如果你拿视频生成工具做过稍长一点的片子,大概率见过这种翻车:前十秒还挺像广告片,人物衣服、背景灯光、镜头运动都在线;到了二十秒,主角的脸开始轻微变形,背景像被人偷偷换了布景,动作也从“奔跑”变成一种说不清的滑行。单帧截图看不一定差,但连起来就露馅。
这也是我觉得 Stream-T1 值得写的原因。它讨论的不是“再把模型训练大一点”,而是另一个更贴近产品工程的问题:模型已经在那里了,推理时多花一点算力,应该花在哪里,才最可能换来更稳的长视频?
论文给出的答案很明确:别把长视频当成一整条来抽卡。把它拆成连续片段,在每一段生成前后都做纠偏,可能比整段生成完再挑一条更划算。
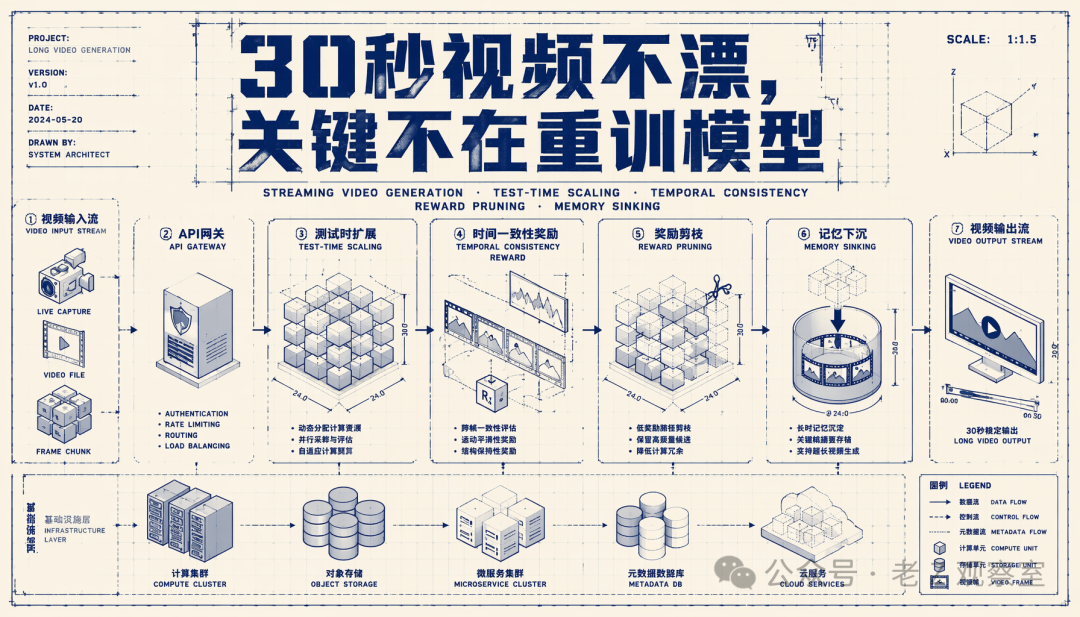
长视频真正难的,是别在第20秒露馅
短视频生成很容易制造“看起来不错”的瞬间。一个漂亮构图、一段顺滑动作、几帧高质量画面,都能撑起 demo。但 30 秒视频要难得多,因为它要求模型一直记得:这个人是谁,场景在哪里,动作往哪个方向走,文本提示里那些约束有没有被遗忘。
这类问题在真实使用里很烦。比如做一条电商产品短片,杯子一开始放在木桌上,镜头绕到后面时桌面纹理变了;再比如做角色剧情预览,人物前半段穿黑色外套,后半段衣领和发型都开始漂。观众未必知道技术原因,但会立刻觉得“不像同一个镜头”。
Stream-T1 把矛盾放在“测试时扩展”上。这个词可以简单理解成:不重新训练模型,而是在生成时增加搜索、评估和选择,让已有模型产出更好的结果。这个方向很诱人,因为训练大视频模型太贵,数据、显卡和调参成本都高。但视频生成不是大语言模型答题,不能直接照搬“多想一会儿”的故事。
