云栈社区的小伙伴们经常讨论一个让人头疼的问题:手机拍照的夜景噪点到底怎么破?深度学习降噪模型虽然效果惊艳,但一到手机上就水土不服。全局自注意力、可变形卷积这些在 GPU 上风生水起的操作,到了手机的神经网络处理单元(NPU)上要么压根不支持,要么慢得让人抓狂,最后只能退回 CPU 或 GPU 运行,功耗飙升,手机秒变暖手宝。
来自维尔茨堡大学计算机视觉实验室的 Faraz Kayani 等人,在 Mobile AI 2026 图像降噪挑战赛中给出了一套硬核解法。核心思路直截了当:既然 NPU 才是最终的运行平台,那就从一开始就只用 NPU 原生支持的算子。3x3 卷积、ReLU 激活、最近邻上采样——就这三板斧,别整那些花里胡哨的。然后靠一个高性能的教师网络通过知识蒸馏,把真本事教给这个轻量级学生。最终,学生模型仅 1.96M 参数,在全分辨率验证集上 PSNR 达到 37.66 dB,SSIM 达到 0.9278,几乎追平了 41.6M 参数的教师模型,质量恢复率达到 99.8%。

图1:验证集上的定性对比。第一行为完整图像,第二行为同一区域放大裁切。从左到右依次为:含噪输入、本文轻量级学生模型的重建结果、真实干净图像。该学生模型在有效抑制可见噪声的同时,保留了局部结构和精细纹理。
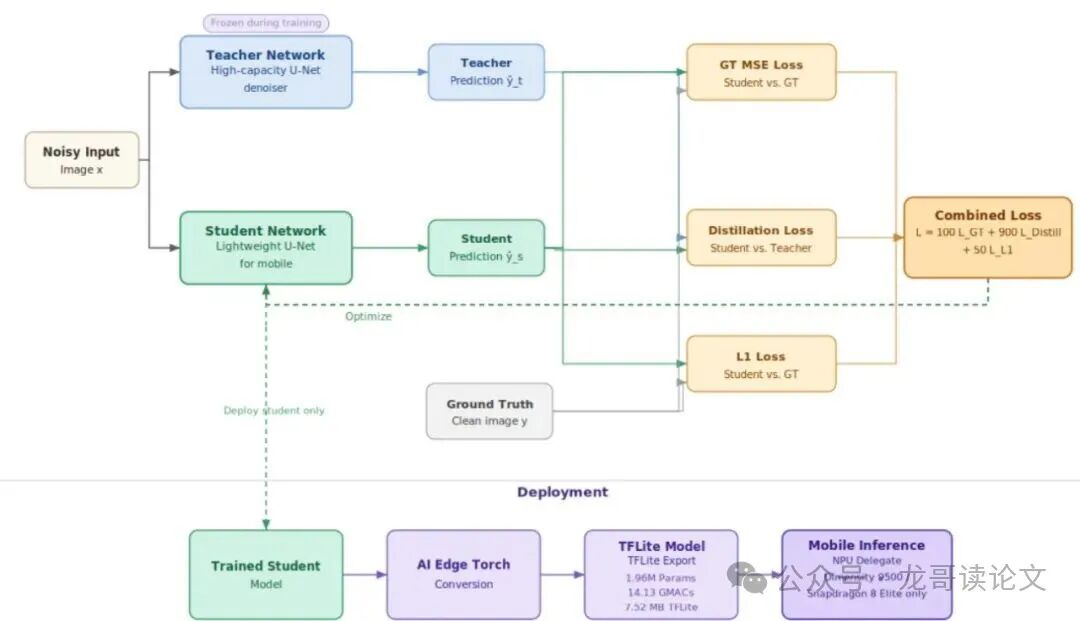
图2:本文提出的教师-学生移动降噪流水线总览。训练阶段,高性能教师使用真实图像重建损失、蒸馏损失和 L1 损失来指导轻量级学生。部署阶段,训练好的学生模型通过 AI Edge Torch 导出为 TensorFlow Lite 格式,实现无回退的 NPU 推理。
“推理反转”效应:NPU 比 GPU 快 3.88 倍
