众所周知,Transformer 及其核心的全注意力机制(Full Attention)虽长期占据大模型架构的核心地位,但其平方级计算复杂度与高额显存占用,早已成为实现超长上下文处理与规模化应用的“拦路虎”。敢于挑战这一现状,需要的不仅是追求 AGI 目标的魄力,更需要独到的技术视野与突破壁垒的硬实力。从 DeepSeek 的稀疏注意力(DSA)、MiniMax 的线性注意力,到月之暗面的线性注意力(KDA),各路研究力量纷纷投入注意力架构的革新竞技场。
今天,面壁智能也在这场变革中迈出了关键一步,正式发布行业首个大规模训练的稀疏-线性注意力混合架构 SALA(Sparse Attention-Linear Attention,简称SALA),以及基于该架构的文本模型 MiniCPM-SALA,其核心目标是追求更长的文本处理能力与极致的推理性价比。
MiniCPM-SALA 亮点一览
- 架构革新:首创 “稀疏-线性”注意力混合架构,在显著降低推理开销与显存占用的同时,克服了纯线性架构在长程信息召回上的精度瓶颈,实现效率与性能的兼得。
- 卓越性能:采用混合位置编码来协调短/长上下文性能。在保持与同规模全注意力模型相当的通用能力(如知识、数学、代码)的同时,MiniCPM-SALA 在多个长上下文基准测试中表现突出。
- 高效推理:不使用投机采样等额外加速算法,在云端芯片上,当序列长度为256K词元时推理速度可达 Qwen3-8B 的 3.5 倍,并支持在云端和消费级端侧 GPU 上进行高达一百万词元上下文长度的推理。
模型资源
为何混合架构是更优解
传统 Transformer 模型在处理长文本时,其全注意力机制会导致计算量呈平方级增长,同时缓存的键值对(KV-Cache)占用大量显存。现有解决方案分为线性注意力与稀疏注意力两大流派,但纯线性注意力存在精度损失,纯稀疏注意力则有存储瓶颈限制。
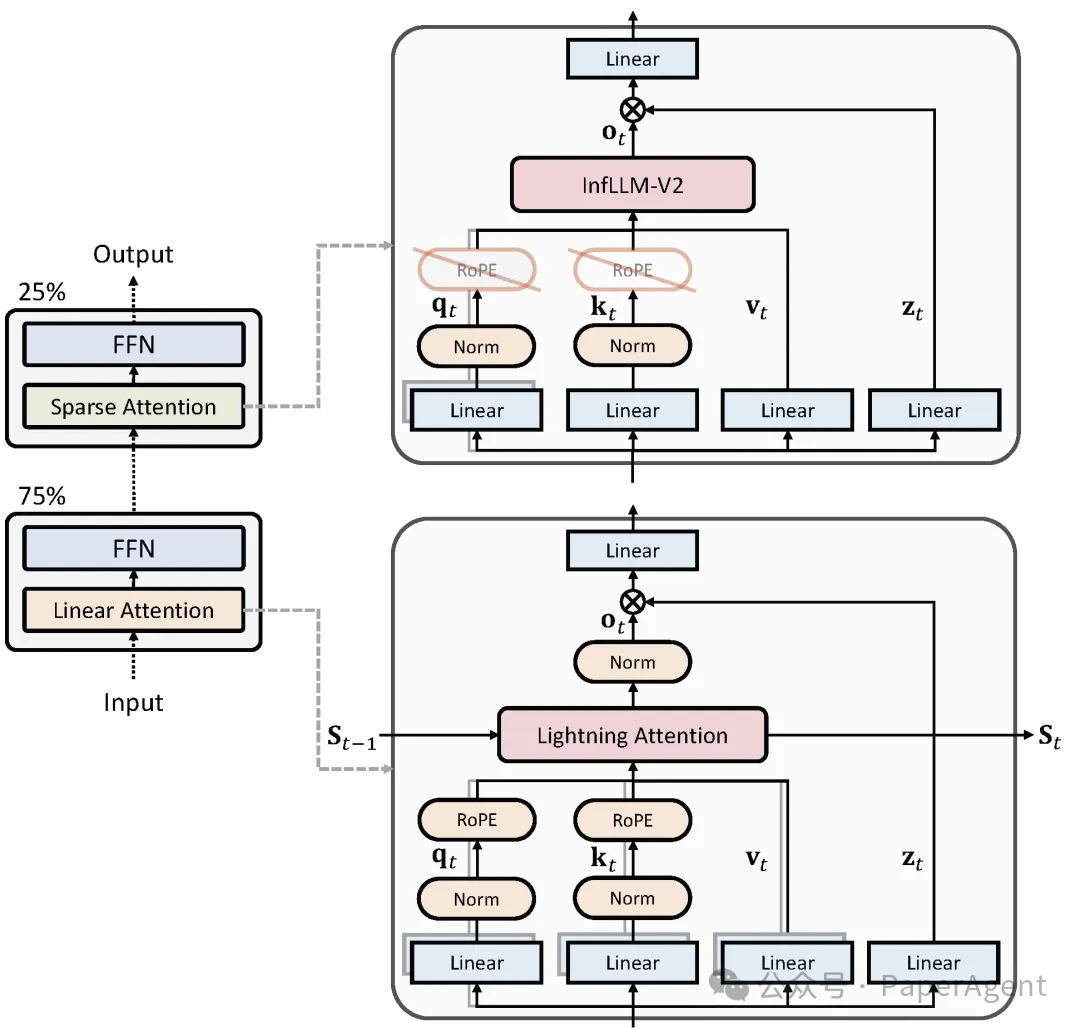
