在海量数据成为常态的今天,高效存储与快速查询是数据平台的核心诉求。自2013年诞生以来,Apache Parquet格式已演进为大数据生态系统中列式存储的事实标准。它究竟凭借何种设计脱颖而出?本文将深入剖析其架构原理与性能优势。
行存储与列存储:根本性差异
理解Parquet优势的起点,在于厘清行存储与列存储的本质区别。
传统的行存储格式(如CSV或某些模式的Avro)将数据按行序列组织。每一行所有字段的值被连续存储在一起,这种模式非常适合需要频繁读取或写入整条记录的事务处理(OLTP)场景。
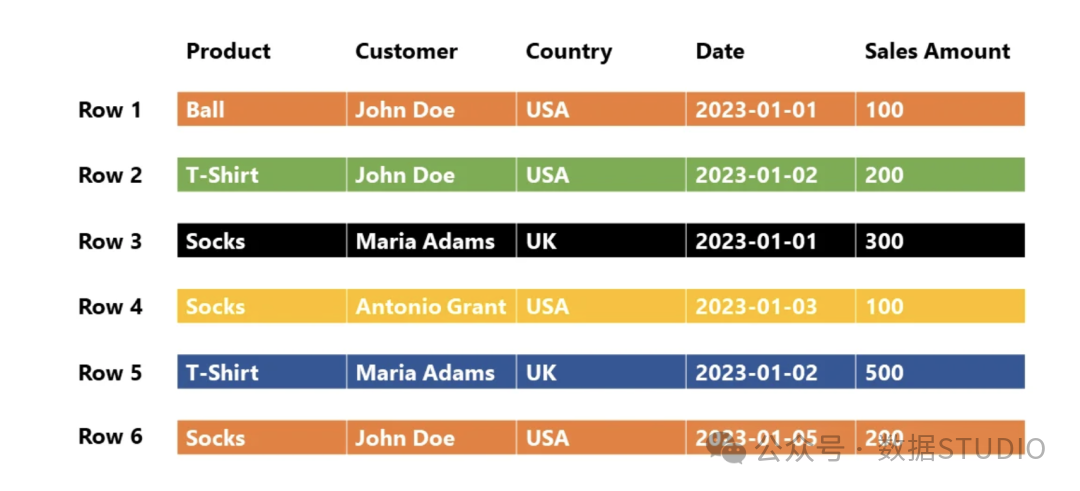
相比之下,列存储格式(以Parquet为代表)将每一列的数据独立存储。这种结构天然适配分析型查询(OLAP),因为此类查询通常只涉及表中少数几个列,而无需扫描全部字段。
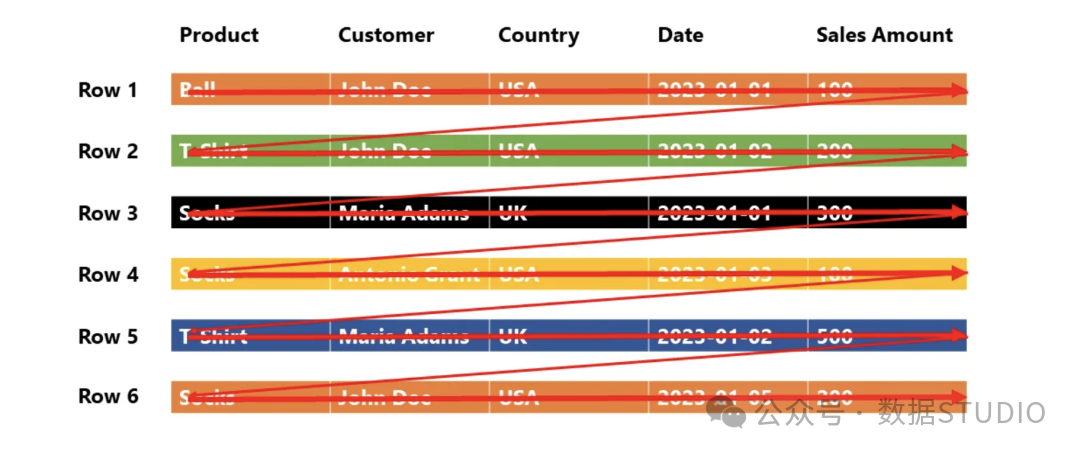
一个形象的比喻:行存储好比将一件件完整的衣服(整行记录)挂进衣柜;列存储则是将所有袖子、衣身、纽扣(各列数据)分别存入不同的抽屉。当任务只需修改袖口时,后者的效率优势显而易见。这种按列组织的特性,也是其能与Hadoop、Spark等大数据处理框架高效协同的基础。
Parquet的核心设计:多层复合结构
Parquet的精妙之处远超简单的列式存储。它设计了一个多层次的分层结构,巧妙融合了行、列两种存储模型的优点。
三层核心结构
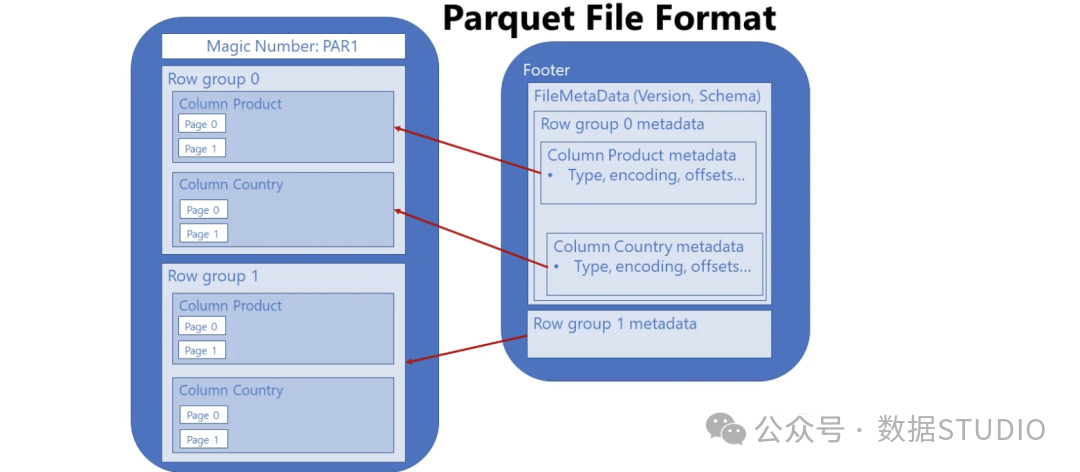
一个Parquet文件包含三个紧密关联的层次:
- 行组:文件被水平切分为多个行组(默认约100万行),每个行组是数据分区和处理的独立单元。
- 列块:在每一个行组内部,每一列的数据形成一个独立的列块。
- 页:列块进一步划分为页(默认最大1MB)。页是I/O操作的最小单元,主要分数据页和字典页两种类型。
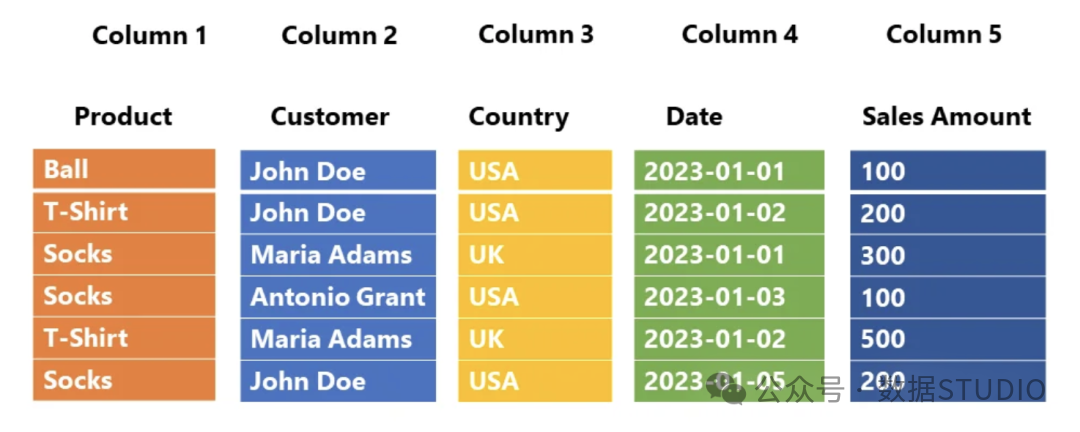 Parquet是一种列式格式,但引入了行组结构以实现水平分区。
