对于一名系统工程师而言,日常巡检或故障排查时,检查磁盘空间几乎是最高频的操作。面对一台配置复杂的物理服务器,如何快速、准确地获取存储全景图?本文将基于一套真实的物理服务器环境进行演示。
这套环境配置了双RAID阵列(RAID 10 + RAID 0,其中RAID 10配置热备盘)、LVM逻辑卷、UEFI引导,非常典型。我们将一步步解读命令输出,让你不仅能看懂数字,更能理解背后的存储架构。
存储配置概览:
- RAID阵列1(
/dev/sda):由5块物理硬盘组成的RAID 10阵列,其中1块为热备盘。实际参与读写的数据盘为4块,总可用容量约4.36T。被划分为独立的 /boot、/boot/efi、/、SWAP 分区以及一个LVM逻辑卷。
- RAID阵列2(
/dev/sdb):由单块物理硬盘组成的RAID 0阵列(JBOD直通模式),总可用容量约2.18T,整块阵列挂载于 /backup。
- LVM逻辑卷
rl-myvmdata:容量4.3T,挂载于 /myvmdata,其底层物理卷是来自RAID 10阵列剩余空间的 /dev/sda5。
注:在操作系统层面,每个RAID阵列被识别为一块虚拟磁盘(如 /dev/sda、/dev/sdb)。RAID阵列中的热备盘对操作系统完全透明,OS只能看到阵列总容量。
方法一:使用 df 命令检查已挂载空间
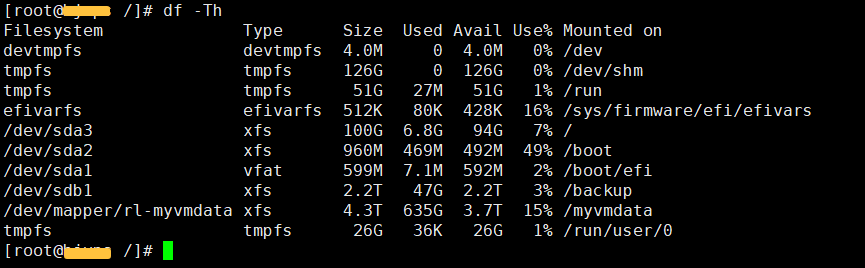
df(disk-free)是查看磁盘空间最经典、最通用的命令。在日常运维中,最推荐的用法是 df -Th。这个组合将人类易读的容量格式与文件系统类型一并呈现,信息一目了然。
[root@mywps ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs tmpfs 126G 0 126G 0% /dev/shm
tmpfs tmpfs 51G 27M 51G 1% /run
efivarfs efivarfs 512K 80K 428K 16% /sys/firmware/efi/efivars
/dev/sda3 xfs 100G 6.8G 94G 7% /
/dev/sda2 xfs 960M 469M 492M 49% /boot
/dev/sda1 vfat 599M 7.1M 592M 2% /boot/efi
/dev/sdb1 xfs 2.2T 47G 2.2T 3% /backup
/dev/mapper/rl-myvmdata xfs 4.3T 635G 3.7T 15% /myvmdata
tmpfs tmpfs 26G 36K 26G 1% /run/user/0
如何快速识别“真正的”存储设备?
物理服务器的 df 输出通常包含很多虚拟文件系统。我们只需要关注以下格式的条目,它们才是实际的RAID阵列分区或逻辑卷:
| 设备名称 |
容量 |
挂载点 |
类型 |
说明 |
/dev/sda3 |
100G |
/ |
xfs |
RAID 10分区:根分区 |
/dev/sda2 |
960M |
/boot |
xfs |
RAID 10分区:独立引导分区 |
/dev/sda1 |
599M |
/boot/efi |
vfat |
RAID 10分区:UEFI启动分区 |
/dev/sdb1 |
2.2T |
/backup |
xfs |
RAID 0整阵列:独立数据存储(JBOD) |
/dev/mapper/rl-myvmdata |
4.3T |
/myvmdata |
xfs |
LVM逻辑卷:基于RAID 10剩余空间 |
至于 devtmpfs、tmpfs、efivarfs,这些都是内存文件系统或内核接口,其容量不占用实际磁盘,巡检时可以直接忽略。
从本例输出,我们可以直接读取到这些关键信息:
-
RAID 10阵列(sda):
- 根分区
/:100G,已用6.8G(7%)—— 系统盘使用率非常健康。
- 独立
/boot 分区:960M,已用469M(49%)—— 接近一半,属于正常范围。
- 独立
/boot/efi 分区:599M,已用7.1M(2%)—— UEFI引导分区,占用很少。
- LVM卷
/myvmdata:4.3T,已用635G(15%)—— 主数据存储区,空间充裕。
- 热备盘不占用可用容量,仅在阵列中磁盘故障时自动顶替。
-
RAID 0阵列(sdb):
- 数据盘
/backup:2.2T,已用47G(3%)—— 第二组RAID阵列,目前几乎为空。
一行 df -Th,容量、类型、使用率尽收眼底,这就是它的高效之处。
方法二:使用 lsblk 查看存储设备拓扑
当你怀疑“磁盘空间神秘消失”或需要确认新加的RAID阵列是否被系统识别时,lsblk 是最可靠的命令。它以树状结构完整地呈现了所有块设备(磁盘、分区、LVM)的拓扑关系。
