本系列旨在探讨增强现代智能体系统可靠性的各种设计模式,力求以直观的方式呈现每个概念,剖析其设计目标,并最终实现一个简单可行的版本,以展示其如何融入现实世界的智能体系统。本系列共包含14篇文章,此为第11篇。原文:Building the 14 Key Pillars of Agentic AI。
优化智能体系统的关键在于运用软件工程思维,确保各个组件能够协调、并行地工作,并与系统高效交互。例如,预测执行(Speculative Execution) 会尝试预先处理可预测的查询来降低延迟;而冗余执行(Redundant Execution) 则让同一智能体重复运行多次,以防单点故障。其他提升现代智能体系统可靠性的常见模式还包括:
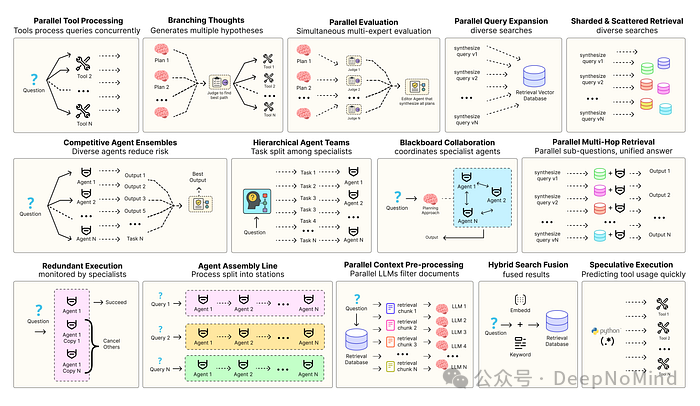
- 并行工具使用:智能体同时执行独立的API调用,以隐藏I/O等待时间。
- 层级智能体:管理智能体将任务分解为多个小步骤,交由专门的执行智能体处理。
- 竞争性智能体组合:多个智能体分别提出答案,系统从中选出最佳方案。
- 冗余执行:让两个或多个智能体解决同一任务,以检测错误并提高可靠性。
- 并行检索与混合检索:多种检索策略协同运行,以提升返回上下文的质量。
- 多跳检索:智能体通过迭代式的检索步骤,收集更深入、更相关的信息。
当然,还有更多其他模式。
本系列的目标是实现这些最常用智能体模式背后的基础概念。我们将逐一介绍,拆解其设计目的,然后用简单可行的代码实现它,并演示如何将其融入一个更完整的智能体系统中。
所有理论和代码都位于GitHub仓库中:🤖 Agentic Parallelism: A Practical Guide 🚀。
代码库的组织结构如下:
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb
分片与分散检索
随着知识库从数千份文档增长到数百万甚至数十亿份,单一、庞大的向量存储逐渐成为主要瓶颈。搜索延迟不断增加,索引本身也变得异常臃肿,难以管理和更新。
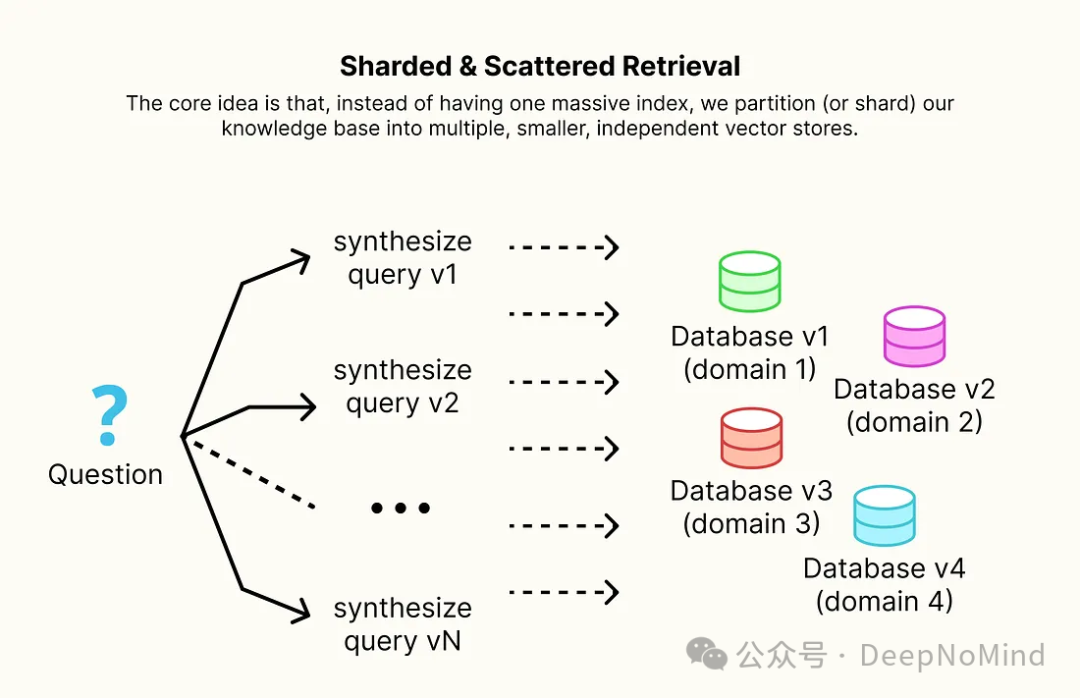
解决这一问题的架构方案正是分片和分散检索。其核心思想是,摒弃单一的庞大索引,转而将知识库分割(或分片)成多个更小、独立的向量存储。
你可以根据任何逻辑来划分这些分片,例如主题、日期或数据来源。当用户查询到达时,一个中央协调器会将查询“分散”到所有分片中。这些分片并行执行搜索,然后协调器收集结果并重新排序,以找出全局最相关的文档。
接下来,我们将构建一个模拟的双分片系统(工程 vs. 市场营销),并与一个模拟的单体系统进行比较,从而在延迟和答案质量两方面理解其优势。
首先,我们需要创建知识库分片。我们将生成两个独立的文档列表,每个列表包含特定领域的信息。
from langchain_core.documents import Document
# 模拟“工程”知识库分片的文档列表
eng_docs = [
Document(page_content="The QuantumLeap V3 processor utilizes a 3nm process node and features a dedicated AI accelerator core with 128 tensor units. API endpoint `/api/v3/status` provides real-time thermal throttling data.", metadata={"source": "eng-kb"}),
Document(page_content="Firmware update v2.1 for the Aura Smart Ring optimizes the photoplethysmography (PPG) sensor algorithm for more accurate sleep stage detection. The update is deployed via the mobile app.", metadata={"source": "eng-kb"}),