MiniCPM-SALA 提出的稀疏-线性混合注意力架构,巧妙地解决了这一矛盾。模型中 75% 的层采用线性注意力(Lightning Attention),负责精准捕捉局部关键信息;其余 25% 的层采用稀疏注意力(InfLLM-v2),专注于信息的高效全局流转。这一黄金配比实现了计算效率与语义精度的平衡。
相关研究论文:
不止于「长」,更在于「强」
MiniCPM-SALA 具备优异的长度泛化能力。在不使用任何外推技术的前提下,可以将训练时使用的上下文长度有效拓展至 2048K。
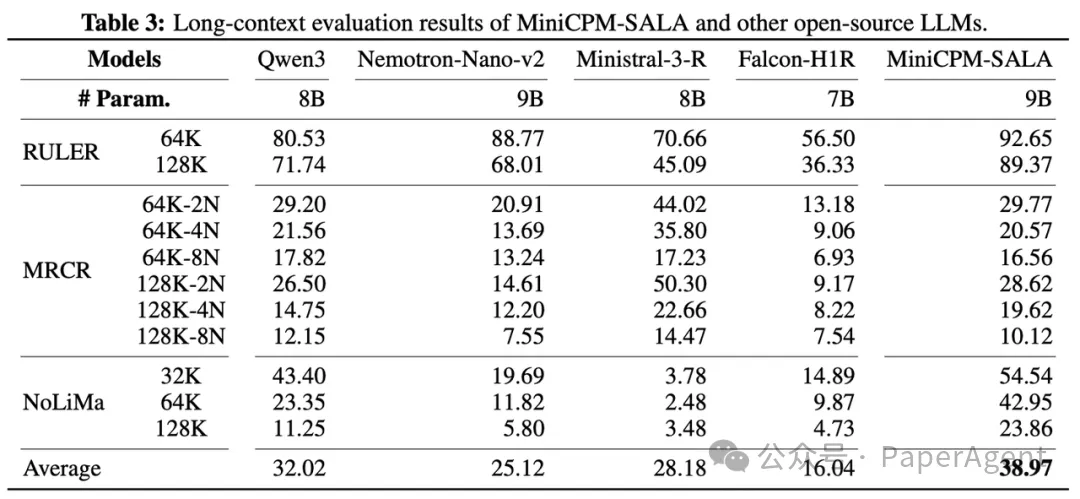
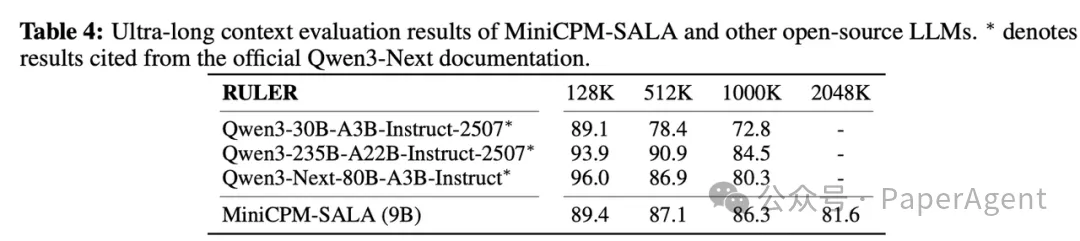
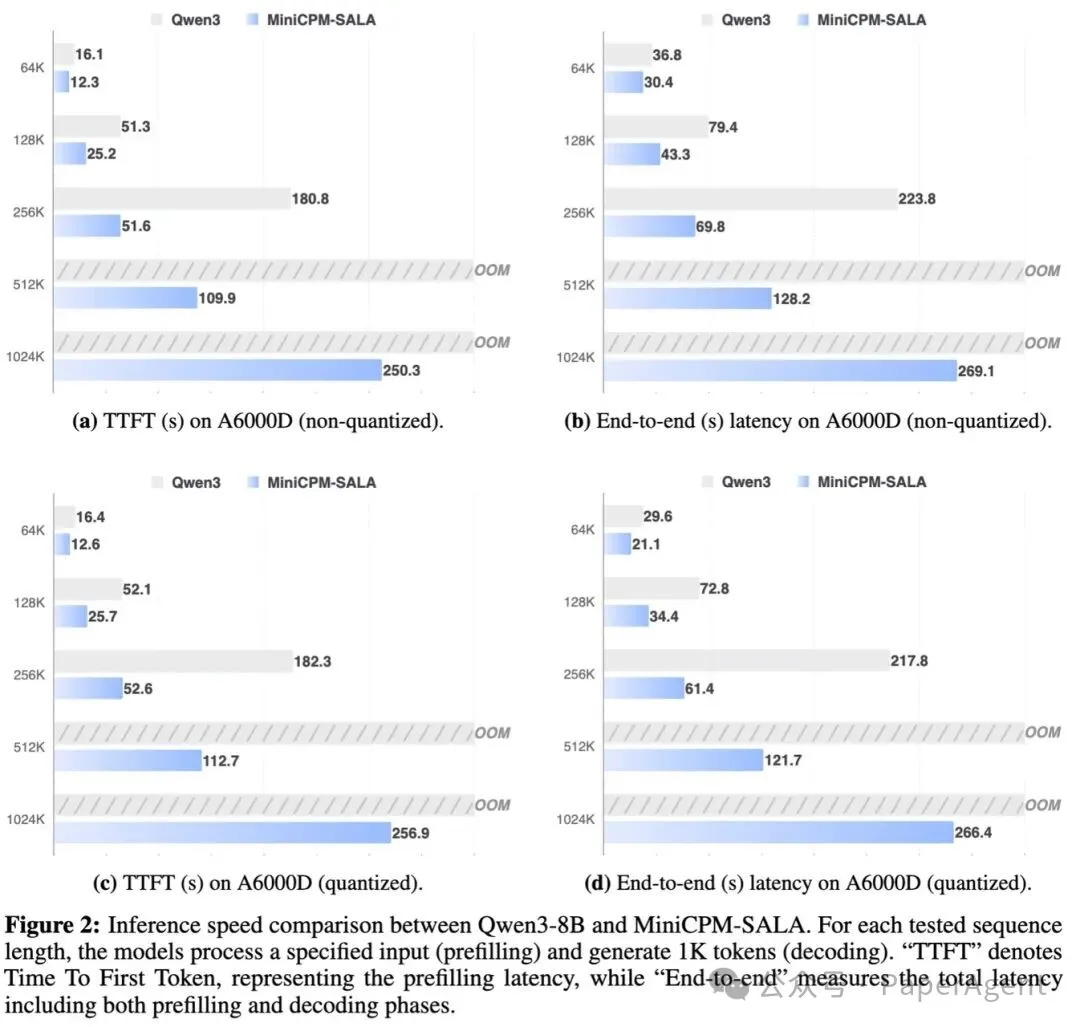
在效率方面,从 64K 到 1024K 词元的序列长度测试中,MiniCPM-SALA 在所有配置下均表现出显著优势。在 256K 序列长度下,其推理速度相比 Qwen3-8B 实现了约 3.5 倍的加速。