[root@mywps ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 4.4T 0 disk
├─sda1 8:1 0 600M 0 part /boot/efi
├─sda2 8:2 0 1G 0 part /boot
├─sda3 8:3 0 100G 0 part /
├─sda4 8:4 0 8G 0 part [SWAP]
└─sda5 8:5 0 4.3T 0 part
└─rl-myvmdata 253:0 0 4.3T 0 lvm /myvmdata
sdb 8:16 0 2.2T 0 disk
└─sdb1 8:17 0 2.2T 0 part /backup
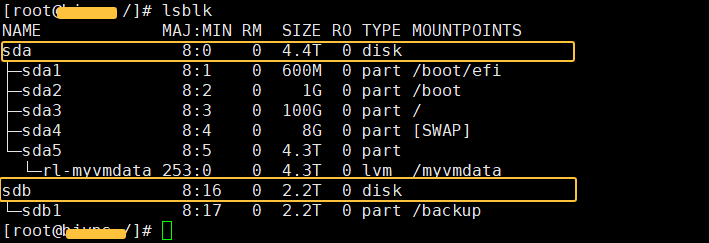
这张图清晰地告诉我们:
- 系统有两块虚拟磁盘:
sda(4.4T)和 sdb(2.2T)。
sda 被划分成5个分区(sda1-sda5),其中 sda5 作为物理卷(PV)贡献给了一个名为 rl-myvmdata 的逻辑卷(LV)。sdb 整盘作为一个分区 sdb1 使用。
关于热备盘的重要说明:
热备盘对操作系统是完全透明的。你在 lsblk 或任何系统命令的输出中都看不到它——没有独立设备,没有容量显示。它只在RAID卡的管理界面中“待命”,不参与日常读写。
方法三:使用 du 与 find 定位空间消耗源头
df 看的是分区级的总容量,而 du(disk-usage)则用于分析目录级的空间占用。两者配合,可以从宏观到微观精准定位问题。
常用 du 命令组合:
# 查看根目录下各一级目录的占用情况(限制深度,避免输出过长卡顿)
du -h --max-depth=1 / 2>/dev/null | sort -hr
# 查看指定目录(如/myvmdata)下哪个子目录占用最大
du -sh /myvmdata/* 2>/dev/null | sort -hr | head -10
# 查看当前目录的总用量
du -sh
# 直接在全盘查找超过1GB的大文件
find / -type f -size +1G -exec ls -lh {} \; 2>/dev/null
实战场景举例:
假设我们发现 /myvmdata 已经使用了635G,想快速找到是哪个目录导致的。
[root@mywps /]# cd /myvmdata
[root@mywps myvmdata]# du -sh * | sort -hr | head -10
604G vmimages
看,一下子就找到了“元凶”——vmimages 目录占用了604G。如果想更直接地定位到具体文件,可以用 find 命令:
# 查找超过100MB的大文件并按大小排序
find / -type f -size +100M -exec ls -lh {} \; 2>/dev/null | awk '{print $5, $9}' | sort -hr
这套组合拳的核心逻辑是:
df 指方向——告诉你“哪个分区快满了”。du 给路径——进一步定位到“是分区下的哪个目录最大”。find 定目标——最终揪出“具体是哪个文件占用了大量空间”。
三步递进,绝大多数磁盘空间异常问题都能迎刃而解。
总结:物理服务器磁盘空间检查标准流程
作为运维人员,在接手或巡检一台物理服务器时,可以遵循以下标准化流程:
| 步骤 |
命令示例 |
目的 |
| 1. 快速总览 |
df -Th |
查看所有已挂载分区的容量、使用率、文件系统类型。 |
| 2. 查看拓扑 |
lsblk |
掌握RAID阵列、分区、LVM的完整布局,发现未挂载空间。 |
| 3. 分析目录 |
du -sh /* 2>/dev/null \| sort -hr \| head -10 |
如果根分区告急,快速找出占用最大的顶级目录。 |
| 4. 定位文件 |
find / -type f -size +100M -exec ls -lh {} \; 2>/dev/null |
直接搜索并列出占用空间大的具体文件。 |
当然,检查空间只是运维工作的起点。当出现磁盘告警时,后续可能涉及LVM在线扩容、XFS文件系统扩展、日志文件轮转清理、乃至通过RAID卡管理界面检查磁盘健康状态和热备盘等更深入的操作。掌握这些基础而强大的命令行工具,是每一位Linux系统工程师的必备技能。如果你在实践中遇到了更复杂的存储问题,欢迎到云栈社区与更多同行交流探讨。
 发表于 2026-2-14 05:28:25
|
查看: 326|
回复: 0
发表于 2026-2-14 05:28:25
|
查看: 326|
回复: 0