Document(page_content="The Smart Mug's heating element is a nickel-chromium coil controlled by a PID controller. It maintains temperature within +/- 1 degree Celsius. Battery polling is done via the `getBattery` function.", metadata={"source": "eng-kb"})
]
# 模拟“市场营销”知识库分片的文档列表
mkt_docs = [
Document(page_content="Press Release: Unveiling the QuantumLeap V3, the AI processor that redefines speed. 'It's a game-changer for creative professionals,' says CEO Jane Doe. Available Q4.", metadata={"source": "mkt-kb"}),
Document(page_content="Product Page: The Aura Smart Ring is your personal wellness companion. Crafted from aerospace-grade titanium, it empowers you to unlock your full potential by understanding your body's signals.", metadata={"source": "mkt-kb"}),
Document(page_content="Blog Post: 'Five Ways Our Smart Mug Supercharges Your Morning Routine.' The perfect temperature, from the first sip to the last, means your coffee is always perfect.", metadata={"source": "mkt-kb"})
]
我们有意创建了两个知识领域截然不同的分片。关于 QuantumLeap V3 的技术规格仅在 eng_docs 中,而其市场定位信息仅在 mkt_docs 中。这种分离将用于测试系统是否能从两个来源正确检索信息。
然后,我们基于这些文档创建两个向量存储分片。
from langchain_community.vectorstores import FAISS
# 创建两个独立的FAISS向量存储
eng_vectorstore = FAISS.from_documents(eng_docs, embedding=embeddings)
mkt_vectorstore = FAISS.from_documents(mkt_docs, embedding=embeddings)
# 为每个分片创建一个检索器
eng_retriever = eng_vectorstore.as_retriever(search_kwargs={"k": 2})
mkt_retriever = mkt_vectorstore.as_retriever(search_kwargs={"k": 2})
print(f"Knowledge Base shards created: Engineering KB ({len(eng_docs)} docs), Marketing KB ({len(mkt_docs)} docs).")
