在Linux服务器运维中,“网络流量激增→CPU使用率飙升”的场景并不鲜见。当业务带宽拉满时,top命令中“si”列的软中断占用率常居高不下,甚至压垮CPU资源,这让不少运维人员困惑:网络数据的接收与转发,为何会如此“消耗”计算资源?答案藏在Linux的中断处理机制中。中断是硬件与系统通信的核心方式,而网卡这类高速设备的中断请求若频繁触发,会频繁打断内核进程,反而降低效率。软中断正是为解决这一问题而生的“缓冲层”,它将紧急但非即时的中断处理任务拆分,让内核能灵活调度。
但物极必反,当网络小包密集涌入,软中断任务会在CPU核心上排队堆积,原本的“优化设计”沦为资源负担。本文将从软中断的设计初衷切入,拆解网络软中断的触发、调度与执行流程,剖析网络流量与CPU占用之间的量化关联,帮你厘清“软中断为何会成为CPU的隐形负载”,为后续定位与优化提供核心理论支撑。
一、Linux软中断是什么?
1.1 软中断概述
中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。
在计算机系统中,中断可分为同步中断与异步中断两大类。同步中断由CPU内部产生,通常被称为异常(exception),其特点是中断请求信号与指令执行严格同步——即必须在一条指令执行完毕后才能触发,不能在指令执行期间发生。与之相对的是异步中断,它由外部硬件设备产生,也称为外部中断或狭义上的“中断”(interrupt),这类中断可在任意时刻发生,包括指令执行过程中。
进一步细分来看:异常可根据处理方式分为故障(fault)、陷阱(trap)和终止(abort)三类;而异步中断则根据是否可被屏蔽分为可屏蔽中断(Maskable interrupt)和非屏蔽中断(Non-maskable interrupt)。
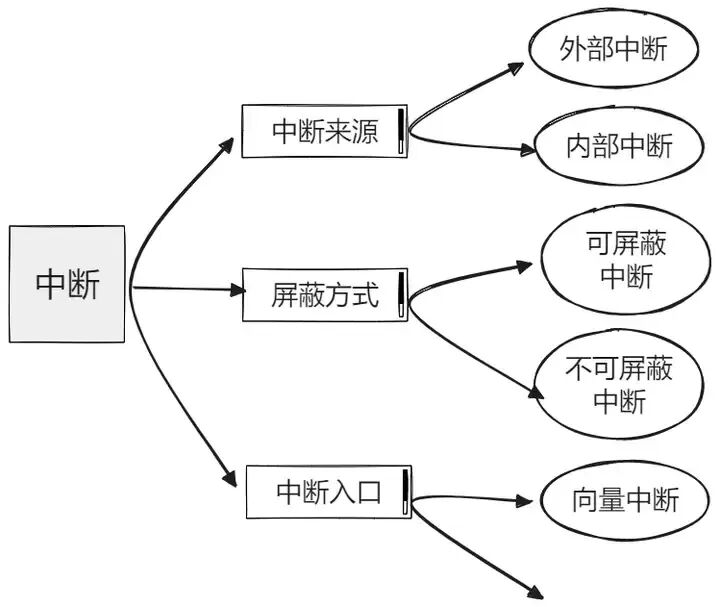
在一个完整的计算机系统中,中断硬件主要由设备、中断控制器和CPU三类组成。
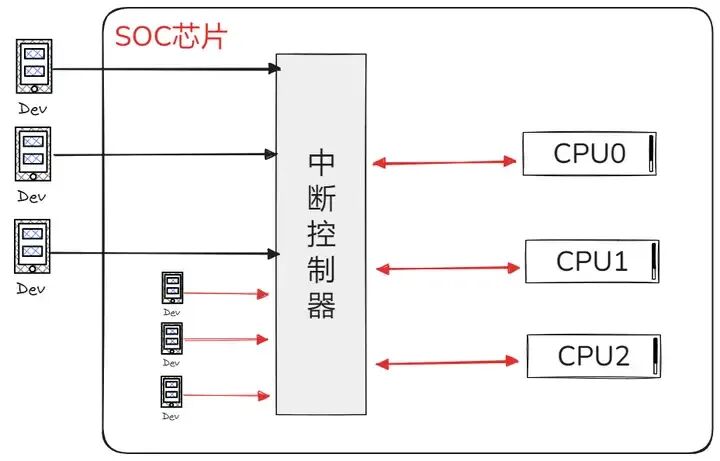
- 设备:作为中断的发起源,在需要请求服务时会发出硬件中断信号,该信号通常首先传递至中断控制器进行处理;在现代移动设备的SoC(System-on-Chip)中,这些设备可能位于芯片外部,也可能集成于内部(如I2C、SPI、显示控制器等IP核)。
- 中断控制器:负责汇总所有中断源的中断请求,其本身多为可编程设计,能够配置各中断源的优先级、电气类型及开关状态;在SMP系统中还可指定将中断发往特定CPU处理。ARM架构常见的中断控制器包括早期的VIC(向量中断控制器)与当前多核环境下广泛使用的GIC(通用中断控制器)。
- CPU:作为实际响应和处理中断的单元,通过对可编程中断控制器的配置来管理系统中的各个中断。当中断控制器判定某个中断可被处理时,会根据预设规则通知一个或多个CPU;尽管多个CPU可能同时收到通知,但最终仅有一个CPU实际响应该中断——这一机制由硬件保证并依赖于操作系统的软件实现。此外在SMP系统中,CPU之间也通过处理器间中断(IPI)进行通信与协调。
1.2 软中断与硬中断的差异
在 Linux 系统的中断体系中,硬中断与软中断犹如两条并行的轨道,各自承担着独特的使命。硬中断是由硬件设备“亲自出马”触发的,当键盘被敲击、网卡接收到数据包或者磁盘完成一次 I/O 操作时,硬件设备会通过中断控制器向 CPU 发送电信号,这就好比是紧急的“警报”,CPU 一旦收到,必须立即暂停当前正在执行的任务,保存现场信息,迅速跳转到对应的中断处理程序。
而软中断则是由软件精心安排触发的,它更像是一种“计划性”的任务调度。软中断常用于实现系统调用、异常处理或者延迟处理一些任务。比如,当应用程序发起系统调用时,就会通过软中断指令实现从用户态到内核态的切换。从处理时机来看,硬中断是分秒必争,必须立即响应;软中断则相对“从容”,可以延迟处理,比如在硬中断处理完成后,由内核在合适的时机调度执行,或交给专门的内核线程 ksoftirqd 来处理。
在中断号来源上,硬中断的中断号是由中断控制器依据硬件设备的连接和配置分配的;软中断的中断号则是由程序在触发软中断时直接指定的。在可屏蔽性方面,硬中断多数情况下可以被屏蔽,以避免在某些关键操作时被打断;软中断则不具备可屏蔽性。从处理速度上看,硬中断处理程序通常短小精悍;软中断可能涉及较为复杂的逻辑,处理时间相对较长。
1.3 软中断的实现机制
在 Linux 内核中,软中断通过一种巧妙的枚举定义方式来确定其类型。在 include/linux/interrupt.h 头文件中,定义了一系列软中断类型,例如 HI_SOFTIRQ(高优先级软中断)、TIMER_SOFTIRQ(定时器软中断)、NET_TX_SOFTIRQ(网络发送软中断)、NET_RX_SOFTIRQ(网络接收软中断)等。这些枚举值就像是给不同类型的软中断贴上了独特的“标签”,每个标签对应着不同的任务,并且索引号小的软中断会在索引号大的软中断之前执行,以此来区分优先级。
软中断的触发依赖于一个标记机制。当某个任务需要触发软中断时,会调用 raise_softirq 函数,将对应的软中断类型标记为“待处理”状态。这个过程就像是在任务清单上给特定任务打上了一个醒目的“待办”标记。而软中断的处理流程则是在合适的时机,内核会检查是否有待处理的软中断。例如,在处理完硬中断之后,或者在 ksoftirqd 内核线程运行时,内核会执行 do_softirq 函数。这个函数会遍历所有被标记为“待处理”的软中断,依次调用它们的处理程序。
