想象一下,给你一张普通的室内照片,你能“走”进去吗?不是像看VR全景图那样被动浏览,而是真正地、自由地探索每一个角落——走到沙发后面看看,绕到书架的另一侧,甚至推开虚拟的“门”进入另一个房间。
这听起来像是科幻电影里的场景,但英伟达(NVIDIA)的最新研究 Lyra 2.0 正在让它接近现实。这项技术的神奇之处在于,它不仅能从单张图像生成3D一致的漫游视频,还能把这些视频一键转化为高质量的3D场景模型,直接用于游戏引擎或机器人仿真。那么,它是如何攻克“空间遗忘”和“时间漂移”这两大技术难题,实现“单图生万物”的呢?
核心目标:从单图到可交互的3D世界
对于游戏设计师或VR内容创作者来说,快速创建复杂的3D场景一直是个耗时费力的过程。传统的做法需要建模师一点一点地用专业软件“捏”出来。生成式重建(Generative Reconstruction)带来了新思路:给AI一张参考图和一个你想走的“相机轨迹”,让它生成一段模拟你走动的视频,然后再用3D重建技术把这个视频“凝固”成3D模型。
这听起来很美,但现有的视频生成模型有个致命问题:它们像得了“健忘症”,走几步就忘了刚才看过什么;同时还像“喝醉了”,画面会慢慢“漂移”变形。因此,它们只能生成很短的、视角变化不大的视频片段,无法支持真正的“大场景探索”。
Lyra 2.0 的目标,就是根治这“健忘症”和“醉酒”两大顽疾,实现长距离、可回溯、3D一致的视频生成,并一键导出高质量3D资产。

