是的,度小满的待遇跟我们熟知的互联网大厂薪资待遇区别不大,年薪也是能达到 30w~40w,诚意很足。
度小满 26 届校招研发岗的开奖信息不算多,从我目前搜集到的来看,主要是下面这些。
| 岗位 |
薪资结构 |
总包(不计入签字费) |
| 后端开发 |
24k × 15 |
36.0w |
| 后端开发 |
26k × 15 + 7w 签字费 |
39.0w |
| 后端开发 |
27k × 15 + 7w 签字费 |
40.5w |
| 后端开发 |
28k × 15 |
42.0w |
我大概猜了下档位:24k 是普通档,26k~27k 是 SP 档,28k 以上妥妥是 SSP 档了。
对了,顺便提一嘴度小满的情况 ,上面说的总包都没算签字费,度小满的签字费跟百度一样,给得相当大方。但这钱不是一次性到手的,得分两次发,每次发一半。关键是,要是签字费没拿完你就跳槽了,剩下的那一半就直接打水漂了。
所以签字费本质就是公司的「留才金」,目的就是绑着你多干一段时间,避免你拿了高薪就跑路,这一点大家选 offer 的时候可得想清楚。
说到这儿,想起去年 3 月份的事,当时有 26 届训练营的林友拿到了度小满的实习机会,这种机会必须冲啊!中大厂的实习经历,对后续校招的加成可不是一点半点。
事实也证明没选错,最后这位林友秋招直接拿下大厂 28k 的 offer,实习的价值一下就体现出来了。
其实找实习这事儿真没啥复杂技巧,核心就一个 「早」 字!
年后很快就会开启今年的暑期实习招聘,大家现在就得开始准备八股 + 算法,把项目也梳理好。赶在别人还没反应过来的时候,你就已经投起来了,竞争者少,公司要求相对也宽松,拿好实习的概率自然高很多,后续校招也能更顺。
社招也是一个道理!前两周有几个社招的林友问我,都要过年了,投大厂还有 HC 吗?
我让他们赶紧投,年前一样有机会的,结果两周过去,他们反馈说收到一堆面试邀约,既有大厂也有初创公司,一周要面好几家,流程推进得还特别快,基本两周就能面完大厂三轮技术面,因为公司也希望年前能把流程走完,所以速度上不会慢的。
到了今天,已经社招同学跟我报喜,说年前面试感觉格外简单,已经拿下好几个大厂 offer,还在接着面呢!
扯远了,咱们再拉回度小满。既然薪资都摸到了大厂门槛,面试难度自然也跟大厂看齐。
这次就来分享今年秋招度小满 Java 后端开发一面的面经,这一看就是重点拷打 Java 并发、MySQL 这两大内容,最后手撕算法也是标配,一点没落下,压力也是不小的。

度小满 Java一面
1. 线程池工作原理和参数介绍一下?
线程在正常执行或者异常中断时会被销毁,如果频繁的创建很多线程,不仅会消耗系统资源,还会降低系统的稳定性,一不小心把系统搞崩了。
使用线程池可以带来以下几个好处:
- 线程池内部的线程数是可控的,可以灵活的设置参数;
- 线程池内会保留部分线程,当提交新的任务可以直接运行;
- 方便内部线程资源的管理,调优和监控;
所以,线程池是为了减少频繁的创建线程和销毁线程带来的性能损耗,线程池的工作原理如下图:
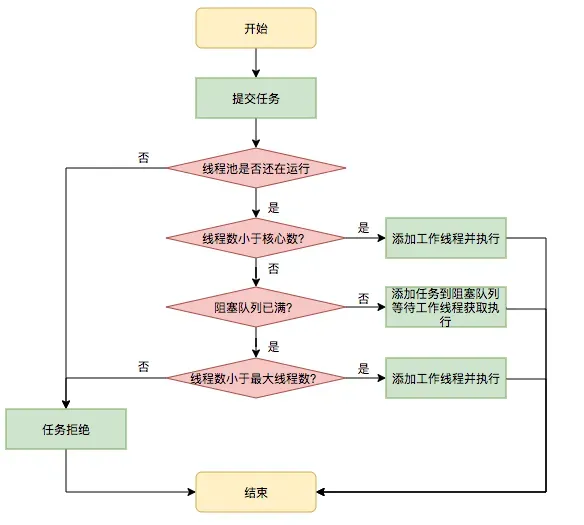
