
1. 引言:预测精度与决策质量的错配
在量化投资组合管理中,我们面对的核心难题始终是如何在不同资产间分配有限的资金,以求在风险与收益间达到最佳平衡。虽然机器学习模型凭借强大的历史数据分析能力,在预测资产未来回报方面成果斐然,但金融市场固有的非线性、高噪声和频繁的体制转换特性,让构建一个真正稳健的决策系统变得异常困难。
这里存在一个根本性的矛盾:提高预测模型的统计精度,并不必然带来投资决策质量的提升。
当前主流的 预测-优化(Predict-then-Optimize, PtO) 范式通常采用两阶段分离的方式:
- 预测阶段:以最小化预测误差(如均方误差 MSE)为目标训练模型,输出资产的收益率预测值。
- 优化阶段:将这些预测值当作确定的输入,直接代入均值-方差模型或其他优化器中进行权重求解。
这种解耦的方法存在明显缺陷。它不仅忽略了预测误差对下游优化结果的非线性传导效应,而且在实际交易中(存在交易费、换手率限制等摩擦时),微小的预测偏差就可能导致最优投资权重的剧烈变化,最终产生严重偏离最优的决策。
为了解决这一核心痛点,一种名为 Smart Predict-then-Optimize (SPO) 的范式应运而生。SPO 直接将下游的投资组合优化问题嵌入到模型的训练循环之中,训练目标不再是追求预测值接近真实值,而是最小化基于预测做出的决策所带来的遗憾值(Regret)。这标志着一个重要的范式转变:从“以预测为中心”转向“以决策为中心”。
2. 文献综述:从复杂模型回归理性建模
现代投资组合理论的基石是 Markowitz 的均值-方差框架,后续研究在此基础上引入了夏普比率、CVaR 以及鲁棒优化等扩展。为了应对参数估计误差,各种统计正则化方法(如权重约束)被证明能有效提升策略的样本外表现。
在机器学习与投资组合管理的交叉领域,研究主要分为两大方向:
- 强化学习:通过与市场环境交互来最大化累积奖励,灵活性强,但其表现严重依赖于奖励函数的设计,且在信噪比极低的金融数据上,往往训练不稳定且缺乏可解释性。
- 预测-优化:利用深度学习模型直接预测优化问题的参数。然而,近期有研究指出,对于缺乏明显周期性和长程依赖的金融时间序列,复杂的 Transformer 架构未必优于简单的线性模型。
在此背景下,Elmachtoub 和 Grigas 提出了 SPO 范式,旨在利用一个凸代理损失函数来解决预测目标与决策目标不一致的问题。本文的工作正是基于此,将 SPO 范式扩展至包含交易成本和正则化的现实投资组合场景,并借助 PyEPO 库实现了端到端的建模和训练。

3. 方法论:构建决策导向的投资组合框架
本研究的核心在于构建一个统一的 SPO 训练管道。为了保持模型的可解释性并遵循奥卡姆剃刀原则,研究统一采用线性模型作为预测器,将市场特征映射为资产收益率预测值,然后输入优化层求解权重,最后通过 SPO+ 损失函数计算梯度并反向传播。
3.1 基础模型:MaxReturnSPO
这是 SPO 框架最基础的实现。
- 预测:给定特征向量
x,线性预测器输出预测收益率 r̂。
- 决策:基于预测收益率
r̂,通过求解一个线性规划问题获得投资组合权重 ŵ:
ŵ = arg max_{w∈W} w^T r̂