Parquet是一种列式格式,但引入了行组结构以实现水平分区。
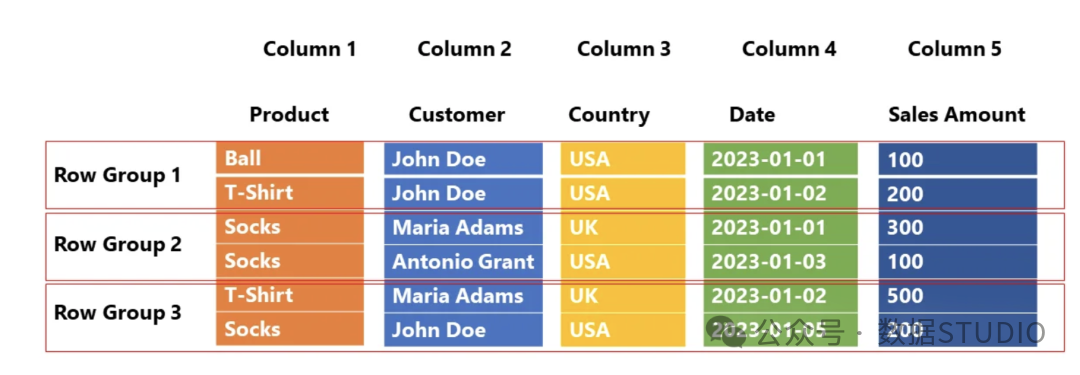 文件物理结构示意图,列数据仍独立存储,但通过行组组织。
文件物理结构示意图,列数据仍独立存储,但通过行组组织。
这种设计实现了两个关键性能优化:投影下推与谓词下推。
- 投影下推:查询引擎只需读取SQL的
SELECT子句中涉及的列,避免全表扫描,大幅减少I/O。
- 谓词下推:Parquet在行组级别存储了列统计信息(如最小值、最大值)。查询引擎可利用
WHERE子句的条件直接跳过不满足条件的整个行组。
场景示例:假设查询“2023年北京的销售额”,引擎可以:
- 仅读取
日期、城市、销售额三列(投影下推)。
- 根据
日期列的行组统计信息,跳过所有不含2023年数据的行组(谓词下推)。最终可能只需读取10%的数据量,查询性能得到质的提升,这种优化对于构建在数据库与各类中间件之上的分析系统至关重要。
 谓词下推与投影下推工作原理示意图。
谓词下推与投影下推工作原理示意图。
高效的压缩与编码技术
Parquet的另一大优势来源于其卓越的压缩能力,这得益于列存储的特性与多种编码技术的结合。
列存储的自然压缩优势
同一列的数据具有相同类型和相似的值分布,其重复性和规律性远高于行存储中交替出现的异构数据,因此更容易获得高的压缩比。
核心编码技术
- 字典编码:为列中所有不同值构建字典,然后用紧凑的整数索引替换原始值。对性别、国家等低基数列效果极佳。
- 行程长度编码:将连续出现的相同值压缩为(值,重复次数)的格式。
- 位打包:对于取值范围小的整数,使用尽可能少的比特位来存储每个值。
以字典编码为例,其过程大致如下:
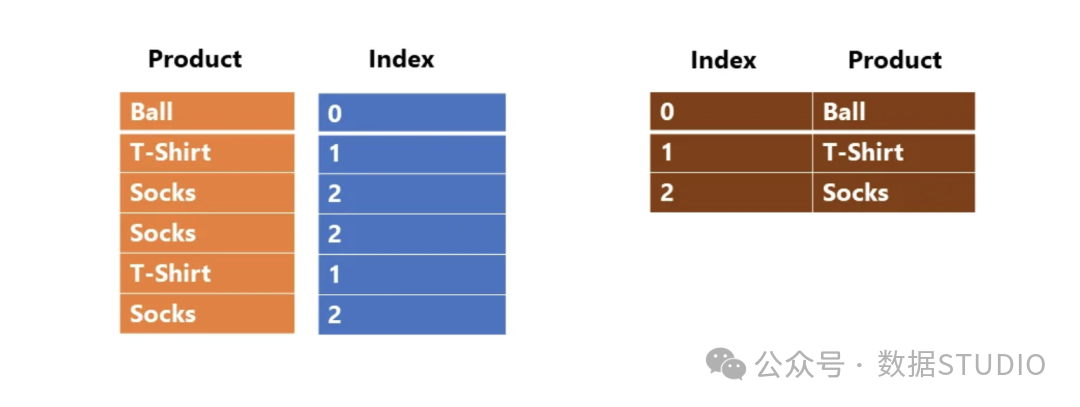 字典编码将原始值替换为紧凑的索引。
字典编码将原始值替换为紧凑的索引。
支持的压缩算法
Parquet支持多种压缩算法,用户可根据场景在压缩比与速度间权衡:
- SNAPPY:平衡之选,速度较快。
- GZIP:高压缩比,速度较慢。
- ZSTD:较新算法,兼顾压缩比与速度。
- LZ4:追求极速读写,压缩比一般。
- BROTLI:提供更高的压缩比。
综合运用这些技术,Parquet文件通常可比等效的CSV文件小75%-90%,不仅节省存储成本,也因减少I/O而提升了查询速度。
Parquet实践:读写操作示例
掌握理论后,来看如何在代码中应用。
使用Python读写Parquet
通过Pandas库可以方便地操作Parquet文件。
环境准备:
pip install pandas pyarrow
写入Parquet文件:
import pandas as pd
# 创建示例DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'salary': [70000, 80000, 90000]
}
df = pd.DataFrame(data)
# 将DataFrame写入Parquet文件
df.to_parquet('example.parquet', engine='pyarrow', compression='snappy')
读取Parquet文件:
# 从Parquet文件读取数据
df_parquet = pd.read_parquet('example.parquet', engine='pyarrow')
print(df_parquet)
利用Python及其丰富的数据科学生态,可以轻松完成数据到Parquet格式的转换与分析。
使用ClickHouse查询Parquet文件
ClickHouse等现代分析型数据库支持直接查询Parquet文件,无需预先导入。
-- 探查文件结构
DESCRIBE TABLE file('house_prices.parquet')
-- 执行查询
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price
