长期以来,AI图像生成领域一直存在一个经典矛盾。
基于潜在空间的模型生成效率高,但细节信息往往有损耗;而在像素空间直接生成的模型保真度高,却容易产生结构混乱、生成速度慢的问题。
这几乎让大家默认,这是模型架构带来的固有取舍,难以彻底解决。
但你是否想过,扩散模型一步步去噪生成图像的顺序,本身可能存在优化空间?
李飞飞团队最新发表的论文《Latent Forcing: Reordering the Diffusion Trajectory for Pixel-Space Image Generation》直接挑战了这一共识。他们的研究发现,图像生成的质量瓶颈可能不在架构,而在于生成顺序。

简单来说,这就像画家作画需要先打草稿再填色。该方法为扩散模型引入了一个“先定结构,后填细节”的强制逻辑。通过巧妙地重排生成轨迹,像素级扩散模型不仅找回了生成效率,更在多项关键指标上刷新了性能记录(SOTA)。
传统方法面临哪些瓶颈?
在深入了解Latent Forcing之前,我们先来梳理当前两大主流方法各自遇到的困境。
传统像素级扩散模型之所以容易“画歪”,是因为它在降噪去噪的过程中,高频的纹理细节往往会过早地干扰低频的语义结构。模型常常在还没完全把握物体整体轮廓时,就不得不去预测局部像素的颜色。这种从细节入手的生成方式,在本质上似乎违背了人类视觉认知和图像生成的“由粗到细”的自然逻辑。
为了解决像素模型的混乱问题,行业主流转向了潜空间模型。它通过预训练的编码器将高维像素图像压缩到低维空间进行生成,大幅提升了推理速度。但潜空间模型必须依赖一个预训练的解码器来将潜变量“翻译”回像素图像。这不仅会引入不可避免的重建误差,导致细节损失,也让模型失去了端到端直接建模原始数据分布的能力。

