
近来,AI圈被一匹神秘的“欢乐马”搅动,它悄然登顶了Artificial Analysis排行榜。就在众人猜测其来历之际,阿里巴巴主动认领了这匹“黑马”。
更令人意外的是,短短几天后,阿里“Happy”家族再添新成员——HappyOyster(快乐生蚝)。
两者“师出同门”,均源自阿里巴巴今年3月新成立的Alibaba Token Hub(ATH)创新事业群。但“快乐生蚝”与主要进行文生视频的“欢乐马”不同,它将自己定位为一款可实时构建和交互的开放式世界模型产品。
其底层基于原生多模态架构,是一个支持多模态输入与音视频联合生成的流式生成世界模型。最大的特点是能在生成过程中持续接收用户指令,实现画面的实时响应与持续演绎。
一手实测:阿里这个世界模型有点意思
HappyOyster目前主要提供漫游(Wander) 和导演(Direct) 两大核心功能。我们也在第一时间拿到了体验资格,进行了上手实测。
体验链接:https://www.happyoyster.cn/
漫游(Wander):构建无限探索的数字世界
漫游功能旨在生成一个可供用户自由探索的场景。它支持通过文字或图片来“生成世界”。
操作界面提供了两种模式:直接输入综合提示词,或者使用“定制模式”分开设定“角色(Character)”和“场景(Scene)”,并能切换第一人称或第三人称视角,实现更精细的控制。
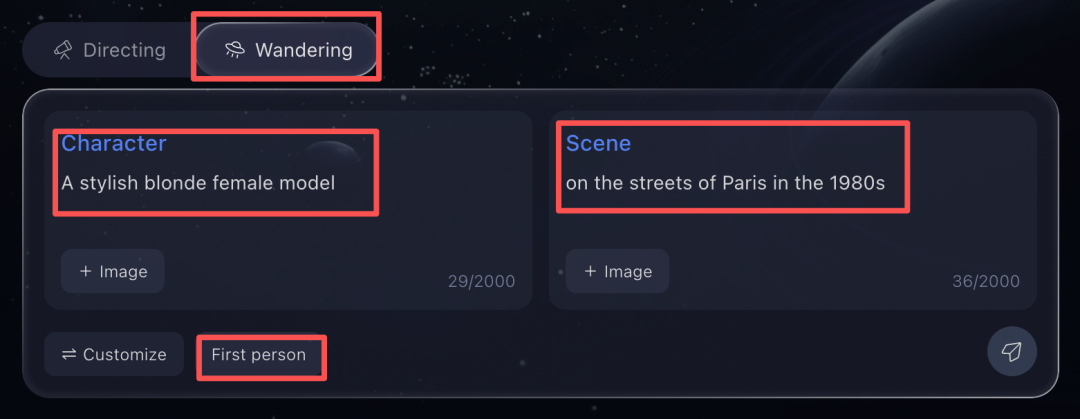
例如,在定制模式下,我们输入角色:“A stylish blonde female model”(一位时尚的金发女模特),场景:“on the streets of Paris in the 1980s”(在20世纪80年代的巴黎街头)。
模型在十几秒内,就构建出一个完整的夜景:雨后的巴黎街道,路面湿润倒映着昏黄路灯,汽车驶过,两旁店铺林立,细节符合物理规律。接下来,用户可以使用WASD键控制角色移动,或用方向键控制镜头推移,在这个空间里自由行走,实时生成视频。整个过程流畅,无明显卡顿,系统还会自动匹配贴合场景氛围的背景音乐。
我们尝试了更多风格。上传一张动漫风格的第一视角骑行图片后,HappyOyster基于这张静态图,延伸出了一个具有空间结构和运动逻辑的完整场景。当视角向前推进时,道路的延展、花海的分布以及远景的层次变化连贯自然,吉卜力风格的视觉语言和樱花飘落的氛围在整个运动过程中保持了一致性。
漫游功能对各种艺术风格展现出强大的适配能力,用户甚至可以直接“走进”梵高的画作中进行探索。
导演(Direct):实时操控的AI视频引擎
如果说漫游是探索一个既成世界,那么导演功能则允许用户成为这个世界的“造物主”,在视频的任意节点实时改变内容走向。
我们上传了一张吉卜力风格的图片。HappyOyster迅速生成一个宫崎骏式的动漫世界:一位小女孩撑着红色雨伞,走在雨后湿润的乡间小路上。
此时,我们在输入框键入:“一只可爱的吉卜力风格的小猫突然跑到女孩身边”。模型没有重新开始渲染,而是在当前画面中无缝生成了一只小猫,它跑向女孩并与其并肩同行。
我们继续追加指令:“女孩蹲下抚摸小猫。”画面再次即时响应,小女孩自然地蹲下身,伸手做出抚摸动作,整个过程流畅且符合动画逻辑。
总之,导演功能下的模型能够根据实时输入的提示词,精确地调整场景元素和人物动作,每个变化都与当前故事情节无缝衔接,实现了真正意义上的交互式叙事。
技术解读:世界模型和文生视频,差在哪里?