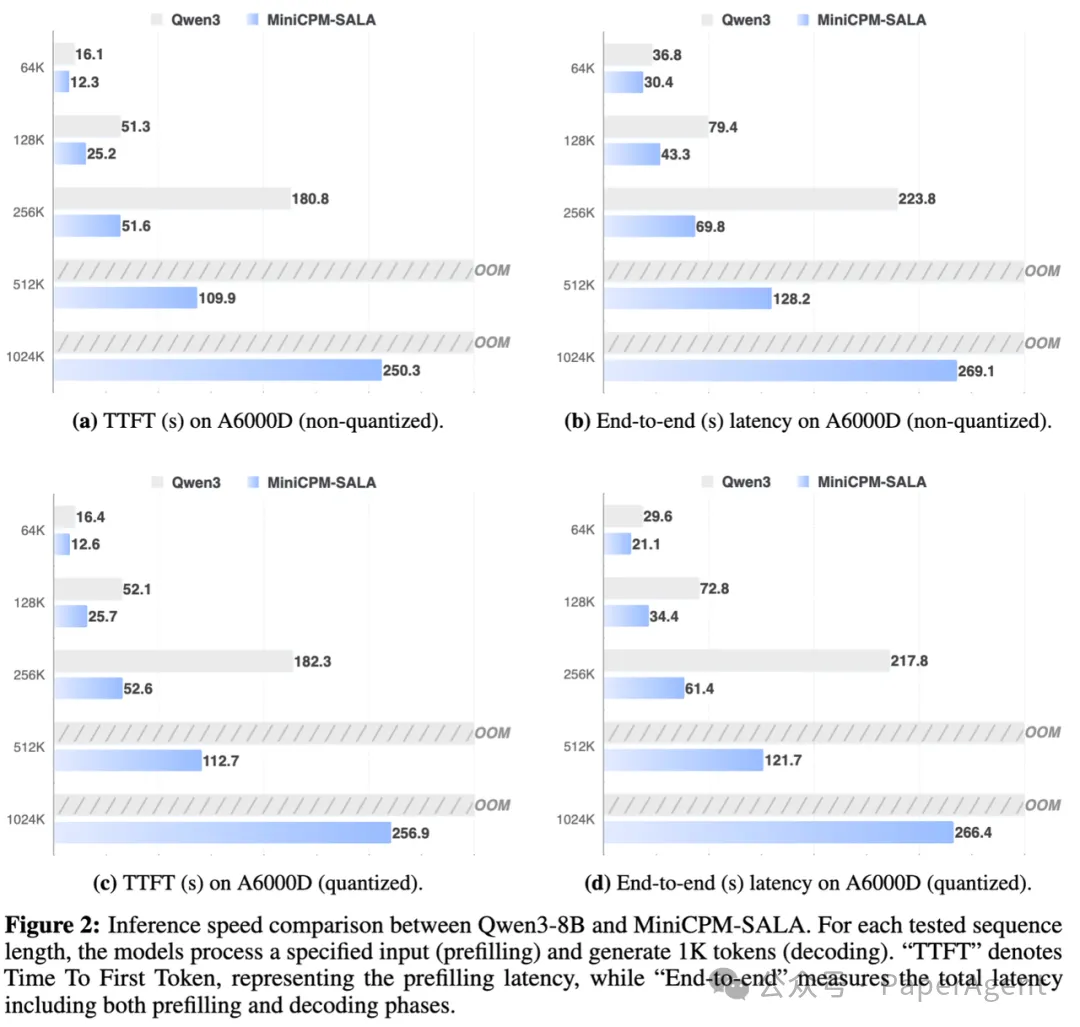
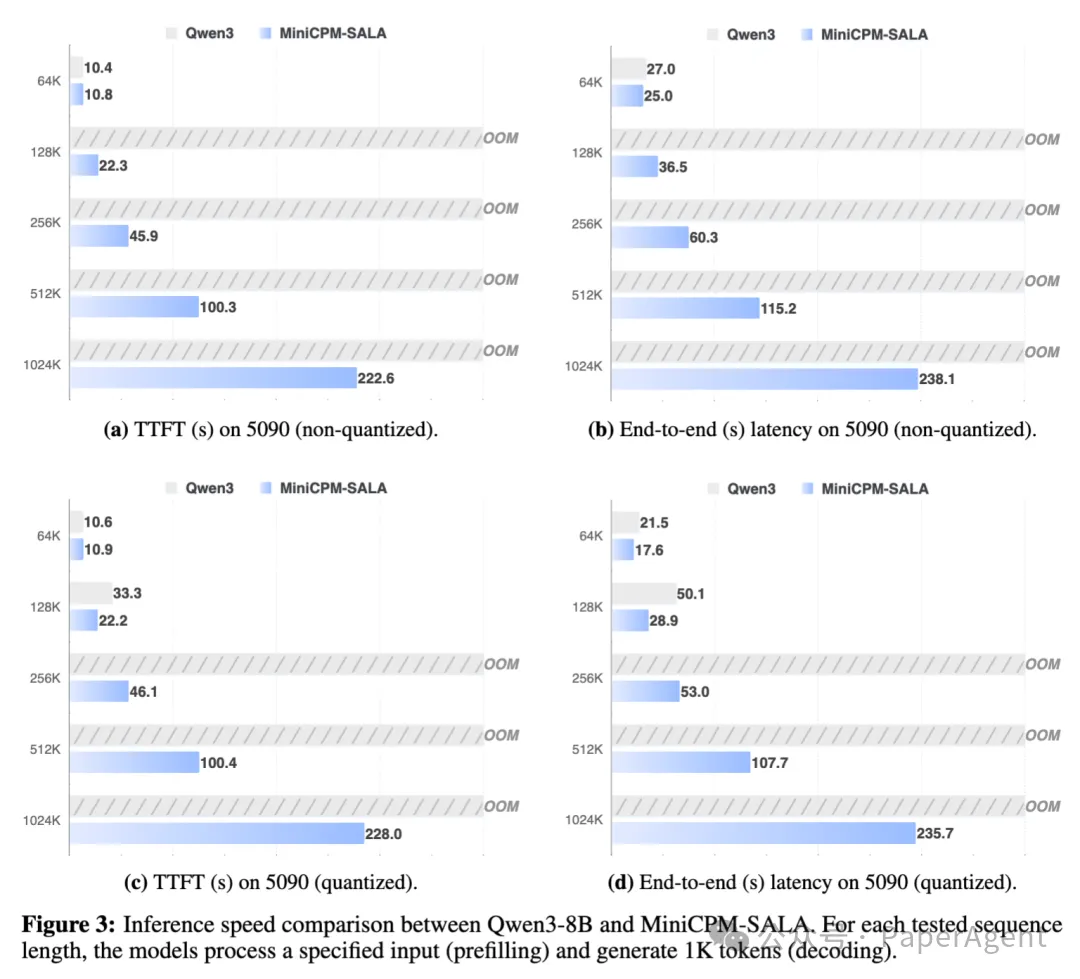
更重要的是,在更长序列(512K 及 1M)上,当同尺寸开源模型因显存爆炸(OOM)而无法运行时,MiniCPM-SALA 依旧能够稳定推理,这使其在端侧应用场景中潜力巨大。
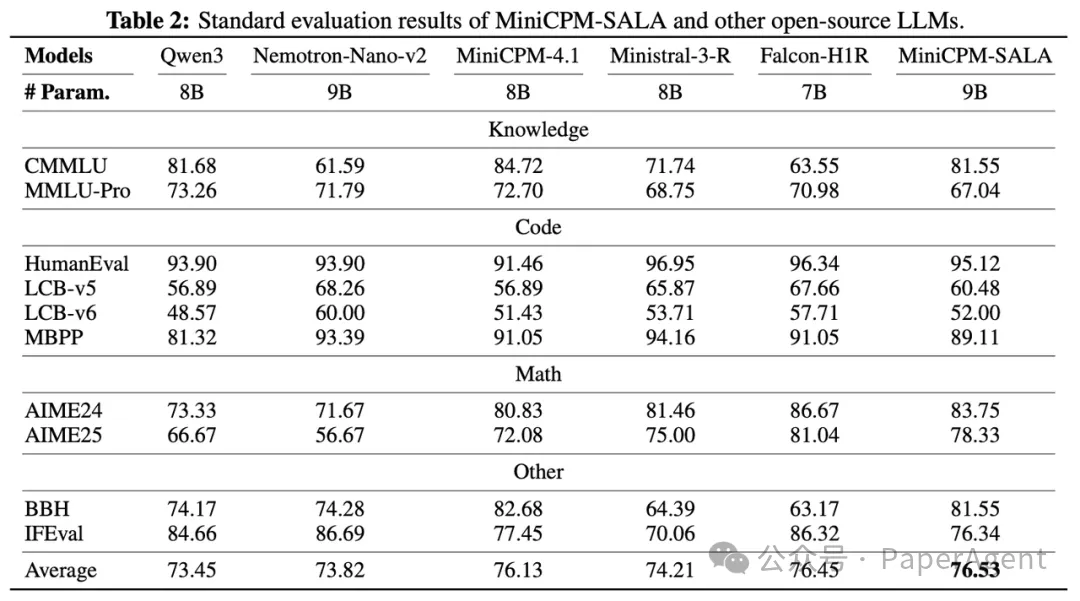
此外,在模型仅有 9B 参数的前提下,MiniCPM-SALA 在知识问答、数学推理、代码生成等核心能力维度上,保持了与同规模全注意力模型相当的卓越水平,真正做到了“长短兼备”。
技术报告核心解读
01 引言:为何需要混合架构?
随着大模型应用场景的深化,处理超长上下文(如整本手册、数万行代码)成为关键能力。传统 Transformer 面临两大瓶颈:
- 计算墙:注意力计算复杂度随序列长度呈二次方增长,导致预填充阶段延迟剧增。
- 显存墙:自回归生成中存储历史 KV-Cache 占用大量显存。
现有稀疏注意力与线性注意力方案各有优劣:稀疏注意力“稀疏计算,稠密存储”,仍受制于显存;线性注意力计算效率高,但存在信息有损压缩导致的精度损失。
MiniCPM-SALA 的混合架构,通过集成 InfLLM-V2 的高保真局部建模与 Lightning Attention 的全局计算效率,旨在同时突破这两面墙。
主要贡献:
- 创新架构设计:提出 SALA 混合注意力,25% InfLLM-V2 + 75% Lightning Attention,平衡性能与效率。
- 高效训练范式:基于预训练权重的架构转换策略,总训练量仅为从头训练的 25%。
- 强大的综合性能:在保持优秀通用能力的同时,长上下文评估优势明显。
- 优越的推理效率:在 A6000D GPU 上 256K 长度推理速度达 Qwen3-8B 的 3.5 倍,并支持消费级 GPU 处理百万词元。
02 模型架构:如何实现混合?
