别被第一眼骗了,视频生成最怕镜头动
很多 AI 视频现在已经很会“骗第一眼”。单帧够精致,光影够电影,人物和建筑也像那么回事。可只要镜头往前一推,或者绕着物体转半圈,问题就出来了:墙面像贴纸一样滑动,远处建筑突然变形,桌上的物体前一秒还在,后一秒像被世界吞掉。
这不是小瑕疵。我一直觉得,视频生成真正难的地方,不是把每一帧画漂亮,而是让这些帧背后站着同一个世界。做短广告片时,穿帮还能剪掉;但如果拿去做自动驾驶仿真、机器人训练、虚拟拍摄预演,几何不稳定就会变成硬伤。车道线不能漂,障碍物不能凭空消失,镜头绕到侧面后,房子也不能变成纸板。
我更愿意把它叫作“镜头压力测试”。静止镜头像是在考绘画,推近和环绕才是在考空间。一个模型如果只能在正面视角保持漂亮,它离世界模型还很远。真正可用的生成系统,应该能让镜头从桌面滑到侧面,杯子、盘子、阴影和背景仍然彼此对得上;也应该能让车载视角穿过路口,行人、路牌、建筑边缘不因为帧间补洞而乱跳。
World-R1 这篇论文,切的正是这个痛点。它来自浙江大学、微软研究院等团队,基座用的是 Wan2.1。它想回答一个很直接的问题:文生视频模型能不能不只会生成画面,而是在镜头运动中守住三维结构?

图一很适合当入口。它不是只展示一排好看的视频帧,而是把对应的三维世界可视化也摆出来。我的第一反应是:这才是判断世界模型的正确姿势。只看正面帧,很多模型都能装得不错;换个视角,纸片感和结构崩坏才会暴露。
它没给模型加骨架,而是请了一群裁判
World-R1 最有意思的地方,不是又做了一个相机控制器。它没有给 Wan2.1 塞一个新的三维模块,也没有要求推理时挂一套沉重的几何系统。它做的是后训练:让模型生成一批候选视频,再请一组裁判反复打分,分数高的方向就被强化。
相机控制这一步很巧。系统会从文本里读出“推近”“横移”“环绕”这类镜头指令,转成相机轨迹,再把这个运动先验写进初始噪声里。你可以把它理解成:还没开始生成画面前,模型就已经被轻轻推了一把,知道这个世界接下来应该怎样被镜头探索。
真正的主菜是奖励。候选视频生成后,World-R1 会用 Depth Anything 3 把它抬升成三维高斯表示,同时估计视频里的相机运动。接着,系统会从一个新视角去看这个重建出来的世界,再让 Qwen3-VL 扮演三维视觉专家,判断有没有漂浮物、拉伸纹理、纸板结构、混乱点云。
这个“换个角度看”的设计很关键。很多失败视频在原视角里并不难看,甚至每帧都挺精致,但一旦从侧后方观察重建结果,就会发现它只是几层纹理贴在一起。我的判断是,World-R1 最像一次反作弊训练:不许只把正面糊好看,还要让背后的空间经得起检查。
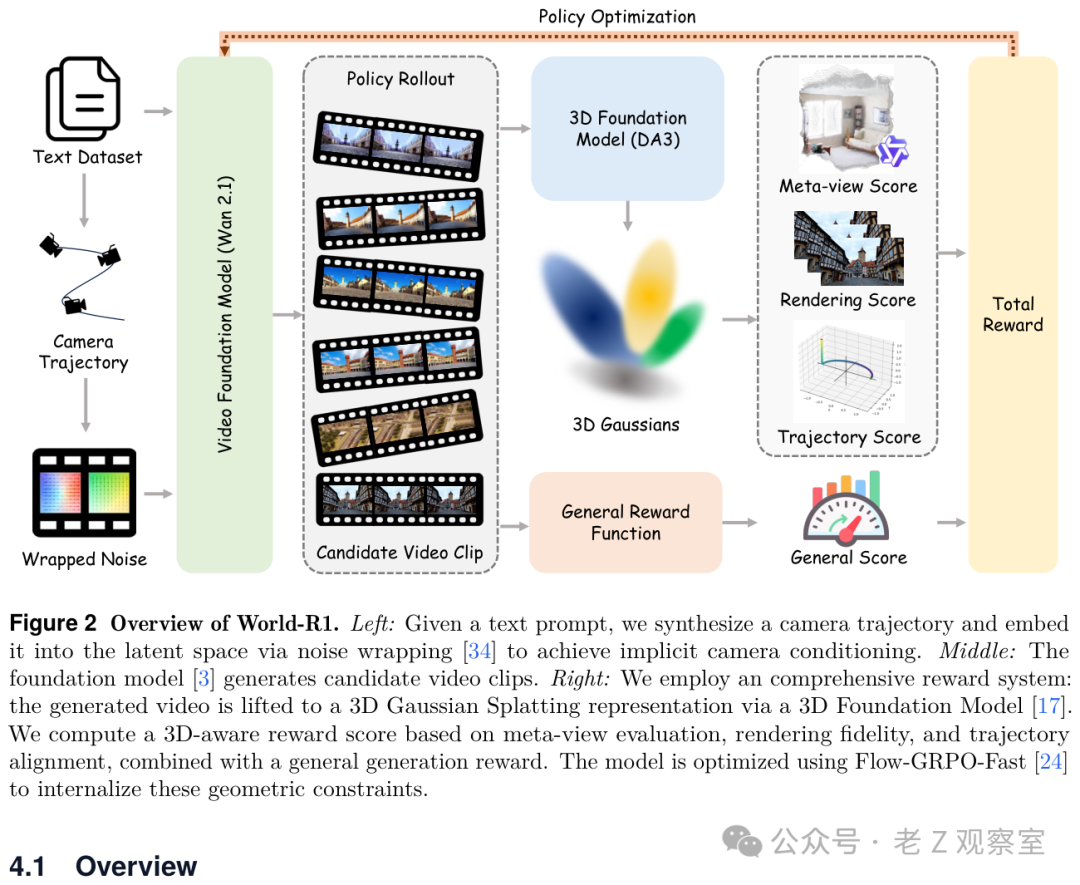