现在,我们有了两个分片 eng_retriever 和 mkt_retriever,即一个分布式知识库,每个检索器只在其专属的小型索引上运行。
接下来构建分片式RAG系统的核心——一个 LangGraph 节点,用于将查询分散到两个分片并收集结果。
from typing import TypedDict, List
from concurrent.futures import ThreadPoolExecutor
import time
class ShardedRAGState(TypedDict):
question: str
retrieved_docs: List[Document]
final_answer: str
def parallel_retrieval_node(state: ShardedRAGState):
"""该模式的核心:将查询并行分散到所有分片并收集结果"""
print("--- [Meta-Retriever] Scattering query to Engineering and Marketing shards in parallel... ---")
# 用 ThreadPoolExecutor 并发运行两个检索调用
with ThreadPoolExecutor(max_workers=2) as executor:
# 创建一个简单的助手,为每个分片搜索添加模拟延迟
# 这模拟了现实世界中搜索一个较小索引所花费的时间
def p_retrieval(retriever):
time.sleep(0.5)
return retriever.invoke(state['question'])
# 将两个检索任务提交给执行器
futures = [executor.submit(p_retrieval, retriever) for retriever in [eng_retriever, mkt_retriever]]
all_docs = []
for future in futures:
all_docs.extend(future.result())
# “收集”步骤:合并并去重所有分片的结果
# 在真实系统中,这里会有一个更复杂的重排序步骤
unique_docs = list({doc.page_content: doc for doc in all_docs}.values())
print(f"--- [Meta-Retriever] Gathered {len(unique_docs)} unique documents from 2 shards. ---")
return {"retrieved_docs": unique_docs}
# 用生成节点组装完整的图
from langgraph.graph import StateGraph, END
workflow = StateGraph(ShardedRAGState)
workflow.add_node("parallel_retrieval", parallel_retrieval_node)
workflow.add_node("generate_answer", generation_node)
workflow.set_entry_point("parallel_retrieval")
workflow.add_edge("parallel_retrieval", "generate_answer")
workflow.add_edge("generate_answer", END)
sharded_rag_app = workflow.compile()
分散操作由 ThreadPoolExecutor 执行,它将相同的查询同时发送给 eng_retriever 和 mkt_retriever。在收集步骤中,我们从 futures 中汇集结果并进行去重,确保从分布式知识库中获得全面且统一的内容。
为了进行最终的对比分析,我们针对一个需要两个分片信息才能完整回答的查询,分别运行模拟高延迟的单体RAG和分片RAG。
# 查询包含强大的市场关键字(‘game-changer‘)和一个特定技术问题(’API status endpoint’)
user_query = "I heard the new QuantumLeap V3 is a 'game-changer for creative professionals'. Can you tell me more about it, and is there an API endpoint to check its status?"
# --- 执行单体 RAG ---
print("--- [MONOLITHIC RAG] Starting run... ---")
start_time = time.time()
monolithic_answer = monolithic_rag_chain.invoke(user_query)
monolithic_time = time.time() - start_time
# --- 执行分片 RAG ---
print("\n--- [SHARDED RAG] Starting run... ---")
start_time = time.time()
inputs = {"question": user_query}
sharded_result = sharded_rag_app.invoke(inputs)
sharded_time = time.time() - start_time
# --- 最终分析 ---
print("\n" + "="*60)
print(" ACCURACY & RECALL ANALYSIS")
print("="*60 + "\n")
# ... (这里应有分析逻辑,例如打印检索到的文档详情) ...
print("\n" + "="*60)
print(" PERFORMANCE ANALYSIS")
print("="*60 + "\n")
print(f"Monolithic RAG Total Time: {monolithic_time:.2f} seconds")
print(f"Sharded RAG Total Time: {sharded_time:.2f} seconds\n")
latency_improvement = ((monolithic_time - sharded_time) / monolithic_time) * 100
print(f"Latency Improvement: {latency_improvement:.0f}%\n")
运行结果如下:
============================================================
ACCURACY & RECALL ANALYSIS
============================================================
**Monolithic System:** Retrieved 3 documents. While it found the two correct documents, it also retrieved an irrelevant document about the 'Aura Smart Ring'. The strong semantic similarity of 'empowers you to unlock your full potential' to 'game-changer for creative professionals' pulled in this unrelated document. This noise can degrade the quality of the final answer.
**Sharded System:** Retrieved 2 documents. The parallel search was more precise. The marketing shard found the press release, and the engineering shard found the technical specs. It correctly ignored all irrelevant documents from other product lines. This resulted in a cleaner, more focused context for the generator.
**Conclusion:** The sharded architecture improved retrieval precision by isolating knowledge domains. This prevents context pollution from irrelevant but semantically similar documents, leading to a more accurate and trustworthy final answer.
============================================================
PERFORMANCE ANALYSIS
============================================================
Monolithic RAG Total Time: 6.89 seconds
Sharded RAG Total Time: 4.95 seconds
Latency Improvement: 28%
最终分析揭示了分片与分散检索架构的两大核心优势:
- 检索精度提升:查询中的营销相关部分在营销分片中顺利解决,技术部分则精准匹配了工程分片。而面向所有内容的单体索引,则被语义相似但无关的其他产品营销文本所干扰,从而降低了上下文的整体质量。这种通过隔离知识领域来提升精度的方式,是构建高可用系统的重要策略。
- 性能显著改善:分片系统的运行速度提高了28%。这是因为并行查询是在更小、领域更专一的索引上执行的。这种设计具备良好的可扩展性:单体检索的延迟会随着语料库规模扩大而线性增加,而分片架构的延迟主要受最大分片大小的制约,总体可以保持稳定。
 发表于 2026-2-20 19:59:02
|
查看: 169|
回复: 0
发表于 2026-2-20 19:59:02
|
查看: 169|
回复: 0
