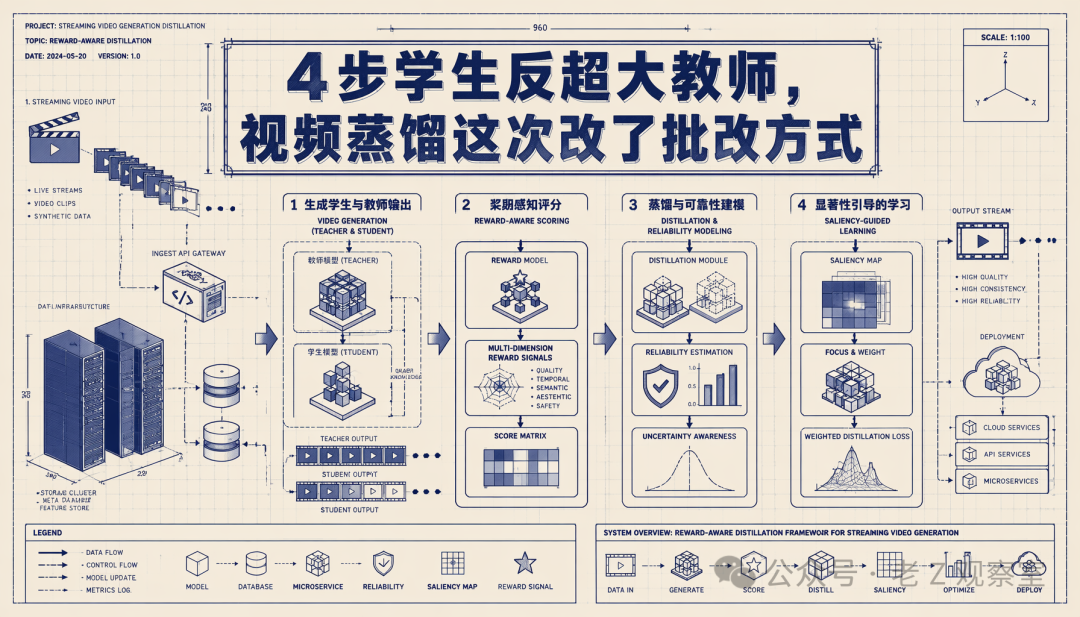
一个小模型,推理时只跑 4 步,就在 VBench 的总分和语义对齐上超过了自己的多步教师模型。结果乍看很反常:蒸馏不都是把大老师的能力压缩给小学生吗,学生怎么能反超老师?Stream-R1 这篇论文给出的答案,不是换了更大的学生,也不是在推理时加新模块,而是把训练阶段的「批改方式」给改了。
把这套方法放到真实业务里,问题会更直观。你让视频模型生成一段 60 秒的商品展示,前 10 秒模特还算稳定,后面衣服纹理就开始乱跳,背景货架慢慢漂移;或者做一段游戏剧情预览,角色起手动作还对,镜头推进几次后,手臂与道具的关系便开始扭曲。短视频里这些错或许只是瑕疵,但在长视频中,它会随时间一路传导下去,演变成系统性崩坏。
真正拖垮长视频的,往往不是第一帧
流式视频生成的吸引力在于,它不像固定窗口视频模型那样一次性憋出几秒,而是像接龙一样一段接一段地往后生成。这样才有机会支持实时交互、超长内容和边生成边调整。但接龙也带来一个老问题:前面一段若有轻微漂移,后面就会把它当成上下文继续放大,人物身份、背景结构、动作节奏都可能越走越偏。