图1:Lyra 2.0 能够从单张图像出发,生成远距离3D一致的场景。用户通过定义相机运动来迭代地探索场景,系统则合成空间持久的视频输出,不断扩展环境。这些视频可以直接重建为高保真的3D高斯模型和表面网格,得到可用于仿真引擎和交互式查看器的3D资产。
两大技术顽疾:空间遗忘与时间漂移
让我们深入看看这两个拦路虎到底是什么。
顽疾一:空间遗忘 (Spatial Forgetting)
现在的视频生成模型,大多是自回归(Autoregressive)的。就像写文章,每次只写下一句话,需要参考前面的内容。但AI的“记忆力”有限,它只能“看到”前面一定数量的帧(比如20帧)。当相机走远了,几百帧之前看过的沙发、桌子,早就超出了它的“记忆窗口”。
这时候如果你让相机绕一圈再回到沙发那里,模型完全不记得沙发长啥样,只能根据当前模糊的上下文“瞎编”一个。结果就是:同一个物体,离开再回来,样子可能完全变了,甚至位置都对不上,全局3D一致性彻底崩塌。
顽疾二:时间漂移 (Temporal Drifting)
自回归生成的另一个致命问题是误差累积。每一步生成都有一点点不完美,比如颜色微微偏了,边缘稍微糊了。下一步生成时,是在上一步这个“略有瑕疵”的基础上进行的,于是瑕疵被继承并放大。这样一步接一步,就像“传话游戏”,传到最后可能面目全非。表现在视频里,就是场景的颜色、光照、纹理会逐渐发生不可控的扭曲和变化,画面质量严重滑坡。
在场景探索中,相机不断看到新区域,与早期帧的视觉重叠越来越少,模型失去了可靠的几何和纹理约束,漂移会进一步加剧。
核心解法:几何指路,生成靠模型
Lyra 2.0 的解决方案非常聪明,它没有选择一条路走到黑,而是做了一个优雅的“职责分离”。它的核心思想是:用3D几何信息只做“指路人”(信息路由),告诉模型该参考历史上的哪些画面,以及这些画面和当前视角的对应关系;而具体的“画图”(外观合成)工作,则完全交给强大的视频扩散模型自己来完成。
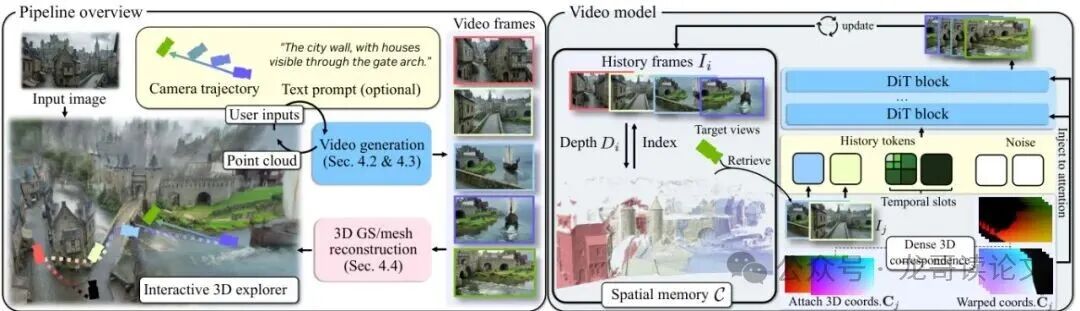
图2:方法概览。(左)给定一张输入图像,Lyra 2.0 在交互式3D浏览器中根据用户定义的相机轨迹和可选文本提示,迭代生成视频片段,并将每个片段提升为3D点云以反馈给后续导航。生成的视频帧最终被重建并导出为3D高斯模型或网格。(右)在每一步,从空间记忆中检索出对目标视图可见性最大的历史帧。它们的标准坐标通过前向扭曲来建立密集的3D对应关系,并与压缩的时间历史一起通过注意力机制注入到DiT中。
1. 构建“3D记忆缓存”与几何感知检索
Lyra 2.0 在生成过程中,会为每一帧都估算一个深度图,并反向投影成一个稀疏点云,存入一个“3D缓存”。注意,这里的关键是它为每一帧都独立存储点云,而不是把所有点云融合成一个全局模型。这样做的好处是避免了早期深度估计不准带来的累积误差污染整个缓存。
当需要生成新的一批画面时,系统会问:“从我这个新的相机角度看过去,缓存里哪些历史帧看到的场景内容和我最相关(重叠最多)?” 然后通过几何计算,选出相关性最高的几帧(比如5帧)。这就解决了“空间遗忘”:即使那帧是几百步之前生成的,只要几何上有重叠,就能被找回来。
2. 注入“几何路标”,而非“瑕疵拐杖”
找到了该参考的历史帧,怎么用呢?一个直观的想法是:把历史帧的图像根据深度信息前向扭曲(Forward-Warp)到新视角,然后把这个扭曲后的图像喂给模型。但这有个大问题:扭曲过程会产生空洞、拉伸等严重瑕疵,模型如果直接以此为依据,就会把这些瑕疵也画出来,等于拄了个“破拐杖”。
Lyra 2.0 的妙招是:不扭曲RGB图像,而是扭曲一个“标准坐标图”。这个坐标图的每个像素值不代表颜色,而是代表一个固定的空间位置编码。扭曲这个坐标图到新视角后,它就成了一张“几何对应关系地图”,清晰地告诉模型:“你看,你目标画面里的这个像素,在历史帧A里对应的是那个位置的像素。”
这样,模型同时接收三种信息:1)检索到的历史帧原图(提供外观参考);2)扭曲后的几何对应图(提供精确的空间对齐线索);3)按时间压缩的上下文(提供短期时序连贯性)。模型凭借自己强大的生成能力,综合这些线索,合成出既与历史一致、又在新视角下合理的新画面。
$$
\hat{C}_j = \text{FwdWarp}(C_j, D_{s_j}, T_{s_j}, T^*, K_{s_j}, K^*).
$$
公式:标准坐标图 Cj 通过前向扭曲函数,结合深度 D{sj}、源相机参数 (T{sj}, K{sj}) 和目标相机参数 (T^, K^) ,生成扭曲后的坐标图 Ĉ_j。这建立了从历史帧到目标帧的密集像素级对应关系。

自增强训练:让模型学会“纠错”
解决了“遗忘”,再来对付“漂移”。漂移的根本原因是训练和推理的不匹配:训练时,模型总是基于完美无瑕的“真实历史帧”来预测下一帧;但推理时,它只能用自己上一步生成的“有瑕疵的历史帧”来预测下一步。它没见过这种“瑕疵历史”,所以不会纠正,只会让瑕疵传播下去。
Lyra 2.0 的方案是:在训练时就“喂”给它一些有瑕疵的历史,教它学会“纠错”。具体来说,在训练迭代中,有概率(比如30%)将作为条件输入的历史帧的潜在表示,用噪声轻微污染一下,然后用模型对这个污染版本做一次去噪,得到一个“模拟的、有瑕疵的”历史条件。模型需要在这个“次品”条件的基础上,仍然努力预测出干净的下一帧。
$$
z_t^{\text{hist}} = (1 - t) z_0^{\text{hist}} + t\epsilon, \quad \epsilon \sim \mathcal{N}(0, I).
$$
$$
\tilde{z}_0^{\text{hist}} = z_t^{\text{hist}} - t \cdot v_\theta(z_t^{\text{hist}}, t, c).
$$
公式:自增强过程:对干净的历史潜在表示 z_0^hist 添加噪声得到 z_t^hist,然后经模型 v_θ 单步去噪得到模拟的含噪历史 ž_0^hist,并用它替代原始干净历史作为条件。
这就好比在驾校学车,不仅要在完美路况下开,教练还会时不时给你制造点小意外,训练你处理突发情况的能力。这样训练出来的“老司机”模型,在实际推理遇到误差累积时,就能更稳健地控制方向,抑制漂移。