当用户提交了一个任务,接下来这个任务将如何执行都是由这个阶段决定的。首先,所有任务的调度都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。其执行过程如下:
- 首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
- 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
线程池七大核心参数如下所示:
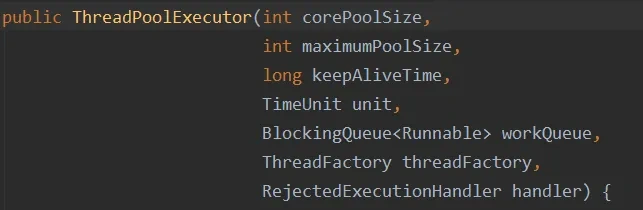
- corePoolSize:线程池核心线程数量,如果设置为5,线程池初始化后默认保持5个线程待命。默认情况下,线程池中线程的数量如果 <= corePoolSize,那么即使这些线程处于空闲状态,那也不会被销毁。
- maximumPoolSize:线程池允许的最大线程数。当任务队列已满,且当前线程数小于
maximumPoolSize 时,线程池会创建新的线程来处理任务,直至线程数达到 maximumPoolSize。
- keepAliveTime:当线程池中线程的数量大于corePoolSize,并且某个线程的空闲时间超过了keepAliveTime,那么这个线程就会被销毁。
- unit:就是keepAliveTime时间的单位。
- workQueue:工作队列。当没有空闲的线程执行新任务时,该任务就会被放入工作队列中,等待执行。
- threadFactory:用于创建线程的工厂。通过自定义线程工厂,你可以为线程设置名称、优先级等属性。
- handler:拒绝策略。当一个新任务交给线程池,如果此时线程池中有空闲的线程,就会直接执行,如果没有空闲的线程,就会将该任务加入到阻塞队列中,如果阻塞队列满了,就会创建一个新线程,从阻塞队列头部取出一个任务来执行,并将新任务加入到阻塞队列末尾。如果当前线程池中线程的数量等于maximumPoolSize,就不会创建新线程,就会去执行拒绝策略
2. synchronized和ReentrantLock的区别是什么?
synchronized 和 ReentrantLock 都是 Java 中提供的可重入锁:
- 用法不同:synchronized 可用来修饰普通方法、静态方法和代码块,而 ReentrantLock 只能用在代码块上。
- 获取锁和释放锁方式不同:synchronized 会自动加锁和释放锁,当进入 synchronized 修饰的代码块之后会自动加锁,当离开 synchronized 的代码段之后会自动释放锁。而 ReentrantLock 需要手动加锁和释放锁
- 锁类型不同:synchronized 属于非公平锁,而 ReentrantLock 既可以是公平锁也可以是非公平锁。
- 响应中断不同:ReentrantLock 可以响应中断,解决死锁的问题,而 synchronized 不能响应中断。
- 底层实现不同:synchronized 是 JVM 层面通过监视器实现的,而 ReentrantLock 是基于 AQS 实现的。
3. 除了ReentrantLock,还了解哪些实现Lock的锁?