其中 W 为可行权重集合(通常包含全额投资、无卖空等约束)。
- 训练目标:定义在真实收益率
r 下的“全知”最优决策为 w*。为了实现端到端学习,采用 SPO+ Loss 作为真实决策遗憾的凸上界进行最小化:
ℒ_SPO+(r̂, r) = (2r̂ - r)^T w* - max_{w∈W} (2r̂ - r)^T w
这个损失函数能有效地将梯度传导回预测模型,使得模型的更新方向倾向于生成那些能带来更高组合收益的预测值,而不仅仅是逼近真实的收益数值。
3.2 引入交易成本:MaxReturn with Transaction Fee
为了贴近真实交易环境,模型显式地将交易费用纳入优化目标。
- 优化形式:令
w_prev 为上一期的持仓权重,决策变量 w 需要最大化扣除交易成本后的净收益:
max_{w∈W} w^T r̂ - γ ||w - w_prev||_1
其中 γ 为交易费系数,||w - w_prev||_1 衡量了换手率。
- SPO特性:根据 Danskin 定理,该凸优化问题的梯度可以有效计算。SPO 框架使得预测模型在训练阶段就能“感知”到“换手”带来的惩罚,从而学会避免为了微小的预期收益增益而进行昂贵的频繁调仓。
3.3 引入正则化:MaxReturn with L2 Weight Regularization
基础的 SPO 模型可能导致极端的权重集中。为了提升投资组合的分散化程度和策略稳定性,我们引入 L2 正则项。
- 优化形式:
max_{w∈W} w^T r̂ - λ ||w||_2^2
其中 λ 控制正则化强度。
- 作用机制:L2 项会惩罚单一资产的过大敞口,促使预测器生成的决策权重更加均衡。由于正则项不依赖于预测值
r̂,优化问题相对于 r̂ 依然是仿射的,这保证了 SPO+ 梯度的有效传播。
3.4 鲁棒SPO (RobustSPO)
考虑到点预测不可避免存在估计误差,我们进一步提出了鲁棒 SPO 扩展,将鲁棒优化的思想融入预测-决策管道。
- 不确定性建模:对预测收益率
r̂ 施加乘性扰动 δ,即 r̃ = r̂ ⊙ (1 + δ),其中扰动 δ 位于一个预设的不确定性集合 Δ 中。
- 训练目标:采用最坏情况遗憾最小化:
min_θ max_{δ∈Δ} ℒ_SPO+(r̂(θ) ⊙ (1 + δ), r)
在实际训练中,通过蒙特卡洛采样生成多个扰动场景,取 SPO+ 损失的最大值进行反向传播。这迫使预测模型学习生成的预测值即使在发生不利扰动时,也能导出一个相对稳健的投资组合。
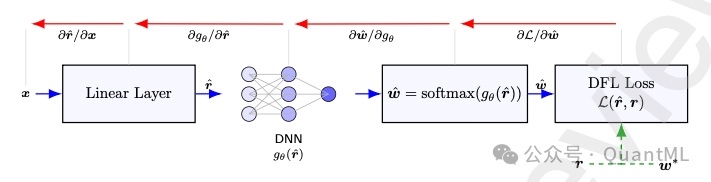
3.5 对照基准:SoftmaxDFL
为了验证显式优化结构的必要性,我们设计了一个完全可微的深度学习基准——SoftmaxDFL。
- 架构:线性层输出预测信号
r̂ → 神经网络 gθ(r̂) → Softmax 层直接输出权重 ŵ。
- 区别:它不求解任何显式的优化问题,而是直接通过神经网络拟合权重。
- 损失函数:直接优化夏普比率或负收益。
该方法虽然实现了端到端训练,但缺乏优化约束所带来的结构化先验,更像一个“黑盒”。
4. 实验设置
4.1 数据与特征
