在持续关注《2022 Linux 内核十大技术革新功能》、《2023 Linux 内核十大技术革新功能》及《2024 年 Linux 内核十大技术革新盘点》之后,我们再次聚焦过去一年内核开发的亮点。本文将深入剖析 2025 年 Linux 内核开发中十个最具代表性的 patchset,为你呈现硬核技术年货。
以下是十大技术创新的概览:
- slab per-CPU cache 机制:Sheaves(一捆)和 barns(谷仓)
- sched_ext: cgroup sub-scheduler 支持
- 代理执行 proxy-execution 以解决优先级翻转
- swap table 替代 xarray
- TCP 零拷贝发送 DMABUF
- 调度器时间片扩展 time slice extension
- multi-kernel
- io_uring 的网络零拷贝收包
- io_uring dmabuf 读写支持
- dmem cgroup
下面一一展开描述。
slab per-CPU cache 机制:Sheaves(一捆)和 barns(谷仓)
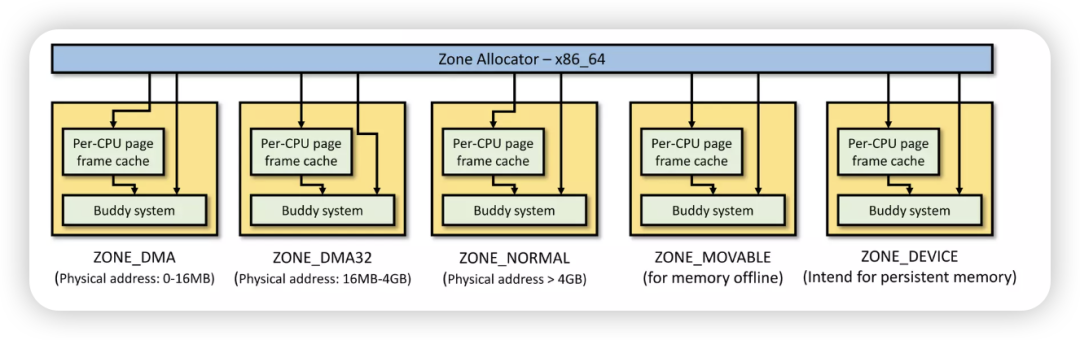
内存管理的 buddy 系统有 pcp (Per-CPU Page frame cache),针对 buddy 申请和释放的内存,维护一定量的 Per-CPU 的 free 内存 list,以减少每次都从底层 buddy 获取、释放 pages 的锁竞争。
对于 Linux 内核 kmalloc/kfree 底层的 slab,实际上我们也需要类似的 per-CPU 机制,来减小 object 申请和释放时跨 CPU 的锁竞争和跨 CPU 的 cache 同步等开销。Vlastimil Babka 的 patchset 把“农场”的 Sheaves 和 Barns 概念借用到内核中,以支撑 slab 的 per-CPU cache 能力。
Sheaves(束/捆)
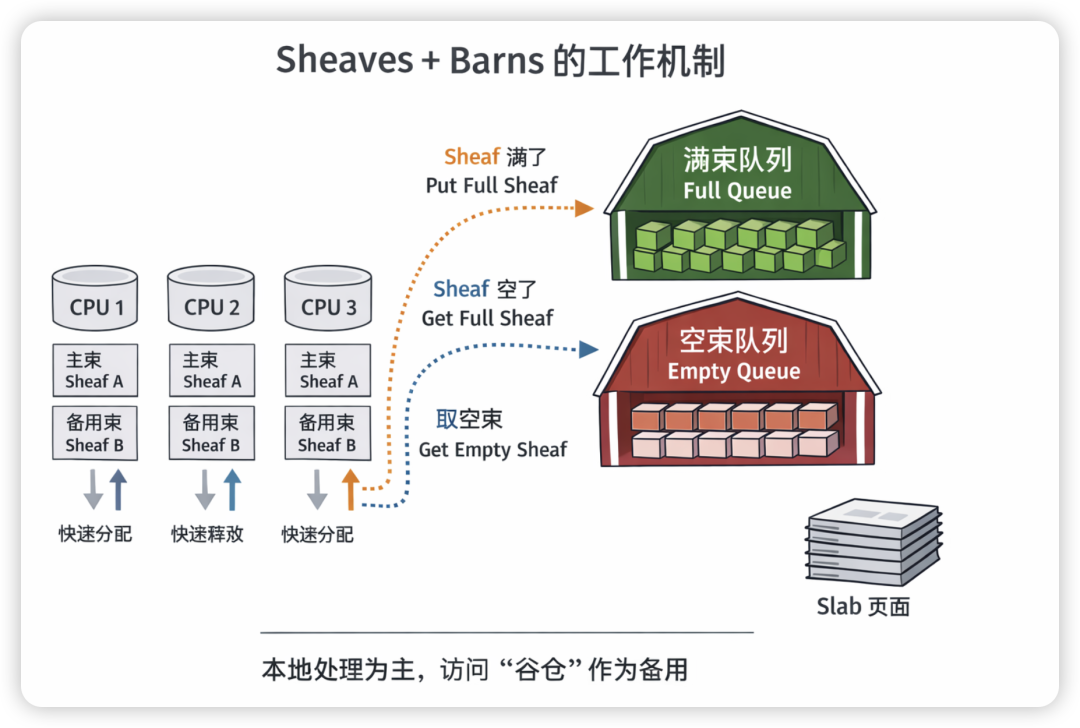
字面意思是 “麦束” 或 “一捆”,内核中指每个 CPU 本地的一小批 slab object 缓存,用于加快本地分配/释放,减少锁竞争。它是一种 per‑CPU 对象缓存,用来快速满足分配和释放请求。每个 CPU 维护两个小缓存(主 sheaf 和备用 sheaf),只要其中有对象,就直接返回/放回,不用去访问全局 slab 页或锁住别人,从而提高性能。分配/释放 object 大多数情况下是 本地、无锁 的操作。
Barns(谷仓/仓库)
字面意思是 “谷仓” 或 “仓库”,内核中指 全局 slab 池(但是是按照 NUMA 来管理的),供各个 CPU 的 sheaves 补充或回收,其功能是保证全局内存平衡,处理 sheaves 空或满的情况。barn 里有两类队列:full(装满对象的 sheaf)和 empty(空 sheaf),方便快速交换。
当某个 CPU 的 sheaves 满了或空了 时,才涉及到 barn(谷仓):
- 空 sheaves:如果分配时 sheaves 空了,CPU 会尝试从 barn 取一个 full sheaf。
- 满 sheaves:释放时 sheaves 都满了,会往 barn 里放一个 full sheaf 或把 sheaf 里的对象回写 slab 页面。
sched_ext: cgroup sub-scheduler 支持