首先是ReentrantReadWriteLock,它其实提供了两把锁,一把读锁一把写锁。读锁是共享的,多个线程可以同时持有,而写锁是独占的。这种设计特别适合读多写少的场景,能显著提升并发性能。
然后是StampedLock,这是Java 8引入的,可以理解为ReadWriteLock的升级版。它提供了三种模式:写锁、悲观读锁和乐观读。特别是乐观读这个特性很有意思,它不加锁就能读取,然后通过validate方法验证数据有没有被修改,如果没被修改就直接返回,这样在读多写少的场景下性能会更好。
还有就是各种Condition对象,虽然它不直接实现Lock接口,但它是配合Lock使用的,可以实现更灵活的线程间通信,比synchronized的wait和notify功能更强大。
另外在并发包里还有一些特殊用途的同步工具,比如Semaphore信号量、CountDownLatch倒计时门栓这些,虽然它们不是严格意义上的Lock实现,但都是基于AQS框架实现的同步器,在实际开发中经常会用到。
4. 介绍AQS 原理
AQS全称是AbstractQueuedSynchronizer,是Java并发包的核心基础框架。
它的核心原理其实就是两个东西,一个是state状态变量,一个是CLH队列。state是用volatile修饰的int变量,用来表示同步状态,比如在ReentrantLock里它就代表锁的持有次数。AQS通过CAS操作来修改这个state,保证原子性。
然后就是CLH队列,这是一个双向链表结构的等待队列。当线程获取锁失败时,会被封装成一个Node节点加入到这个队列的尾部,然后进入等待状态。队列的头节点就是当前持有锁的线程。
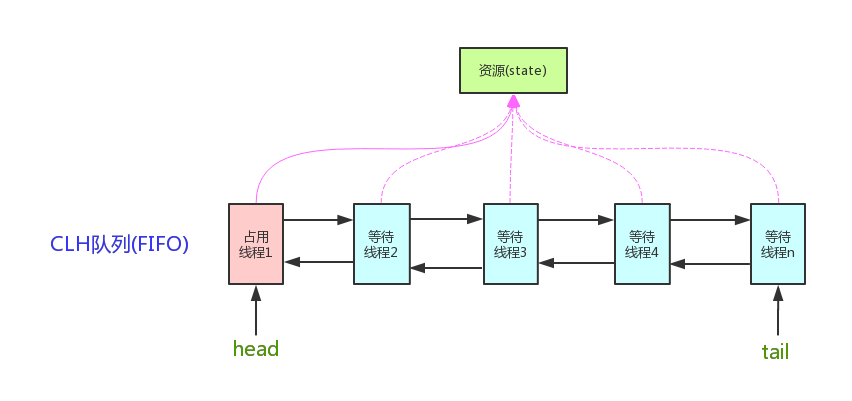
整个工作流程是这样的:线程先尝试CAS修改state来获取锁,如果成功就直接执行,如果失败就把自己包装成Node加入队列尾部并阻塞。当持有锁的线程释放锁时,会唤醒队列中的下一个节点,被唤醒的线程再次尝试获取锁。
AQS提供了独占模式和共享模式两种。独占模式就像ReentrantLock,同一时间只能有一个线程持有锁;共享模式就像Semaphore,可以允许多个线程同时访问。子类只需要实现tryAcquire、tryRelease这些方法,定义获取和释放资源的逻辑就行了,队列管理和线程阻塞唤醒这些复杂操作AQS都帮我们处理好了。
5. 介绍CAS 原理
CAS全称是Compare And Swap,比较并交换,它是一种乐观锁的实现方式。
它的原理其实很简单,就是包含三个操作数:内存位置V、预期原值A和新值B。执行CAS操作时,会先比较内存位置V的值是不是等于预期值A,如果相等就把它更新为新值B,如果不相等就说明已经被其他线程修改过了,那就不做任何操作直接返回失败。这整个比较和交换的过程是原子性的,由CPU指令来保证。
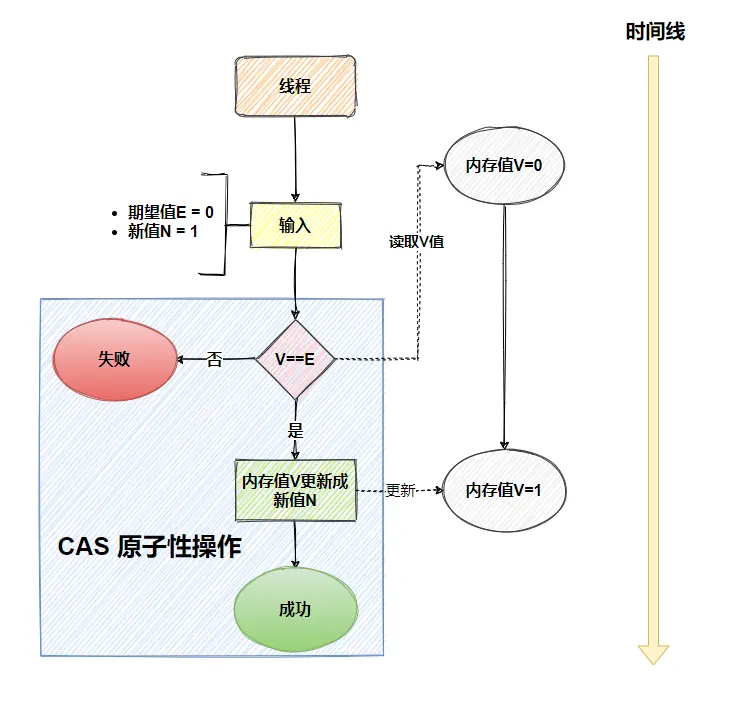
在Java里面,CAS主要是通过Unsafe类来实现的,Unsafe类会调用底层的CPU原语指令,比如x86架构下的cmpxchg指令。像AtomicInteger这些原子类,底层就是用CAS来实现的。
