扩散模型(Diffusion Model)和 Transformer 的结合,如DiT,已经在图像生成等领域大放异彩。但一个根本问题始终悬而未决:为什么Transformer能如此有效地学习去噪(Denoising)? 这背后是玄学还是有其深刻的数学原理?今天解读的这篇论文,首次为这个问题提供了严格的理论收敛性分析。它不仅在理论上证明了Transformer能够逼近最优去噪器,还揭示了其核心机制—— “均值去噪”。
先一句话总结本论文最酷的发现:经过DDPM目标训练的单层Transformer,其自注意力模块学会了“均值去噪”机制。
这是什么意思?想象一下,你有一张被噪声严重污染的图片,图片里有好几只猫和狗(代表不同的“模式”或“概念”)。Transformer的自注意力层会做一件事:它把所有看起来像“猫”的像素区域(Token)找出来,然后计算它们的平均值。 对于“狗”的区域,它也做同样的事情。
为什么求平均能去噪?因为噪声通常是随机的、零均值的。当你把属于同一个真实信号(比如“猫”)的多个嘈杂版本拿来平均时,随机噪声就会相互抵消,而真实的“猫”的信号则会得到加强。这其实就是信号处理里经典的最小方差无偏估计的思想。
论文用下面这张图非常直观地展示了这个过程:
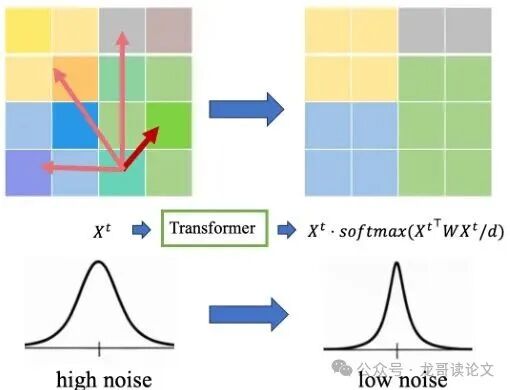
图1:训练后Transformer的均值去噪机制。深红色箭头表示查询(Query)和键(Key)共享相同模式时的注意力权重;浅红色箭头表示不同模式之间的注意力权重。可以看到,注意力主要汇聚在相同模式的Token上。
通过这种“物以类聚”然后求平均的方式,Transformer能够有效地估计出每个Token背后未被噪声污染的真实均值。一旦知道了真实均值,结合扩散过程已知的噪声强度,就能最优地估计出当初加入了多少噪声(即去噪目标)。这就是Transformer能在扩散模型中胜任去噪工作的 核心机密。
理论基石:多Token高斯混合模型与收敛性定理
理论分析需要一个可处理的起点。本文提出了一个叫做 多Token高斯混合模型 的数据分布,英文是 Multi-Token Gaussian Mixture (MTGM)。