ksoftirqd 内核线程在软中断处理中扮演着至关重要的角色。在多核系统中,每个 CPU 核心都会有一个与之对应的 ksoftirqd 线程,比如 ksoftirqd/0 对应 CPU 0。这些线程专门负责处理软中断任务。当有软中断被标记为“待处理”,并且当前 CPU 的软中断处理没有在进行中时,ksoftirqd 线程就会被唤醒执行处理逻辑。
在网络通信中,软中断起着承上启下的关键作用。当网卡接收到网络数据包时,首先会触发硬中断,CPU 迅速响应,将数据包从网卡读取到内存中。随后,就会触发网络接收软中断 NET_RX_SOFTIRQ。这个软中断负责从内存中找到网络数据,然后按照网络协议栈的规则,对数据进行逐层协议解析和处理,最终将数据准确无误地递交给应用程序。同样,在网络数据包的发送过程中,软中断NET_TX_SOFTIRQ负责将数据从内核缓冲区发送到网卡。一旦软中断处理出现问题,比如处理速度跟不上网络流量的增长,就会导致数据包积压、丢失,进而影响整个网络服务的质量。
二、Linux软中断过程分析
软中断是内核中用于延期执行任务的一种机制,其运作方式与硬件中断类似,可以视为在软件层面模拟了硬件中断的处理流程。软中断的设计主要涉及以下几个关键环节:
- 软中断的注册:内核在初始化时预先注册好所需的软中断类型;
- 软中断的触发:在适当的时机(如硬件中断处理返回前),调用接口触发已注册的软中断;
- 软中断的处理:内核在特定的执行点(如中断下半部或ksoftirqd内核线程)检查并执行挂起的软中断。
目前 Linux 内核中预定义了约10种软中断类型,涵盖网络收发、定时器、RCU 及任务队列等核心功能。由于系统不建议用户新增自定义的软中断类型,开发者通常应基于现有机制进行扩展。若需要实现类似功能,可选用预定义类型中的 TASKLET_SOFTIRQ——它本身是一种基于软中断实现的、更易用的任务延迟执行机制。下面我们将逐一解析每个环节的关键实现原理。
2.1 软中断的注册过程
在深入了解软中断的注册过程之前,我们先来认识一下两个关键的数据结构:软中断描述符(softirq_action)和软中断全局数组(softirq_vec)。软中断描述符 softirq_action 定义如下:
struct softirq_action{
void (*action)(struct softirq_action *);
void *data;
};
其中,action 是一个函数指针,指向软中断发生时执行的处理函数;data 是一个指针,用于传递参数给处理函数。可以把它想象成一个任务描述,当软中断被触发时,就会根据这个描述来执行相应的任务。
而软中断全局数组 softirq_vec 则是一个包含多个 softirq_action 结构体的数组。这个数组就像是一个“任务列表”,每个元素对应一种类型的软中断及其处理函数。在注册软中断时,我们实际上就是在填充这个数组,告诉系统当某种类型的软中断发生时,应该执行哪个处理函数。
注册函数 open_softirq
在 Linux 内核中,使用 open_softirq 函数来注册软中断处理函数:
void open_softirq(int nr, void (*action)(struct softirq_action*), void *data){
softirq_vec[nr].data = data;
softirq_vec[nr].action = action;
}
这个函数接受三个参数:
nr:软中断的类型编号,它是一个索引值,对应 softirq_vec 数组中的某一个元素。action:软中断处理函数的指针,当该类型的软中断被触发时,系统就会调用这个函数来进行处理。data:传递给软中断处理函数的参数。
常见软中断类型的注册
在 Linux 系统中,有许多常见的软中断类型在系统启动或相关模块初始化时就会被注册。
- 定时器软中断(TIMER_SOFTIRQ):在系统启动过程中,内核会调用
init_timers 函数来初始化定时器相关的功能,其中就包括注册定时器软中断。
void __init init_timers(void){
open_softirq(TIMER_SOFTIRQ, run_timer_softirq, NULL);
// 其他定时器初始化相关代码
}
- 网络接收软中断(NET_RX_SOFTIRQ):在网络设备驱动初始化时,会注册网络接收软中断。在网络子系统的初始化过程中,
net_dev_init 函数会进行注册。
static int __init net_dev_init(void){
// 其他网络设备初始化代码
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
// 更多网络相关初始化代码
return 0;
}
2.2 软中断的触发机制
在 Linux 内核中,raise_softirq函数用于触发软中断,其定义如下:
void raise_softirq(unsigned int nr){
unsigned long flags;
local_irq_save(flags);
__raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
这个函数首先通过 local_irq_save 保存当前中断状态并禁用本地中断,以保证操作的原子性。然后调用 __raise_softirq_irqoff 函数真正执行标记操作,最后恢复中断状态。
__raise_softirq_irqoff 函数的核心操作是将软中断位图(__softirq_pending)中对应软中断类型的标志位置位。软中断位图是一个全局变量,它的每一位对应一种软中断类型。这样,当系统检测到 __softirq_pending 中某一位被置位时,就知道有相应类型的软中断需要处理。
软中断触发的相关场景:
- 硬件中断处理结束后:当硬件中断处理程序执行完毕,准备返回时,会检查是否有软中断等待处理。在硬件中断处理函数的最后,通常会调用
irq_exit 函数,该函数会进一步调用 invoke_softirq 来检查和执行软中断。以网卡接收数据包为例,硬中断处理程序完成紧急操作后,在返回路径中就会检查并执行可能已触发的 NET_RX_SOFTIRQ 软中断。
- 系统调用返回时:当一个系统调用执行完成,准备返回用户空间时,内核也会检查是否有软中断等待处理。
- 调度程序执行时:在 Linux 系统中,调度程序负责决定哪个进程或线程可以在 CPU 上运行。当调度程序执行时,它也会检查是否有软中断等待处理。如果有,调度程序会优先处理软中断,然后再进行进程调度。
2.3 软中断的处理流程
(1)ksoftirqd 内核线程
在 Linux 系统中,每个 CPU 都对应一个名为 ksoftirqd 的内核线程。这个线程专门负责处理软中断任务。ksoftirqd 线程会不断地循环检查软中断位图(__softirq_pending)来判断是否有软中断需要处理。一旦检测到有待处理的软中断,ksoftirqd 线程就会调用 do_softirq 函数来执行处理。处理完毕后,线程会进入睡眠状态,直到下一次被唤醒。
(2)do_softirq 函数解析
do_softirq 函数是软中断处理的核心函数,其执行流程如下:
- 检查中断上下文:函数首先会检查当前是否处于中断上下文。如果是,则直接返回,避免在中断上下文中嵌套过多的软中断处理,防止系统栈溢出等问题。
- 获取软中断位图:如果当前不在中断上下文,则获取当前 CPU 的软中断位图,这个位图记录了当前 CPU 上所有待处理的软中断类型。
- 遍历软中断数组执行处理函数:通过一个循环,遍历软中断位图。对于每一个被置位的位,找到对应的软中断类型编号,然后清除该位。接着,从
softirq_vec 数组中取出对应的处理函数并执行。在处理过程中,还会进行一些统计和跟踪工作。
- 处理结束:当所有待处理的软中断都处理完毕后,函数恢复上下文状态,完成处理流程。
(3)处理函数的执行与注意事项
软中断处理函数在执行时具有一些特殊的要求和注意事项:
- 不能睡眠:软中断处理函数运行在中断上下文或内核线程中,不能执行任何可能导致睡眠的操作。因为睡眠会导致进程上下文切换,而软中断处理函数在执行过程中是不允许进行进程上下文切换的,否则可能导致死锁。
- 可重入性要求:由于软中断可以在多个 CPU 上并发执行,所以软中断处理函数必须是可重入的。这意味着处理函数不能依赖于一些全局状态或者静态变量,否则在并发执行时可能会出现数据竞争。
- 共享资源与自旋锁:当软中断处理函数需要访问共享资源时,必须使用合适的同步机制来保护临界区,例如自旋锁(spin lock)。需要注意的是,自旋锁的持有时间不能过长,否则会浪费 CPU 资源。
三、网络高负载引发CPU瓶颈的剖析
3.1 网络高负载时的常见问题
在网络高负载的汹涌浪潮下,一系列棘手的问题如潮水般涌现。最直观的感受就是系统响应变得迟缓,曾经快速加载的网页,如今需要漫长的等待;原本流畅的在线视频播放,也开始频繁出现卡顿、缓冲。这是因为大量的网络请求蜂拥而至,服务器的资源被急剧消耗,处理每个请求的时间也随之大幅增加。
服务超时的问题也接踵而至。当服务器忙于处理堆积如山的请求时,一些请求可能因为等待时间过长而超时,无法得到及时处理。在电商购物或在线支付场景中,这会给用户和商家都带来极大的困扰。
系统的稳定性也受到严重威胁,可能会出现崩溃的情况。当网络负载超出服务器的承受极限,服务器就像一台过度运转的机器,各个部件不堪重负,最终导致系统崩溃。这对于依赖在线服务的企业来说,无疑是一场灾难。
3.2 软中断在其中扮演的角色
在网络高负载的情境下,软中断就像一把双刃剑。当网络流量急剧增加,大量的网络数据包不断涌入,网卡会频繁触发硬中断,进而导致网络接收软中断 NET_RX_SOFTIRQ 和网络发送软中断 NET_TX_SOFTIRQ 被频繁调用。这些软中断的处理程序需要占用 CPU 资源来完成数据包的解析、传递等任务。
随着软中断触发频率的不断升高,CPU 需要花费越来越多的时间和精力来处理这些软中断。在极端情况下,CPU 的大部分时间都被软中断处理程序占据,其他任务如用户进程的执行、系统调度等无法及时得到 CPU 资源。这种情况下,CPU 的利用率会迅速飙升,接近甚至达到 100%,从而引发 CPU 瓶颈。
软中断处理不及时还会导致数据包积压。由于 CPU 忙于处理软中断,无法及时处理新到达的数据包,这些数据包就会在缓冲区中不断堆积。当缓冲区被填满后,新的数据包就会被丢弃,导致网络通信出现丢包现象。
3.3 软中断的实际应用与案例分析
在网络子系统中,软中断起着至关重要的作用,尤其是NET_RX_SOFTIRQ和NET_TX_SOFTIRQ。
当网卡接收到数据包时,首先会触发硬件中断。硬中断处理程序会迅速将数据包搬运到内核内存中的环形缓冲区,并更新网卡状态。完成后,会触发NET_RX_SOFTIRQ软中断。ksoftirqd内核线程检测到后,会调用net_rx_action函数来处理接收到的数据包。net_rx_action函数会从环形缓冲区中取出数据包,并进行一系列的协议解析工作,最终将数据递交给相应的应用程序。
在网络发送方面,当应用程序调用系统调用发送数据时,内核会将数据封装成网络数据包,并放入发送队列。随后,内核会触发NET_TX_SOFTIRQ软中断。ksoftirqd内核线程响应后,调用net_tx_action函数将数据包发送到网卡的硬件缓冲区。
为了提高网络数据处理效率,可以采取以下优化措施:
- 多队列网卡与 RPS/RFS 技术:使用多队列网卡可以将网络中断分散到多个 CPU 核心上处理。结合 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering)技术,可以实现负载均衡和提高缓存命中率。通过配置
/proc/sys/net/core/rps_sock_flow_entries 和 /sys/class/net/eth0/queues/rx-0/rps_cpus 等文件来设置。
- 中断合并与自适应中断处理:中断合并技术可以减少中断的频率,将多个数据包的处理合并到一次中断处理中。自适应中断处理则根据网络流量的大小动态调整中断的触发频率。可以通过调整网卡驱动的相关参数来实现。
在 Linux服务器运维 中,可以通过/proc/softirqs文件查看软中断的运行统计信息。执行cat /proc/softirqs命令,可以分析软中断对系统性能的影响:
- 软中断 CPU 使用率过高:如果
top命令中si值持续较高,说明软中断处理占用了大量的 CPU 资源。此时,可以通过多队列网卡、RPS/RFS 等技术将负载均衡到多个 CPU 核心上。
- 软中断处理不均衡:观察不同 CPU 上同一种软中断的触发次数,如果差异较大,说明处理不均衡。可以通过调整中断亲和性(如使用
irqbalance服务或手动设置/proc/irq/[irq号]/smp_affinity)来改善。
- 软中断类型分析:不同类型的软中断对系统性能的影响不同。例如
NET_RX_SOFTIRQ和NET_TX_SOFTIRQ与网络性能密切相关,需要针对性优化。
软中断网络处理监控工具(C++ 实现)
以下代码实现了一个简单的软中断监控工具,重点监控NET_RX_SOFTIRQ和NET_TX_SOFTIRQ状态,同时展示软中断 CPU 负载均衡分析:
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <chrono>
#include <thread>
#include <cstdio>
#include <sstream>
// 存储每个CPU的软中断统计
struct SoftIRQStats {
unsigned long net_rx; // NET_RX_SOFTIRQ 触发次数
unsigned long net_tx; // NET_TX_SOFTIRQ 触发次数
};
// 读取/proc/softirqs获取软中断统计
bool read_softirq_stats(std::vector<SoftIRQStats>& stats) {
std::ifstream file("/proc/softirqs");
if (!file.is_open()) {
std::cerr << "无法打开 /proc/softirqs" << std::endl;
return false;
}
std::string line;
int line_num = 0;
stats.clear();
while (std::getline(file, line)) {
std::stringstream ss(line);
std::vector<std::string> parts;
std::string part;
while (ss >> part) {
parts.push_back(part);
}
if (line_num == 0) {
// 第一行是CPU序号,计算CPU核心数
int cpu_count = parts.size() - 1; // 排除第一列"CPU0"标题
stats.resize(cpu_count, {0, 0});
} else if (parts[0] == "NET_RX:") {
// 解析NET_RX_SOFTIRQ统计
for (size_t i = 0; i < stats.size() && (i + 1) < parts.size(); ++i) {
stats[i].net_rx = std::stoul(parts[i + 1]);
}
} else if (parts[0] == "NET_TX:") {
// 解析NET_TX_SOFTIRQ统计
for (size_t i = 0; i < stats.size() && (i + 1) < parts.size(); ++i) {
stats[i].net_tx = std::stoul(parts[i + 1]);
}
}
line_num++;
}
file.close();
return true;
}
// 打印软中断统计信息
void print_softirq_stats(const std::vector<SoftIRQStats>& stats) {
std::cout << "=== 网络软中断统计(NET_RX/NET_TX)===" << std::endl;
std::cout << "CPU核心\tNET_RX触发次数\tNET_TX触发次数" << std::endl;
std::cout << "----------------------------------------" << std::endl;
for (size_t i = 0; i < stats.size(); ++i) {
std::cout << "CPU" << i << "\t\t"
<< stats[i].net_rx << "\t\t"
<< stats[i].net_tx << std::endl;
}
}
// 分析软中断CPU负载均衡情况
void analyze_softirq_balance(const std::vector<SoftIRQStats>& stats) {