这个 patchset 来自 Tejun Heo,为 sched_ext 增加了基于 cgroup 的子调度器(sub-scheduler)支持,使多个 BPF 调度器可以按 cgroup 层级结构协同运行:父调度器负责在不同 cgroup(租户/分区)之间分配 CPU 资源,子调度器负责各自 cgroup 内部的任务调度。这样系统就能按 workload 分区部署不同调度策略,满足多租户服务器和混部场景下对差异化调度(如延迟优先、吞吐优先等)的需求。比如不同的业务类型需求不一样,可以组成如下层次化的调度系统:
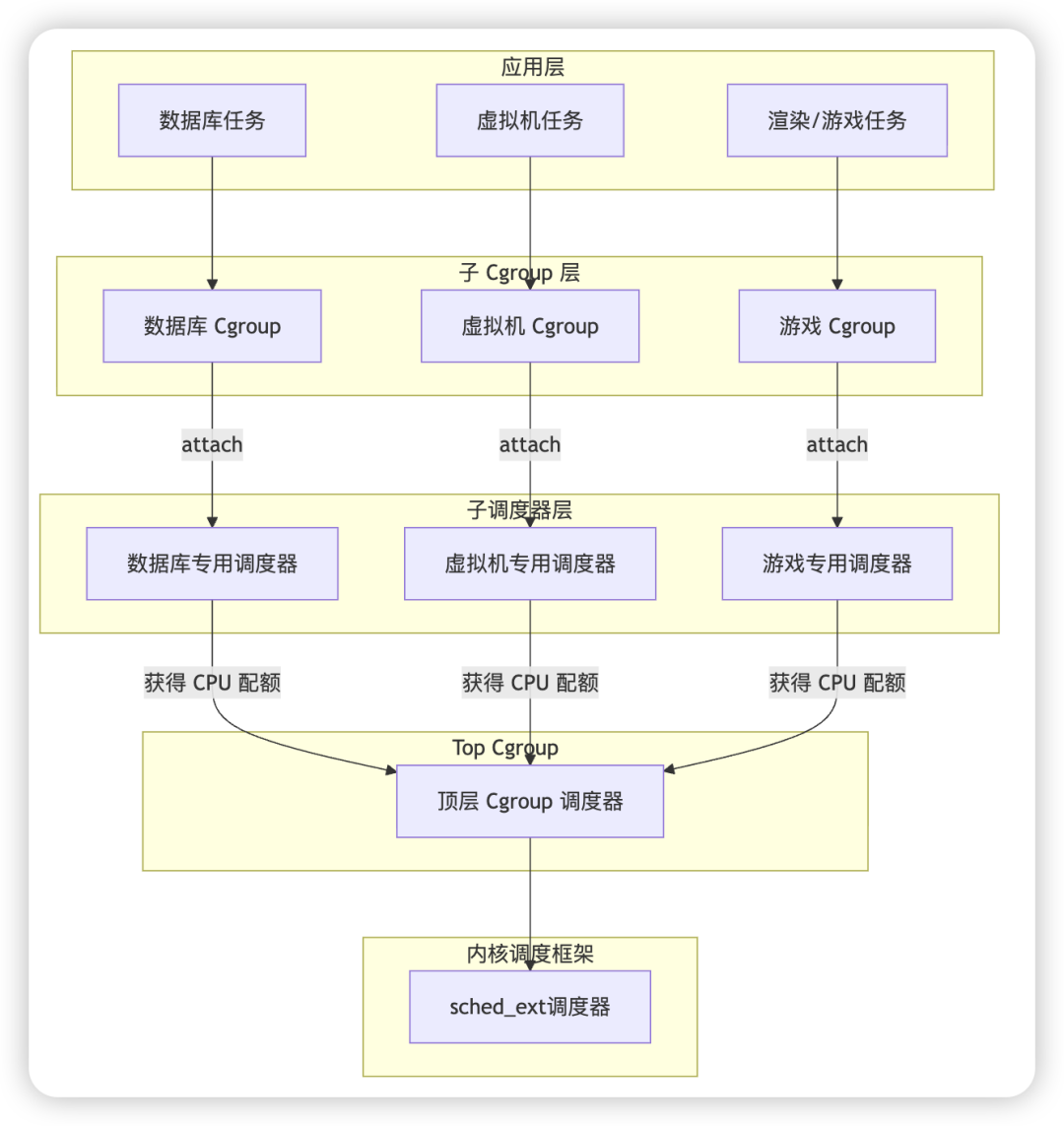
上图中,数据库系统的调度器能够理解查询的优先级和锁持有者的重要性(criticality)。虚拟机管理程序(VMM)可以与虚拟机内部的调度器协同,并智能地安排 vCPU 的位置。游戏引擎的调度器则知道渲染的截止时间,以及哪些线程对延迟敏感(latency-critical)。
每个 cgroup 可绑定一个 scheduler,父 scheduler 通过 dispatch 驱动子 scheduler 获得 CPU 时间,从而形成自顶向下的带宽分配 + 组内调度两级(或多级)结构,目前控制最大深度 SCX_SUB_MAX_DEPTH = 4,防止调度路径过深、复杂度失控。
父 scheduler 在 ops.dispatch() 里面决定哪个子 scheduler 运行以及给多少 CPU 时间。每个 sub-scheduler 都是独立实例,维护自己的运行参数,典型包括:默认时间片(time slice)、watchdog(卡死检测)、bypass mode(旁路模式)、本地 DSQ / runqueue 状态,因此,每个 cgroup 可能成为一个独立调度域。父 scheduler 的 ops.dispatch() 可以调用 scx_bpf_sub_dispatch() 来触发子调度器的 dispatch,child 再选具体 task 运行。
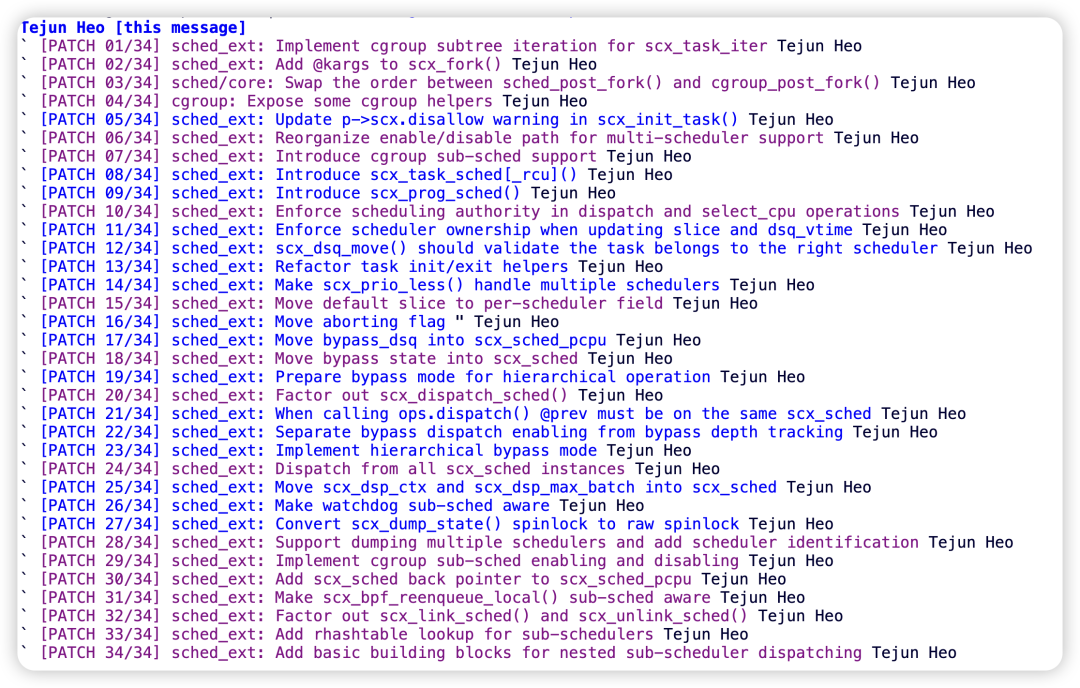
tj 的 patchset 一共 34 个 patch:
代理执行 proxy-execution 以解决优先级翻转
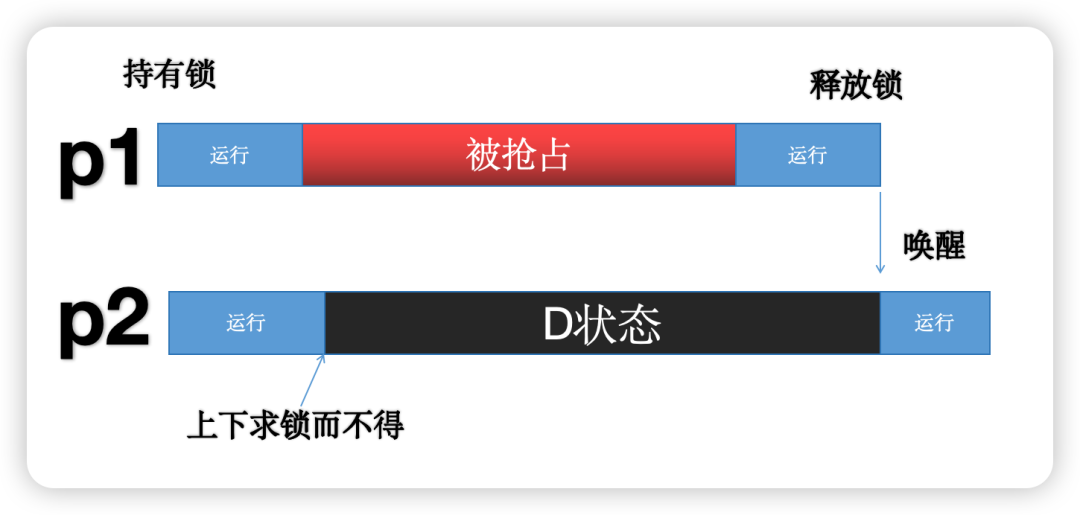
如下图,P2 求 P1 的持有的锁,但是 P1 因为被抢占(时间片耗尽等原因)拿不到 CPU,从而 P2 要等很久才拿到锁,造成用户层面的卡顿体验。
代理执行的逻辑是,在调度层面把调度上下文和执行上下文分开。假设 P2 上下求锁而不得的时候,它会在它的 task_struct 里面记录 block_on 什么任务上面,在这里是 P1,于是 P2 会把自己的时间(调度上下文)“捐献”给 P1 去跑,P1 用 P2 捐献给自己的时间执行 P1 的代码(执行上下文)。
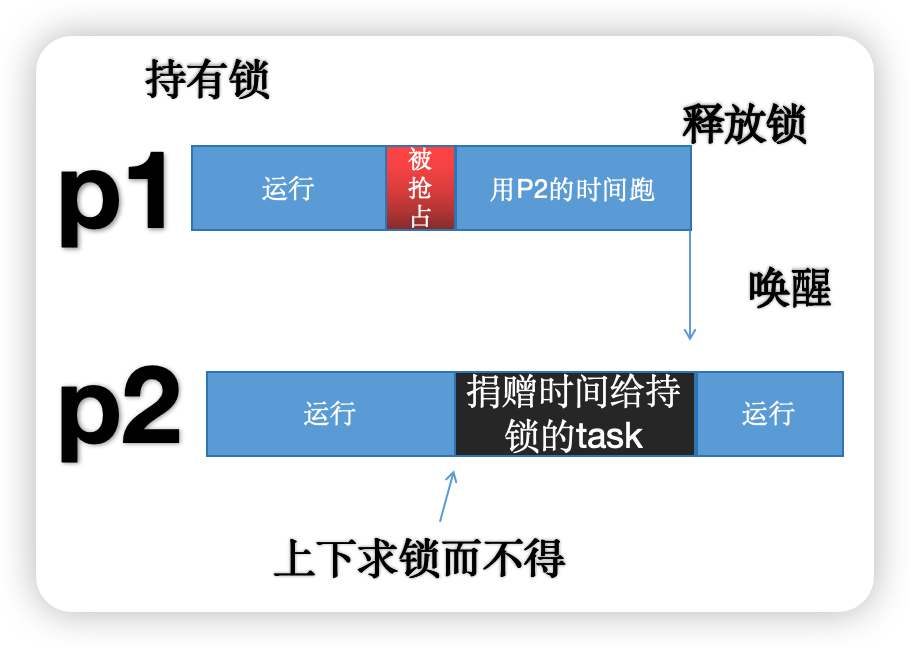
如上图所示,现在 P2 把时间捐给 P1 后,很快 P1 就把锁释放了。然而,魔鬼都在细节里,实际上,这里面有一些复杂的问题:
- P2 把时间捐给 P1 后,P1 运行的过程中说不定会要求持有第 2 个锁等待,因此再次阻塞;显然我们需要把这个捐赠的过程变成一个链条。
- P1 和 P2 可能不在一个 CPU 上,不在一个 runqueue 上面,跨国没法捐。所以我们很可能要把 P2 的调度上下文先迁移到 P1 上面去给 P1。
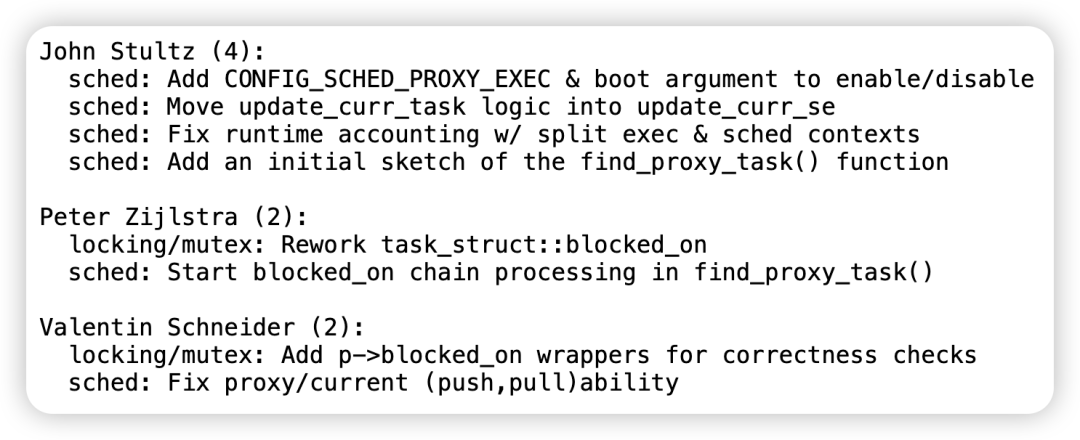
目前 6.17 合入的是一个 baby step,支持 P1 和 P2 本身在一个 CPU 上的时候的代理执行,目前显然没有实际意义,因为哪怕手机只有 8 个核,P1 和 P2 在同一个 CPU 的机会也很渺茫。但是,基于社区迭代开发的流程意义上来讲,这是极其重大的一个进展,它为 proxy execution 的未来开启了一扇大门。关于 Donor Migration 的支持,已成为一个单独的 patchset 来开发和 review。