你可以把它想象成:每个数据点(比如一张图片)不是单个东西,而是由多个“碎片”(Token)拼接而成。每个“碎片”都独立地从M个可能的高斯分布(代表M种基础图案,如猫、狗、车)中随机选一个生成。但一张图里不会包含所有M种图案,只包含其中K种。这非常接近我们对真实图像的理解——一张图由若干物体/纹理组成。
模型与目标
模型采用了一个极简的 单层、单头Transformer。这显然是对现实(如DiT)的巨大简化,但却是理论突破的必要步骤。其形式化定义如下:
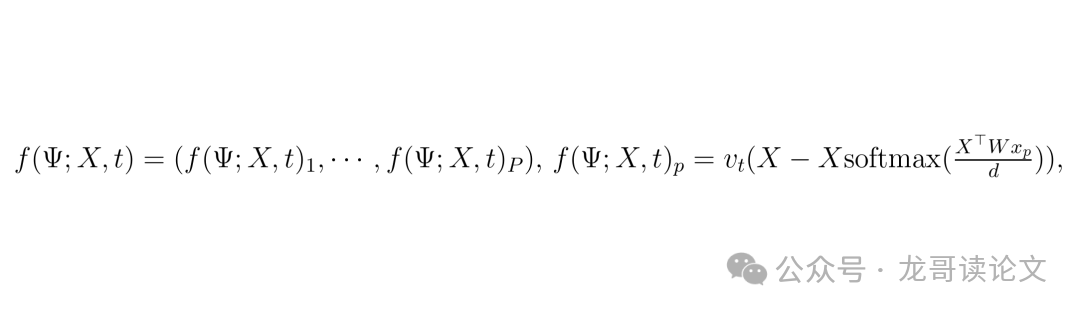
这里,$X^t$ 是加了噪声的数据,$W$ 是自注意力层的权重矩阵,$v_t$ 是一个与扩散时间步 $t$ 相关的标量权重。模型的目标就是预测加入的噪声 $E$。
训练目标就是标准的 DDPM 去噪损失函数:
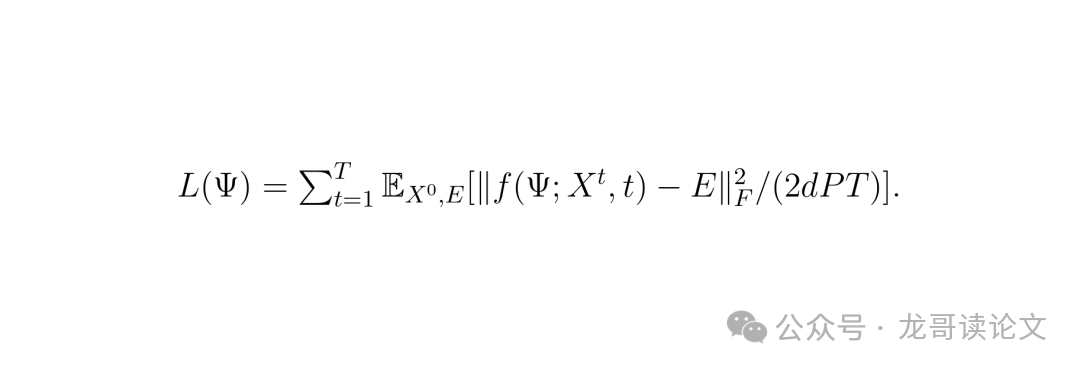
简单说,就是让Transformer的输出尽可能接近我们当初加入的噪声。如果能完美预测噪声,那么从噪声中减去它,就能得到干净的数据了。
收敛定理说了啥?
本文最硬核的贡献—— 定理1(收敛性定理)。它证明了,在满足一定条件下,用梯度下降训练上述Transformer,其损失函数可以收敛到 贝叶斯最优风险 附近。
贝叶斯最优风险是啥?可以理解为,哪怕你知道了数据的全部概率分布,所能达到的最好去噪效果。这是一个理论下限。定理1说,Transformer能学到接近这个下限。
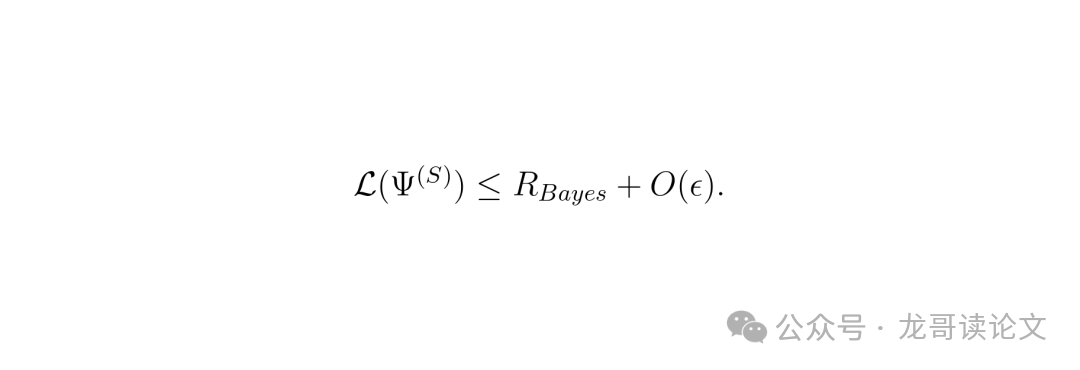
定理还量化了达到这个效果需要的条件,非常接地气:
1. 每个数据点需要足够多的Token (P要大):这很好理解,“均值去噪”要有效,你至少得有多个同一模式的样本来平均吧?如果一张图里某个物体就出现一次,那很难靠平均来消噪。
2. 训练需要足够多的迭代次数 (S要大):特别是当数据中模式分布不均匀(有的图案出现得少),或者扩散过程中信噪比很低时,需要更多迭代来学习。
3. 维度要够高 (d要大):这是保证注意力机制能有效区分不同模式的算法性条件。
此外,论文还给出了一个 定理2(分数匹配定理),表明用这个训练好的去噪器构造出的分数网络,其分数匹配误差也是可控的。这连接了DDPM训练和分数匹配理论。
深入机制:自注意力如何实现“均值去噪”?