std::cout << "\n=== 软中断CPU负载均衡分析 ===" << std::endl;
// 计算NET_RX总触发次数和各CPU占比
unsigned long total_rx = 0;
for (const auto& s : stats) {
total_rx += s.net_rx;
}
std::cout << "NET_RX_SOFTIRQ 负载分布:" << std::endl;
for (size_t i = 0; i < stats.size(); ++i) {
if (total_rx == 0) {
std::cout << "CPU" << i << ": 0.00%" << std::endl;
} else {
double ratio = (stats[i].net_rx * 100.0) / total_rx;
std::cout << "CPU" << i << ": " << ratio << "%" << std::endl;
// 检测负载不均衡(单个CPU占比超过60%)
if (ratio > 60.0) {
std::cerr << "警告:CPU" << i << " NET_RX负载过高(" << ratio << "%),可能存在软中断不均衡" << std::endl;
}
}
}
}
// 读取CPU软中断使用率(top命令解析si%)
void read_softirq_cpu_usage() {
std::cout << "\n=== CPU软中断使用率(si%)===" << std::endl;
FILE* pipe = popen("top -b -n 1 | grep -E '^%Cpu|si%'", "r");
if (!pipe) {
std::cerr << "无法执行top命令" << std::endl;
return;
}
char buffer[256];
while (fgets(buffer, sizeof(buffer), pipe) != nullptr) {
std::cout << buffer;
}
pclose(pipe);
// 检测软中断使用率过高(si% > 50%)
pipe = popen("top -b -n 1 | awk '/^%Cpu/ {print $8}'", "r");
if (pipe) {
char si_buf[32];
if (fgets(si_buf, sizeof(si_buf), pipe) != nullptr) {
double si_usage = std::atof(si_buf);
if (si_usage > 50.0) {
std::cerr << "警告:软中断使用率过高(" << si_usage << "%),可能影响系统性能" << std::endl;
}
}
pclose(pipe);
}
}
// 显示优化建议
void show_optimization_tips() {
std::cout << "\n=== 软中断优化建议 ===" << std::endl;
std::cout << "1. 多队列网卡+RPS/RFS配置:" << std::endl;
std::cout << " - 设置RPS哈希表大小:echo 32768 > /proc/sys/net/core/rps_sock_flow_entries" << std::endl;
std::cout << " - 绑定RX队列到CPU:echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus(f表示CPU0-3)" << std::endl;
std::cout << "2. 中断亲和性调整:" << std::endl;
std::cout << " - 使用irqbalance服务自动均衡中断" << std::endl;
std::cout << " - 手动设置:echo 2 > /proc/irq/[网卡中断号]/smp_affinity(绑定CPU1)" << std::endl;
std::cout << "3. 中断合并配置:调整网卡驱动参数(如ethtool -C eth0 rx-usecs 100)" << std::endl;
}
int main() {
std::vector<SoftIRQStats> stats;
while (true) {
// 读取并打印软中断统计
if (read_softirq_stats(stats)) {
print_softirq_stats(stats);
// 分析负载均衡
analyze_softirq_balance(stats);
// 读取CPU软中断使用率
read_softirq_cpu_usage();
// 显示优化建议
show_optimization_tips();
}
// 每5秒刷新一次
std::cout << "\n----------------------------------------\n" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(5));
}
return 0;
}
该工具实现了:
- 软中断统计读取:解析
/proc/softirqs 文件,提取各 CPU 核心的 NET_RX_SOFTIRQ 和 NET_TX_SOFTIRQ 触发次数。
- 负载均衡分析:计算每个 CPU 核心的软中断负载占比,检测是否存在单 CPU 负载过高(占比 > 60%)的不均衡情况。
- CPU 使用率监控:通过解析
top 命令输出,获取软中断(si%)的 CPU 占用率,检测是否存在性能瓶颈。