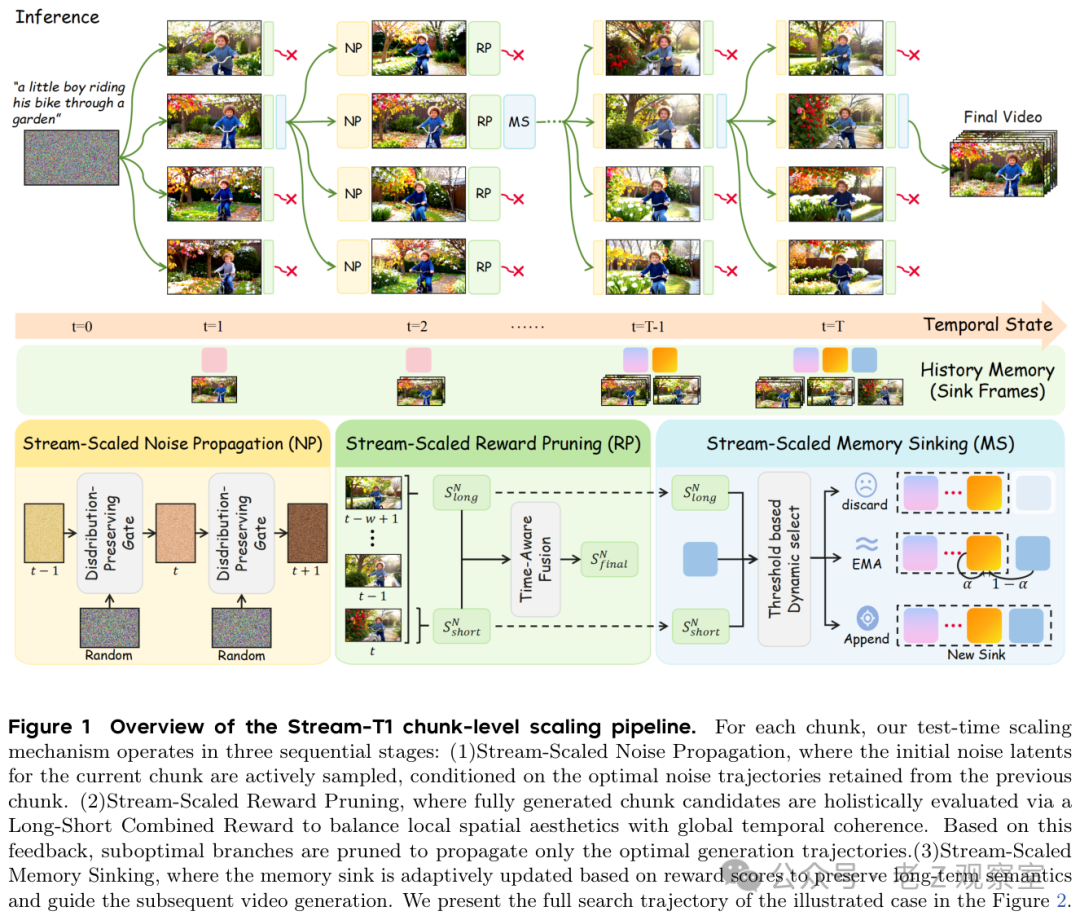
整段抽卡不够用,流式生成反而更好下手
普通的视频测试时搜索,最大的问题是太像“整段抽卡”。你让模型一次生成完整视频,再用奖励模型挑最好的候选。听起来合理,可是一旦视频变长,候选空间会突然膨胀:每个候选都贵,每次评估都重,某个局部动作坏掉,还可能导致整条视频被扔掉。
这像一次性拍完整部短片,然后发现第 18 秒有个穿帮镜头,只能重来一遍。对生成模型来说,这种粗粒度纠错很浪费。更麻烦的是,一次性生成时很难沿着时间轴插入细粒度引导:第 6 秒该稳住主体,第 12 秒该保留背景,第 20 秒该承认转场,这些控制点都被压成了一个整体结果。
Stream-T1 选择了流式视频生成。流式生成不是一次出完整视频,而是一段一段往后接。每段只需要少量去噪步数,论文里强调这种 chunk 级生成天然形成“浅搜索树”:每次不用探索一整条漫长视频,只要在当前片段周围找更好的分支。

这张搜索路径图很关键。它说明 Stream-T1 不是在结尾评奖,而是在生成途中不断剪枝。上一段留下什么,会影响下一段怎么开始;当前段生成得好不好,会影响哪些候选继续往前走;旧缓存被挤出去时,也不是随手丢掉。
Stream-T1 的关键,是让每一段都能被纠偏
我对这篇论文的判断是:它最有价值的地方不是提出三个新名词,而是把测试时算力拆到了三个很工程化的位置:生成起点、候选选择、历史记忆。长视频会漂,往往也正是这三处失控。
第一个位置是起点。扩散视频生成从噪声开始,初始噪声会影响最终画面。Stream-T1 不让当前片段完全从随机起点出发,而是参考上一段已经被验证更好的噪声轨迹。用人话说,就是下一镜不要凭空开拍,而要带着上一镜的惯性往前走。这样做的目的不是复制上一段,而是让相邻片段在生成源头上更连续。
