项目资源链接:
https://github.com/VincentLien/HyperRAG.git
https://arxiv.org/pdf/2602.14470
HyperRAG: Reasoning N-ary Facts over Hypergraphs for Retrieval Augmented Generation
一、当二元知识图谱遇到瓶颈
当前 GraphRAG 的主流范式建立在二元知识图谱(Binary KG)之上——将知识拆解为(头实体-关系-尾实体)的三元组。这种简化虽便于存储,却带来两个结构性缺陷:
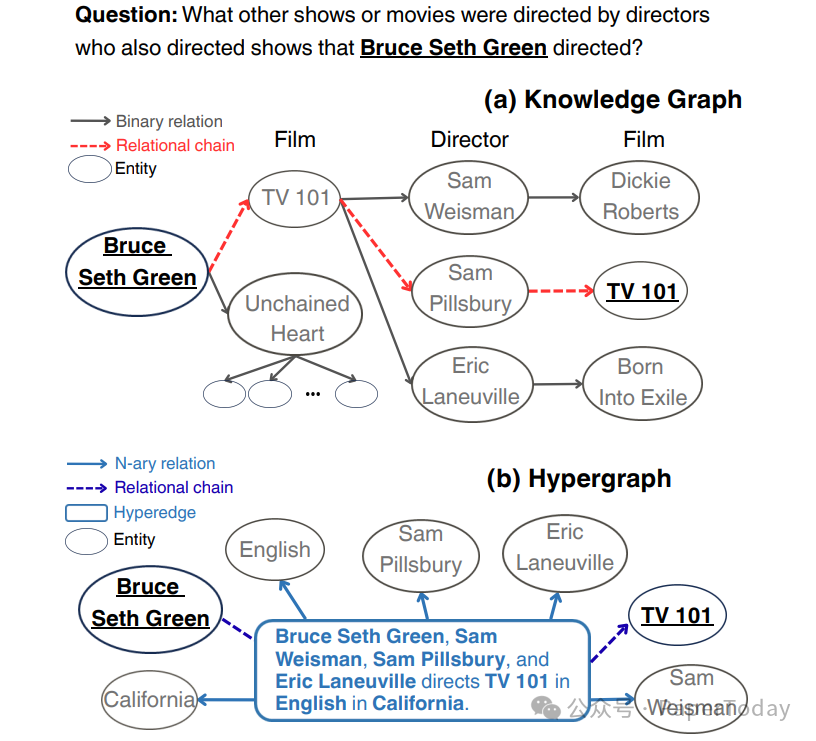
传统KG需要3跳推理,而超图通过单条n元超边即可完成推理。
语义碎片化(Semantic Fragmentation):复杂的多实体交互被强行拆分为独立三元组,丢失了整体性的语义关联。例如,“导演A在地点B拍摄电影C”这一完整事实,在二元图谱中不得不被拆解为多个孤立的边,原始的上下文联系就此断裂。
路径爆炸(Path Explosion):为了重建完整的语义链,系统需要进行深度的多跳遍历。这不仅带来了巨大的计算开销,还很容易在推理路径上引入错误的传播和积累,最终影响答案的准确性。
二、HyperRAG的双引擎架构
那么,如何突破这个瓶颈呢?HyperRAG 提出了一个基于 n元超图(n-ary Hypergraph) 的检索框架。其核心创新在于,将超边(Hyperedge)作为基本的检索单元——一条超边可以同时绑定多个实体与它们的角色,从而天然地保留了高阶关系的完整性。
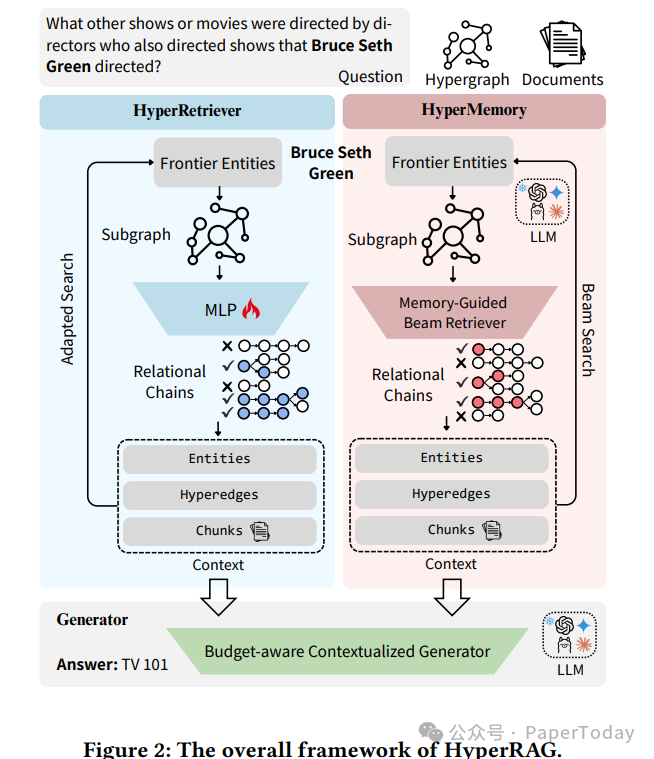
关键复杂度优势:原生超图检索的每结果开销为O(1)(所有参数共存于单条超边记录),而二元KG需O(n-k)次指针跳转(通过事件节点重构n元事实)。
整个框架包含两个互补的检索范式,共同构成了强大的推理引擎。
