用 C++ 写线程池,就是个一遍遍证明自己是个傻X的过程。
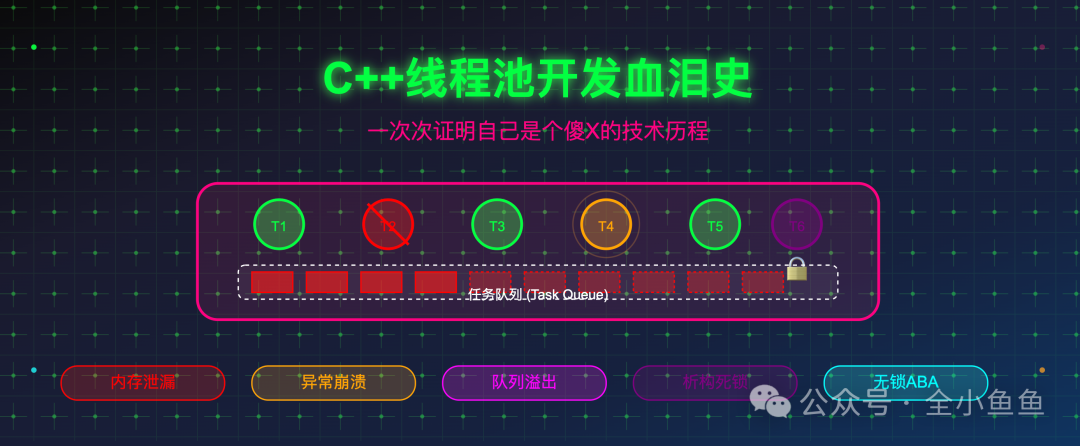
1、裸指针传参,内存漏成筛子
刚开始写那会,C++ 标准库里还没有线程池,那会用 pthreads。想在线程里调个类的成员函数,需要手写结构体,把 this 指针和参数打包进去,new 出来转成 void* 传给 pthread_create,再在另一头强转回来。用完还得手动 delete。
结果有次忘了 delete,服务上线后的第 3 天,就崩溃了。日志里干干净净,团队里的其他同事也是一头雾水,那天我查了一宿,最后发现是漏了个 delete。那会的开发很原始,但是对多线程的开发理解很深刻,有时感觉自己写的不是程序,是自毁装置。
2、lambda 很爽,异常差点要了半条小命
C++11 来了,lambda 一行提交任务,std::thread 跨平台,std::lock_guard 自动解锁。代码写的清爽,以为高枕无忧了。
结果有个任务抛了未捕获异常,直接 std::terminate。十个线程慢慢死到剩俩,监控一切正常,就是不干活。现代 C++ 的 RAII 解决了锁问题,但没解决异常传播问题。
那一次后,为了避免类似的问题再次发生,我给每个工作线程都套 try-catch:
try { task(); }
catch (...) { /* log, but don't die */ }
这不是为了逃避错误,是为了尽早发现问题,确保线程可用。
3、队列无限,内存溢出没商量
后来我又栽在队列上。系统资源是有限的,任务积压不是缓冲,是雪崩前兆。前端突发流量涌入,std::queue 无限增长,内存爆掉,OOM killer 直接杀进程。
我们在使用线程池时,都会设置 max_size,但你问过自己满了后该怎么办吗?丢弃、阻塞、或回调通知上层降级,不管怎么样,但必须有策略。线程池是资源控制器,不是垃圾桶。没有边界的设计,迟早被现实打脸。
4、无锁很酷,调试到想哭
用 std::atomic 实现多生产者单消费者,吞吐翻倍,牛的很。但很快出事:ABA 问题导致节点被提前回收,程序随机 crash。