效果如何?全面领先的量化与可视化对比
理论说得好,不如效果跑一跑。Lyra 2.0 在DL3DV和Tanks-and-Temples等多个数据集上,与当前最先进的几种长视频生成方法进行了全面对比。
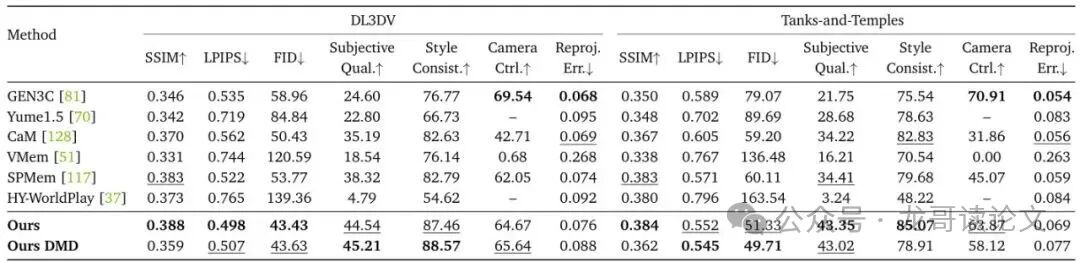
表1:单视图到长视频生成的定量比较。最佳结果以粗体显示,次佳结果以下划线标出。
从表1可以看出,无论是衡量图像质量的SSIM、LPIPS、FID,还是人工评估的主观质量、风格一致性、相机控制,Lyra 2.0(Ours)在绝大多数指标上都取得了最佳或接近最佳的成绩。这证实了其方法在生成长距离、高一致性视频方面的有效性。

图3:视频生成对比。给定Tanks and Temples中的单张输入图像,我们比较了所有评估视频模型的长距离生成(约第800+帧)。基线方法在长距离上表现出严重的质量下降、几何扭曲或内容漂移,而我们的方法保持了真实的结构和外观。
可视化对比更具说服力。图3显示,在生成了800多帧后的远距离视角,基线方法要么严重模糊失真,要么物体结构崩塌,要么出现了诡异的颜色和纹理漂移。而Lyra 2.0生成的画面依然清晰,结构保持完好,证明了其强大的抗遗忘和抗漂移能力。

图6:定性消融研究。给定单张输入图像,我们在Tanks and Temples场景上比较了我们完整模型与消融变体的生成结果。
图6的消融实验直接验证了各个组件的必要性。去掉几何感知检索后,模型在回看区域出现严重不一致(红框内书架结构突变)。去掉自增强训练后,画面出现了明显的颜色漂移和细节丢失。两者结合(完整模型)才能得到最佳效果。
不止于视频:高质量3D场景一键生成
生成长视频只是第一步,Lyra 2.0 的终极目标是产出可直接使用的3D资产。它采用了3D高斯泼溅(3D Gaussian Splatting, 3DGS)作为重建方法。3DGS是一种显式3D表示,渲染速度快、质量高,非常适合实时应用。
然而,即便是Lyra 2.0生成的视频,也难免存在微小的多视角不一致,这会使得标准的3D重建模型产生“漂浮物”和噪声。为此,论文对前沿的Depth Anything v3 (DAv3)模型进行了微调,使其更加适应生成数据的特点,从而能够从Lyra 2.0的视频中稳健地重建出干净、连贯的3DGS场景。进一步,还能从3DGS中提取出表面网格。

图4:3DGS对比。我们比较了从视频扩散模型输出重建的3DGS场景的渲染图,起始于Tanks and Temples中的单张输入图像。
图4展示了3D重建效果的对比。其他方法生成的视频重建出的3D场景,往往几何破碎、充满孔洞和漂浮物。而Lyra 2.0重建的场景则几何完整、表面光滑,显示出极高的3D一致性。
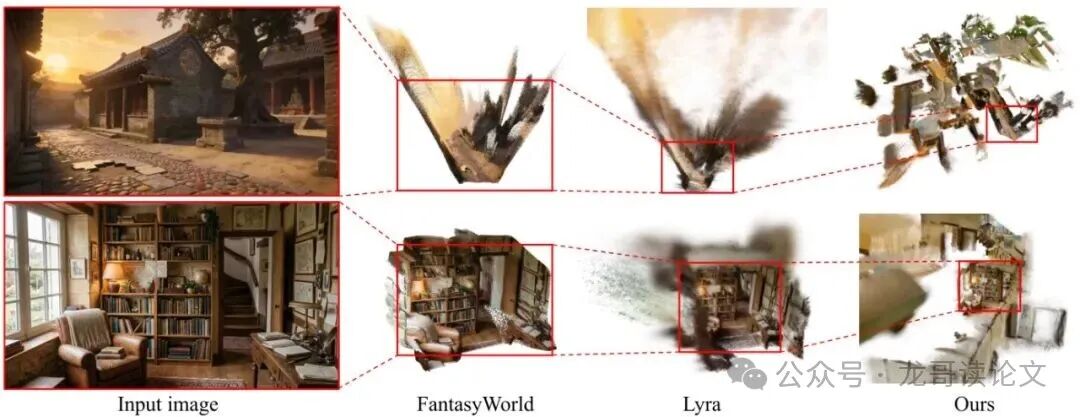
图5:与Lyra和FantasyWorld的定性对比。我们展示了鸟瞰视角下的3DGS渲染。红色边界框突出了不同方法之间大致相同的空间区域。我们的交互式探索框架产生了规模和复杂性显著更大的场景。
图5的鸟瞰图更是震撼。对比之前的Lyra 1.0等工作,Lyra 2.0能够探索并重建出规模大得多、结构复杂得多的完整场景,展现了其在大规模3D世界生成方面的潜力。