proxy execution 主要由 Google 的 John Stultz 领导开发,由多名 developer 联合贡献,其首要目的在于改善 Android 系统的用户体验。
swap table 替代 xarray
swap table 本质上是一种替代目前 xarray 管理方式的,更简洁、更高性能的 swapcache 实现。
在 Linux 内核中,我们用 xarray 来描述一个文件的 pagecache 命中情况。比如一个很大的文件,在 pagecache 中只命中了很少的页。拿到相应位置的文件 offset,则可通过 xarray 树形结构的逐级查询(类似多级页表从虚拟地址到物理地址的方式)来获知这些命中页的指针,而其他绝大多数区间由于未在 pagecache 命中,并不需要在 xarray 上分配出元数据。
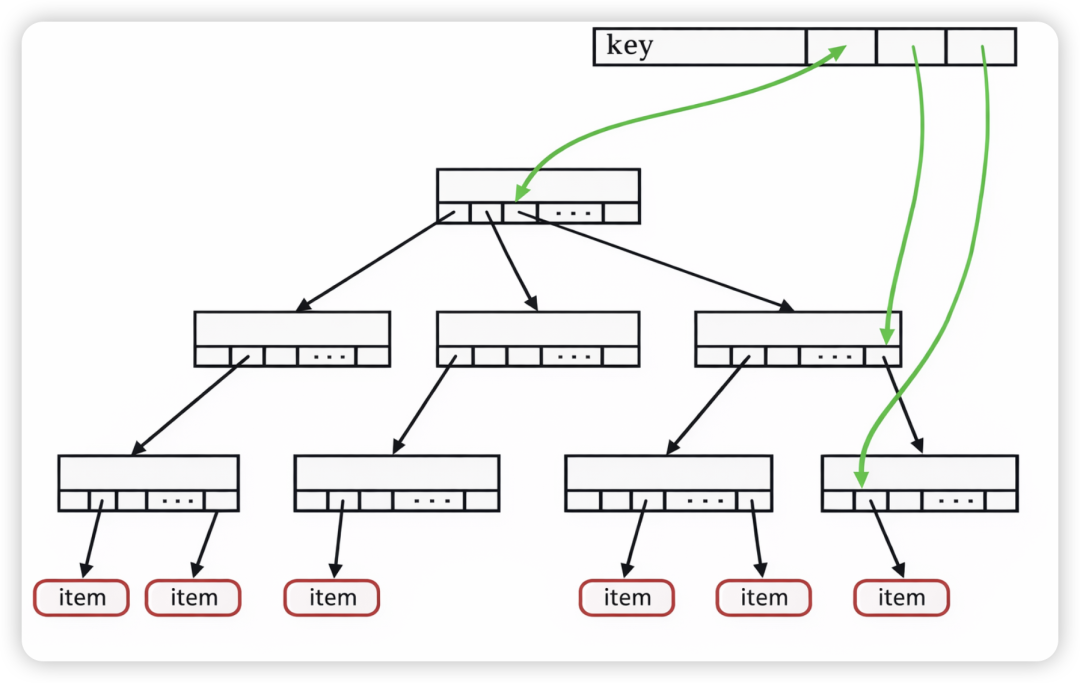
在 Linux 内核的实现中,针对匿名页,也存在一种与文件页的 pagecache 类似的东西,叫 swapcache。swapcache 可简单理解为一张表,给到一个 offset,可以查询到对应 swap slot,是否在内存也有副本,如果有,副本是哪一个 page。
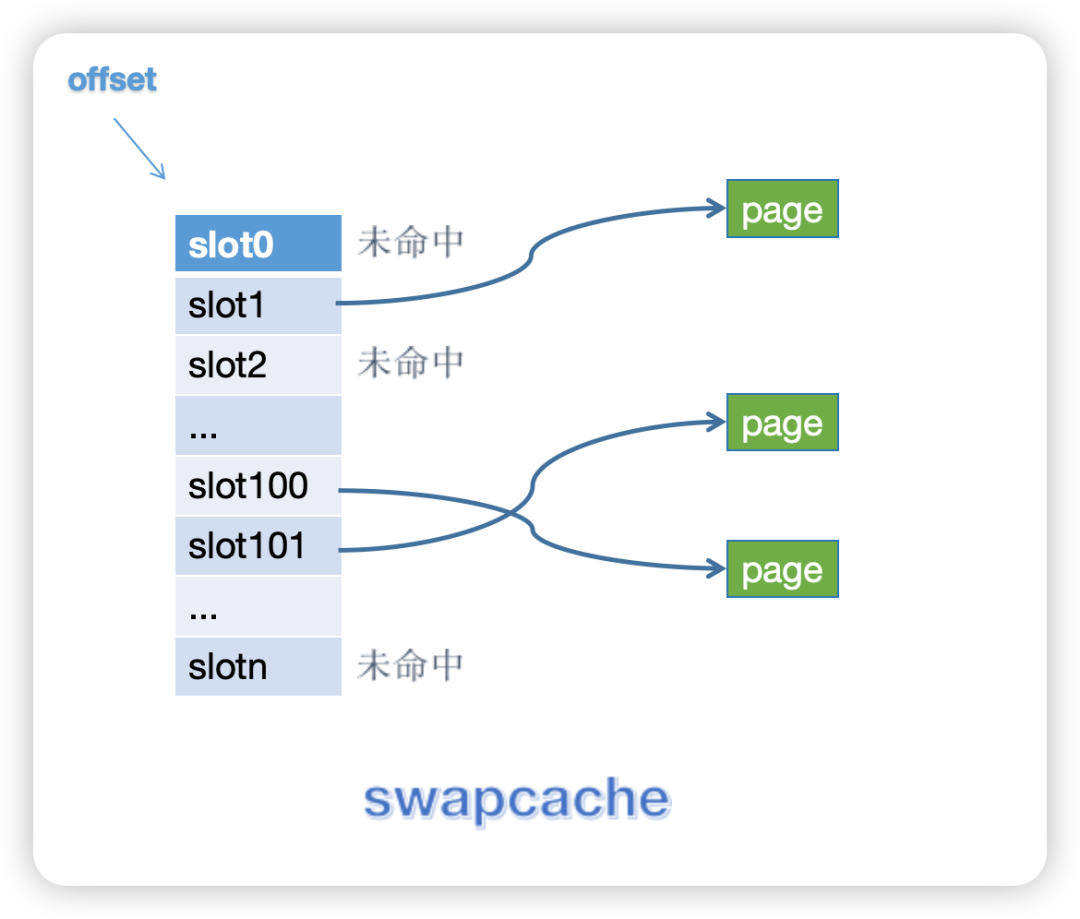
在 swapcache 的管理上,Linux 内核采用了与文件页 page cache 管理相似的做法,甚至底层 swapcache 的查询 API 都间接是文件的 API:
struct folio *swap_cache_get_folio(swp_entry_t entry, struct vm_area_struct *vma, unsigned long addr) {
struct folio *folio;
folio = filemap_get_folio(swap_address_space(entry), swap_cache_index(entry));
if (!IS_ERR(folio)) {
目前 Linux 内核把 swap 分区/文件的每 64MB 组织为一个 address_space,每 64MB 作为 1 个 xarray 来描述。
/* linux/mm/swap_state.c */
/* One swap address space for each 64M swap space */
#define SWAP_ADDRESS_SPACE_SHIFT 14
#define SWAP_ADDRESS_SPACE_PAGES (1 << SWAP_ADDRESS_SPACE_SHIFT)
#define SWAP_ADDRESS_SPACE_MASK (SWAP_ADDRESS_SPACE_PAGES - 1)
extern struct address_space *swapper_spaces[];
#define swap_address_space(entry) (&swapper_spaces[swp_type(entry)][swp_offset(entry) >> SWAP_ADDRESS_SPACE_SHIFT])
swap 相对文件其实是有显著区别的:
- swap 分区/文件的数量是相对有限的,往往就是 1 个,常见的配置也很难超过 4、5 个。不像文件,可能成千上万无数个。
- swap 的大小相对来说是固定的,可预测的。比如开机配置好了,就基本不动了。不像文件,有大有小,大则多少个 T,小则多少个 B,五花八门。
- swap 的访问模型相对可控,针对特定的 workload 场景,有多少 swap 空间会被用到,相对来说是可预测的。