大家的刻板印象里,GPU 算力强,NPU 只能跑跑人脸解锁这类轻活。但这篇论文直接打脸——作者发现,当模型完全由 NPU 原生算子构建时,NPU 上的推理速度竟然比手机集成 GPU 快 2.86 倍(骁龙 8 Elite)到 3.88 倍(天玑 9500)。他们把这个现象称为推理反转效应(Inference Inversion)。
在官方 Full HD 分辨率(1088x1920)评测协议下,本文学生模型在骁龙 8 Elite NPU 上仅需 46.1 毫秒,在天玑 9500 NPU 上更是只有 34.0 毫秒。而同一模型在骁龙 8 Elite 的 GPU 上需要 127 毫秒,在天玑 9500 GPU 上要 138 毫秒。换句话说,本来以为 GPU 是主角,结果 NPU 成了隐藏大腿。背后的原因很简单:没有框架层回退,所有算子都走硬件加速的快速路径,避免了 CPU 和 GPU 之间频繁的数据搬运和内存访问开销。
硬件友好的轻量级学生网络设计
学生网络名为 LiteDenoiseNet,是一个超轻量的编码器-解码器结构。作者设定了三条硬性设计原则,确保每一个操作都能在 NPU 上高效执行:
第一,高度向量化的基础宽度。 特征图的基础通道数设为 16,并随下采样阶段逐步倍增。这个选择完美匹配现代 NPU 的 SIMD(单指令多数据流)执行特性,让向量计算单元利用率拉满。
第二,核心计算单元:LiteDenoisingBlock。 每个块只使用标准 3x3 卷积和 ReLU 激活,避免 GELU、Swish 这类在移动平台上会产生惩罚性延迟的复杂非线性函数。块内还采用了通道缩减瓶颈(从 f 缩到 f/2 再回到 f),减少计算量但保留残差连接。
第三,抛弃转置卷积。 解码器中的上采样全部改用无参数的最近邻插值加上一个 3x3 卷积精修,完全消除了转置卷积中复杂的零填充逻辑在 NPU 上可能触发的硬件回退。最终输出通过全局残差学习获得:
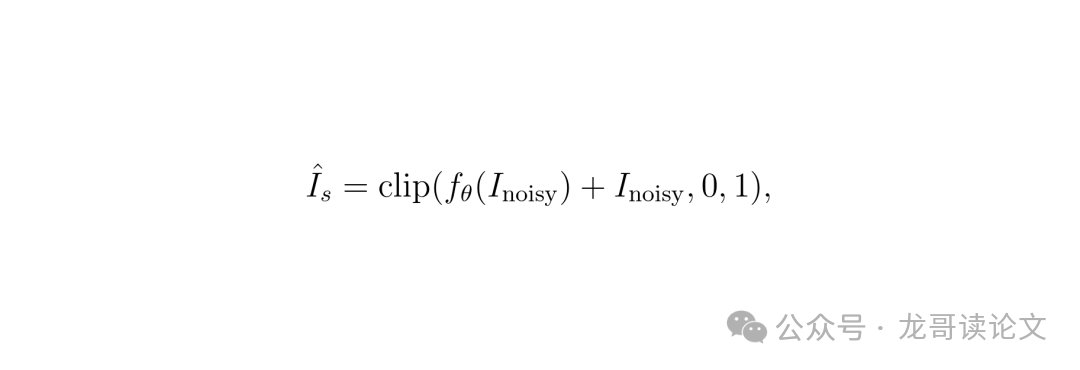
其中 f_θ 表示学生网络,I_noisy 为带噪输入,输出被裁剪到 [0,1] 范围。整个学生网络仅有 1.96M 参数,完美兼容旗舰 NPU 的快速执行图。
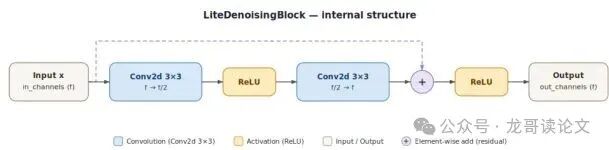
图3:LiteDenoisingBlock 的内部结构。该块在标准 3x3 卷积之间使用通道缩减瓶颈(f → f/2),配合硬件原生的 ReLU 激活和局部残差连接。
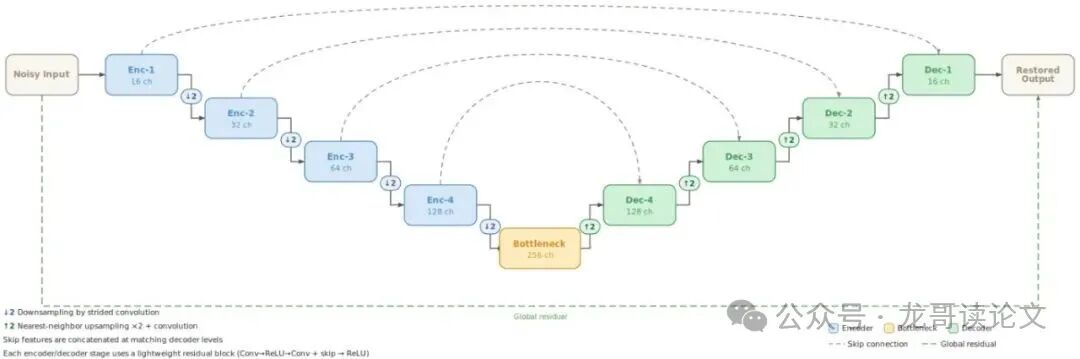
图4:轻量级学生降噪模型的简化内部结构。网络采用紧凑的 U-Net 风格设计。编码器和解码器中重复的处理单元是 LiteDenoisingBlock。对 NPU 部署至关重要的是,下采样通过步长卷积实现,而解码器使用硬件友好的最近邻上采样后接卷积精修,而不是转置卷积。
高 α 知识蒸馏与渐进式上下文扩展
教师网络是一个 41.6M 参数的高容量 U-Net,在验证集上达到了 37.71 dB 的 PSNR。学生网络参数少,感受野受限,直接训练只能到 36.08 dB,与教师有 1.63 dB 的差距。作者祭出了高 α 知识蒸馏,即蒸馏损失权重远大于重建损失。总损失函数如下:
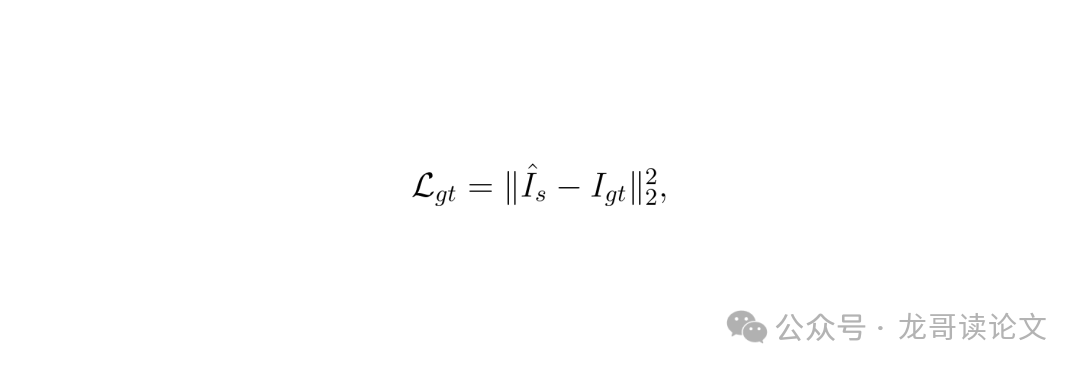
这是与真实图像的重建 L2 损失。
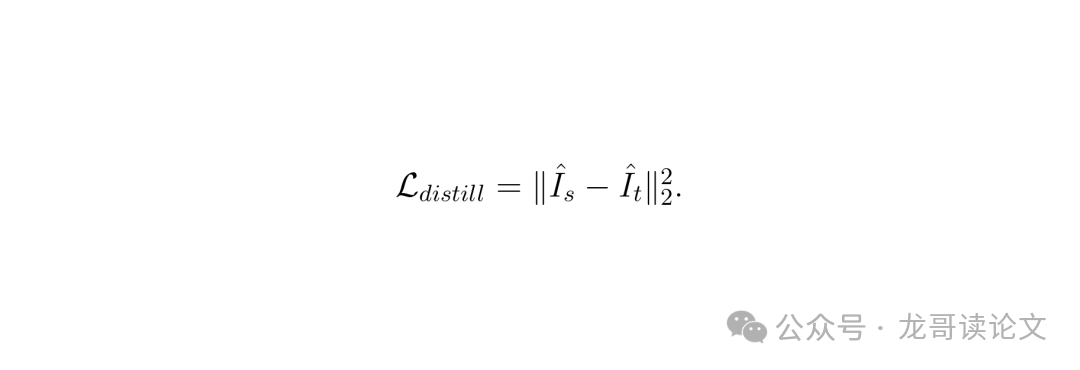
这是蒸馏损失,强制学生模仿教师的输出。
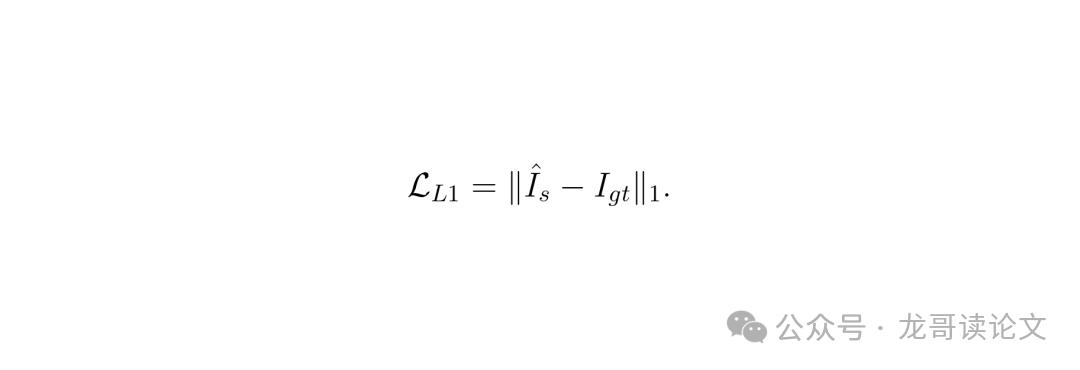
额外的 L1 损失用于稳定高频纹理生成。
