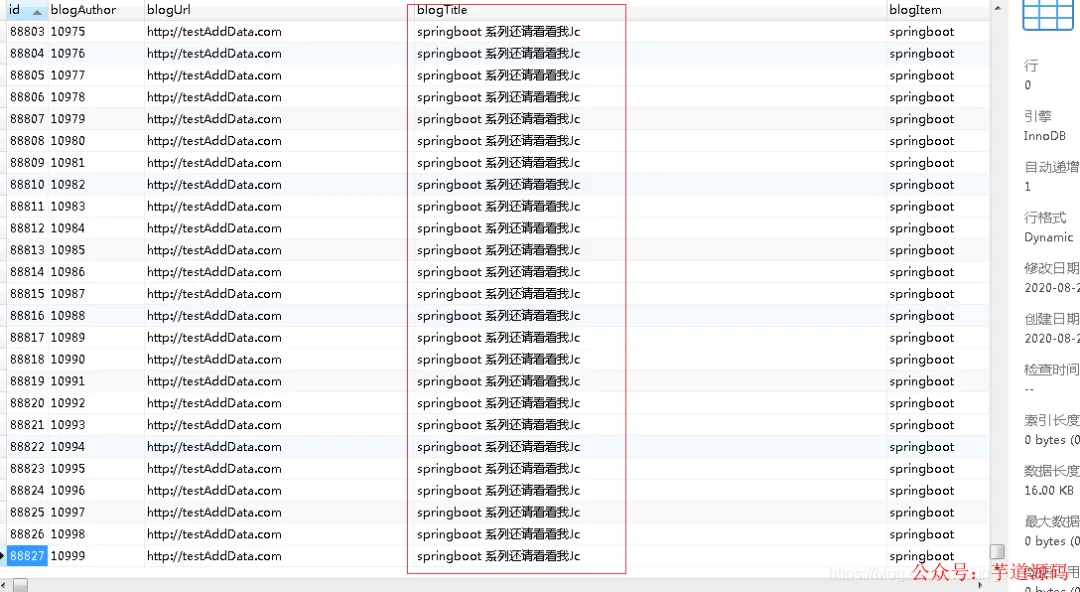
查看 bloginfo 表数据是否按预期处理并写入:
-
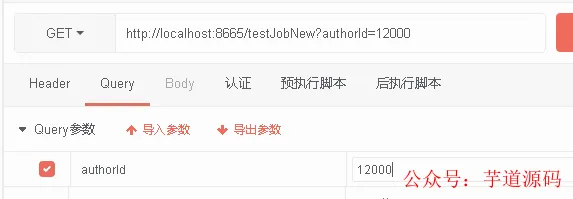
调用 /testJobNew?authorId=12000,验证数据库查询场景:
- ✅ 成功时:日志显示
[COMPLETED],bloginfonew 表中数据按 authorId 分段生成标题;
- ❌ 失败时(若误用 Druid):报
java.sql.SQLFeatureNotSupportedException(见下图);
![错误日志截图:红色高亮 `SQLFeatureNotSupportedException` 及 `[FAILED]` 状态](https://static1.yunpan.plus/attachment/76d1251cfdfc8349.webp)
关键排障:Druid 兼容性问题与 HikariCP 方案
问题现象
当使用 MyBatisCursorItemReader 时,若连接池为 Druid(druid-spring-boot-starter),会抛出:
Caused by: java.sql.SQLFeatureNotSupportedException: null
at com.alibaba.druid.pool.DruidPooledStatement.executeQuery(...)
根本原因
MyBatisCursorItemReader 底层调用 SqlSession.selectCursor(),依赖 JDBC ResultSet.TYPE_FORWARD_ONLY + CONCUR_READ_ONLY 游标类型,而 Druid 对该组合支持不完善。
解决方案(推荐)
✅ 移除 Druid 依赖,使用 Spring Boot 2.x 默认 HikariCP(性能更优、官方首选):
- 删除
pom.xml 中 Druid 依赖;
application.yml 中删除 datasource.druid.* 配置;- 保持
spring.datasource.* 基础配置即可(HikariCP 自动装配)。
📌 官方文档明确指出:“We prefer HikariCP for its performance and concurrency. If HikariCP is available, we always choose it.”
如需自定义 HikariCP 参数,可添加:
spring:
datasource:
hikari:
connection-timeout: 30000
maximum-pool-size: 20
minimum-idle: 5
总结与延伸
本文完整实现了 Spring Batch 在 Spring Boot 2.x 环境下的两大核心场景:
- ✅ 文件驱动批处理:
FlatFileItemReader + CSV → 业务处理 → DB 写入;
- ✅ 数据库驱动批处理:
MyBatisCursorItemReader + 动态参数 → 分段处理 → 新表写入;
同时解决了生产环境中常见的 Druid 兼容性陷阱,给出了经过验证的 HikariCP 替代方案,保障稳定性与性能。
Spring Batch 的强大不仅在于功能丰富,更在于其可扩展性:
- 通过
@StepScope 实现 Step 级别 Bean 生命周期与参数注入;
- 通过
faultTolerant() 配置 retry/skip 策略应对脏数据;
- 通过
Chunk 机制精细控制事务边界与内存占用;
- 通过
JobExecutionListener/ItemReadListener 等监听器实现可观测性。
如需进一步深入,可参考云栈社区的 Java 技术板块,获取更多关于 Spring Boot、数据库/中间件 及 开源实战 的系统化内容。
 发表于 2026-2-14 03:03:10
|
查看: 228|
回复: 0
发表于 2026-2-14 03:03:10
|
查看: 228|
回复: 0