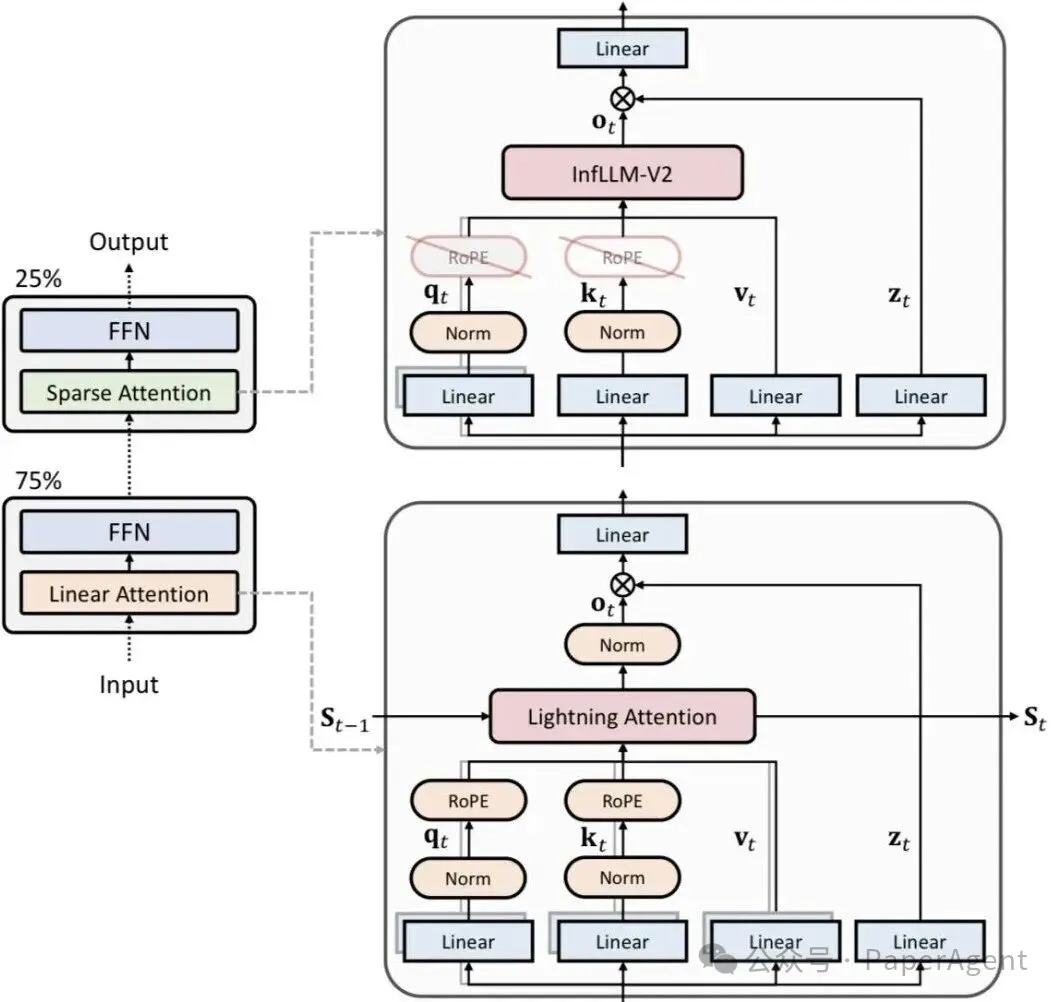
- 总体架构设计:采用交替式混合,25%稀疏注意力层与75%线性注意力层异构堆叠。通过 HALO 算法将预训练的全注意力 Transformer 转换为混合架构,避免冷启动。
- 稀疏注意力模块:采用可切换的 InfLLM-V2,通过块选择机制让每个 Query 只处理关键 Key/Value。训练中可根据序列长度开关稀疏模式,并加入了输出门控机制以提升通用能力。
- 线性注意力模块:选用与全注意力计算范式更接近的 Lightning Attention,以保证与 HALO 转换的良好适配。采用了 QK 归一化、GQA 转 MHA 及输出门控等稳定训练、提升性能的设置。
- 混合位置编码:
- 线性层:保留 RoPE,以保持与转换前模型的一致性。
- 稀疏层:采用 NoPE,使历史 KV-Cache 不耦合位置信息,有效规避 RoPE 的长距离衰减问题,增强极远距离信息召回能力。
03 模型训练:分阶段高效演进
模型训练分为五个高效衔接的阶段,具体如下:
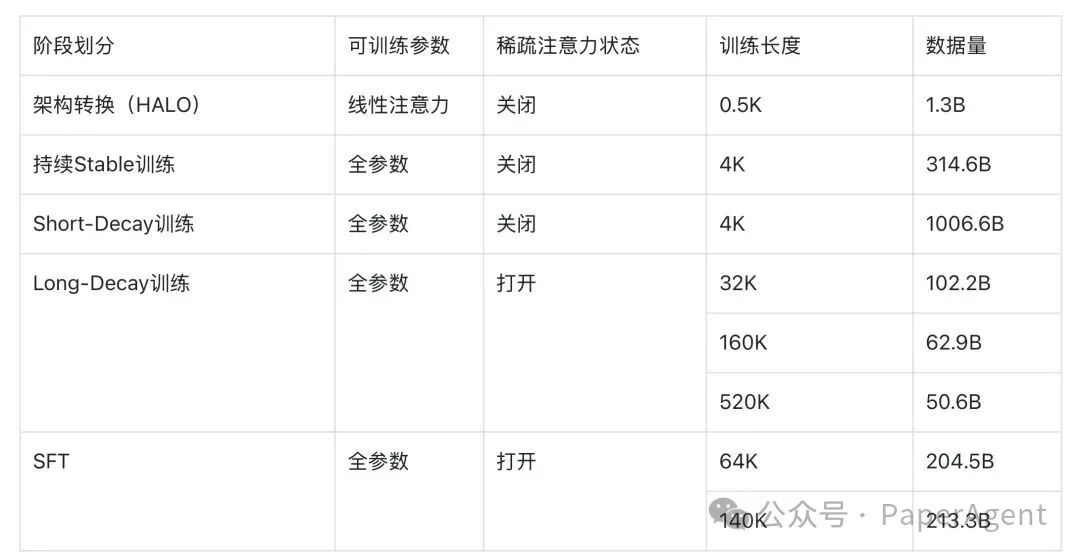
- 架构转换:使用 HALO 方法将 Transformer 转换为混合架构,仅训练转换后的线性层,使用 1.3B 短序列词元高效完成。
- 持续 Stable 训练:序列长度 4K,训练 314.6B 词元,促进转换层与模型其他组件适配,此阶段关闭稀疏注意力。