这为 swapcache 的至简化设计创造了可能性,swap table 的设计和实现诞生了。
假设一个 swap 分区是 2GB,我们先把这 2GB swap 空间按照 2MB 拆分为 cluster:

而每个 cluster 内部则有 512 个 swap slot。

swap table 的设计理念非常简单,它为每个 cluster 给出 512 个 unsigned long 型数据,这个 unsigned long 数据可以存放 swapcache 命中的 page(现在我们或可别扭地称呼它为“folio”)的指针,或者是 shadow(用于 refault 机制),或者是 NULL。
static int swap_table_alloc_table(struct swap_cluster_info *ci)
{
WARN_ON(ci->table);
ci->table = kzalloc(sizeof(unsigned long) * SWAPFILE_CLUSTER, GFP_KERNEL);
if (!ci->table)
return -ENOMEM;
return 0;
}
这样,对于 64 位的 arm64, x86_64 等 arch 而言,每个 cluster 的 swap table 占据的内存正好是 4KB。
根据 swap offset,我们通过它的高位可以找到它属于哪个 cluster,而通过它的低位可以找到它对应 512 个 slot 里面的哪一个 slot:
static inline struct swap_cluster_info *swp_cluster(swp_entry_t entry)
{
return swp_offset_cluster(swp_info(entry), swp_offset(entry));
}
static inline unsigned int swp_cluster_offset(swp_entry_t entry)
{
return swp_offset(entry) % SWAPFILE_CLUSTER;
}
由此可见,这个检索过程是相对于 xarray 而言是更快的,相对于 xarray 原先的 O(logN),现在可认为是 O(1)。原先 swapcache 虽然限制了每个 address_space 的大小为 64MB,但是树的深度还是可以达到 3 级的。
另外,由于一个 cluster 的 swap table 的内存都聚集在同一个 page 里面,当 swap out 密集发生在同一个 cluster 的时候,它能表现出更强的 locality 局部性,有利于减小 cache miss 等。xarray 的树形结构以及基于 slab 的内存管理方式,则更可能在多个 page 里面来回跳跃访问。
xarray 的树管理一个更广阔的范围,每个 address_space 为 64MB,这意味着,会跨越多个 cluster,64MB 的范围需要统一管理和加锁,并且 cluster 内部的访问也需要 cluster lock。而 swap table,本身不会垮 cluster,仅在一个 cluster 内部访问,只需要对 2MB 的 cluster 本身加锁。由此去掉了原先管理 xarray 树形结构的锁需求。
最后,大道至简,swap table 这种类似数组的设计思路,写出来的代码人人都能看得懂。
关于 swap table 内存占用方面的优化,在 [PATCH 8/9] mm, swap: implement dynamic allocation of swap table 中,Chris 和 Kairui 实际安排了 swap table 的动态释放,在一个 cluster 里面的 512 个 slot 都没人用的时候,这个 cluster 的 swap table 可以释放。