1. HyperRetriever:结构-语义融合检索
这个模块专注于从超图结构中高效、精准地提取信息。
- 方向距离编码(DDE):其思路扩展自 SubGraphRAG,并适配了 n 元超图结构。通过双向的特征传播机制,它能有效捕获实体之间的结构邻近性。
- 对比似然评分:系统会训练一个轻量级的 MLP 分类器。这个分类器能够融合查询、实体、超边的语义嵌入与结构编码,从而计算候选三元组的似然得分,判断其与问题的相关性。
- 自适应阈值搜索:检索策略并非一成不变。它会根据当前超图的密度动态调整扩展策略——在稀疏图中采取保守检索,在稠密图中进行深度探索,从而在检索覆盖率和答案精度之间取得最佳平衡。
2. HyperMemory:LLM记忆引导的束搜索
如果说 HyperRetriever 是“循规蹈矩”的专家,那么 HyperMemory 则更像一位“直觉敏锐”的助手。
- 它利用大语言模型(LLM)内部的参数化记忆,来动态评估超边与实体对于当前查询的相关性。
- 搜索过程采用束搜索(Beam Search),束宽设为3,搜索深度设为3。通过复合得分(超边得分 × 实体得分)来指导推理路径的扩展。
- 该模块还会进行实时的“证据充分性”检查,一旦判断当前信息足以回答问题,就会停止检索,有效避免了过度检索带来的效率损耗。
三、性能与效率的双重提升
理论上的优势需要实验数据来支撑。HyperRAG 在广泛的基准上进行了测试,覆盖了11个 WikiTopics 闭域数据集和3个开域多跳QA基准(包括 HotpotQA、MuSiQue、2WikiMultiHopQA)。
| 维度 |
核心结果 |
| 闭域性能 |
HyperRetriever 在 MRR 指标上平均提升 2.95%,在 Hits@10 指标上提升 1.23%,在11个测试领域中,有9个取得了最佳性能。 |
| 消融验证 |
将 n 元超图结构替换回传统的二元知识图谱后,MRR 指标下降了 2.3%(从36.45%降至34.15%),这有力地证明了高阶图结构对于复杂推理的必要性。 |