现有蒸馏路线通常把多步教师模型压成少步学生,让学生更快模仿教师分布。问题在于,很多方法默认每条学生生成轨迹都同样值得学,每一帧、每一块画面区域都应该用同样强度去修。这个假设在短视频里勉强能用,到了长视频就显得粗糙:有些样本本身已接近高质量区域,教师信号更可靠;有些样本偏得很远,继续向它学习,可能只是在低质量区域里反复打磨低质量。
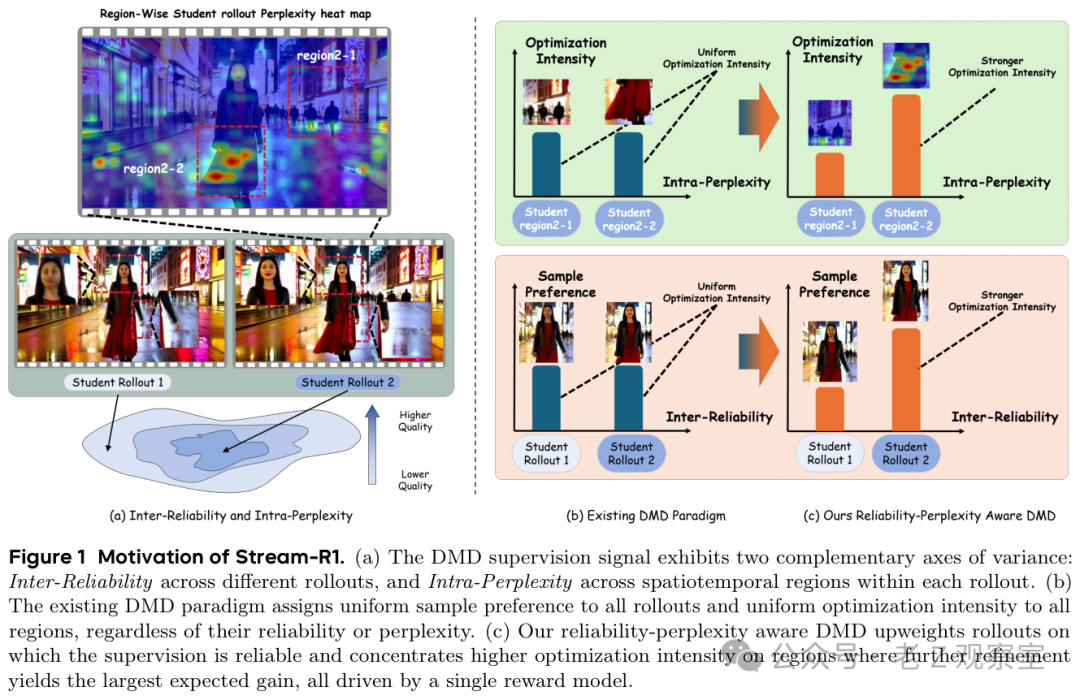
论文把这个矛盾拆成两个问题。一个是样本之间的可靠性:哪条生成轨迹更值得信任?另一个是样本内部的困惑度:同一段视频里,到底是人物脸部、手部动作、背景边缘,还是某几个时间片段最该被重点修?这一步拆分很关键——它把「视频质量不好」从一句笼统抱怨,变成了训练时可以分配预算的具体问题。
Stream-R1 像换了一位会圈重点的老师
Stream-R1 的核心做法,可以理解成把奖励模型从「打分器」升级成「训练路由器」。以往奖励模型常被拿来给整段视频一个分数:好就多学,差就少学。Stream-R1 继续使用奖励,但不满足于一个总分,而是让它同时回答两个问题:这条学生生成轨迹值不值得重点学?这条轨迹里面,哪里最该被修?