定理证明了“能做到”,那“怎么做”的呢?论文通过一系列命题,深入剖析了自注意力权重的秘密。
关键在于,训练后的自注意力权重矩阵 $W$ 学会了一个神奇的能力:对于两个Token,如果它们源自同一个高斯成分(即同一个“图案”),那么它们的特征经过 $W$ 变换后的内积会很大;如果源自不同的成分,内积则非常小(量级上相差大约 $\sqrt{d}$ 倍)。
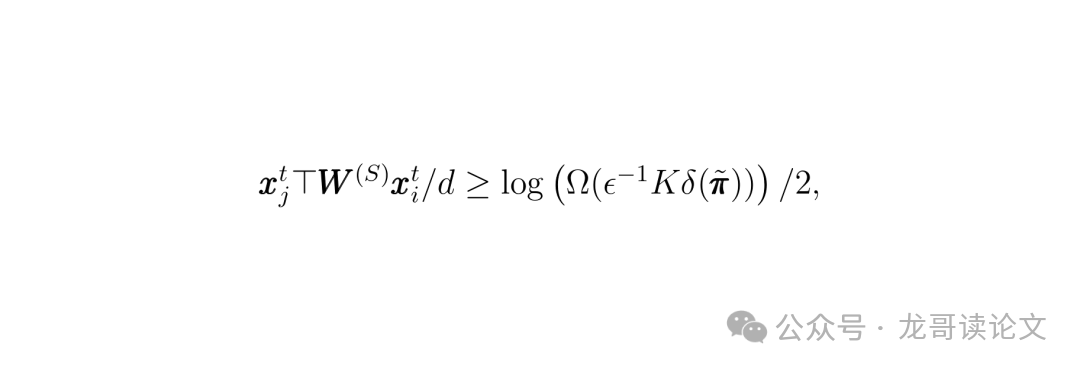
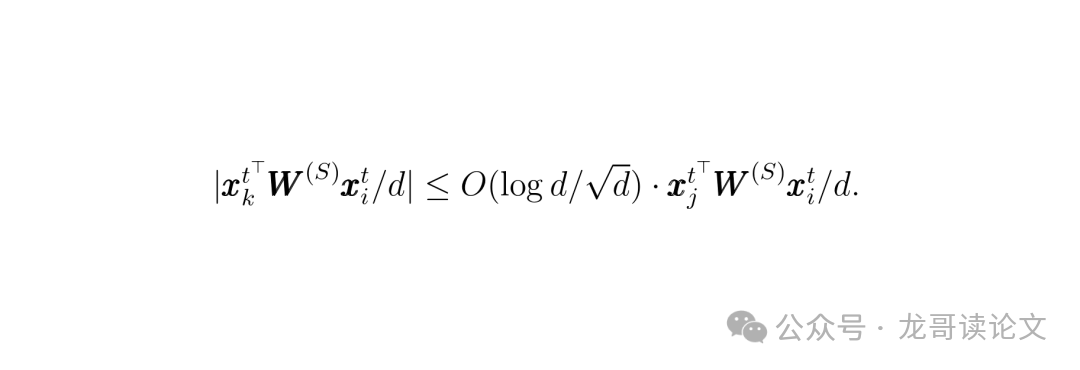
这个差异是巨大的!经过 Softmax 归一化后,结果就是:对于一个查询Token,几乎所有的注意力都集中在了与它同类的那些Key Token上,并且在这些同类内部,注意力权重几乎是均匀分布的。
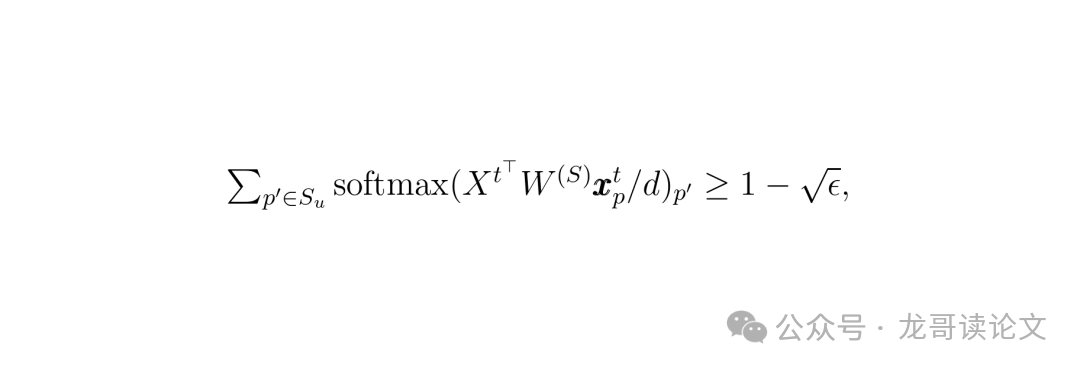
这完美解释了“均值去噪”机制:自注意力层实际上是在执行“按模式分组,组内求平均”的操作。输出就是该Token所属模式的所有Token的均值,这正是对原始干净信号(均值)的一个很好估计。
这个机制还有一个非常好的性质:它不依赖于训练数据中各种模式的具体比例。只要模型在学习阶段“见过”所有模式,那么即使测试数据中模式的比例发生了变化(比如训练时猫多狗少,测试时狗多猫少),只要每张测试图片里每种模式有足够的Token,模型依然能有效地对其进行去噪。这暗示了Transformer扩散模型具有一定的分布外泛化能力。
实验验证:合成与真实数据均支持理论
理论再漂亮,也需要实验的支撑。论文在合成MTGM数据和部分真实数据(MNIST)上进行了验证。
首先,在合成数据上的实验完美印证了理论预测。下图展示了训练过程中损失下降、分数匹配误差减小,并最终逼近贝叶斯风险的过程。同时,实验也验证了“每个数据所需Token数(P)”、“模式不平衡性”、“时间步采样策略”等因素对收敛的影响,与定理的量化分析相符。
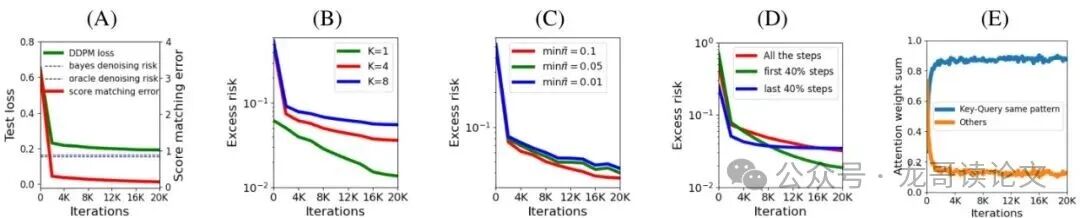