第二个位置是选择。每一轮,系统会扩展多个候选片段,再用奖励模型筛掉差分支。这里有个细节值得注意:它不是只看单帧好不好看。短期奖励负责检查当前片段里的画面质量,长期奖励则在滑动窗口里看一段视频的运动和语义是否连贯。这个设计很现实,因为视频生成最常见的坑就是“每张图都能看,连起来不对劲”。
第三个位置是记忆。流式生成有缓存窗口,窗口外的历史迟早会被挤出去。老办法要么直接丢,要么固定保留开头,要么把历史压成一种平均记忆。Stream-T1 的处理更细:质量差的历史不要污染后面;同一场景里连续变化的高质量片段,可以压缩进短期记忆;如果奖励信号显示这里发生了明显语义变化,就把它作为新的长期锚点留下。
这套机制像一个剪辑师在旁边工作:差镜头别进素材库,连续动作可以合并记忆,重要转场要单独打标。对长视频来说,这比“永远记住开头”更灵活,也比“什么都平均一下”更不容易把语义搅浑。在 云栈社区 的技术讨论中,不少开发者都认为这种分级记忆策略对处理长序列生成非常关键。
数字里最值得看的,不是单项第一
实验部分最值得看的不是某个指标涨了多少,而是它在 5 秒和 30 秒两个场景都能压住漂移。论文在 VBench 的 946 个 5 秒提示上测试,也在 MovieGen 前 128 个提示上生成 30 秒视频,再用 VBench-long 和 VideoAlign 评估主体一致、背景一致、运动顺滑、画质、审美、文本对齐等维度。
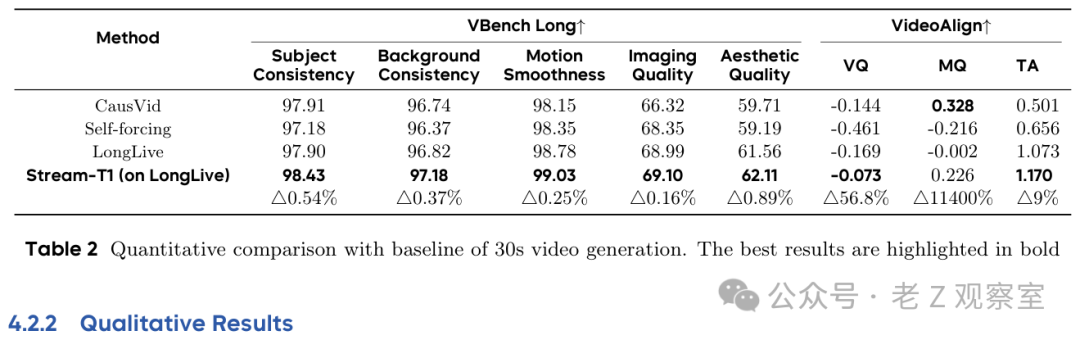