由于 swap table 的显著优势来源于查询路径的缩短、locality 的提升、lock contention 的减小,相对 xarray 加速了 swapcache 的查询、修改等操作,属于基础设施的改善,其优势在服务器等场景会呈现较大的实用价值,对一些关键业务的吞吐量带来提升。
TCP 零拷贝发送 DMABUF
Device Memory TCP (devmem TCP) 完成了 2 个目标:
- 通过网络发送设备 memory。底层的设备 memory 采用 dma-buf 机制;
- 通过网络接收设备 memory 并直接存入本地的设备 memory。
因此,它是一种 Direct-to-device 的网络方法。
我们知道 dma-buf 提供了一种本机内部设备与设备、设备与设备共享内存的方法。简单地来说,dma_buf 可以实现 buffer 在多个设备的共享,应用可以把一片底层驱动 A 的 buffer 导出到用户空间成为一个 fd,也可以把 fd 导入到底层驱动 B。当然,如果进行 mmap() 得到虚拟地址,CPU 也是可以在用户空间访问到已经获得用户空间虚拟地址的底层 buffer 的。
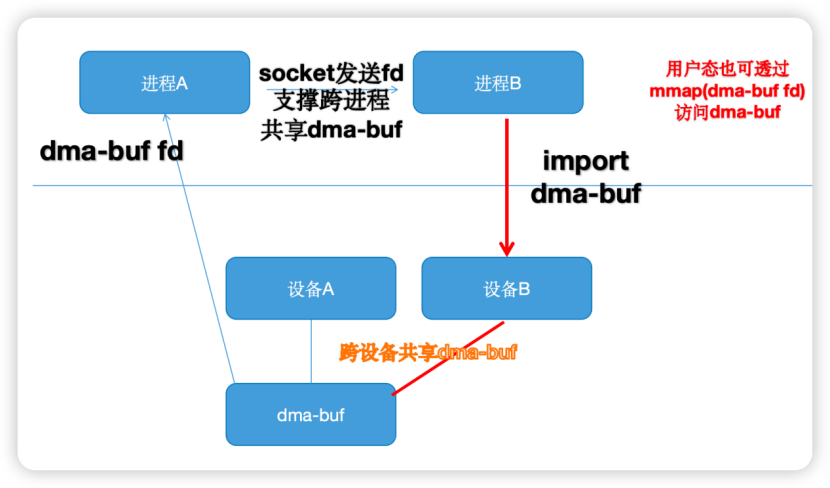
devmem TCP 实际上把 dma-buf 的传输扩展到网络上并非本机的设备、CPU 之间了。由于是 A 机器的 dma-buf 送到 B 机器的 dma-buf,这样避免了设备的 dma-buf 和 host buffer 之间的拷贝。
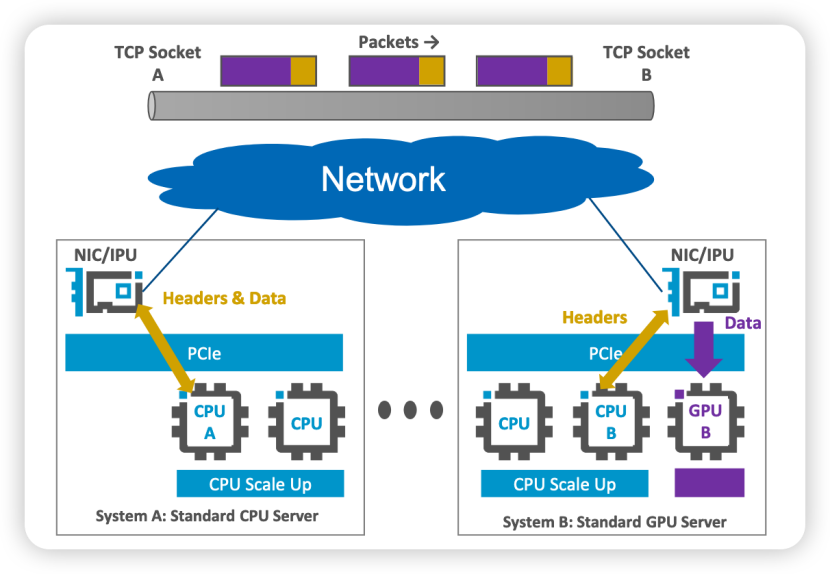
跨节点的 device 到 device 的传输,在下面的一些应用场景中可能受益:
- 分布式训练,即在不同主机上的机器学习加速器(如 GPU)之间交换数据。
- 分布式 raw block storage 应用与远程 SSD 传输大量数据。其中大部分数据不需要主机处理。
相关的 patchset 主要由 Google 的 Mina Almasry 完成,Linux 6.12 中支持了 rx,而 6.16 内核中,也支持了 TCP dmabuf 的 tx 路径。接收端的网卡应支持 header 的自动分离,并且支持 flow steering、RSS,确保目标是 devmem 的网络包能流向正确的 RX queue。
调度器时间片扩展 time slice extension
想象用户态的线程 A 拿到了 spinlock,由于用户态 spinlock 并不会像内核态 spinlock 那样禁止抢占,完全有可能线程 B 抢占线程 A,线程 B 可能运行很久,而假设线程 C 需要等待线程 A 的 spinlock 释放,这个 C 的等待可能是非常长的。
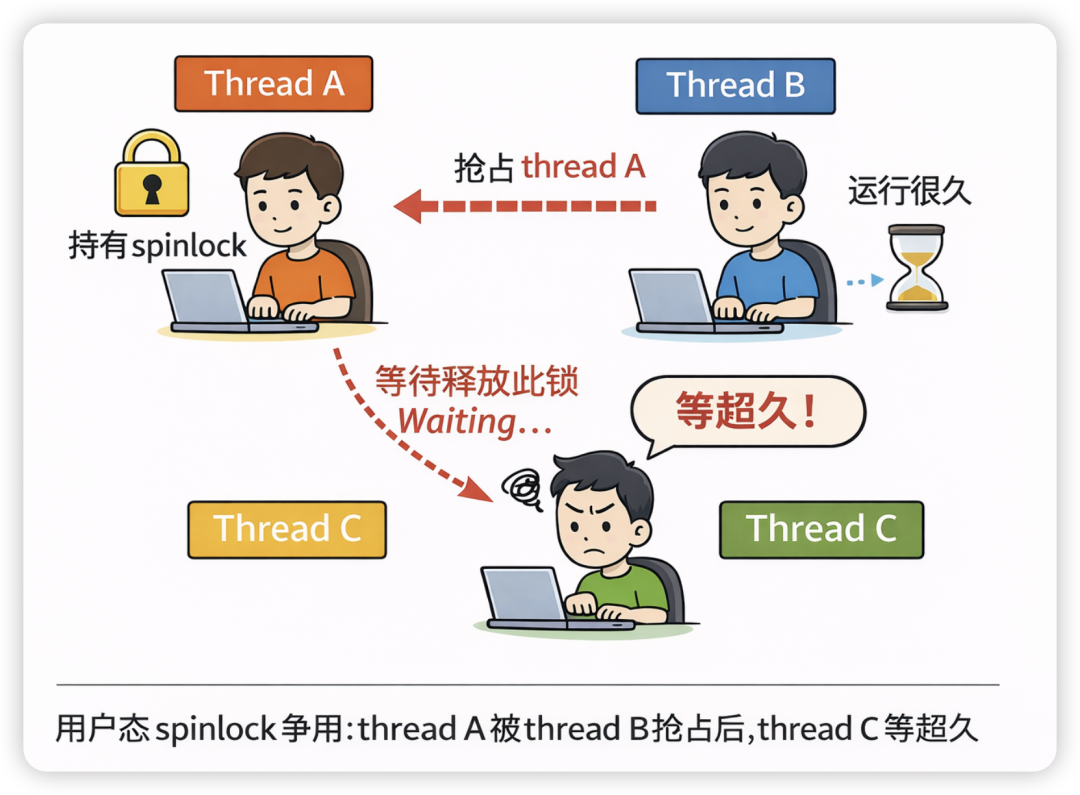
如果我们提供一个机制,比如线程 A 拿到了 spinlock,在 critical section 里面执行的过程中,若发生时间片用完或者其他什么事情要抢占 A,调度器可以扩展一点点时间片给 A,比如 50 微妙内让 A 不被抢占,则线程 A 大概率可以执行完 critical section,从而规避一系列问题。而具体扩展时间片的长度则可由新增的 rseq_slice_extension_nsec 这个 sysctl 决定。
用户空间线程通过 prctl() 显式地告诉内核,它需要时间片扩展:
prctl(PR_RSEQ_SLICE_EXTENSION, PR_RSEQ_SLICE_EXTENSION_SET,
PR_RSEQ_SLICE_EXT_ENABLE, 0, 0);