实验采用美国 ETF 市场的日度历史数据,时间跨度从 2015 年 1 月 1 日至 2025 年 1 月 1 日,覆盖了完整的市场周期。输入特征不仅包含原始价格,还包含了一系列具有经济含义的技术指标,用于描述市场状态:
- 对数收益率:捕捉短期价格变动。
- 简单移动平均与价格偏离:反映趋势跟随与均值回归特性。
- RSI 与 MACD 差值:捕捉动量与趋势动力学。
- 布林带宽度:衡量市场波动率。
- 成交量指标:反映市场参与热度。
4.2 滚动回测机制
为了模拟真实的投资流程,实验严格采用滚动窗口回测,并按月进行再平衡。
- 时间轴:在每个再平衡点
t,使用过去 12 个月 [t-12, t) 作为训练集,随后 3 个月 [t, t+3) 作为验证集进行超参数选择,最后在 t+3 月份进行样本外测试。
- 交易摩擦:所有策略在回测中均扣除 0.5% (50bps) 的双边比例交易费,费用基于换手率计算。这是一个相对严苛但现实的设定。
4.3 比较策略
实验对比了以下几类策略:
- SoftmaxDFL:基于 Softmax 的端到端直接分配模型。
- RobustSPO:设置不同鲁棒半径 (
ρ) 的 SPO 模型。
- SPO+及其变体:标准 SPO+,带交易费感知的 SPO+,带换手惩罚的 SPO+。
- PtO Baseline:传统的预测-优化模型(用 MSE 损失训练线性回归,再用 Markowitz 优化)。
- Classical Baseline:传统的最大化夏普比率模型。
5. 结果与讨论
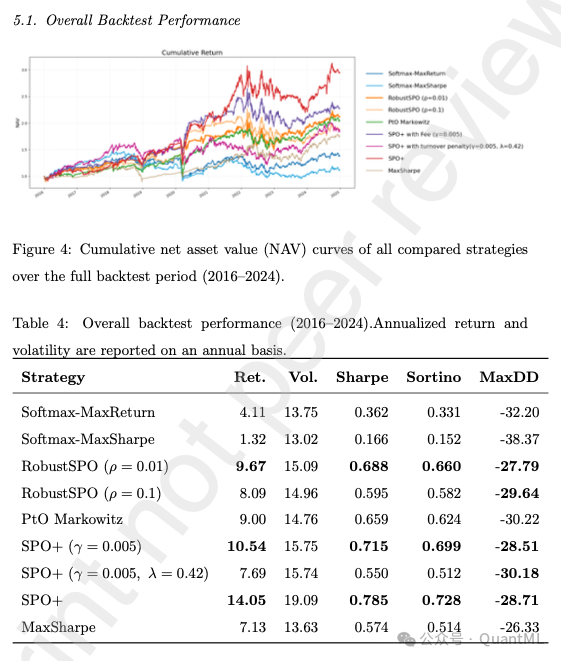
5.1 整体回测表现 (2016-2024)
实证结果表明,决策导向学习方法在风险调整后收益上显著优于传统 PtO 和经典优化方法。
- 最佳风险收益比:SPO+ 策略取得了最高的年化收益(14.05%)和最高的夏普比率(0.785),以及最高的 Sortino 比率(0.728)。尽管其波动率略高,但高收益充分补偿了风险。
- 成本感知的有效性:SPO+ with Fee 变体在显式考虑交易成本后,依然保持了极具竞争力的风险调整收益。
- 正则化的影响:引入 L2 正则化后,策略变得更加保守和分散,虽然降低了绝对收益,但最大回撤控制得当,体现了对极端配置的抑制作用。
- SoftmaxDFL的失败:完全可微的 Softmax 策略表现最差,甚至无法跑赢基准。这表明在非平稳的金融数据上,缺乏显式优化结构的“黑盒”分配模型极易受到噪声干扰,难以学习到稳健的策略。
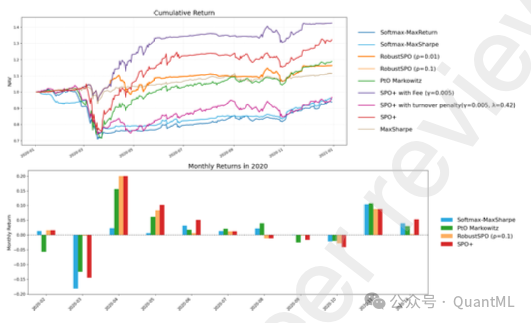
5.2 极端市场下的鲁棒性:COVID-19 危机分析
我们重点分析了 2020 年 1 月至 12 月 COVID-19 引发的市场动荡期,这是检验模型鲁棒性的关键压力测试。
- SPO的防御性:RobustSPO (ρ=0.01) 和 SPO+ with Fee 展现了惊人的防御能力。两者在该期间的净值曲线几乎重合,且最大回撤控制在 -10% 左右,远优于 PtO 基准的 -30.22%。
- 机制分析:这一现象揭示了深层的机制联系——在极端市场压力下,显式的鲁棒性约束与交易费惩罚殊途同归,都迫使模型通过减少激进调仓和避免极端权重来“寻求安全”。