5 秒结果里,Stream-T1 在主体一致、背景一致、运动平滑、审美质量、运动质量、文本对齐等多项指标拿到最好。更有意思的是 30 秒结果:它在 VBench-long 的主体一致、背景一致、运动平滑、成像质量、审美质量上都领先;VideoAlign 里视觉质量和文本对齐也最好,运动质量排第二。长视频场景赢下来,比短视频单项漂亮更能说明问题。
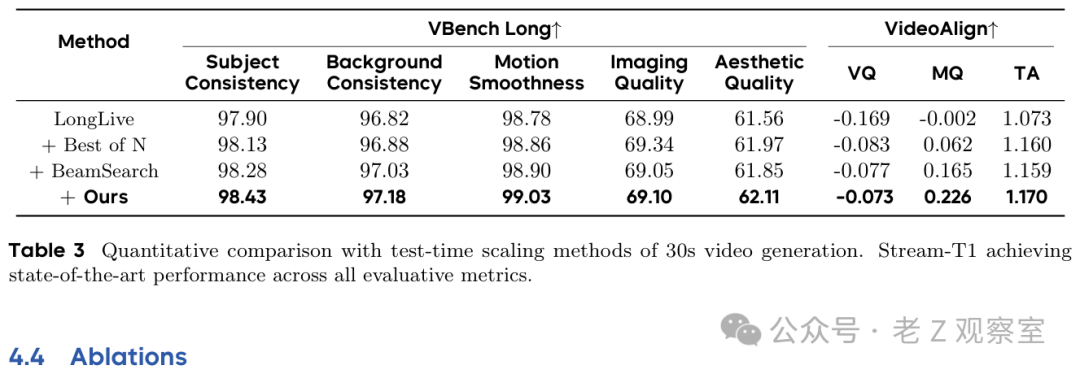
论文还专门拿它和 Best-of-N、Beam Search 这类常规测试时搜索比较。结果显示,Stream-T1 在 30 秒指标上整体更强。我认为这组对比比主表更有说服力,因为它回答了一个关键质疑:这是不是只是“多生成几个候选再挑”?表 3 的信号是,不完全是。它在主动改生成轨迹,而不是只在固定候选池里选运气最好的。
消融也很直观。去掉记忆沉降,背景稳定性会掉;去掉噪声传播,局部结构会出问题,论文图里举了主体尾部的例子;去掉奖励剪枝,语义对齐和审美会明显变差。也就是说,三块不是装饰:起点、选择、记忆分别对应长视频里的不同脆弱点。
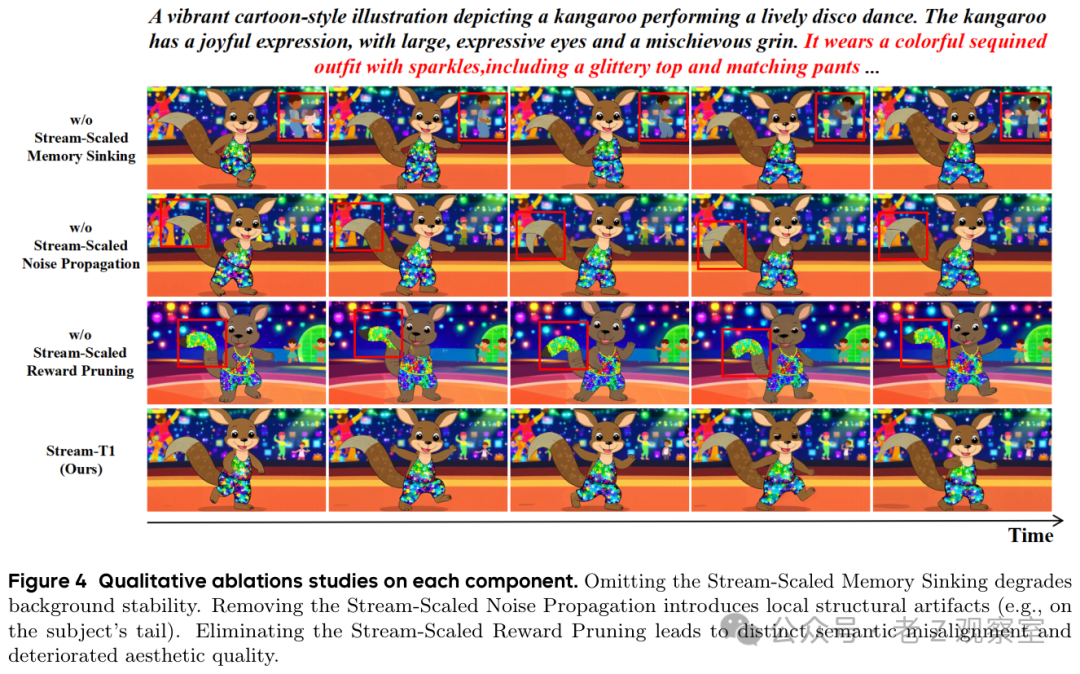
我还会把这里看成一个工程提醒:长视频系统里,某个模块让画面更锐利,不一定代表整段更可靠。表 4 里去掉记忆沉降后,成像质量反而更高一些,但主体一致和背景一致都变差。这种结果很像真实产品里的取舍:单帧截图赢了,用户观看体验却输了。对做视频生成应用的人来说,这比一个漂亮均分更有参考价值,也更接近上线前真正要盯的风险。
这条路有用,但成本账还没算完