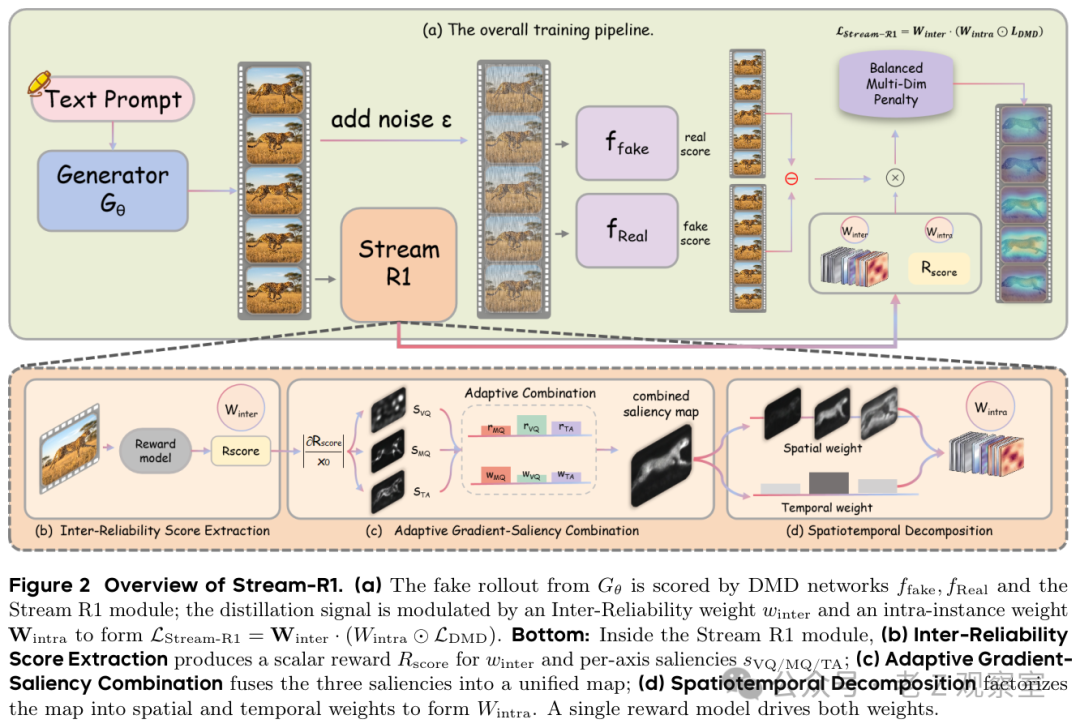
第一层是挑样本。学生模型每次生成一条视频轨迹后,奖励模型会评估它的视觉质量、运动质量和文本对齐。若一条轨迹已接近教师模型的高质量区域,它得到的训练权重就更高;如果偏离很远,模型不会把它当成同等可靠的老师。这个判断很朴素:不要让差作业占掉太多批改时间。
第二层更有意思:圈位置。奖励模型在看视频时,并非画面上所有像素、所有帧都同样影响分数。Stream-R1 利用这种敏感性,把训练火力集中到奖励最容易被改善的区域和时间片段。比如人物脸部已经清楚,背景也稳定,但手部动作和下半身出现模糊,那训练就不该继续平均涂抹整张画面,而应该把更多压力给到那些真正拖分的位置。
论文还做了一个很直观的可视化:把每帧下半部分人为加上模糊,而且模糊区域从左到右逐渐变大。结果奖励敏感区域会明显追着受损区域走,时间权重也从 0.587 增到 2.117。这个实验让人更愿相信它不是硬编一个注意力热图,而是确实把奖励模型的判断变成了可用的训练指引。

指标最有意思的地方:学生反超了教师
短视频实验里,Stream-R1 用 Wan2.1-T2V-1.3B 做学生,Wan2.1-T2V-14B 做教师,在 946 个 VBench 提示上评估 5 秒视频。结果它的总分达到 84.40,质量分 85.14,语义分 81.44;Reward Forcing 分别是 84.13、84.84、81.32。更有传播性的点是,它在总分和语义对齐上超过了多步教师 Wan2.1,而推理速度保持在 23.1 FPS。这不是「小模型全面碾压大模型」,但足够说明:蒸馏不一定只是压缩,也可能通过更聪明的训练信号,避开教师分布里的低效部分。