它还会检查两件事:重渲染回原来的镜头时,画面能不能对得上;模型实际生成的镜头运动,和文本指定的轨迹是不是一致。再加上 HPSv3 这样的通用审美奖励,避免模型为了空间稳定把画面做丑。这个设计我很喜欢,因为它没有把“好视频”简化成“好看的帧”,而是把可重建、可换视角、可控镜头都纳入了评价。
最聪明的地方,是用纯文本训练空间感
按直觉,训练三维一致性好像需要大量带相机标注、带三维资产的视频数据。World-R1 反过来走:它构造了大约三千条纯文本提示词,用 Gemini 合成,覆盖自然景观、城市建筑、微观世界、幻想场景,还把镜头运动分成不同难度。
这也解释了它为什么强调“纯文本”。如果依赖现成视频,模型很容易学到数据集里的拍摄习惯和画面偏见,却未必学到空间规则。纯文本提示词反而把训练焦点推回到场景描述、物体关系和镜头意图上。这个选择不华丽,但很工程。
这点我认为很聪明。比如深红峡谷里的河流适合推近,上海外滩的玻璃高楼适合横移,海底珊瑚礁适合环绕。数据不是随便写一段风景描述,而是让场景布局和相机运动绑定起来。模型学到的不是某个视频样本,而是“什么样的空间,适合什么样的镜头”。
论文里还有一个容易被忽略的细节:过强的三维约束会让模型变僵。火焰、水流、人群、动物都不是刚体,如果裁判只奖励稳定结构,模型可能会越来越像一个会旋转的静态展柜。为了解决这个问题,训练每隔一段时间就会暂时关掉三维奖励,只用通用质量奖励训练约五百条高动态提示词。
我觉得这是整套方案里非常现实的一步。世界不是博物馆展品,自动驾驶里有行人,游戏场景里有爆炸,影视镜头里有水和烟。只追求“不要变形”,模型会安全但无聊;只追求“动起来”,世界又会塌。World-R1 至少正面承认了这个拉扯。
数字很猛,但要读准它猛在哪里
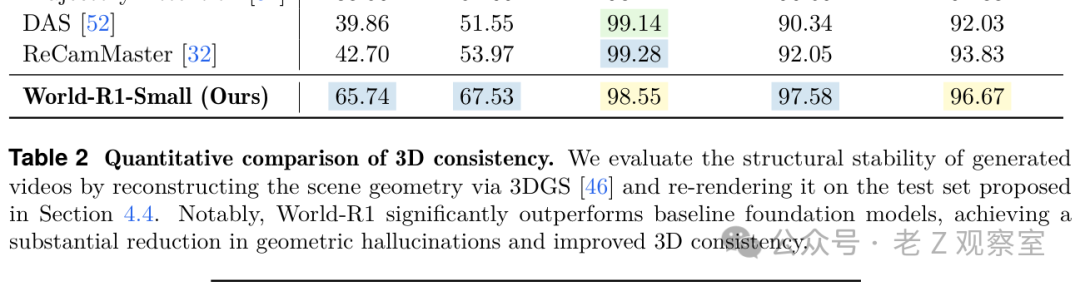
定性图里,World-R1 和 Wan2.1、Wan2.2、CogVideoX 放在一起比较。差别不是哪张图更艳丽,而是镜头移动后还能不能重建出密集、成形、连贯的三维结构。我的判断是,这比单纯比清晰度更接近世界模型的核心问题。

主表里的三维一致性结果很直观。World-R1-Small 的 PSNR 是 27.63,SSIM 是 0.858,LPIPS 是 0.201;World-R1-Large 的 PSNR 是 27.67,SSIM 是 0.865,LPIPS 是 0.162。相比 Wan2.1 基座,论文报告 Small 提升 10.23 dB,Large 提升 7.91 dB。更重要的是,重建无关的多视角一致性指标也有提升,说明不完全是在讨好三维重建流程。
通用视频质量也没有明显被牺牲。VBench 上,World-R1-Small 的审美质量、成像质量、主体一致性都超过 Wan2.1-T2V-1.3B,也明显优于一些显式相机控制方法。用户研究里,二十五名参与者看三十组复杂提示词,World-R1 在几何一致性上的胜率是百分之九十二,相机控制准确性是百分之七十六,总体视觉偏好是百分之八十六。

