不知道大家有没有听过,在Linux文本处理领域,有号称“三剑客”的三个命令,它们分别是 grep、sed、awk。
这三者在功能上分工明确,共同构成了强大的命令行文本处理工具链:
- grep:查找文本内容,支持正则表达式匹配,是文本检索的主要工具。
- sed:编辑文本,可以进行替换、删除、插入等操作,主要用于修改文本内容。
- awk:分析、计算、格式化文本,核心优势在于按列处理数据。
很多人初次接触 awk 时可能会望而却步,觉得它语法有些奇怪,逻辑似乎很复杂。其实恰恰相反,只要你抓住它的核心思想,awk 会变得 非常直观、极其强大,往往一行命令就能抵上其他工具好几行的功夫。
本文将从最基础的运行原理讲起,为你梳理 awk 最核心、最实用的知识,帮助你在运维/DevOps/SRE的日常工作中得心应手。
一、awk 究竟是什么?
简单来说,awk 是一种专门为处理文本数据而设计的脚本语言。它得名于其三位创始人姓氏的首字母。它的主要特点是支持变量、条件判断、循环和数组,天生就非常适合处理结构化的表格数据。
用一句话总结它的能力:awk = 按行读取 + 按列提取 + 数值计算/统计 + 格式化输出。
二、awk 的基础结构
awk 命令的基本语法格式如下:
awk [选项] ‘条件 { 执行动作 }’ 文件名
重要提示:命令中的模式与动作部分需要用单引号 ‘ ’ 包裹。
- 选项:最常用的是
-F,用于指定字段分隔符。
- 条件:用于筛选需要处理的行。
- 动作:对符合条件的行要执行的操作,最常见的就是
print。
- 文件名:需要处理的文本文件。
awk 的基本工作流程非常清晰:
- 读入一行文本。
- 根据指定的分隔符,将这一行切割成若干个字段。
- 判断该行是否满足设定的“条件”。
- 如果满足,则执行大括号
{ } 里定义的“动作”。
- 处理完毕后,继续读取下一行,直到文件结束。
三、核心机制:字段引用
awk 最强大的特性之一,就是能够轻松地按列提取数据。默认情况下,它使用空格或制表符(Tab)作为字段分隔符。
几个最关键的字段引用符号:
$0 → 代表整行内容。$1 → 代表第1列。$2 → 代表第2列。$NF → 代表最后一列(NF 是一个内置变量,表示当前行的字段总数)。NF → 当前行有多少列。NR → 当前行的行号。
来看一个最简单的例子:
awk ‘{print $1,$2}’ 12.txt
这条命令的意思是:打印文件 12.txt 中每一行的第1列和第2列。
四、指定分隔符:-F 参数
现实中的数据文件并不总是用空格分隔。例如,CSV文件用逗号,系统配置文件 /etc/passwd 用冒号。这时,就必须使用 -F 选项来明确指定分隔符。
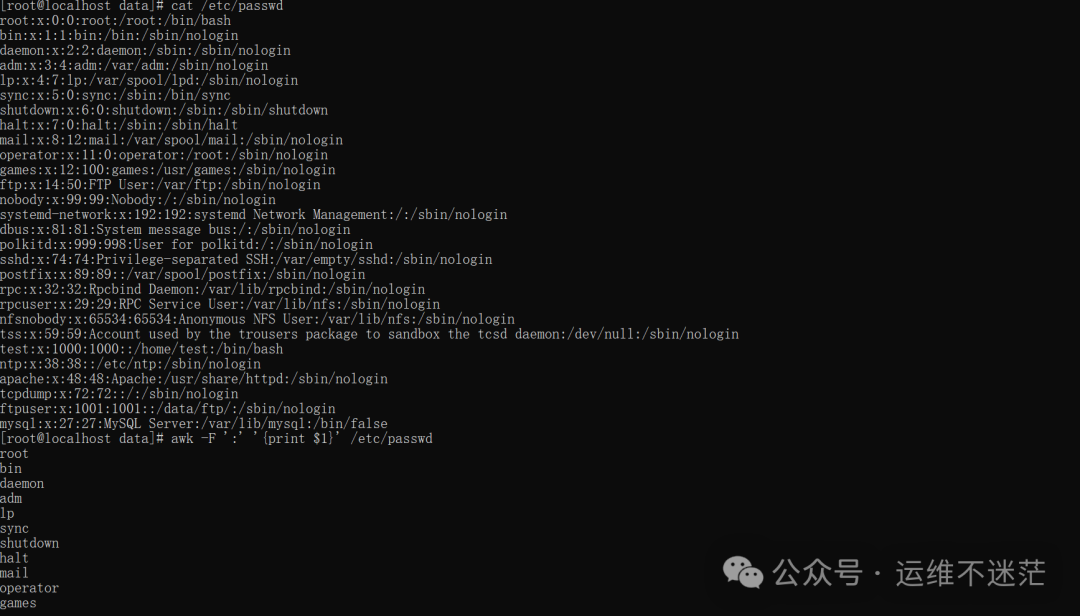
示例1:提取系统用户名
/etc/passwd 文件以冒号 : 分隔各字段,第一列是用户名。
awk -F ‘:’ ‘{print $1}’ /etc/passwd
示例2:读取 CSV 文件
假设 222.csv 文件以逗号分隔。
awk -F ‘,’ ‘{print $1,$2}’ 222.csv