于是,研究团队提出了一个核心问题:能否既保留像素级生成的无损精度,又获得潜空间模型那种清晰的结构引导能力?
核心思路:先打草稿,再填色
Latent Forcing给出的答案简洁有力:对扩散生成轨迹进行重新排序。
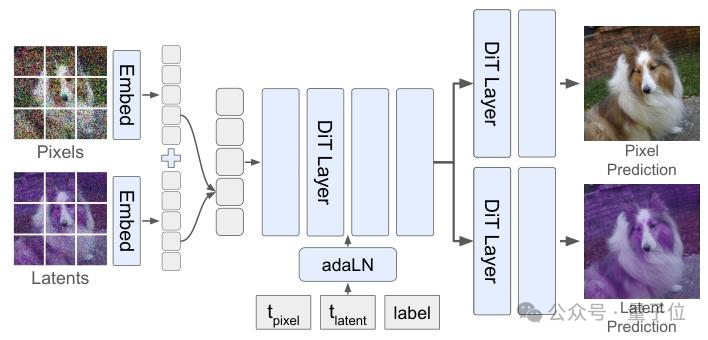
具体是如何实现的呢?
该方法并未改变基础的Transformer架构,而是创新性地引入了“双时间变量”机制。在训练和推理过程中,模型同时处理像素和潜变量两种表示。关键在于,研究团队为两者设计了独立且有序的降噪节奏:
- 潜变量先行(打草稿):在生成的早期阶段,潜变量部分会率先完成大部分降噪过程,从而在大尺度上确立图像的整体语义和结构骨架。
- 像素跟进(填色):当图像的结构基本确定后,像素部分再开始进行精细化的降噪,填充丰富的纹理和颜色细节。
在整个过程中,潜变量就像一个临时的“草稿本”。生成结束时,这个草稿本被直接丢弃,最终输出仍然是100%无损的原始像素图像,无需任何外部解码器。整个过程保持了端到端的特性,具有良好的可扩展性,并且几乎没有增加额外的计算开销(处理的token数量不变,推理速度接近原生DiT模型)。
性能表现:刷新像素模型SOTA
这种“先潜变量,后像素”的细微顺序调整,在ImageNet等标准基准测试中展现出了惊人的效果。
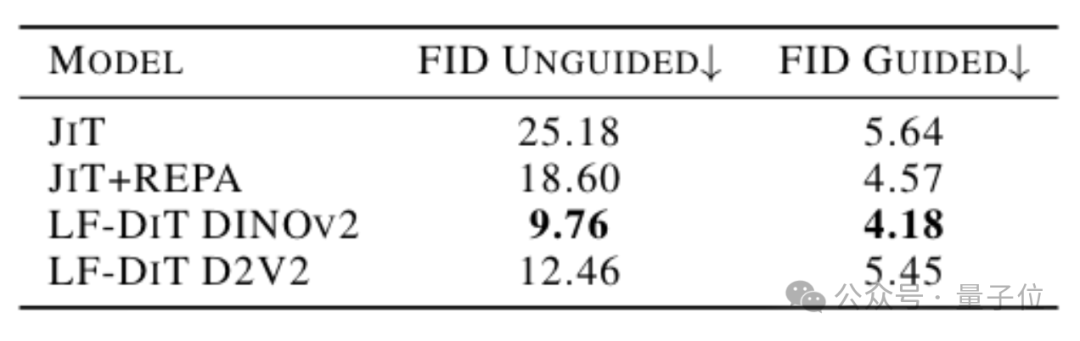
在相同模型规模、训练80个epoch的条件下,Latent Forcing在ImageNet-256×256图像生成任务中,将条件生成(guided)的FID分数从当时最强的像素级模型JiT+REPA的18.60大幅降低至9.76,性能提升接近一倍。
在使用ViT-L规模模型训练200个epoch后,最终模型实现了条件生成FID 2.48、无条件生成FID 7.2的优异分数,创下了像素空间扩散Transformer模型的新SOTA记录。
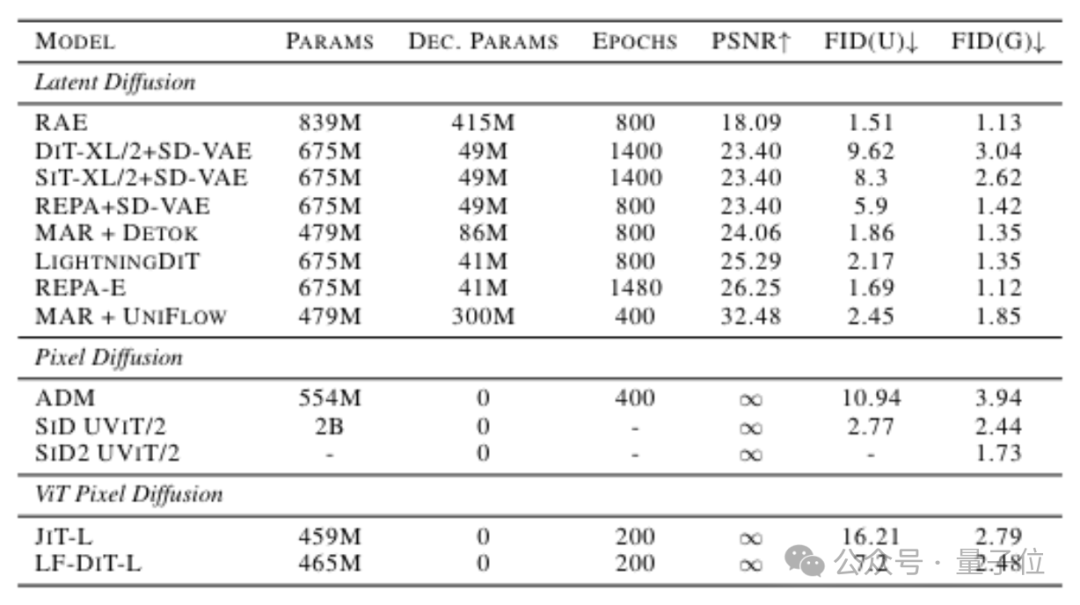
过去,学术界有一个普遍认知:为了获得更好的FID指标(即生成质量),必须对图像进行较高倍率的有损压缩(即使用潜空间)。Latent Forcing的实验结果有力地挑战了这一观点——在保持100%原始像素精度的前提下,模型性能依然可以超越许多有损的潜空间模型。
这项研究为高质量图像生成提供了一条新路径,其“顺序重于架构”的洞察也颇具启发性。更多关于扩散模型、计算机视觉的前沿技术讨论,欢迎在云栈社区的人工智能板块与大家交流。
论文地址:https://arxiv.org/abs/2602.11401

 发表于 2026-2-18 21:47:34
|
查看: 200|
回复: 0
发表于 2026-2-18 21:47:34
|
查看: 200|
回复: 0