这些数字让我更愿意相信,它不是用三维稳定换掉了视频美感。消融实验也支持这一点:没有三维奖励,几何学不好;没有通用奖励,审美会掉;没有噪声写入,相机对齐收敛更慢;没有周期解耦,动态会被压住。换句话说,这套系统不是一个单点技巧,而是一组互相牵制的工程组合。
这里我会给一个比较明确的评价:如果只看某一次生成效果,World-R1 可能不是最会“炫技”的视频模型;但如果你关心镜头能不能稳定穿过一个场景,它的指标和设计都更有说服力。尤其是对游戏关卡预览、数字孪生素材、机器人仿真数据这类场景,三维一致性比单帧惊艳更值钱。
我的担心:它在理解世界,还是在讨好裁判?
我对 World-R1 的整体判断偏积极,但不想把它吹成已经完成的通用世界模拟器。最大的不确定性在奖励本身。Depth Anything 3、三维高斯重建、Qwen3-VL 都是裁判,可裁判也会有盲区。模型到底是在学真实空间规律,还是学会生成更容易被这些裁判打高分的视频?这个问题还需要更多公开复现和更强的跨评测验证。
成本也是现实门槛。Small 训练用了四十八张 H200,Large 用了九十六张 H200,在线强化学习还要反复生成视频、重建、打分。对大厂来说,这是可讨论的后训练路线;对普通团队来说,短期内更像一张昂贵门票。更现实的落地形态,可能不是人人从头训一遍,而是等开源权重、轻量奖励器和低成本微调流程成熟后,再被集成进视频生产工具链。
还有边界。论文自己也承认,复杂多物体组合、细手部动作、非常长的场景演化,仍然会受基座模型能力限制。我的看法是,World-R1 更像是在证明一种方向:视频模型里可能已经藏着一些空间感,只是需要更好的训练信号把它逼出来。
所以我最关心后续三件事。开源代码能不能让外部团队复现同样趋势,奖励裁判换一套之后结果还稳不稳,长视频和交互式控制能不能继续受益。如果这些问题得到更扎实的回答,World-R1 这条路线才会从漂亮论文变成可复用方法。
这就足够值得关注了。文生视频的下一关,不只是更高清、更长、更像电影,而是镜头真的走进一个稳定世界。World-R1 没有把这件事彻底解决,但它给了一个清晰信号:未来的视频模型,不能只会画画,还得学会守住空间。对我来说,这也是“世界模型”四个字第一次从口号变得更可检验:把镜头移开,看看世界还在不在。
在云栈社区的讨论里,类似的趋势也常被提及:从单纯的画面生成到可度量的三维空间理解,人工智能领域正悄悄迈过一道坎。当模型不再只讨好眼睛,也开始经得起几何检验时,我们才算真正摸到了世界模型的门槛。
 发表于 2026-5-2 01:16:09
|
查看: 175|
回复: 0
发表于 2026-5-2 01:16:09
|
查看: 175|
回复: 0