图2:收敛性能与注意力行为。(A) 训练中测试损失(绿)和分数匹配误差(红)下降,逼近贝叶斯风险(蓝虚线)和Oracle风险(黑虚线)。(B-D) 不同因素对超出风险的影响。(E) 注意力权重在同类(深色)与异类(浅色)Key上的求和,证实了注意力集中于同类Token。
更引人注目的是在MNIST数据集上的实验。虽然MNIST不是严格的MTGM分布,但论文将每个数字图像分割成多个图块作为Token。他们设置了一个长尾分布,让某个数字(如“2”)成为少数类。
实验发现,模型生成图像质量的评价指标FID分数显示,少数类数字的FID下降得比其他数字慢。这与理论预测一致:少数类模式在数据中出现的Token更少,模型学习其去噪更加困难,需要更多的训练迭代或数据。
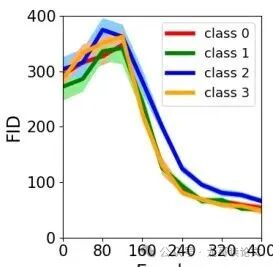
图3:MNIST上四个生成数字的FID分数。少数类“2”的FID下降速度比其他数字慢。
可视化结果也表明,训练后的模型能够生成清晰的数字图像。

图4:生成数字的可视化。
启示与展望:简化模型下的坚实第一步
这篇论文的意义,与其说在于其结论能直接指导工程实践,不如说在于它 为理解Transformer在扩散模型中的行为打开了一扇理论之窗。
它首次严格证明了,在合理的简化设定下(MTGM数据,单层Transformer),通过DDPM目标训练,梯度下降确实能够收敛到一个接近最优的去噪器,并且揭示了这个过程的内部机制是“均值去噪”。这为“Transformer为何在扩散模型中有效”这个长期的经验性成功,提供了第一个理论注脚。
当然,局限性也很明显:模型极度简化,距离真实的视觉Transformer(多层、多头、更复杂的数据分布)还有巨大的差距。但这正是理论工作的典型路径—— 从最简化的核心案例入手,建立理解的地基。未来的工作可以在此基础上,逐步增加模型的复杂性(如分析多层Transformer),探索更真实的数据分布,从而一步步逼近对现实模型的完全理解。
这项工作也启发我们,在设计与分析模型时,可以更多地思考自注意力“聚集相似信息”这一本质特性,如何在不同任务(如去噪、生成)中被利用和演化。
常见问题解析