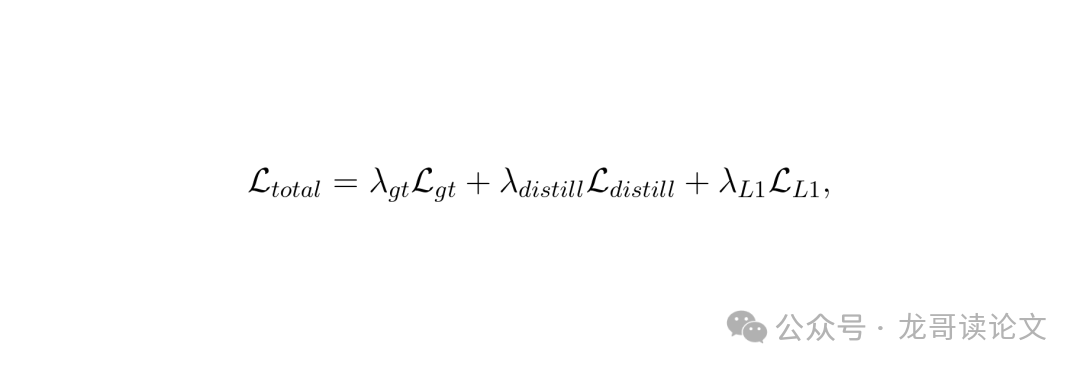
其中 λ_gt=100,λ_distill=900,λ_L1=50。蒸馏损失的权重是重建损失的 9 倍,这就是“高 α”(α=0.9,即蒸馏损失占总损失的 90%)的含义。通过这种方式,学生能学到教师对噪声的平滑预测,而不是硬去拟合真实图像中可能残留的传感器噪声。
此外,作者还提出了渐进式上下文扩展策略。因为学生网络非常轻量,感受野有限,在精细调优阶段,训练裁切尺寸从 256×256 逐步增加到 512×512,最后到 1024×1024。巨大的空间上下文让模型能够学到全局亮度梯度和结构连贯性,全分辨率推理质量因此大幅提升。
结果与讨论:定量、定性与推理逆反
消融实验结果在表1中清晰展示。从最初 0.34M 参数的注意力增强模型(31.68 dB,编译失败),到 41.6M 参数的教师(37.71 dB,但在 8MP 分辨率下显存溢出),再到 12 滤波器的超轻量基线(34.86 dB,26.4 ms),最后到 16 滤波器的蒸馏学生(37.66 dB,46.1 ms),整个发展脉络非常清晰:硬件兼容性是第一限制,知识蒸馏是救世主。
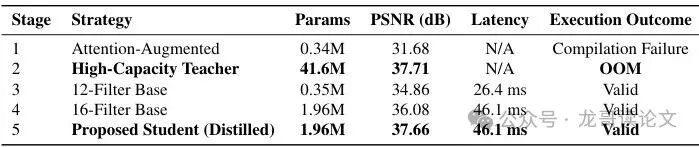
表1:架构演进的系统消融实验。PSNR 在全分辨率验证集上报告,延迟在 NPU 上按 Full HD 协议测量。
在与挑战赛其他方法的对比中(表2),本文方法以 37.58 dB 的测试 PSNR 位居榜首,并且是在两个目标 NPU 上都有有效运行时间的方法中 PSNR 最高的。在 NPU 重新计算的分数中,本文方法以 139.5 分大幅领先第二名 TLG 的 118.8 分。