6. CAS 会有什么问题?怎么解决解决?
CAS主要有三个问题。
- 第一个是ABA问题。比如说一个值原本是A,线程1读取后准备更新,这时候线程2把它改成B又改回A,线程1再执行CAS时发现值还是A就以为没变过,实际上中间已经被修改过了。解决办法就是加版本号,Java提供了AtomicStampedReference类,它不仅比较值,还会比较版本号,只有值和版本号都匹配才会更新成功。
- 第二个问题是自旋时间过长。如果竞争特别激烈,CAS会一直失败然后不断重试,这样会空耗CPU资源。解决方案有两个,一个是设置自旋次数的上限,超过就放弃;另一个是在高并发场景下改用传统的锁机制,比如synchronized或者ReentrantLock,让线程阻塞等待反而更合适。
- 第三个是只能保证单个变量的原子性。如果要对多个变量进行原子操作,CAS就做不到了。这种情况可以把多个变量封装成一个对象,然后用AtomicReference来操作整个对象,或者直接用锁来保证多个变量操作的原子性。
7. SQL优化有什么方式?
- 分析查询语句:使用EXPLAIN命令分析SQL执行计划,找出慢查询的原因,比如是否使用了全表扫描,是否存在索引未被利用的情况等,并根据相应情况对索引进行适当修改。
- 创建或优化索引:根据查询条件创建合适的索引,特别是经常用于WHERE子句的字段、Orderby 排序的字段、Join 连表查询的字典、 group by的字段,并且如果查询中经常涉及多个字段,考虑创建联合索引,使用联合索引要符合最左匹配原则,不然会索引失效
- 避免索引失效:比如不要用左模糊匹配、函数计算、表达式计算等等。
- 查询优化:避免使用SELECT *,只查询真正需要的列;使用覆盖索引,即索引包含所有查询的字段;联表查询最好要以小表驱动大表,并且被驱动表的字段要有索引,当然最好通过冗余字段的设计,避免联表查询。
- 分页优化:针对 limit n,y 深分页的查询优化,可以把Limit查询转换成某个位置的查询:select * from tb_sku where id>20000 limit 10,该方案适用于主键自增的表。
- 读写分离: 搭建主从架构, 利用数据库的读写分离,Web服务器在写数据的时候,访问主数据库(master),主数据库通过主从复制将数据更新同步到从数据库(slave),这样当Web服务器读数据的时候,就可以通过从数据库获得数据。这一方案使得在大量读操作的Web应用可以轻松地读取数据,而主数据库也只会承受少量的写入操作,还可以实现数据热备份,可谓是一举两得。
- 优化数据库表:如果单表的数据超过了千万级别,考虑是否需要将大表拆分为小表,减轻单个表的查询压力。也可以将字段多的表分解成多个表,有些字段使用频率高,有些低,数据量大时,会由于使用频率低的存在而变慢,可以考虑分开。
- 使用缓存技术:引入缓存层,如Redis,存储热点数据和频繁查询的结果,但是要考虑缓存一致性的问题,对于读请求会选择旁路缓存策略,对于写请求会选择先更新 db,再删除缓存的策略。
8. 分库分表是什么?垂直分表和水平分表区别是什么?
