你是否曾在准备复现AI论文时,被pip install torch后那数GB的下载量劝退?是否曾为CUDA版本、环境配置和各种Segmentation fault而感到焦头烂额?
在开源世界的某个角落,有一个名为tinygrad的项目,正以一种近乎“暴力”的简洁,挑战着深度学习框架的复杂性认知。它的核心代码仅约2000行,却完整实现了自动微分、JIT编译,并能运行LLaMA和Stable Diffusion等模型。这不仅仅是一个框架,更像是对现代软件工程“臃肿化”趋势的一次极简主义反思。它的作者是George Hotz(geohot),那位曾破解iPhone和PS3的天才黑客,Comma.ai的创始人,一个对“黑箱”和冗余代码深恶痛绝的极客。
架构对比:为何tinygrad如此不同?
传统框架如PyTorch或TensorFlow,其计算路径如同精密的“俄罗斯套娃”:从Python调用到C++封装,再到CUDA内核,层层叠叠。这种设计带来了性能与便利,但也筑起了理解底层运作的高墙。
而tinygrad选择了一条截然不同的路:Python all the way down。它几乎没有复杂的C++底层(除少量运行时接口),核心计算逻辑全部用Python清晰呈现。这意味着,你可以轻松追溯任何函数的源头,彻底理解从高级API到硬件指令的完整链条。这种极致的透明性,是其在教育价值和启发意义上最闪耀的部分。
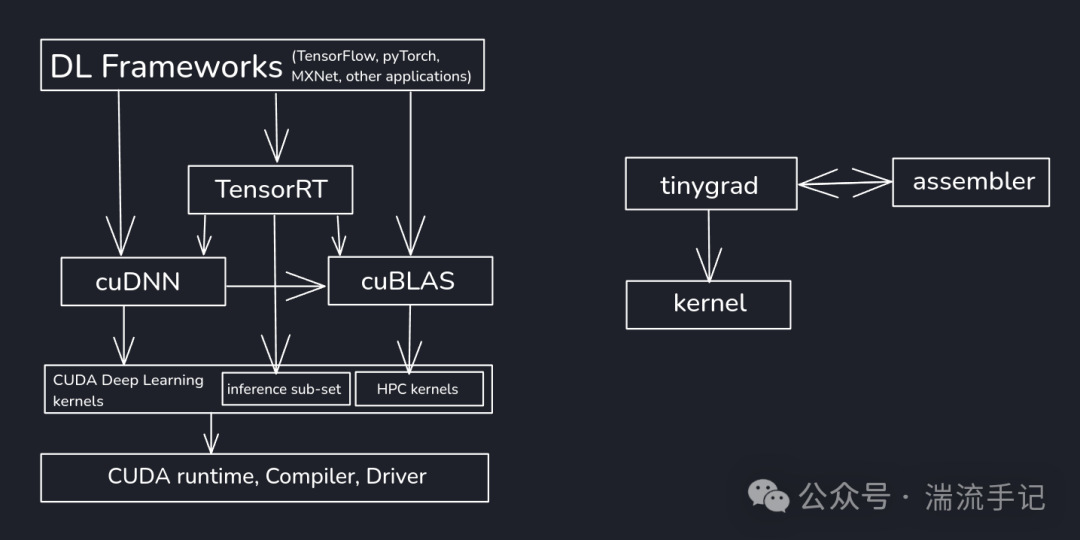
上图直观对比了传统框架(左)与tinygrad(右)的架构差异。左边是复杂的多层抽象,右边则是直达内核的简洁路径。
核心思想:懒惰与融合
tinygrad的魅力很大程度上源于其“懒惰”(Lazy Evaluation)的设计哲学。当你写下 a + b 这样的操作时,tinygrad并不会立即计算。它只是记录下这个操作意图,构建一个计算图。直到你显式调用.realize()方法时,它才开始真正的计算工作。
这种“懒惰”带来了一个关键优势:编译器拥有了全局视野。它可以审视你定义的一系列连续操作(例如加法、乘法、激活函数),然后将其融合(Fuse) 成一个单一的、高效的GPU内核。这就好比优化了工作流程,从“跑多次腿办零碎事”变成了“一次出门办好所有事”。算子融合是高性能计算的基石之一,而tinygrad用极其精简的代码实现了这一机制。
动手实践:从安装到运行你的第一个内核
理论再好,不如动手一试。让我们跟随极客的仪式,从源码开始。
1. 环境准备
建议直接从源码安装,以获取最新的特性。
- Python 3.8+
- 支持OpenCL的显卡(包括Intel/AMD核显,或Apple M系列芯片)或CUDA环境的NVIDIA显卡。
2. 核心体验:观察代码生成
首先,克隆仓库并安装依赖:
# 克隆仓库
git clone https://github.com/tinygrad/tinygrad.git
cd tinygrad
# 安装依赖
python3 -m pip install -e .