- 优化建议输出:直接给出多队列网卡、RPS/RFS 配置、中断亲和性调整、中断合并等优化措施的具体操作命令。
在实际的高并发网络服务器场景中,此类监控工具对于及时发现并定位由软中断引起的网络延迟升高、数据包丢失等异常至关重要。
四、定位问题:实用工具与分析流程
4.1 top:初步洞察 CPU 使用概况
在排查网络高负载引发的 CPU 瓶颈问题时,top 命令堪称我们的“第一侦察兵”。通过在终端中输入 top 命令,我们重点关注 “Cpu(s)” 这一行的信息,其中 “si” 列代表软中断占用的 CPU 时间百分比。
比如,当我们看到 “si” 的值持续居高不下,达到 30% 甚至更高时,这就表明软中断可能已经成为了 CPU 的沉重负担。同时,观察系统整体的 CPU 使用率,如果接近 100%,而其他进程的 CPU 占用相对较低,那么软中断占用过高的嫌疑就更大了。
4.2 /proc/softirqs:深入挖掘软中断数据
当 top 命令提示软中断可能存在问题后,/proc/softirqs 文件就成为了我们进一步挖掘真相的关键。这个文件记录了系统中各类软中断的详细统计信息。使用 cat /proc/softirqs 命令,我们可以看到类似如下的输出:
CPU0 CPU1 CPU2 CPU3
HI:0 0 0 0
TIMER:100000 100001 100002 100003
NET_TX:5 3 4 6
NET_RX:1000 998 1002 1001
...
每一列对应一个 CPU 核心,每一行代表一种软中断类型,而数值就是该软中断在对应 CPU 核心上的累计触发次数。我们重点关注 NET_RX(网络接收软中断)和 NET_TX(网络发送软中断)这两行的数据,如果它们的触发次数在短时间内急剧增加,远远超过其他类型的软中断,那就说明网络相关的软中断出现了异常。
4.3 perf:精准剖析软中断处理函数
如果说 /proc/softirqs 让我们知道了哪些软中断出现了问题,那么 perf 工具则能帮助我们深入了解这些软中断处理函数的具体执行情况。perf 是 Linux 系统中强大的性能分析工具。
使用 perf top -e softirq 命令,我们可以查看软中断处理函数的 CPU 占用排名。例如,在输出结果中,如果我们看到 net_rx_action 函数(网络接收软中断处理函数)的 CPU 占用率高达 70%,那就说明这个函数在处理网络接收软中断时花费了大量的 CPU 时间。
为了更深入地了解函数的调用关系和执行流程,我们还可以使用 perf record -g -e irq:softirq_entry -a sleep 10 命令记录软中断的调用栈信息,然后通过 perf report 命令查看详细的报告。在报告中,我们可以清晰地看到软中断处理函数的调用层级和每个函数的执行时间占比。
4.4 完整排查流程梳理
当我们发现服务器出现 CPU 瓶颈问题时,可以遵循以下流程:
- 初步判断:使用
top 命令查看系统整体的 CPU 使用率和软中断占用率(si%)。如果软中断占用率过高,初步判断软中断可能是导致 CPU 瓶颈的原因。
- 确定异常类型:查看
/proc/softirqs 文件,确定是哪种类型的软中断出现了异常增长(如 NET_RX 或 NET_TX)。
- 深入分析:使用
perf 工具对异常的软中断处理函数进行深入分析。通过 perf top 查看 CPU 占用排名,再用 perf record 和 perf report 来获取详细的调用栈信息,找出占用 CPU 时间长的具体函数。
软中断 CPU 瓶颈排查工具示例
以下工具示例将上述排查流程自动化:
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <chrono>
#include <thread>
#include <cstdio>
#include <sstream>
#include <algorithm>
// 存储软中断类型及各CPU触发次数
struct SoftIRQTypeStats {
std::string type; // 软中断类型(如NET_RX、NET_TX)
std::vector<unsigned long> cpu_counts; // 各CPU核心的触发次数
};
// 步骤1:查看系统CPU和软中断整体占用(解析top命令)
void check_system_cpu_softirq() {
std::cout << "===== 步骤1:查看系统CPU及软中断整体占用 =====" << std::endl;
FILE* pipe = popen("top -b -n 1 | grep -E '^%Cpu|Tasks:|si%'", "r");
if (!pipe) {
std::cerr << "错误:无法执行top命令" << std::endl;
return;
}
char buffer[256];
while (fgets(buffer, sizeof(buffer), pipe) != nullptr) {
std::cout << buffer;
}
pclose(pipe);
// 提取软中断使用率(si%)并判断是否过高
pipe = popen("top -b -n 1 | awk '/^%Cpu/ {print $8}'", "r");
if (pipe) {
char si_buf[32];
if (fgets(si_buf, sizeof(si_buf), pipe) != nullptr) {
double si_usage = std::atof(si_buf);