表2:从 NPU 视角重新审视 Mobile AI 2026 图像降噪挑战赛结果。方法按测试集 PSNR 降序排列。PSNR 和 SSIM 在全分辨率下评估,运行时间在 Full HD 下获取。
教师-学生单张图像的 PSNR 差距分布直方图(图5)显示,绝大多数图像的差距在 0 附近,平均差值仅 0.08 dB,学生偶尔还能小胜教师。
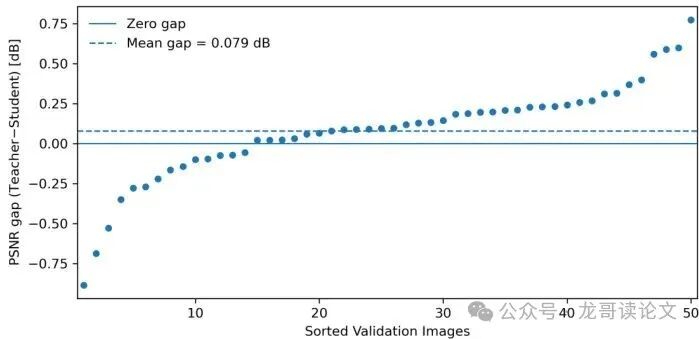
图5:50 张验证图像上教师与蒸馏学生之间的每图像 PSNR 差距排序。正值表示教师 PSNR 更高,负值表示蒸馏学生略优。大部分差距接近零,与 0.08 dB 的平均差值一致。
定性结果在图1中已经展示,学生模型在抑制噪声的同时保留了精细纹理,没有出现过度平滑。而推理逆反效应我们已经讨论过了——NPU 在专属加速下比 GPU 快 3.88 倍,让 NPU 成为了更优的推理目标。
总结、局限与未来展望
本文的贡献非常清晰:第一,提出了一个硬件-算法协同设计的教师-学生框架;第二,设计了一个完全由硬件友好算子构成的轻量级学生网络;第三,通过高 α 蒸馏和渐进式上下文扩展,1.96M 参数的学生恢复了教师 41.6M 参数质量的 99.8%;第四,在骁龙 8 Elite 和天玑 9500 上跑出了 46.1ms 和 34.0ms 的 NPU 延迟。
不过局限也很明显:论文只在特定两款旗舰 NPU 上验证,更广泛的兼容性未知;渐进式上下文扩展需要大尺寸训练裁切,GPU 显存需求较高,1024x1024 的批次很吃显存;另外,由于完全放弃转置卷积,模型对不同上采样因子的适应能力有限,未来可能需要针对更多分辨率做差异化优化。
未来工作方向可以包括:将方法扩展到其他低层视觉任务,比如超分、去模糊、HDR 融合;探索 NPU 友好的注意力机制变体;以及研究自动搜索最佳硬件友好算子组合的 NAS 方法。
龙迷三问
这篇论文解决什么问题?