接下来,我们创建一个简单的矩阵乘法程序,并让它展示生成的底层代码。新建一个文件 run_lazy.py:
from tinygrad import Tensor
# 定义两个1024x1024的惰性张量,此时并无实际计算发生
N = 1024
a = Tensor.rand(N, N)
b = Tensor.rand(N, N)
# .realize() 是触发实际计算的关键
# DEBUG=3 环境变量将打印出生成的内核代码
c = (a.dot(b)).realize()
print(c.numpy()) # 将结果转为numpy数组输出,验证计算
使用以下命令运行,见证“代码生成”的奇迹:
DEBUG=3 python3 run_lazy.py
关键点解析:
Tensor.rand(N, N): 在tinygrad中,这创建了一个代表随机张量的惰性节点,而非立即分配内存并填充随机数。.realize(): 这是整个流程的灵魂。它命令JIT编译器将累积的操作图进行优化,并生成针对当前硬件(GPU/CPU)的高效执行代码。DEBUG=3: 这是tinygrad提供的强大调试工具。通过设置环境变量,你可以直接看到框架为你的Python操作所生成的底层C/GPU代码。这无疑是学习编译器与GPU编程的绝佳窗口。其他级别如DEBUG=1显示执行时间,DEBUG=4则展示更底层的汇编信息。
3. 进阶实战:构建与训练一个微型神经网络
如果以为tinygrad只能做基础运算,那就错了。它的API设计借鉴了PyTorch的风格,使得构建神经网络变得非常直观。以下是一个简单的MNIST分类网络示例:
from tinygrad import Tensor, nn
class TinyNet:
def __init__(self):
# 使用Kaiming初始化权重
self.l1 = Tensor.kaiming_uniform(784, 128)
self.l2 = Tensor.kaiming_uniform(128, 10)
def __call__(self, x: Tensor) -> Tensor:
# 前向传播:展平 -> 线性层 -> ReLU -> 线性层
# 注意,此处仍未触发实际计算
return x.flatten(1).dot(self.l1).relu().dot(self.l2)
# 初始化模型和优化器
model = TinyNet()
optim = nn.optim.Adam([model.l1, model.l2], lr=0.001)
# 生成模拟数据 (Batch Size=32, 图像尺寸28x28)
x = Tensor.rand(32, 1, 28, 28)
y = Tensor.randint(32, high=10)
# 开启训练模式
Tensor.training = True
# 简易训练循环
for i in range(10):
optim.zero_grad() # 梯度清零
# 前向计算并计算损失
loss = model(x).sparse_categorical_crossentropy(y).backward()
optim.step() # 更新权重
# .item() 会触发计算并返回Python标量数值
print(f"Step {i}, Loss: {loss.item()}")
实践注意事项:
- 后端检查:tinygrad支持多种后端。运行
from tinygrad import Device; print(Device.DEFAULT) 来确认当前使用的是CUDA、METAL、OpenCL还是CPU。错误的设备选择会导致性能天差地别。
- 严格的形状推导:tinygrad对张量形状的要求非常严格。若遇到
Shape mismatch错误,务必使用.shape属性仔细检查各张量的维度,其错误提示可能不如成熟框架那么详尽。
理性看待:tinygrad的定位与价值
在热情体验之后,我们必须冷静思考:tinygrad旨在取代PyTorch或TensorFlow吗?答案是否定的。
成熟的深度学习框架拥有无与伦比的生态优势:海量预训练模型、成熟的分布式训练支持、完善的部署工具链以及巨头公司的持续优化。这些是生产环境不可或缺的要素。
那么,tinygrad的价值何在?它更像是一把磨刀石和一道光:
- 卓越的教育工具:它是理解自动微分、计算图优化、GPU编程等底层概念的绝佳材料。阅读其源码比阅读大型框架源码的体验要直观得多。
- 新硬件的快速适配通道:在AI芯片百家争鸣的时代,为PyTorch移植一个新硬件后端是项浩大工程。而tinygrad的极简设计,理论上只需实现约25个核心底层算子,就能让一款新硬件跑起主流模型,这为硬件创新提供了敏捷的软件试验田。
- 对“复杂性”的反思:它证明了深度学习框架的核心逻辑可以被极度浓缩,促使我们思考在追求功能丰富的同时,是否牺牲了过多的简洁与可理解性。
结语
在这个技术快速迭变的时代,我们常常沉浸于使用高级API的便利,却与底层原理渐行渐远。tinygrad像是一个闯入者,用2000行代码的“暴力美学”,揭开了深度学习框架的神秘面纱。它可能不是你的下一个生产工具,但绝对是拓宽认知、锤炼思维的最佳学习资源之一。
探索像tinygrad这样的项目,正是云栈社区所倡导的极客精神——不满足于黑箱调用,执着于理解每一行代码背后的光芒。
参考资料
 发表于 2026-2-14 03:29:11
|
查看: 309|
回复: 0
发表于 2026-2-14 03:29:11
|
查看: 309|
回复: 0