经过实测,一个直观的感受是:HappyOyster与Sora、可灵等文生视频模型很不一样。这种不同并非表面,而是源于底层逻辑的根本差异。
Sora、可灵这类文生视频模型,本质上是一个“一次性”系统。用户给定文本或图像条件后,模型在一个预设的时间窗口内组织内容、运动和节奏,然后输出一段完整的视频。流程是封闭的、单向的,用户中途无法介入更改已发生或即将发生的内容。这种模式适合生成一段精美的预定短片。
世界模型的思路则完全不同。它学习的核心是世界接下来会如何演化。它将当前状态作为输入,预测施加某个动作或条件后会发生什么。这个过程没有预设的终点,是一个持续的、开放的系统。当用户没有新输入时,模型基于已有状态自主延续世界发展;一旦用户中途注入新指令,模型就会结合“当前状态”重新推断后续走向。这意味着它可以随时被打断、干预和重写。
正因为这种开放性,世界模型的训练难度远高于文生视频模型。
首要挑战是速度。世界模型需要在用户指令输入的瞬间做出响应,任何明显延迟都会破坏沉浸感。HappyOyster采用了流式生成框架,将高维视频与多模态信息压缩为紧凑的动态潜在状态,大幅降低了单步生成的计算开销,从而实现低延迟的持续生成。控制信号(文本、图像、漫游指令)被设计为可在线注入的条件变量,模型无需重置就能在任意节点即时响应。
更棘手的是长时序一致性问题。生成时间越长,场景越容易出现内容漂移、结构退化,物理规律和空间约束可能失效。为了对抗这种“失忆”,HappyOyster引入了持续状态复用机制,通过历史注意力状态的连续传递,让模型高效继承已生成信息并渐进更新,从而在更长的时间跨度内维持稳定的场景结构与动态连贯性。
在音画协同上,HappyOyster没有将音频作为视频的后期附加物,而是采用统一的音视频联合生成框架。音频作为世界动态的一部分,在同一世界状态下与视觉信号同步生成,从而自然建立起跨模态的时间对齐关系。
目前,世界模型领域有几个不同的探索方向:Google的Genie专注于实时交互式世界建模,但在多模态统一表达和音视频联合生成上尚有局限;李飞飞团队的World Labs走的是3D空间结构化重建路线,更侧重几何一致性而非像素级的长时序动态生成。

HappyOyster选择的路径是:在像素空间内进行长时序、实时可交互的动态世界模拟,并集成音视频联合生成能力。这是一条此前鲜有人完全走通的道路,充满了技术挑战,也意味着没有太多现成答案可供参考。
结语:从“生成内容”到“构建世界”
AIGC发展至今,从文本、图像到视频的内容生成工具已日趋成熟。但行业正悄然逼近一个新的拐点:从 “生成内容”迈向“构建世界”。
HappyOyster的出现,勾勒出了这个方向的早期轮廓。它试图提供给每个人一个可以随时进入、实时修改、并得到即时反馈的“自定义数字世界”。你可以在其中漫游,可以担任导演,可以分享这个世界让他人继续演绎。
其应用场景的想象空间,远不止于屏幕内的娱乐体验。文旅展陈、互动短剧、影视概念验证、品牌营销、直播共创……凡是需要实时感知、实时生成、实时反馈形成闭环的场景,它都具备天然的应用潜力。从更长远的角度看,一旦与摄像头、传感器、空间计算设备等硬件结合,它可能演变成一个能被现实世界信号持续驱动和修改的生成式环境系统。
然而,必须清醒地认识到,世界模型整体仍处于非常早期的阶段。长时序下的物理一致性、复杂场景中的因果推理、对现实世界规律的深度理解与泛化,这些都是悬而未决的核心挑战。HappyOyster是目前这个方向上,形态最接近“可用产品”的探索之一。但“探索”本身就意味着边界尚未确定,能力存在局限。
这既是当前技术的局限,也恰恰是未来想象力和创新存在的理由。对于关注人工智能和交互式媒体前沿的开发者与创作者而言,这无疑是一个值得持续关注的方向。欢迎在云栈社区继续交流关于世界模型、多模态AI以及下一代人机交互的更多想法。
 发表于 2026-4-20 12:29:57
|
查看: 145|
回复: 0
发表于 2026-4-20 12:29:57
|
查看: 145|
回复: 0