| 效率优势 |
在对比模型中,HyperRAG 实现了最短的检索时间和最高的 Hits@10 分数,达到了“低延迟、高精度”的理想状态。 |
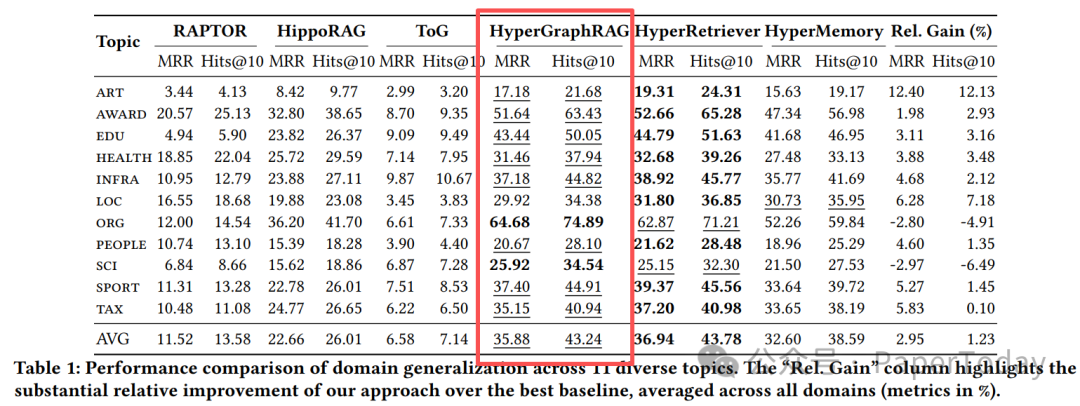
Table 1: 跨11个领域的域泛化性能对比
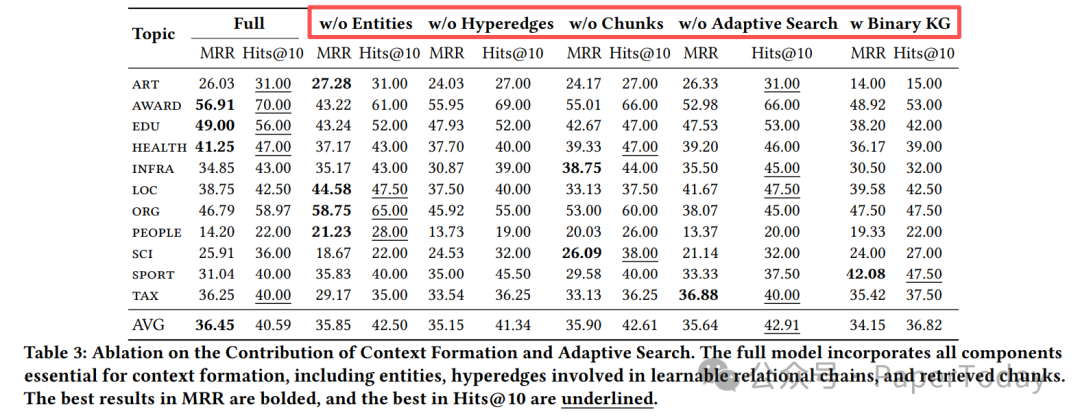
Table 3: 上下文构成与自适应搜索的消融实验
关键洞察:从消融实验中可以清晰地看到,超边(Hyperedges)是上下文构成中最核心的要素——移除超边导致的性能下降最为显著,而移除实体或文本块的影响相对较小。这直接验证了高阶拓扑结构对于实现精准推理的决定性作用。
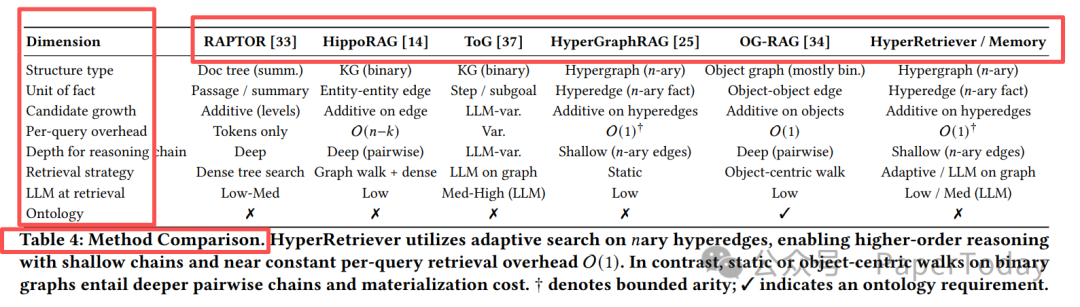
Table 4: 不同RAG方法在多维度上的对比。HyperRetriever 利用自适应搜索处理 n 元超边,实现了高阶推理与近乎恒定的单查询检索开销。
总结与展望
HyperRAG 的突破性在于,它重新定义了GraphRAG的基本检索单元——从二元边升级到了能够表达丰富语义的 n 元超边。这不仅从根源上解决了传统知识图谱面临的语义碎片化与路径爆炸问题,更通过精巧的自适应检索策略,在答案精度与计算效率之间取得了出色的平衡。
对于需要处理复杂多跳推理的知识密集型应用(如深度问答、事实核查、研究辅助等),HyperRAG 无疑提供了一个表达力更强、计算更高效的新范式。这项研究也启发我们,在处理复杂知识时,有时跳出传统的简化模型,回归并利用信息更丰富的原始结构,反而能开辟出更优的解决方案。对这类前沿的 RAG 技术与 开源实战 项目感兴趣的朋友,欢迎在 云栈社区 继续交流探讨。 |  发表于 2026-2-25 02:45:00
|
查看: 212|
回复: 0
发表于 2026-2-25 02:45:00
|
查看: 212|
回复: 0