DDPM是什么?和分数匹配有什么关系? DDPM (Denoising Diffusion Probabilistic Models) 是扩散模型的一种经典形式,其训练目标是让神经网络预测在前向过程中加入的噪声。分数匹配 (Score Matching) 的目标是让神经网络匹配数据对数概率密度的梯度(即分数函数)。在一定的参数化下(如本文公式(11)),优化DDPM损失等价于在优化一个加权的分数匹配损失。因此,本文分析DDPM训练的收敛性,也自然带来了分数匹配误差的保证。
论文中提到的“Oracle MMSE估计器”是什么意思? MMSE是最小均方误差估计器 (Minimum Mean Squared Error estimator) 的缩写,即在已知某些信息下,对随机变量的最优(均方误差最小)估计。本文中,真实的MMSE估计器 $E[E|X^t]$ 很难分析。因此,论文定义了一个“Oracle”(先知)估计器 $E[E|X^t, M_Y]$,它额外假设我们知道每个Token到底属于哪个高斯成分(即知道 $M_Y$)。这个Oracle估计器有闭式解,易于分析。论文证明,当每个数据点Token数足够多时,Transformer学到的解非常接近这个Oracle估计器,而Oracle估计器的性能又非常接近真实的贝叶斯最优解。
这个理论对实际使用DiT等模型有什么指导意义? 目前来看,更多的是原理性的启发,而非直接的工程调参指南。它告诉我们,Transformer在扩散模型中成功的一个关键可能是其“均值去噪”能力。这暗示着,为了让模型更好地处理数据中的少数模式或复杂模式,可能需要确保模型有足够的容量和机会去学习这些模式(例如,通过足够深的网络、足够多的注意力头来捕捉不同粒度/类型的模式),或者在数据层面保证每种模式有充分的、多样化的表达。它也从理论上支持了“每个数据点应有丰富上下文信息”的直观想法。
总结
总而言之,这篇论文为理解Transformer在扩散模型中的去噪能力提供了宝贵的理论基石。虽然设定简化,但其揭示的“均值去噪”机制深刻且直观,为后续更复杂场景下的理论研究铺平了道路。对于希望深入理解生成模型底层原理的开发者与研究者而言,这是一份极具价值的参考资料。欢迎在云栈社区继续探讨相关技术话题。
 发表于 2026-4-18 23:01:27
|
查看: 152|
回复: 0
发表于 2026-4-18 23:01:27
|
查看: 152|
回复: 0