std::cout << "\n软中断(si%)使用率:" << si_usage << "%" << std::endl;
if (si_usage > 30.0) { // 阈值30%,超过则判定为高占用
std::cout << "警告:软中断占用率过高,可能是CPU瓶颈根源" << std::endl;
} else {
std::cout << "软中断占用率正常" << std::endl;
}
}
pclose(pipe);
}
std::cout << std::endl;
}
// 步骤2:解析/proc/softirqs,定位异常软中断类型
void check_softirq_type() {
std::cout << "===== 步骤2:定位异常软中断类型 =====" << std::endl;
std::ifstream file("/proc/softirqs");
if (!file.is_open()) {
std::cerr << "错误:无法打开/proc/softirqs" << std::endl;
return;
}
std::vector<SoftIRQTypeStats> all_stats;
std::string line;
int cpu_count = 0;
// 读取第一行获取CPU核心数
if (std::getline(file, line)) {
std::stringstream ss(line);
std::string part;
while (ss >> part) {
if (part.find("CPU") == 0) cpu_count++;
}
}
// 重置文件指针,重新读取所有行
file.clear();
file.seekg(0, std::ios::beg);
// 解析各类型软中断统计
while (std::getline(file, line)) {
std::stringstream ss(line);
std::vector<std::string> parts;
std::string part;
while (ss >> part) {
parts.push_back(part);
}
if (parts.empty() || parts[0].back() != ':') continue;
// 提取软中断类型(去掉末尾的冒号)
SoftIRQTypeStats stats;
stats.type = parts[0].substr(0, parts[0].size() - 1);
// 提取各CPU的触发次数
for (size_t i = 1; i < parts.size() && (i - 1) < (size_t)cpu_count; ++i) {
stats.cpu_counts.push_back(std::stoul(parts[i]));
}
all_stats.push_back(stats);
}
file.close();
// 打印关键软中断类型(重点关注NET_RX、NET_TX等)
std::vector<std::string> key_types = {"NET_RX", "NET_TX", "TIMER", "TASKLET", "RCU"};
for (const auto& stats : all_stats) {
if (std::find(key_types.begin(), key_types.end(), stats.type) != key_types.end()) {
std::cout << stats.type << ":";
unsigned long total = 0;
for (size_t i = 0; i < stats.cpu_counts.size(); ++i) {
std::cout << "CPU" << i << "=" << stats.cpu_counts[i] << " ";
total += stats.cpu_counts[i];
}
std::cout << "(总计:" << total << ")" << std::endl;
// 检测是否有CPU核心触发次数异常高(占比超过60%)
for (size_t i = 0; i < stats.cpu_counts.size(); ++i) {
if (total == 0) continue;
double ratio = (stats.cpu_counts[i] * 100.0) / total;
if (ratio > 60.0) {
std::cout << " 异常:" << stats.type << "在CPU" << i << "占比" << ratio << "%,可能存在负载不均衡" << std::endl;
}
}
}
}
std::cout << std::endl;
}
// 步骤3:调用perf工具进行深度分析(触发perf命令,输出操作指引)
void trigger_perf_analysis() {
std::cout << "===== 步骤3:perf工具深度分析 =====" << std::endl;
std::cout << "1. 查看软中断CPU占用排名(执行以下命令):" << std::endl;
std::cout << " perf top -e softirq" << std::endl << std::endl;
std::cout << "2. 记录10秒软中断调用栈(执行以下命令):" << std::endl;
std::cout << " perf record -g -e irq:softirq_entry -a sleep 10" << std::endl << std::endl;
