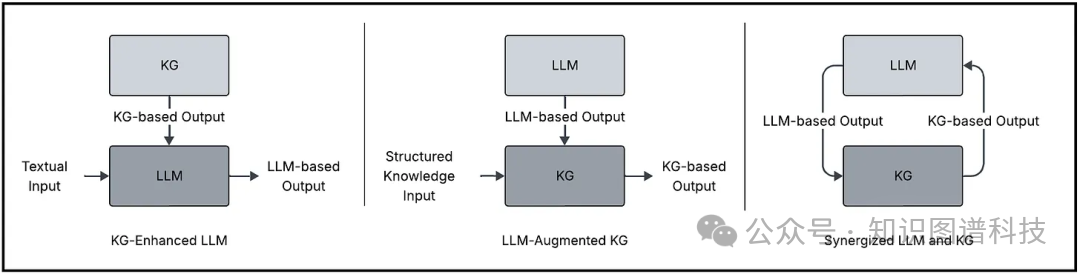
当前,人工智能正以前所未有的速度迭代,大语言模型(LLM)与知识图谱(KG)的融合,正在成为突破现有AI能力边界的关键技术。这种结合不仅为企业级应用带来了革命性变化,也为科研领域的知识发现与推理提供了全新的范式。本文将深入解析知识图谱如何从预训练、推理和可解释性三大路径增强大语言模型,并探讨其面临的技术挑战与应用前景。
一、大语言模型基础:从语言建模到智能生成
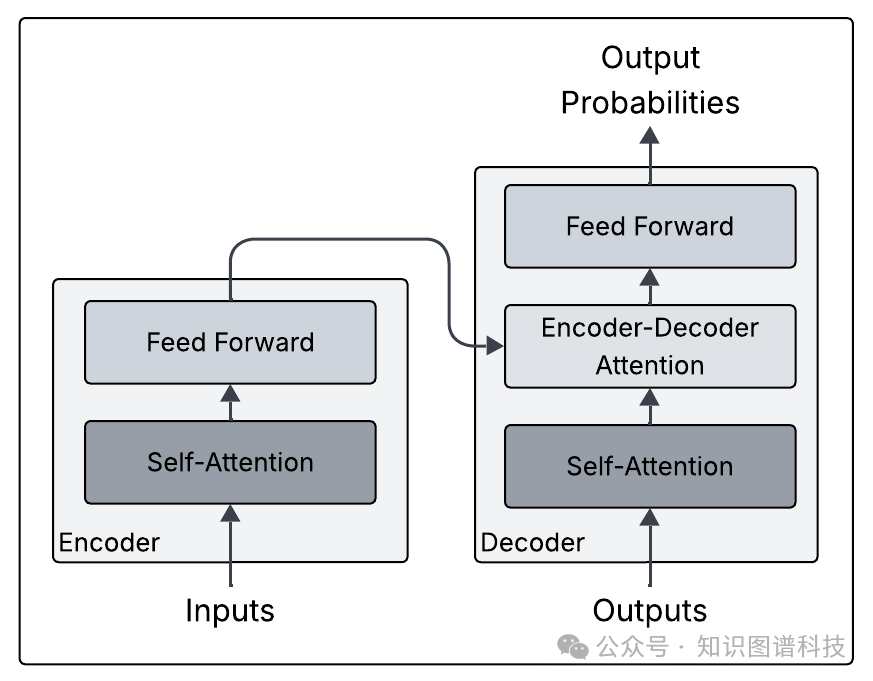
在探讨融合之前,我们先理解现代大语言模型的基础。当前主流的语言模型基于Transformer架构,主要分为三种类型:
编码器型语言模型
这类模型仅由编码器块组成,在大量文本上进行预训练以学习语言语义。著名的Google/BERT模型系列(如BERT(2018)和ALBERT(2020))就基于此架构。
解码器型语言模型
这类模型具有生成性质。OpenAI的GPT系列和Meta的LLaMA模型(2023)都基于解码器架构。它们通常在泛化到新任务时表现出色,无需针对特定任务进行微调。
编码器-解码器型语言模型
这种架构常用于序列到序列任务,如机器翻译和文本摘要。它允许模型在潜在空间编码输入序列,再解码为输出序列。Meta的BART(2020)和Google的Flan-T5(2022)是其中的代表。
大语言模型通常是包含海量参数(高达数千亿)的庞然大物,它们在海量数据上进行预训练,从而获得了通用语言理解和生成能力。一个引人注目的现象是“涌现能力”——随着模型规模增大而意外出现的能力,如复杂推理和多步骤问题解决,这些都不是在较小模型中初始存在的。
二、为何需要知识图谱?大语言模型的局限性
尽管大语言模型是强大的生成式AI工具,但其局限性也日益凸显:
- 事实性错误:模型有时会生成与事实不符的内容,这反映了训练数据中可能存在的噪音或错误。
- 信息滞后:模型的知识被“冻结”在训练数据截止的时间点,无法感知和整合实时发生的信息。
- 缺乏深度推理:对于需要复杂逻辑链条和多跳推理的任务,模型的表现可能不尽如人意。
- “黑箱”问题:模型的决策过程不透明,缺乏可解释性,这在医疗、金融等高风险领域是个重大障碍。
三、知识图谱增强LLM:融合架构与核心价值
知识图谱是信息的结构化表示,它将实体(如人物、概念)表示为节点,关系表示为边。这种显式的、结构化的知识,恰好可以弥补大语言模型从非结构化文本中学习知识的不足。
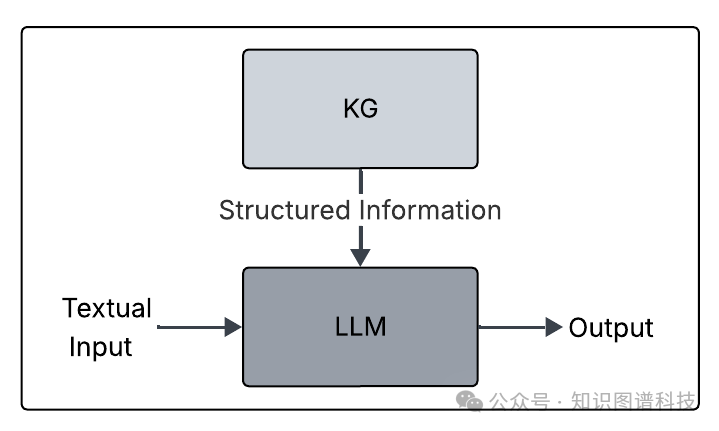
通过集成知识图谱,系统能够:
- 提升事实准确性:让模型的输出基于可靠的结构化知识,减少“幻觉”。
- 增强复杂推理:利用图谱中实体间的显式关系,进行多跳推理和逻辑判断。
- 实现知识实时更新:无需重新训练整个模型,通过更新图谱即可获取最新事实。
- 注入领域知识:整合特定行业的知识图谱,使模型具备深厚的领域洞察力。
四、知识图谱增强大语言模型的三大技术路径
研究通常将增强方法分为三个主要类别:预训练增强、推理增强和可解释性增强。
4.1 路径一:知识图谱增强的预训练
此方法在模型预训练阶段就将知识图谱信息“注入”模型参数中。
- 输入整合:例如,ERNIE 3.0将句子与相关的知识图谱三元组连接起来,作为一个序列输入模型。在训练时,随机掩码句子或三元组中的部分内容,迫使模型学会从文本和图谱信息中共同学习。