分库分表是应对数据量大、并发高的一种数据库扩展方案。当单表数据量达到几百万甚至上千万,或者单库的连接数、IO压力太大时,就需要通过分库分表来解决性能瓶颈。
- 分库就是把数据分散到多个数据库实例上,可以分摊连接数和IO压力。
- 分表就是把一个大表拆分成多个小表,降低单表的数据量,提升查询效率。
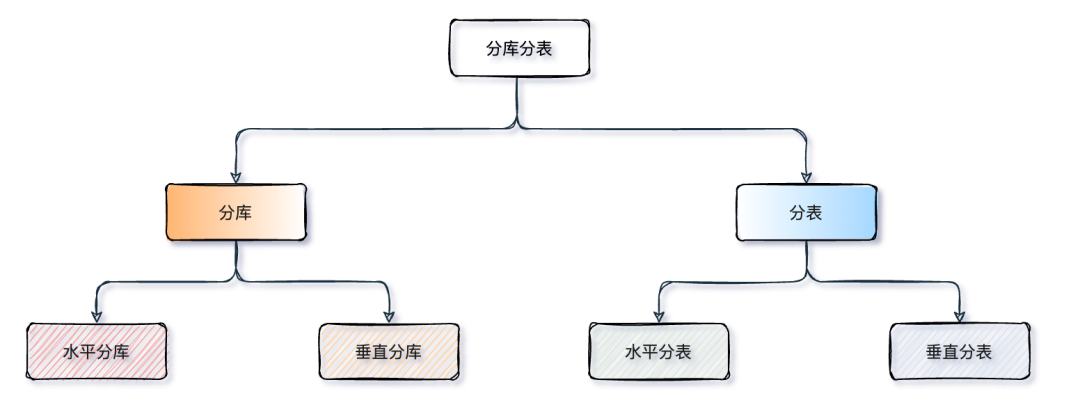
垂直分表和水平分表是两种不同的拆分方式。垂直分表是按照字段来拆,把一个表里不常用的字段或者大字段拆到另一个表里。比如用户表,可以把基本信息像用户名、手机号放一个表,把不常用的详细信息像个人简介、头像这些大字段放另一个表,通过用户ID关联。这样做的好处是减少IO,因为查询基本信息时不用加载那些大字段。
水平分表是按照数据行来拆,表结构完全一样,只是数据分散存储。比如订单表数据太多,可以按用户ID取模分成多个表,或者按时间维度分表,每个月一张表。水平分表主要解决的是单表数据量过大的问题,可以提升查询和写入性能。
一般来说,数据量大就用水平分表,字段多或有大字段就考虑垂直分表,实际项目中也可能两种方式结合使用。
9. 水平分表之后,如何避免分表查询聚合问题?
水平分表后确实会带来跨表查询聚合的问题,这个需要从设计和技术两方面来解决。
首先在设计上,最重要的是选好分片键。分片键要尽量贴合业务查询场景,让大部分查询都能落到单表上。比如订单系统按用户ID分片,那查某个用户的订单就只查一张表,不需要跨表聚合。所以说避免聚合问题的核心其实是在分表时就规划好,让查询路由到单表。
如果确实避免不了跨表查询,就需要在应用层做聚合。比如查总订单数或者做排序分页,就得先从各个分表查出数据,然后在应用层进行合并计算。像分页的话,要从每个分表都取出前N条数据,然后在内存里排序后再截取最终结果。不过这种方式会增加应用层的复杂度,性能也会受影响。
另外一个思路是引入中间件,像ShardingSphere这种分库分表中间件,它会帮你处理SQL的解析、路由和结果归并,对业务代码的侵入性比较小。
还有就是对于一些复杂的统计分析需求,可以考虑用ES或者数据仓库来做,把数据同步过去专门做查询分析,不要直接在分表上做复杂聚合,这样能保证业务库的性能
10. 事务隔离级别有哪些?