- Short-Decay 训练:主要训练阶段(1T词元),学习率衰减,序列长度 4K。增加高质量数据权重,引入 PDF 及合成数据,以强化通用与推理能力。
- Long-Decay 训练:逐步将上下文窗口从 4K 扩展至 32K、160K、520K。启用稀疏注意力并进行全参数训练,让模型学习两种注意力的协同作用。
- SFT:使用高质量的推理密集型及长上下文合成数据进行指令微调,依次在 64K 和 140K 长度下训练,全程启用稀疏注意力。
04 模型能力测试:长短兼备
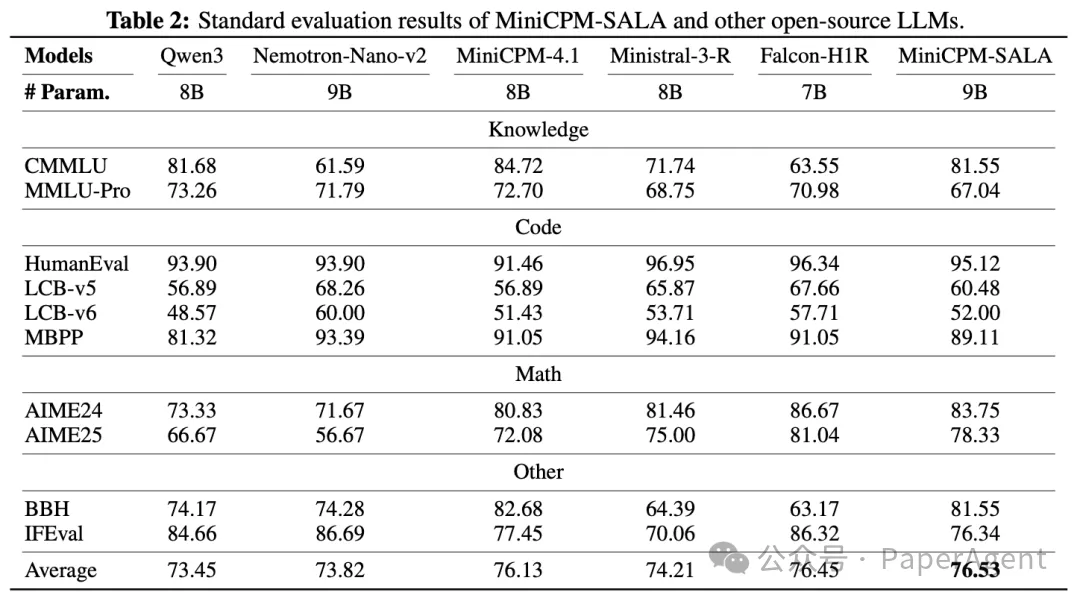
短上下文能力测试:在知识、代码、数学等标准评测集上,9B 的 MiniCPM-SALA 与同规模主流全注意力模型表现相当。
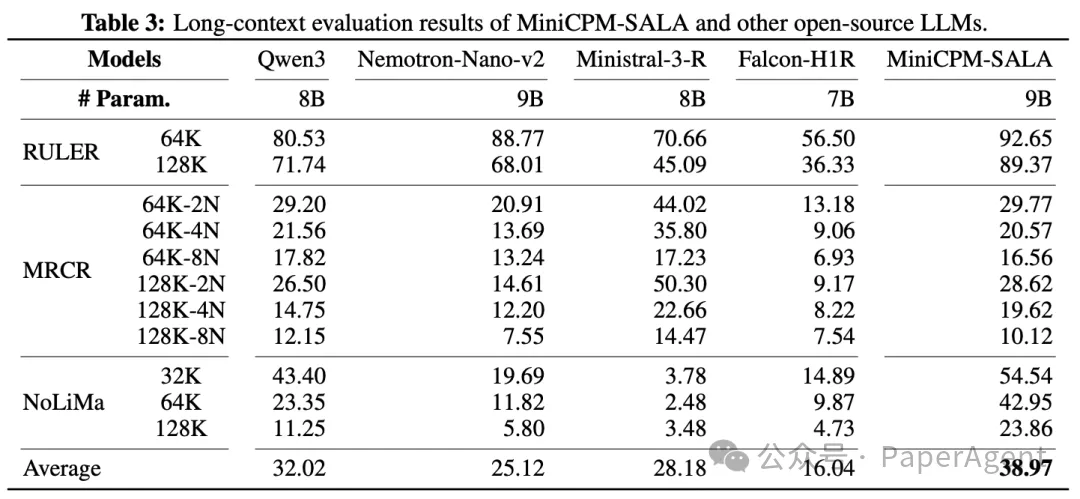
长上下文能力测试:在 RULER、MRCR、NoLiMa 等长文本基准上,MiniCPM-SALA 均表现出明显优势。
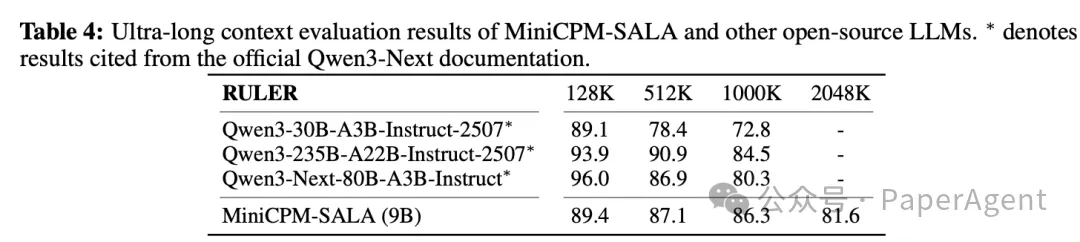
超长序列能力测试:模型展现了优秀的长度外推能力,无需 YaRN 等技术即可有效处理至 2048K 长度,性能衰减平缓。
05 计算效率测试:优势显著
测试对比了 MiniCPM-SALA 与 Qwen3-8B 在 A6000D 和 RTX 5090 上的 TTFT(首字延迟)和端到端延迟。