有一个 per-cpu 的 Restartable sequences(简称 rseq)供用户态和内核态交互,需要时间片扩展的一个典型的用户态伪代码如下:
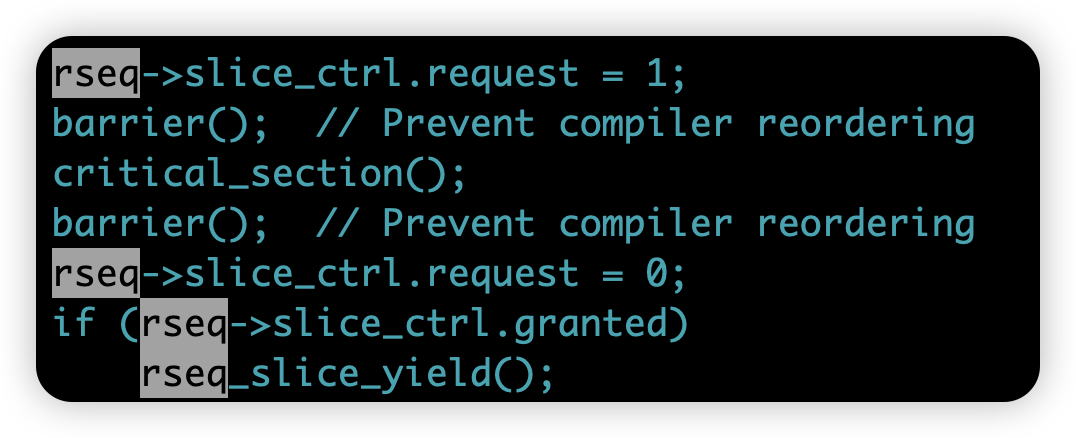
如果线程通过 prctl() 启用了该机制,就可以把 rseq::slice_ctrl::request 设为 1 来请求延长当前时间片。当线程被中断且内核因此产生重新调度请求时,内核看到了用户态设置了 rseq::slice_ctrl::request =1,它可能选择不立即把线程换下 CPU,而是批准一次 rseq_slice_extension_nsec 时间片扩展并直接返回用户态继续执行。
当内核同意时间片扩展时,会把 rseq::slice_ctrl::request 清零,并将 rseq::slice_ctrl::granted 置为 1,表示扩展已批准;如果在扩展之后线程仍然被 resched(被换下 CPU),内核会再把 granted 位清零,用来通知用户态这次扩展已经结束或失效。
基于 RSEQ 的时间片扩展工作,主要由 Thomas Gleixner 和 Peter Zijlstra 完成。
multi-kernel
Cong Wang 在 LKML 发送了一个 RFC 序列,支持 multi-kernel。multi-kernel 与容器、hypervisor 都有本质不同,它在同一台机器上并行运行多个 Linux kernel,每个 kernel 独占一部分硬件,并通过消息通信协作。
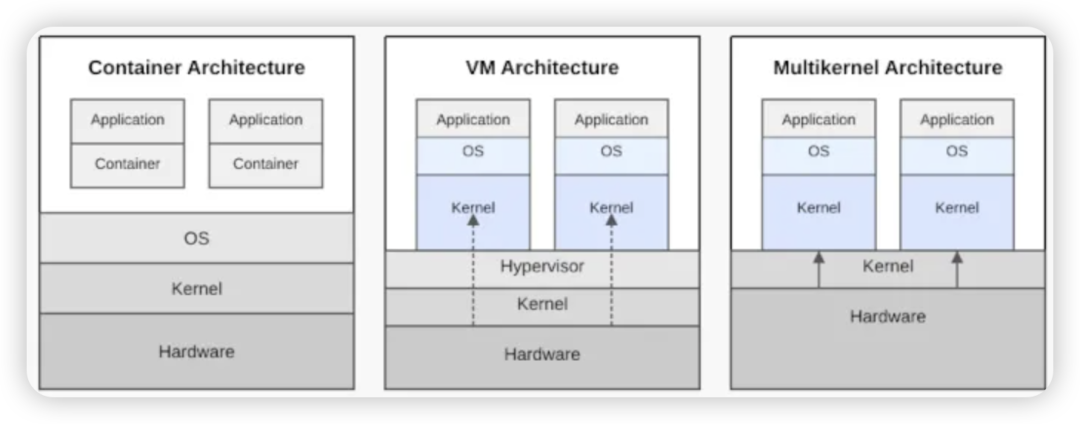
在 Cong Wang 建议的方法中,host kernel 管理 spawn kernel。
Host kernel 负责:硬件资源管理、创建 / 销毁子 kernel、跨 kernel 协调。Spawn kernel 负责跑应用、具备独立调度 / 内存 / IO 并与其他 kernel 隔离。Cong Wang 的 multi-kernel 实现可以概括为:
- 用 kexec 在同机启动多个 Linux
- 用 CPU / 内存 / IO 硬件分区做隔离
- 用 IPI + 共享内存通信
- 用 hotplug + DT overlay 动态调资源
- 用硬件 queue 切分 IO
- 每 workload 跑定制 kernel
这个 multi-kernel 方案未来会走向何方、能否在 Linux 内核上游社区引起足够关注和投入,都会是很值得观察的看点。
io_uring 的网络零拷贝收包
由 Pavel Begunkov 和 David Wei 完成的工作,正式合入 Linux 内核 6.15,为 io_uring 增加了零拷贝接收(zero-copy receive)支持,使数据能够直接批量、快速地接收并写入应用程序内存,而无需再从内核内存中拷贝一份。
io_uring 的零拷贝与 DPDK 有很大不同,DPDK 完全 bypass 了内核,而 io_uring 这种内核为 userspace 提供的 async I/O 模式,则仍然重用了内核的网络机制,如下图,借鉴硬件的支持,payload 被硬件直接 DMA 到 userspace 的 buffers。
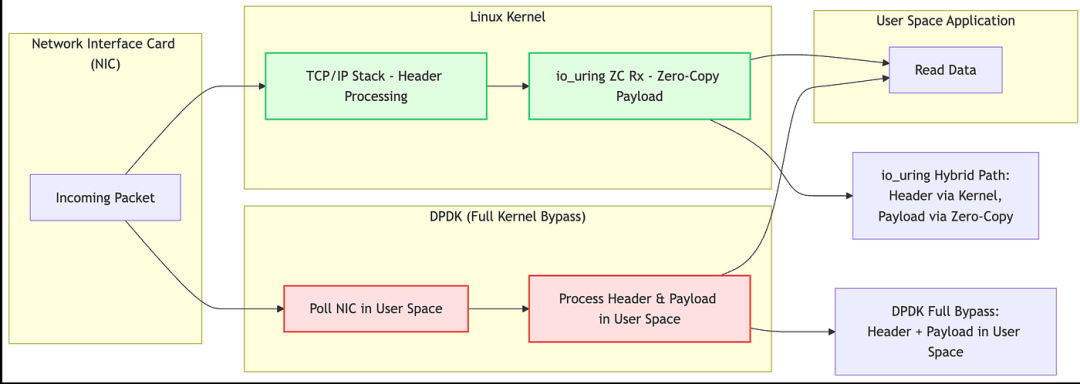
io_uring 提供了一种“混合旁路(hybrid bypass)”机制:在保持与 Linux 内核体系紧密集成的同时,实现了显著的性能提升。相比 DPDK 这种完全旁路(full bypass)方案,它在使用上更加便捷,对现有系统的侵入性也更低。
它的整个工作流程如下:
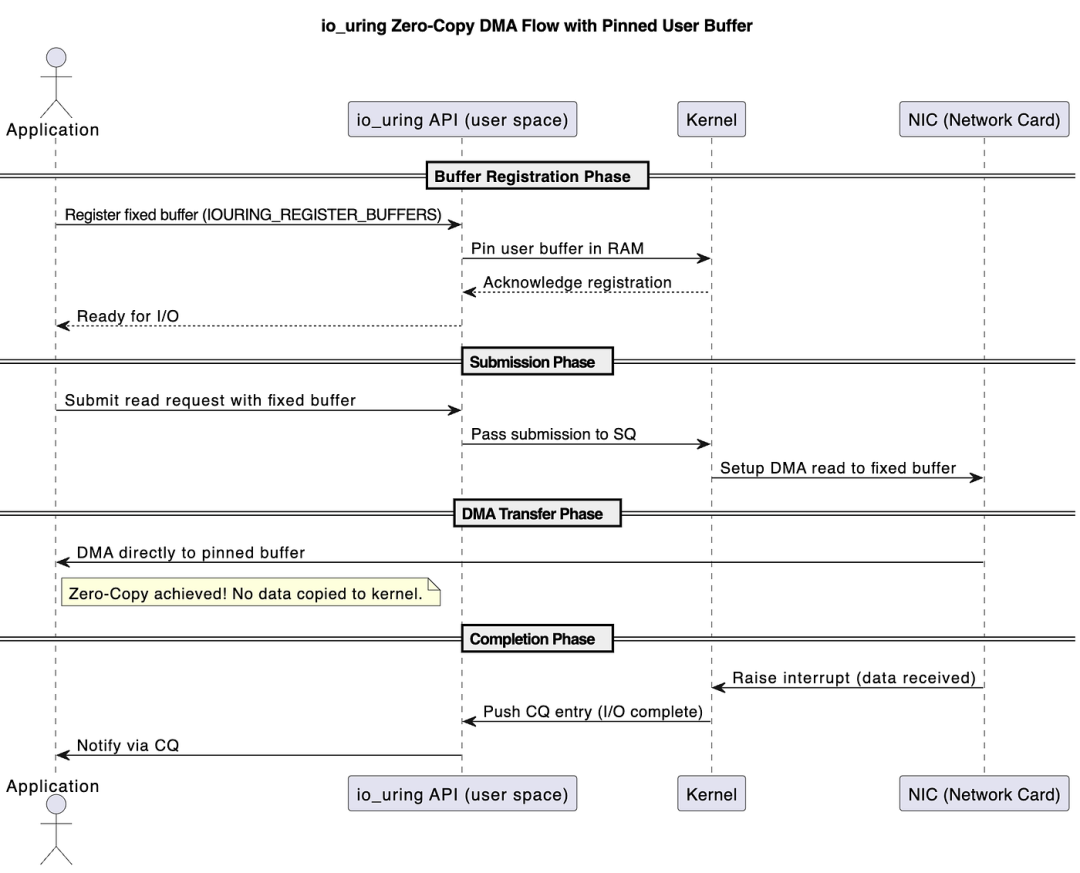