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化(serializable);会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
11. MVCC机制原理是什么?
MVCC允许多个事务同时读取同一行数据,而不会彼此阻塞,每个事务看到的数据版本是该事务开始时的数据版本。这意味着,如果其他事务在此期间修改了数据,正在运行的事务仍然看到的是它开始时的数据状态,从而实现了非阻塞读操作。
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,大家可以把 Read View 理解成一个数据快照,就像相机拍照那样,定格某一时刻的风景。
- 「读提交」隔离级别是在「每个select语句执行前」都会重新生成一个 Read View;
- 「可重复读」隔离级别是执行第一条select时,生成一个 Read View,然后整个事务期间都在用这个 Read View。
Read View 有四个重要的字段:
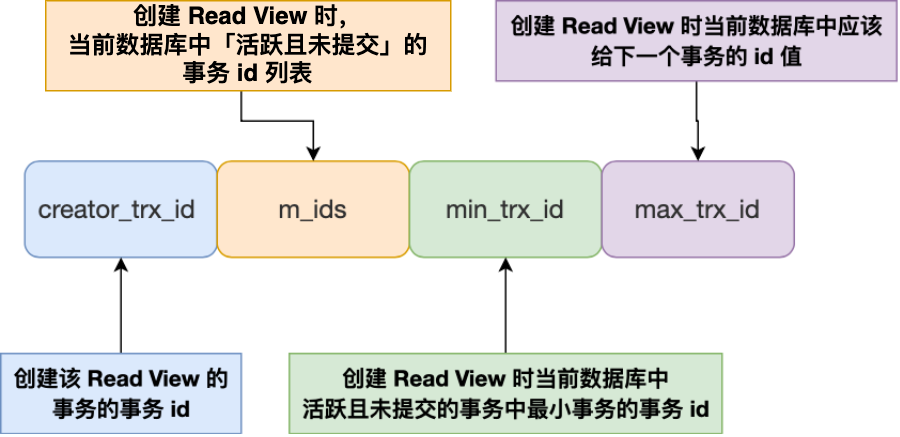
- m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id。
对于使用 InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列:
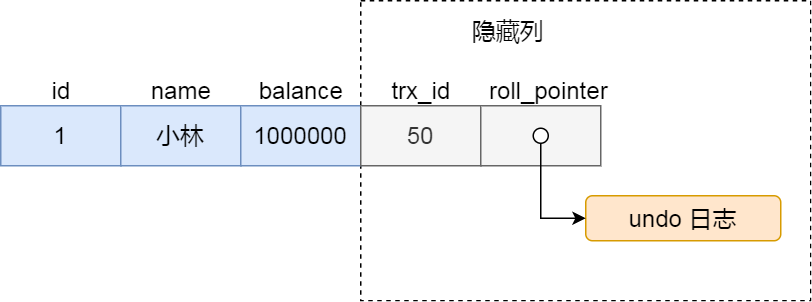
- trx_id,当一个事务对某条聚簇索引记录进行改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列里;
- roll_pointer,每次对某条聚簇索引记录进行改动时,都会把旧版本的记录写入到 undo 日志中,然后这个隐藏列是个指针,指向每一个旧版本记录,于是就可以通过它找到修改前的记录。
在创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
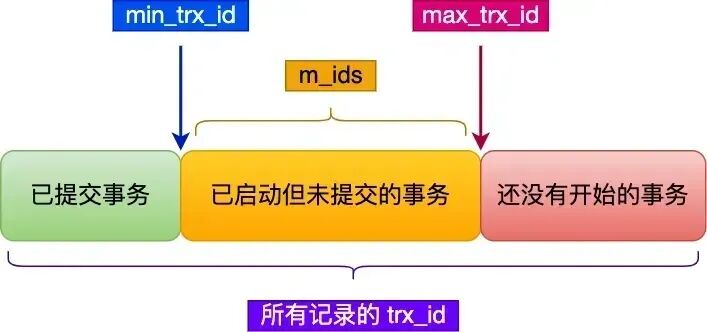
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
12. 手撕算法
无论是准备冲击像度小满这样高薪的大厂,还是为其他面试求职机会做准备,透彻理解这些高频的Java并发与数据库原理都至关重要。希望这份结合了薪资调研和真题解析的内容,能对大家有所启发。如果你对更多技术话题或面试经验感兴趣,也欢迎来我们云栈社区交流探讨。
 发表于 2026-2-25 02:20:28
|
查看: 252|
回复: 0
发表于 2026-2-25 02:20:28
|
查看: 252|
回复: 0