图7:应用。我们的交互界面允许用户在3D缓存内指定相机轨迹,轻松生成新视角。此外,重建的3DGS场景可以转换为表面网格,并集成到具身AI模拟器(如NVIDIA Isaac Sim)中进行机器人仿真。
最终,如图7所示,这一切集成为一个交互式系统。用户可以从单张图开始,在初步重建的3D点云中自由规划漫游路径,系统实时生成扩展视频并更新3D模型。生成的3D网格可以直接导入到NVIDIA Isaac Sim等机器人仿真平台中,用于训练机器人的导航、交互等能力。从一张图到可交互、可仿真的3D世界,就此打通。
技术要点问答
论文中提到的DiT和3DGS分别是什么?
DiT 是 Diffusion Transformer 的缩写,是一种基于Transformer架构的扩散模型,常用于图像和视频生成。3DGS 是 3D Gaussian Splatting 的缩写,中文可称“3D高斯泼溅”,它是一种新颖的显式3D场景表示方法,用许多可学习的3D高斯椭球体来表示场景,可以实现非常快速的、高质量的渲染,近年来在3D重建领域非常流行。
“几何只指路,生成靠模型”这个设计妙在哪里?
妙在“职责分离”和“扬长避短”。3D几何(深度估计)往往是不完美的,尤其是对AI生成的画面。如果直接用不完美的3D几何去渲染图像作为条件,会把瑕疵硬塞给生成模型。Lyra 2.0让3D几何只负责做信息检索和对齐(这是它的相对强项),而把最终的、困难的外观合成任务交给训练有素的、懂得“脑补”和“纠错”的视频扩散模型。这样既利用了3D信息实现长程一致性,又避免了被3D误差带偏,发挥了生成模型的最大潜力。
自增强训练和传统的“教授强制”训练有什么区别?
传统的“教授强制”(Teacher Forcing)在训练序列模型时,总是使用真实的上一步数据作为条件。而“自增强”可以看作是一种针对自回归生成中“误差累积”问题的“教授强制”变体。它有策略地引入模型自身在推理时可能产生的噪声或误差作为条件,迫使模型学习如何在“不完美”的基础上进行“修正”,从而缩小训练与推理的差距,提升模型在长序列生成中的鲁棒性。
总结与展望
英伟达的Lyra 2.0为我们展示了一条从2D图像生成可探索3D世界的清晰技术路径。通过将3D几何作为“信息路由器”巧妙解耦,并结合自增强训练策略,它有效解决了长视频生成的“健忘”与“漂移”难题,最终输出可用于仿真的高质量3D资产。
这项研究不仅在学术上为生成式AI与3D视觉的融合提供了新思路,其展现的应用前景——从游戏开发、虚拟现实到机器人训练——也极具吸引力。当然,该方法目前对算力要求较高,且管线较长,距离完全鲁棒的工业化应用尚有距离,但它无疑指明了未来3D内容创作自动化的重要方向。
你对这种从单图生成3D世界的技术有什么看法?欢迎在云栈社区的 人工智能 或 智能 & 数据 & 云 板块与其他开发者一起交流探讨。
主要参考文献
[1] Tianchang Shen, Sherwin Bahmani, Kai He, et al. Lyra 2.0: Explorable Generative 3D Worlds. arXiv preprint arXiv:2604.13036v1, 2026.
[2] Lyra 2.0 项目主页:https://research.nvidia.com/labs/sil/lyra2/

 发表于 2026-4-18 23:07:17
|
查看: 166|
回复: 0
发表于 2026-4-18 23:07:17
|
查看: 166|
回复: 0