在 A6000D (96GB) 上:MiniCPM-SALA 在所有序列长度(64K-1024K)和量化状态下均延迟更低。尤其在 256K 长度,非量化 TTFT 从 Qwen3 的 180.8 秒降至 51.6 秒,加速约 3.5 倍。当 Qwen3 在 512K/1024K 遭遇 OOM 时,MiniCPM-SALA 仍可稳定推理。
在 RTX 5090 (32GB) 上:显存优势更为突出。Qwen3-8B 在非量化 128K、量化 256K 时即触发 OOM,而 MiniCPM-SALA 可成功扩展至 1024K 词元,证明了其在消费级硬件上处理百万词元的可行性。
结语
整体而言,SALA 通过融合稀疏与线性注意力,构建了一种面向长上下文高效建模的混合架构,在模型能力与处理效率间实现了出色平衡。它证明了从预训练 Transformer 出发进行架构转换是一条高效可行的技术路径。
随着对长上下文处理需求的爆发,稀疏-线性混合架构正成为最具实效的技术方向之一。面壁智能联合 SGLang、NVIDIA 发起的 “SOAR 2026 稀疏算子加速大奖赛”,也正是为了进一步挖掘该架构在底层硬件上的性能极限。

对于开发者而言,这意味着我们拥有了一个在性能、效率与显存占用上更加均衡的工具。如果你对大语言模型的架构演进、高效推理实践感兴趣,不妨下载 MiniCPM-SALA 尝试,或关注相关开源社区的后续动态,共同探索长上下文应用的更多可能性。
 发表于 2026-2-16 03:55:13
|
查看: 262|
回复: 0
发表于 2026-2-16 03:55:13
|
查看: 262|
回复: 0