FROM file('house_prices.parquet')
WHERE town = 'LONDON'
GROUP BY year
ORDER BY year ASC
性能优化最佳实践
为了充分发挥Parquet的性能,请考虑以下技巧:
- 合理设置行组大小:更大的行组(如100万行)有助于提升压缩率和读取效率,但会增加内存开销。需根据数据规模和查询模式调整。
- 选择合适的压缩算法:在线查询可选Snappy;归档存储追求极致压缩比可选GZIP或ZSTD。
- 合并小文件:避免产生大量小Parquet文件,每个文件的元数据开销会降低效率。理想文件大小在几百MB到几GB。
- 按常用过滤列排序:在写入前,根据高频查询的WHERE条件列对数据排序,能极大提高谓词下推的跳过效率。
- 明智使用字典编码:对低基数列启用字典编码;对高基数列(如用户ID)关闭,以免字典过大反而降低性能。
生态系统与未来展望
Parquet已成为大数据生态的基石。它不仅被Spark、Flink、Hive等主流计算框架原生支持,更是数据湖表格式(如Delta Lake、Apache Iceberg、Apache Hudi)底层的存储标准,这些表格式在Parquet之上增加了事务、版本控制等高级功能。
Parquet本身也在持续演进,近期方向包括:
- 支持更高效的编码(如字节流分割)。
- 增强对复杂嵌套数据类型的处理能力。
- 与Apache Arrow深度集成,实现内存与磁盘格式的高效转换。
总结
Parquet凭借其列式存储的先天优势、多层复合的精巧结构以及高效压缩编码的技术组合,在存储效率与查询性能之间取得了最佳平衡,从而确立了其在大数据存储领域的事实标准地位。无论是构建数据仓库、数据湖还是实时分析系统,深入理解并合理应用Parquet格式,都是打造高效数据架构的关键一步。
 发表于 2025-12-6 01:57:15
|
查看: 204|
回复: 0
发表于 2025-12-6 01:57:15
|
查看: 204|
回复: 0