- 收益与风险的脱钩:值得注意的是,决策导向模型在危机期间不仅降低了风险,还实现了比 PtO 更高的绝对收益。这证明将优化问题嵌入训练目标,能够帮助模型在市场崩盘时识别出真正具有防御价值的资产,而非仅仅是降低波动。
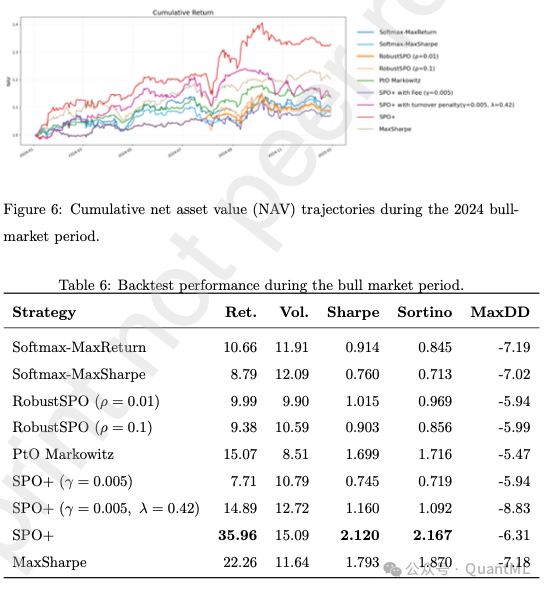
5.3 牛市环境下的表现:2024年行情
在 2024 年的单边牛市行情中,模型展现了在“进取”与“稳健”之间的权衡。
- PtO的优势:传统 PtO 模型在牛市中表现出色(年化 15.07%,夏普 1.699),这得益于其对预测收益的直接响应,能够激进地利用上涨趋势。
- 鲁棒模型的滞后:带有严格换手惩罚或鲁棒约束的模型因其保守的投资风格,在持续上涨中略显滞后,收益率低于 PtO。
- SPO+的均衡性:SPO+ 基准模型再次证明了其优越性,以 35.96% 的年化收益和 2.120 的夏普比率全面领先。这说明在没有过度约束的情况下,SPO 范式既能捕捉上行机会,又能维持比 PtO 更好的风险收益结构。
5.4 核心发现:进取与稳健的权衡
综合分析揭示了投资组合构建中一个根本性的权衡:
- PtO策略:倾向于在持续牛市中通过对预测信号的强暴露获利,但对噪声极其敏感,在危机中回撤巨大。
- 决策导向策略:侧重于稳定性与下行风险控制。在恶劣市场环境中优势显著,但在强劲牛市中可能因过于保守而牺牲部分潜在收益。
- SPO+:作为一种平衡方案,通过直接优化决策后悔值,无需人为引入过度的保守约束,即可在不同市场体制下实现“全天候”的优异表现。
6. 结论
本研究证实,在现实的滚动回测框架下,将机器学习模型的学习目标与下游投资组合的决策质量对齐,能显著提升策略的决策质量。
与主要关注预测精度的传统 PtO 方法相比,SPO 方法表现出以下优势:
- 一致的风险调整后收益提升:在全样本及各分样本区间,SPO 方法的夏普比率和 Sortino 比率普遍更高。
- 内生的风险控制:即使不通过显式的风险约束,SPO 通过优化后悔值也能学会在高波动环境下降低仓位集中度。
- 对噪声的鲁棒性:特别是在 COVID-19 等极端行情下,结合了交易费感知或鲁棒优化的 SPO 模型,提供了传统模型无法比拟的下行保护。
这项工作强调了在充满噪声和非平稳性的金融数据环境中,摒弃单纯追求预测精度,转而采用决策感知建模的重要性。对于从事量化研究和 算法 交易的开发者而言,这是一个值得深入探索的方向。更多的技术讨论和实践分享,欢迎来 云栈社区 交流。
7. 未来展望
基于当前的研究,以下几个方向具有广阔的探索空间:
- 高级风险控制:在 SPO 框架中引入分布鲁棒优化或 VaR/CVaR 约束,以进一步增强对抗极端尾部风险的能力。
- 树模型的集成:鉴于梯度提升树等模型在处理低信噪比数据时的鲁棒性,未来可探索将树模型预测器整合进决策导向学习框架。
- 分散化与收益的动态平衡:开发更具原则性的方法,在决策导向优化中动态地、自适应地平衡投资组合的分散化程度与收益最大化目标。
 发表于 2026-2-14 05:32:09
|
查看: 392|
回复: 0
发表于 2026-2-14 05:32:09
|
查看: 392|
回复: 0