在 io_uring 中,用户和内核通过 2 个 queue 交互:SQ(Submission Queue)、CQ(Completion Queue)。

由于 DMA 要直接往 userspace 的 buffers 里面传输数据,所以 buffer 需要在内核 pin 住,相关 API 是:io_uring_register_buffers()。
与前面的 devmem TCP 相似,该机制也依赖于硬件的报文头/数据分离(header/data split)、流量引导(flow steering)以及 RSS(接收端扩展),以确保数据包头部保留在内核内存中,而只有目标流量才会被导向配置为零拷贝的硬件接收队列。
io_uring dmabuf 读写支持
这个 patchset 试图让存储设备(如 NVMe)可以直接 DMA 到 dmabuf 所代表的内存,而不是走用户页缓存 / copy 路径。
用户态发起:
io_uring_update_buffer(ring, idx,
{ dma_buf_fd, file_fd });
即:
- 提供 dmabuf fd
- 提供目标 file fd(如 nvme block)
发起读:
io_uring_prep_read_fixed(..., reg_buf_idx);
注意这套能力不是给通用文件 I/O 准备的,而是给高性能数据管线 / 设备直通 pipeline 用的,不是 ext4 / f2fs 等文件读写。
该 patchset 把 dmabuf 封装成一种可被 block 层提交和 DMA 的 buffer 类型,让存储设备可以直接对 dmabuf 做 DMA。主要实现原理(4 步):
A. 注册:dmabuf → dma_token
用户用 dmabuf fd 注册 io_uring buffer 时:
dma_buf_get() -> dma_buf_attach(target_device) -> dma_buf_map_attachment() → stable
然后封装成一个内部对象:dma_token,它代表一块可 DMA 的共享内存。
B. 提交 IO:新 iterator 类型
新增一种 buffer 迭代器:ITER_DMA_TOKEN
提交 read/write 时:
SQE → dma_token → iov_iter
让 block 层识别这是 dmabuf,而不是用户页。
C. 构建 bio / request
block 层改造后可以:
bio → dma_token → sg_table
不再依赖 page,而是直接用 dmabuf 的 scatter-gather 表。
D. Driver DMA
以 NVMe 为例:
sg_table → PRP / SGL → device DMA → dmabuf
实现存储设备直接 DMA 到 dmabuf 内存。
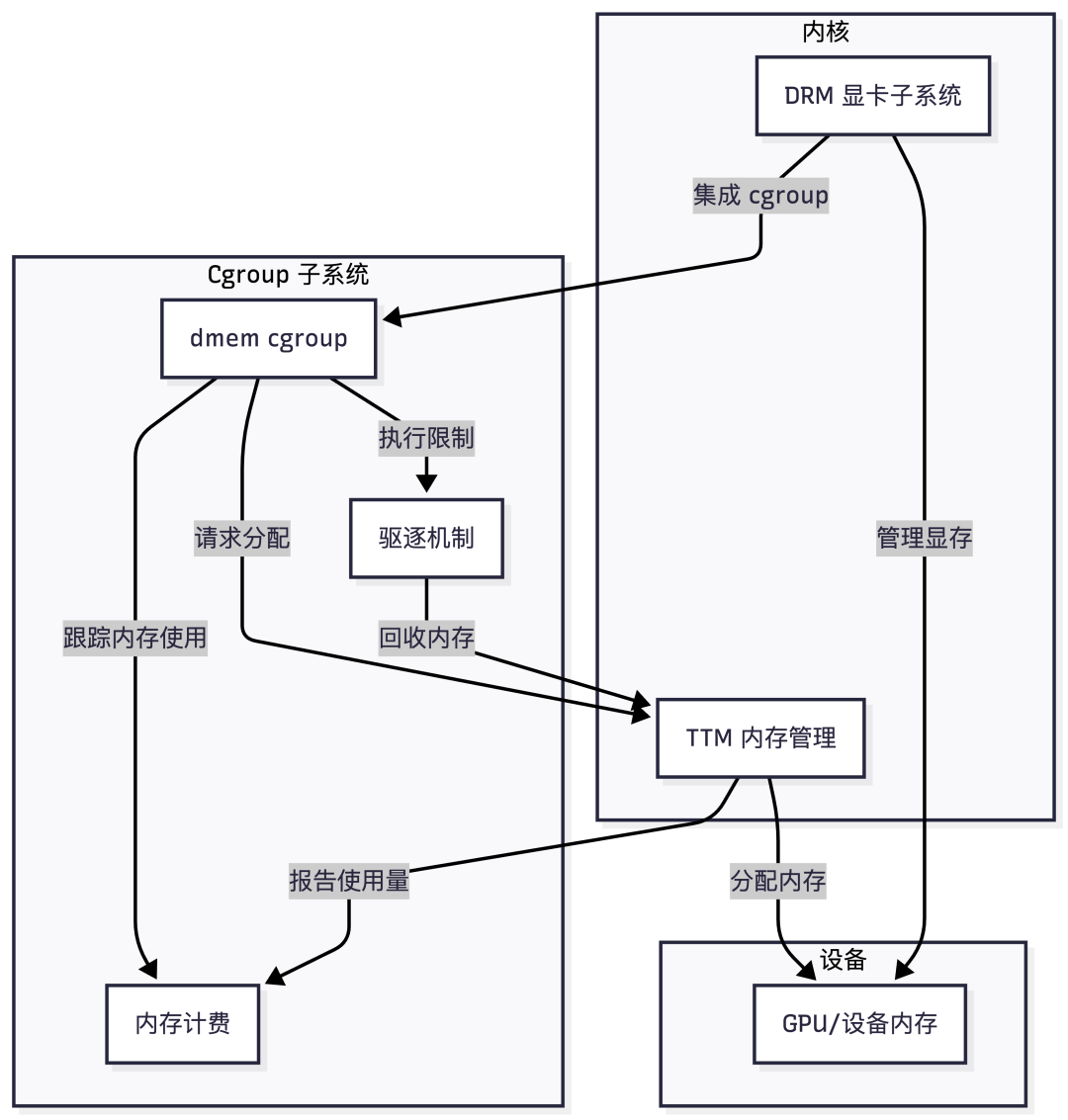
dmem cgroup
在较早的内核中,cgroup 已经可以管理普通系统内存(RSS、swap 等),但缺少针对 GPU / 加速器设备内存的统一计量与限制机制。
dmem cgroup 是用来对“设备私有内存(device memory)”做资源隔离与计量的 cgroup 控制器。它管的不是普通 DRAM,而是 GPU、accelerator 和其他的 device 本地内存。dmem cgroup 目的在于:
- 让 cgroup 能统计设备内存使用量;
- 能针对这些内存设置 min/low/max 限制;
- 能在资源过度使用时做 eviction(回收/驱逐)