当然,测试时算力不是魔法。Stream-T1 需要扩展候选,需要跑图像和视频奖励模型,还要维护滑动窗口里的长期评估。这些操作都会增加推理成本。论文证明了质量提升,但如果要放进真实产品,还需要更细的成本曲线:多花一倍推理时间,能换来多少稳定性;不同分辨率和时长下,收益会不会变薄。
我还有一个存疑点:奖励模型会塑造系统偏好。短期图像奖励更喜欢漂亮单帧,长期视频奖励更看重连贯运动,两者在不同内容上不一定总能平衡。比如快节奏转场、复杂运镜、角色大幅动作,系统到底该保守延续,还是大胆承认变化,可能仍要靠具体策略调参。
这在工具产品里会变成一个很具体的选择:给广告片做产品转台,稳定性优先;给游戏预告做高速追逐,动作张力可能更重要。Stream-T1 提供的是一套可插拔的控制位置,真正上线时还得按内容类型重新配权重。对于正在从事 人工智能 相关应用落地的团队而言,如何在推理效率与生成质量间权衡,始终是需要深入探索的课题。
另外,论文主要基于 LongLive 和 Wan2.1-T2V-1.3B 做验证。这个组合很有参考价值,但不等于所有视频生成架构都能原样复用。尤其是更大模型、商业视频工作流、多镜头叙事里,记忆该怎么沉降、奖励该怎么设计,还会出现新问题。
即便如此,Stream-T1 仍然给了一个清楚信号:长视频生成的进步不只来自更大的模型,也来自生成过程中的控制。下一阶段的竞争,可能不是谁更会画一帧,而是谁更会在第 10 秒、第 20 秒、第 30 秒持续改方向。
 发表于 2026-5-11 20:07:52
|
查看: 117|
回复: 0
发表于 2026-5-11 20:07:52
|
查看: 117|
回复: 0