长视频更贴近这篇论文的主战场。论文在 10 秒、30 秒、60 秒、120 秒、180 秒五种长度上比较 Stream-R1 和 Reward Forcing。Figure 4 里最重要的不是某个点赢了多少,而是趋势:视频越长,差距越明显。对流式生成来说,这说明时间维度上的训练分配确实在发挥作用,否则模型很容易在前几十秒看着还行,后面逐步掉进漂移。
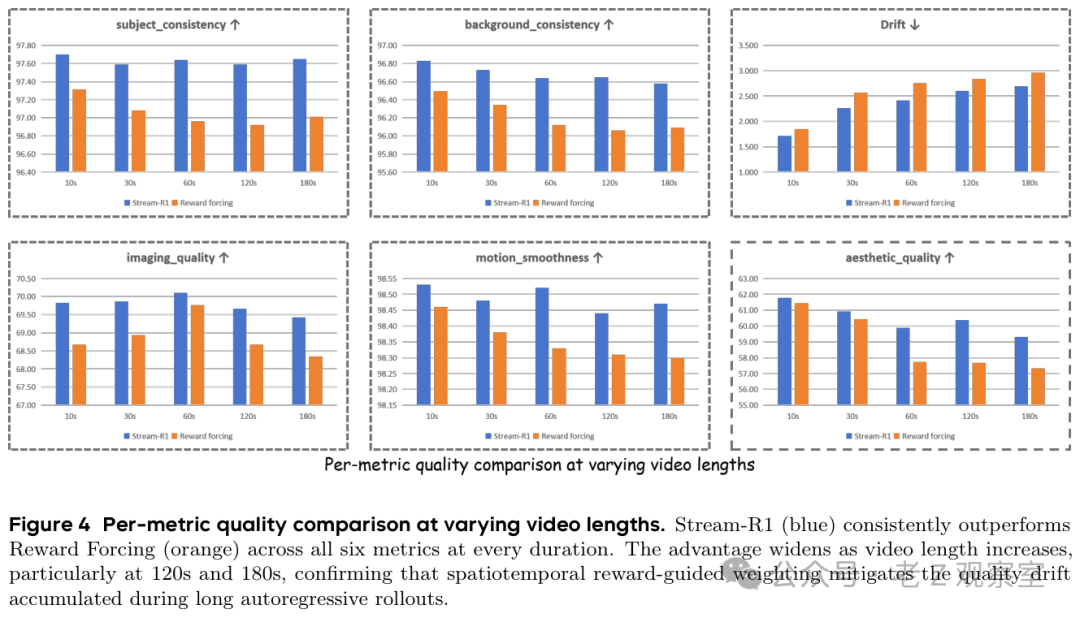
这对内容生产者很现实。假设你要用 AI 做一分钟口播广告,失败常常不是第一帧的脸不够精致,而是后半段嘴型、手势、背景小物件一点点不守规矩;假设你做分镜预演,导演真正怕的也不是某一帧轻微噪声,而是镜头连续推进后空间关系乱掉。Stream-R1 的时间权重至少给了一个工程答案:训练时不能只看单帧好不好看,还要把那些会把错误带到后续片段的时间点提前拎出来。这个判断比单纯刷短视频榜单更接近产品问题。
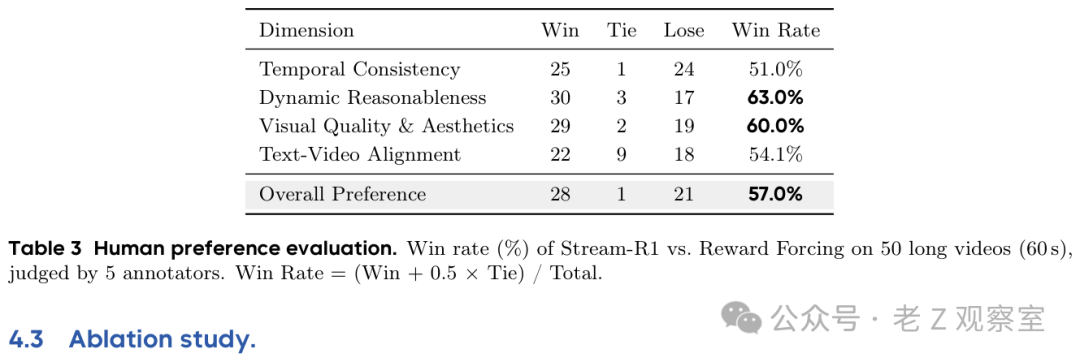
机器评分和人评也给了一个有趣对照。Qwen3-VL 评估 60 秒视频时,Stream-R1 的视觉质量为 4.92、文本对齐为 4.11,都是最高;动态分 4.04,略低于 Reward Forcing 的 4.18。但在人类偏好测试里,5 名标注者看 50 条 60 秒视频,Stream-R1 在所有维度都更占优,其中动态合理性胜率 63.0%,视觉质量与美感 60.0%,总体偏好 57.0%。这个分歧或许在提醒我们:视频生成的自动指标还没完全抓住人眼对「动作合理」的感受。
消融实验则把关键部件拆得更清楚。只加空间奖励后,质量分从 84.16 到 84.46,长视频总分从 79.45 到 80.71;加入时间分解后,短视频总分升到 84.40,长视频漂移从 2.697 降到 2.417。我的判断是,空间权重主要解决「画面哪里糊」,时间权重才是长视频稳定性的关键,因为它决定模型是否能在错误开始扩散前,把某些时间片段拉回来。
这不是免费魔法,但方向很值得跟