std::cout << "3. 查看详细报告(执行以下命令):" << std::endl;
std::cout << " perf report" << std::endl << std::endl;
// 可选:自动执行perf record(需root权限)
std::cout << "是否自动执行perf record采集10秒数据?(y/n,需root权限):";
char choice;
std::cin >> choice;
if (choice == 'y' || choice == 'Y') {
std::cout << "正在采集10秒软中断数据..." << std::endl;
system("perf record -g -e irq:softirq_entry -a sleep 10 2>/dev/null");
std::cout << "采集完成!执行 'perf report' 查看详细报告" << std::endl;
}
}
int main() {
std::cout << "===== 软中断CPU瓶颈排查工具 =====" << std::endl << std::endl;
// 按步骤执行排查
check_system_cpu_softirq();
check_softirq_type();
trigger_perf_analysis();
return 0;
}
该工具遵循“整体判断→类型定位→深度分析”的递进式排查逻辑,与实际运维中定位软中断问题的流程完全一致。
五、解决方案:有效策略与优化实践
5.1 优化网络配置
启用网卡多队列(RSS,Receive Side Scaling)是优化网络配置的关键一步。在高网络负载下,单队列网卡容易成为性能瓶颈。RSS 技术通过哈希算法,依据数据包的五元组,将接收的数据包分发到多个硬件队列中,每个队列对应一个不同的 CPU 核心,实现了网络中断的并行处理,从而分散了 CPU 的负载。
中断亲和性配置同样重要。通过将软中断绑定到特定的 CPU 核心,可以避免软中断在多个 CPU 核心之间频繁迁移,减少上下文切换带来的开销,提高 CPU 缓存的命中率。在实际操作中,可以通过修改 /proc/irq/[irq_number]/smp_affinity 文件来实现。
调整网络队列大小也是不容忽视的优化策略。合理增大网络队列的大小,可以有效减少数据包的丢失。当网络流量突发时,如果队列过小,新到达的数据包可能会因为队列已满而被丢弃。可以使用 ethtool -G 命令来调整网卡的队列大小。
5.2 调整中断亲和性
通过设置 /proc/irq/[irq_number]/smp_affinity 文件,我们能够实现中断亲和性的精细调整。这个文件中的值是一个位掩码,每一位对应一个 CPU 核心。例如,假设服务器有 4 个 CPU 核心,我们希望将中断号为 32 的中断绑定到 CPU 0 和 CPU 1 上处理,那么可以通过 echo 3 > /proc/irq/32/smp_affinity 命令来实现(3的二进制0011对应CPU0和1)。
除了手动设置文件,使用 irqbalance 服务也是一种便捷的方式。irqbalance 服务会自动监控系统中各个 CPU 核心的负载情况,然后动态地将硬件中断分配到负载较低的 CPU 核心上,实现中断的负载均衡。我们可以通过 systemctl status irqbalance 等命令管理该服务。
5.3 升级驱动与内核
更新网卡驱动是解决软中断相关问题的重要手段。随着技术的不断发展,网卡厂商会持续优化驱动程序,修复已知的软中断处理漏洞。新的驱动通过优化算法和数据结构,能够更高效地处理软中断,减少数据包的丢失,提升网络性能。
升级内核同样具有重要意义。新版本的内核往往包含了对软中断处理的性能提升。例如,一些内核版本改进了软中断的调度算法,使其能够更合理地分配 CPU 资源。新内核还可能修复了一些与软中断相关的内核漏洞。在升级内核时,需要注意先在测试环境中进行充分的测试。
5.4 参数调优实践
net.core.netdev_budget 是一个关键的内核参数,它用于控制单次网络软中断(NET_RX_SOFTIRQ)处理的最大数据包数量。在高流量服务器场景中,默认值可能导致软中断频繁触发。此时,适当增大该值(如从300增大到1000-2000),可以减少软中断的触发次数,提升网络吞吐量。但如果设置过大,单次软中断处理时间会延长,可能影响其他任务的响应。可以通过 sysctl -w net.core.netdev_budget=600 命令临时修改,或在 /etc/sysctl.conf 中永久修改。
net.core.netdev_max_backlog 定义了网卡接收队列的最大长度。当数据包处理速度跟不上接收速度时,队列会暂存数据包。在高流量场景下,若该值过小,队列容易溢出导致丢包。因此,需要同步增大该值(如设置为30000-65535)。可以通过 sysctl -w net.core.netdev_max_backlog=30000 命令进行修改。
在实际的参数调优过程中,需要密切关注系统的性能指标。通过 cat /proc/softirqs 查看软中断统计;使用 mpstat -P ALL 1 监控 CPU 软中断占用率;通过 ethtool -S eth0 查看网卡统计信息,关注 rx_dropped 指标。根据这些指标的变化,逐步调整参数,找到最适合系统的配置。
 发表于 2025-12-6 01:30:22
|
查看: 140|
回复: 0
发表于 2025-12-6 01:30:22
|
查看: 140|
回复: 0