- 训练目标整合:除了修改输入,还可以设计特定的训练目标。ERNIE引入了“词-实体对齐”目标,训练模型预测文本中的词与知识图谱中实体之间的对应关系,从而加强语言与结构化知识之间的连接。
- 指令调优:对大语言模型进行微调,使其能更好地理解知识图谱的结构并遵循利用图谱进行推理的指令。例如,OntoPrompt方法在微调前,将图谱中的实体信息整合到提示上下文中,以增强模型在下游任务中的推理能力。
4.2 路径二:知识图谱增强的推理
这种方法在模型推理阶段动态利用知识图谱,使其能访问最新知识而无需重新训练。
- 检索增强生成:这是目前最流行的范式之一。经典的RAG框架从文档库中检索相关信息来辅助生成。而其进阶版Graph-RAG,则直接从知识图谱中检索相关的子图或片段,通过结构化提示整合给大语言模型,使其回答更具领域针对性和事实依据。
- 知识图谱提示:将知识图谱中的结构化知识以自然语言描述或三元组的形式,直接编织进给模型的提示中。例如,将“(爱因斯坦,出生于,乌尔姆)”这样的三元组放入提示,模型就能利用这个确切事实进行推理和生成。
4.3 路径三:知识图谱增强的可解释性
利用知识图谱来解释大语言模型的行为和内部知识。
- 推理过程显式化:例如,QA-GNN框架将大语言模型在问答过程中的每一步输出,都映射到一个知识图谱上进行推理。最终提取出的推理路径图,可以直观展示模型是如何一步步得出答案的,提升了透明度。
- 探测隐式知识:研究通过分析大语言模型的神经元激活,发现了与特定事实知识相关的“知识神经元”。这为了解模型内部存储了哪些知识提供了一种可解释的视角。
五、技术挑战与应对思路
尽管前景广阔,但实现高效的KG-LLM融合仍面临挑战:
- 表示鸿沟:大语言模型处理序列,知识图谱是图结构,如何高效对齐和转换是一大难题。
- 效率与扩展性:对大规模知识图谱进行实时查询可能带来高昂的计算成本和延迟。
- 知识图谱质量:图谱本身可能不完整、有噪声或领域受限,盲目使用会导致错误传播。
应对这些挑战,业界正在探索更高效的图神经网络算法、向量化检索与子图缓存技术,以及建立自动化的知识图谱质量评估与更新机制。
六、应用前景与展望
知识图谱与大语言模型的协同,代表了AI走向更可靠、更精准、更可解释的重要方向。其应用场景广泛:
- 智能客服与问答:提供事实准确、实时更新的专业领域问答。
- 企业知识管理:构建动态的企业知识大脑,辅助决策与创新。
- 金融风控与投研:整合多源异构数据,进行深度关联分析与风险推理。
- 生物医药与科研:加速科学文献挖掘与假设生成,辅助药物发现。
结语
知识图谱与大语言模型的融合,绝非简单的技术叠加,而是结构化知识与生成式智能的深度协同。从预训练注入、推理时检索到可解释性分析,三条技术路径为我们提供了丰富的工具箱。随着相关技术的不断成熟与工程化落地,这种融合必将催生出更强大、更可信的下一代AI系统,为各行各业的智能化转型提供核心驱动力。
本文聚焦于技术架构与核心路径的解析。对具体实现方案、开源工具以及行业案例感兴趣的开发者,可以持续关注云栈社区的技术动态,这里汇聚了最新的人工智能实战经验和深度探讨。 |  发表于 2026-2-24 10:23:09
|
查看: 256|
回复: 0
发表于 2026-2-24 10:23:09
|
查看: 256|
回复: 0