当然,Stream-R1 不是一个免费按钮。论文的训练设置用了 8 张 A100,跑了约 56 小时;奖励敏感性也需要在训练阶段额外计算。它的好处在于推理时不增加成本,但训练端并不轻。对团队来说,如果本来就没有稳定的视频训练管线,直接复现这套方法不会轻松。
另一个存疑点是奖励模型本身。如果奖励模型偏好过度清晰的静态画面,或者对复杂运动理解不准,那么「圈重点」也可能圈错。尤其视频生成常常在审美、物理合理性、文本忠实度之间拉扯,某个奖励轴被误读,训练就可能向错误方向集中。这篇论文似乎还没解决视频奖励的全部可靠性问题,它更像在告诉我们:奖励模型的价值不止是给分,还能把训练信号拆得更细。
这里还有一个容易被忽略的工程问题:奖励模型看到的「好」未必等于业务里的「好」。广告片可能更在意商品不变形,动画分镜可能更在意动作连贯,数字人可能更在意口型和身份一致。Stream-R1 提供的是一套分配训练注意力的方法,真正落地时还要把奖励维度换成任务关心的指标。否则模型很勤奋地修了画面亮度,却放过了角色手指穿模,这种进步对用户来说并不值钱。
所以,这篇论文最值得关注的地方,不是总分从 84.13 到 84.40 这种小数点差距,而是它把视频蒸馏的竞争从「谁的学生更会模仿老师」推进到「谁更会分配训练预算」。当视频生成走向一分钟、三分钟,甚至实时交互,模型会不会生成只是入场券,训练过程会不会识别可靠监督、会不会把力气用在最该修的帧上,可能会变得越来越重要。
回到开头那个反直觉结果:学生反超老师,并不是因为老师不强,而是因为学生没有盲目抄整本答案。它学会了挑更可靠的样本,盯住更关键的错误。视频生成接下来要拼的,或许不只是更大的模型,还有更聪明的批改方式。对这类前沿技术的探索感兴趣,不妨在云栈社区看看更多同行的深度解读与实践分享。
 发表于 2026-5-11 20:10:50
|
查看: 97|
回复: 0
发表于 2026-5-11 20:10:50
|
查看: 97|
回复: 0