解决的是真实图像去噪模型在手机 NPU 上部署难的问题。以往去噪模型效果好但算子不兼容 NPU,导致只能跑在耗电的 GPU 上或者干脆跑不起来。本文通过硬件-算法协同设计,只使用 NPU 原生支持的算子(3x3 卷积、ReLU、最近邻上采样),再通过知识蒸馏从大模型中学习,实现了高质量加低延迟的移动端去噪。
什么是 NPU?什么是知识蒸馏?
NPU 是 Neural Processing Unit(神经网络处理单元)的缩写,是手机 SoC 中专用于加速神经网络计算的硬件模块,比如高通的 Hexagon NPU、联发科的 APU。知识蒸馏是一种模型压缩技术,用一个大型教师模型(高精度但笨重)的输出来监督一个小型学生模型(轻量级、可部署)的学习,让学生模仿教师的行为,从而在参数大幅减少的情况下保持接近的性能。
推理反转效应是怎么发生的?
通常人们认为手机 GPU 算力强于 NPU,但本文发现当模型完全由 NPU 原生算子构建时,没有不兼容的算子导致 CPU 回退,NPU 可以执行纯硬件加速,避免框架层的开销和内存搬运,所以反而比 GPU 快 2.86 到 3.88 倍。这个现象就叫推理反转。
龙哥点评
论文创新性分数: ★★★★☆
将硬件兼容性作为第一设计约束的蒸馏框架具有很强的新颖性,提出的“推理反转”效应令人印象深刻。
实验合理度: ★★★★☆
消融实验设计清晰,从低到高逐步验证;与挑战赛其他方法公平对比,但部分对比方法数据来自主办方表格,未提供公平的 GPU/NPU 时间对比。
学术研究价值: ★★★★☆
为移动端降噪的硬件-算法协同设计提供了系统方法论,推动了深度学习模型在边缘设备上部署的研究,具有重要参考意义。
稳定性: ★★★☆☆
仅在特定两款旗舰 NPU 上测试,更广泛硬件的稳定性和泛化能力未知;模型对输入分辨率有一定要求(Full HD 下 14.13 GMACs),但 NPU 驱动差异可能引入不稳定因素。
适应性以及泛化能力: ★★★☆☆
只针对图像降噪任务和有限硬件平台,任务泛化性和跨平台(如其他品牌 NPU)适配性未研究。
硬件需求及成本: ★★★★☆
学生模型仅 1.96M 参数、7.52 MB 存储、Full HD 下 14.13 GMACs,部署成本很低;但训练需要 RTX 4090 和较大显存(1024×1024 裁切)。
复现难度: ★★★★☆
学生模型和训练统计已公开在 NN Dataset(GitHub),且提供了详细的导出部署流程,复现相对容易,但教师模型未开源。
产品化成熟度: ★★★★☆
已在两款旗舰 NPU 上实测通过,且严格遵循移动 AI 挑战赛的部署协议,接近产品级;但需要针对更多手机品牌和 NPU 进行适配验证。
可能的问题:
实验验证的硬件平台仅两款,对其他 NPU(如华为达芬奇、谷歌 TPU、苹果 ANE)的兼容性未知;渐进式上下文扩展的最后阶段(1024×1024)对显存要求较高;教师模型完全基于卷积,没有尝试更先进的 transformer 架构作为教师。
主要参考文献
[1] Abdelrahman Abdelhamed, Stephen Lin, and Michael S. Brown. A high-quality denoising dataset for smartphone cameras. In CVPR, 2018. (SIDD)
[2] A. Abdelhamed, M. Afifi, T. et al. NTIRE 2020 challenge on real image denoising. In CVPR Workshops, 2020.