后来请教大佬才知道,工业级无锁队列需要 hazard pointer 或 epoch-based memory reclamation。那会精力不足,两周后放弃,回归分段锁队列。性能重要,但可调试性更重要。稳定压倒一切,尤其是在边缘设备上。
5、析构顺序不对,ARM 上直接挂
最隐蔽的坑在对象析构顺序。有次在边缘设备上,线程池析构时 hang 死。x86 上跑得好好的,ARM 上直接挂。
最后靠 helgrind 定位到:成员变量声明顺序是 workers_、cv_、mtx_,析构时 mtx_ 先于 cv_ 销毁。而某个工作线程还在 cv_.wait(lock) 中,引用了已销毁的 mutex。C++ 对象析构顺序是成员声明的逆序,这是常识,但因为常识产生的bug,才是最折磨人的。
6、notify 在锁内,白白浪费 CPU
还有个细节是 condition_variable 的 notify 时机。我最初这么写:
{
std::lock_guard lock(mtx_);
tasks_.push(task);
cv_.notify_one();
}
后来改为:
{
std::lock_guard lock(mtx_);
tasks_.push(task);
} // 先释放锁
cv_.notify_one(); // 再 notify
因为被唤醒的线程会立刻抢锁。如果 notify 时锁还 held,它抢不到,白白上下文切换一次。实测性能差 10%~15%。这不是理论,是我在高吞吐网关上测出来的。
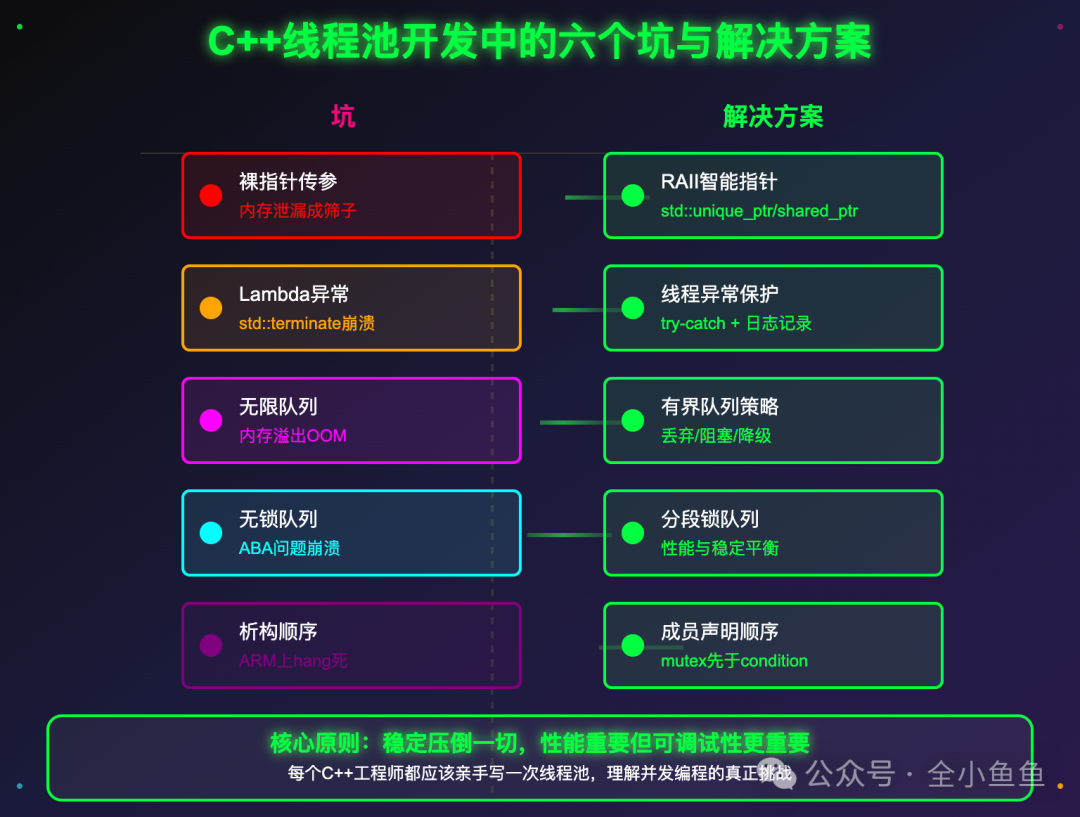
最后,我还是建议每个 C++ 工程师亲手写一次线程池。主要是为了理解:并发的魔鬼不在 API,而在你忽略的边界条件、资源生命周期和硬件差异。
我干开发好多年,到现在也不敢说完全搞懂了。每次以为稳了,总能在新平台上栽个新坑。你呢?你最近写的线程池,有没有在你不注意的时候,悄悄搞过什么鬼?
- 任务抛异常,线程是不是偷偷退了?
- 队列爆满,内存是不是静默炸了?
- 析构时,有没有线程还在等一个已销毁的
mutex?
如果你也有类似的“血泪史”,或者对操作系统底层的并发原理想有更深入的探讨,欢迎来云栈社区交流分享,一起填坑。
 发表于 2026-2-20 18:58:47
|
查看: 140|
回复: 0
发表于 2026-2-20 18:58:47
|
查看: 140|
回复: 0