在 Linux 6.14 中,DMEM cgroup 支持已经集成到 Intel Xe 内核图形驱动中,用于根据 cgroup 层级限制显存(vRAM)的使用。这个用于显存内存计数的 DMEM cgroup 代码,也可以“轻松地”被其他依赖 TTM(Translation Table Maps)进行内存管理的内核图形驱动复用。
dmem 的 cgroup 接口如下:
dmem.current:当前 cgroup 使用的 device memory 字节数;dmem.max, dmem.min, dmem.low: nested-keyed(支持层级键值),用于配置不同 cgroup 的内存资源限制;dmem.capacity:显示该内存区域的最大容量,仅存在于 root。
dmem 的整个实现原理如下:
结语
从 Sheaves & Barns 优化内存分配,到 sched_ext 实现层级化调度,再到跨越网络的零拷贝 DMA 传输,2025 年的 Linux 内核创新再次证明了其在高性能计算与系统资源精细化管理方面的强大活力。这些改进不仅提升了内核本身的效率,也为上层应用,尤其是云计算、AI 训练和实时系统等领域,提供了更坚实、更灵活的基础设施。对于持续跟踪内核发展的开发者和技术爱好者而言,深入理解这些变革是把握未来技术趋势的关键。想了解更多前沿技术动态与实践,欢迎访问 云栈社区 进行交流探讨。
参考文献:
- slab sheaves 和 barns: https://lore.kernel.org/linux-mm/20260123-sheaves-for-all-v4-0-041323d506f7@suse.cz/
- sched-ext sub-schedulers: https://lore.kernel.org/lkml/20260121231140.832332-1-tj@kernel.org/
- 代理执行 Proxy Execution: https://lwn.net/ml/all/20250712033407.2383110-1-jstultz@google.com/ , https://lwn.net/ml/all/20250722070600.3267819-1-jstultz@google.com/
- scheduler 时间片扩展: https://lore.kernel.org/lkml/20251215155615.870031952@linutronix.de/
- tcp dmabuf tx 零拷贝: https://lore.kernel.org/netdev/20250508004830.4100853-1-almasrymina@google.com/
- io_uring zero_copy rx: https://lwn.net/Articles/1004591/
- io_uring file->dmabuf: https://lore.kernel.org/all/cover.1763725387.git.asml.silence@gmail.com/
- dmem cgroup: https://lore.kernel.org/lkml/20241204134410.1161769-1-dev@lankhorst.se/
- swap table: https://lore.kernel.org/linux-mm/20250822192023.13477-1-ryncsn@gmail.com/ , https://lore.kernel.org/linux-mm/20250514201729.48420-25-ryncsn@gmail.com/
 发表于 2026-2-17 03:20:37
|
查看: 340|
回复: 0
发表于 2026-2-17 03:20:37
|
查看: 340|
回复: 0