[3] A. Abdelhamed, M. Afifi, R. Timofte, et al. NTIRE 2021 challenge on real image denoising. In CVPR Workshops, 2021.
[4] S. Guo, Z. Yan, K. Zhang, W. Zuo, and L. Zhang. Toward convolutional blind denoising of real photographs. In CVPR, 2019. (CBDNet)
[5] Y. Li, X. Liu, L. Jin, et al. HINet: Half instance normalization network for image restoration. In CVPR, 2021.
[6] Z. Liu, Y. Lin, Y. Cao, et al. Swin Transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021. (SwinIR)
[7] PyTorch. AI Edge Torch. https://pytorch.org/edge, 2025.
[8] A. Ignatov, R. Timofte, et al. Mobile AI 2021 challenge. In CVPR Workshops, 2021.
[9] R. Flepp, A. Shonen, et al. MIDD: A mobile image denoising dataset with efficient baselines. In CVPR Workshops, 2025.
[10] A. Ignatov et al. LEMUR NN Dataset framework. GitHub, 2025.
[11] S. Anwar and N. Barnes. Real image denoising with feature attention. In CVPR, 2019. (RIDNet)
[12] G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. NeurIPS Workshop, 2015.
[13] A. Ignatov et al. Mobile AI 2022 challenge. In CVPR Workshops, 2022.
[14] A. Ignatov et al. Mobile AI 2026 image denoising challenge results. In CVPR Workshops, 2026.
[15] Z. Wang et al. Lightweight image restoration with knowledge distillation. In ECCV, 2024.
[16] Y. Li et al. Two-phase knowledge transfer for lightweight denoising. In AAAI, 2023.
[17] S. W. Zamir, A. Arora, S. Khan, et al. Restormer: Efficient transformer for high-resolution image restoration. In CVPR, 2022.
[18] Y. Liu et al. MFDNet: Mobile-friendly denoising network with NPU-aware design. In CVPR Workshops, 2025.
[19] A. Ignatov et al. MAI 2026 benchmark leaderboard. https://ai-benchmark.com, 2026.
[20] T. Plotz and S. Roth. Benchmarking denoising algorithms with real photographs. In CVPR, 2017. (DND)
[21] A. Romero, N. Ballas, S. E. Kahou, et al. FitNets: Hints for thin deep nets. In ICLR, 2015.
[22] O. Ronneberger, P. Fischer, and T. Brox. U-Net: Convolutional networks for biomedical image segmentation. In MICCAI, 2015.
[23] Z. Wang et al. Practical raw denoising for mobile devices. In ECCV, 2020.
[24] L. Chen, X. Chu, X. Zhang, and J. Sun. Simple baselines for image restoration. In ECCV, 2022. (NAFNet)
[25] J. Young et al. Feature-level distillation for efficient RAW denoising. In WACV, 2022.
[26] Z. Wang, X. Cun, J. Bao, et al. Uformer: A general U-shaped transformer for image restoration. In CVPR, 2022.
[27] S. W. Zamir, A. Arora, S. Khan, et al. MIRNet: Learning enriched features for image restoration. In CVPR, 2020.
[28] S. W. Zamir, A. Arora, S. Khan, et al. MPRNet: Multi-stage progressive image restoration. In CVPR, 2021.
[29] K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE TIP, 2017. (DnCNN)
[30] K. Zhang, W. Zuo, and L. Zhang. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE TIP, 2018.
本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。

 发表于 2026-5-7 06:13:29
|
查看: 104|
回复: 0
发表于 2026-5-7 06:13:29
|
查看: 104|
回复: 0