示例3:解析配置文件
对于用等号 = 赋值的配置文件,我们可以这样提取所有配置项的名称(键)。
awk -F ‘=’ ‘{print $1}’ vsftpd.conf
五、最常用的内置变量
熟练掌握以下几个内置变量,你就能应对80%的 awk 使用场景。
| 变量 |
含义 |
$0 |
整行内容 |
$n |
第 n 列 |
NF |
当前行的字段总数 |
$NF |
最后一个字段 |
NR |
当前处理的行号 |
FS |
输入字段分隔符(作用同 -F) |
OFS |
输出字段分隔符 |
BEGIN |
在处理任何行之前执行一次 |
END |
在处理完所有行之后执行一次 |
实用示例:
打印行号及第一列(两者紧挨着):
awk ‘{print NR $1}’ 123.txt

仅打印最后一列:
awk ‘{print $NF}’ 123.txt

六、条件筛选:精准处理目标行
awk 支持强大的行级过滤功能,让你可以只处理感兴趣的数据。
1. 按数值比较
awk ‘$1 > 2 {print $1,$2}’ data.txt
这条命令表示:只处理第一列数值大于2的行,并打印这些行的前两列。

2. 按模式(字符串)匹配
查找包含 “error” 关键字的行:
awk ‘/error/ {print}’ messages
查找不包含 “error” 关键字的行:
awk ‘!/error/ {print}’ messages
3. 多条件组合
awk 支持使用逻辑运算符组合多个条件。
==, !=, >, <, >=, <=&& (与), || (或)
例如,筛选第二列为”20″且第三列时间晚于”11:00:00″的行:
awk ‘$2==“20” && $3>“11:00:00” {print}’ secure
七、BEGIN 和 END 模式
这两个模式非常有用,它们允许你在处理数据“之前”和“之后”执行操作。
BEGIN:在处理任何输入行之前执行一次。常用于打印表头、初始化变量等。
例如,在分析认证日志前,先打印一个漂亮的标题:
awk ‘BEGIN{print “时间\t\t\tIP地址”} /Accepted password/ {print $1, $2, $3 “\t” $11}’ /var/log/secure

END:在处理完所有输入行之后执行一次。最适合用于最终统计,如求和、求平均值、输出总结信息。
例如,计算一个文件中第二列的总和:
awk ‘{sum += $2} END {print sum}’ 12.txt

八、基础实战场景
掌握了以上核心概念,我们来看几个在网络/系统管理中极其常见的实战例子。
1. 查看系统当前占用 CPU 最高的 10 个进程
ps -aux | awk ‘{print $3,$11}’ | sort -nr | head -10

2. 查看内存占用最高的 10 个进程
ps -aux | awk ‘{print $4,$11}’ | sort -nr | head -10

3. 提取登录日志中所有以 192.168 开头的 IP 地址
awk ‘{print $11}’ /var/log/secure | grep 192.168

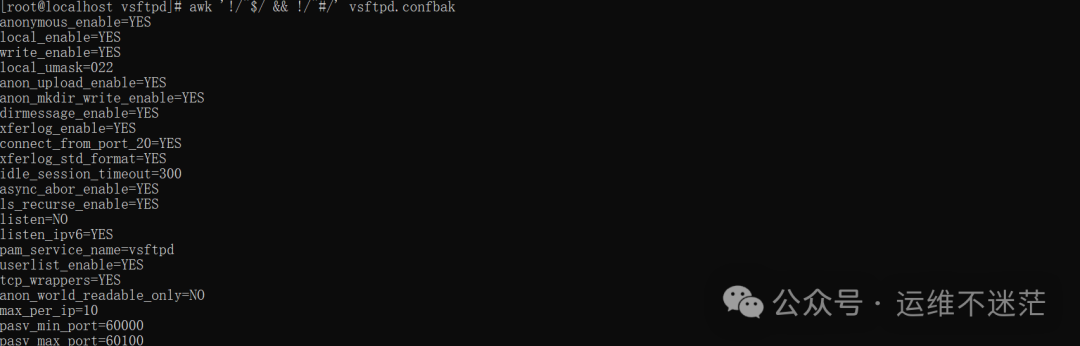
4. 清理配置文件:去除空行和注释行
awk ‘!/^$/ && !/^#/’ vsftpd.conf.bak
这条命令会打印出所有非空行(! /^$/)且非注释行(! /^#/)的内容,常用于查看配置文件的“干货”。
九、总结
awk 的语法初看可能有些独特,但一旦理解了它“逐行处理、按列切割”的核心思想,你就会发现它是一门逻辑清晰、功能强大的高效工具。通过灵活运用字段引用、分隔符指定、条件筛选和内置变量,你可以轻松解决日常工作中大量的文本提取、数据统计和格式化输出任务。
希望这篇入门指南能帮助你打开 awk 世界的大门。如果你在实践过程中有任何心得或疑问,欢迎在云栈社区与大家一起交流探讨。记住,最好的学习方式就是动手实践,下次遇到需要处理文本数据时,不妨先想想:awk 能不能帮我搞定?
 发表于 2026-2-25 02:47:11
|
查看: 204|
回复: 0
发表于 2026-2-25 02:47:11
|
查看: 204|
回复: 0
