问题背景
在调试一个基于 RAGFlow 的应用时,发现 Elasticsearch(ES)的查询响应很慢,同时伴随一些关于缓存生命周期的错误日志。本文记录了从错误日志出发,一步步追踪和定位问题根源的过程,涉及对 RAGFlow 内部向量搜索、缓存设置等代码模块的分析。
日志分析与初步定位
首先,我们注意到以下错误频繁出现:
Fail set expire cache: config must be LifecycleConfig type
这个错误提示在为缓存设置过期规则时,传入的配置参数类型有误。为了定位问题,需要先确定发出此错误的具体代码位置。
第一步:追踪 ES 查询耗时
在查询接口中增加了日志,以观察 ES 查询构造与执行的耗时点。关键日志输出如下:

从日志可以看到,程序成功构建了一个包含布尔查询和向量搜索(knn)的复杂 ES 查询 DSL。查询中包含了针对用户问题“我家猫咪最近是在挠耳朵...”的关键词匹配和向量相似度检索。日志显示,在调用 search 方法后,收到了 500 错误。
第二步:深入查询执行逻辑
根据日志线索,追踪到执行搜索的核心代码段。这部分代码负责构建查询对象、应用过滤器,并决定是否加入向量搜索。
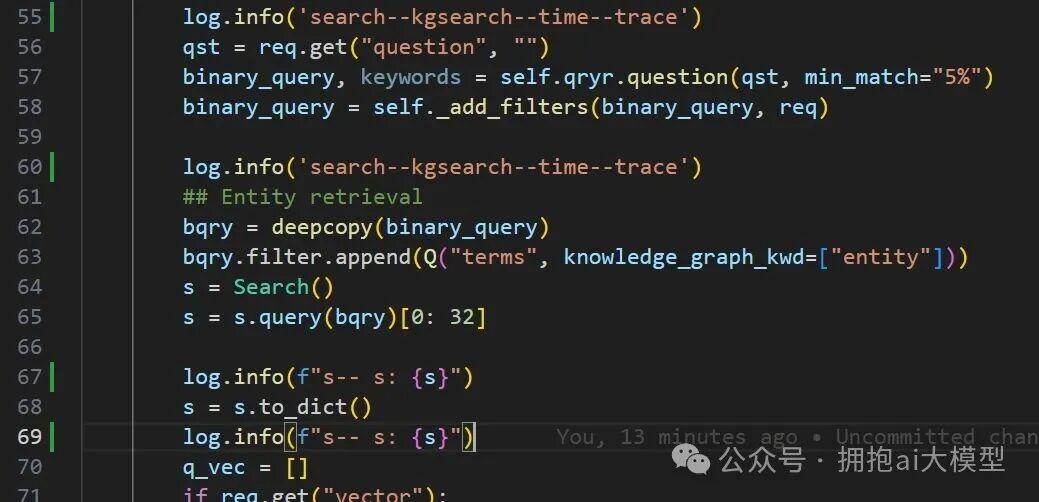
代码显示,在执行检索前,程序会检查请求中是否包含 vector 参数。如果包含,则会调用 _vector 方法来为查询添加向量搜索部分。我们的日志表明,请求中确实包含了该参数,因此逻辑会进入 _vector 方法。
第三步:聚焦 _vector 方法
_vector 方法负责将文本转换为向量,并构建 ES 的 KNN 查询参数。其简化版逻辑如下:
def _vector(self, txt, emb_mdl, sim=0.8, topk=10):
qv, c = emb_mdl.encode_queries(txt)
return {
"field": "q_%d_vec" % len(qv),
"k": topk,
"similarity": sim,
"num_candidates": topk * 2,
"query_vector": [float(v) for v in qv]
}
为了确认问题是否出在这里,我们尝试在代码中设置断点进行调试。
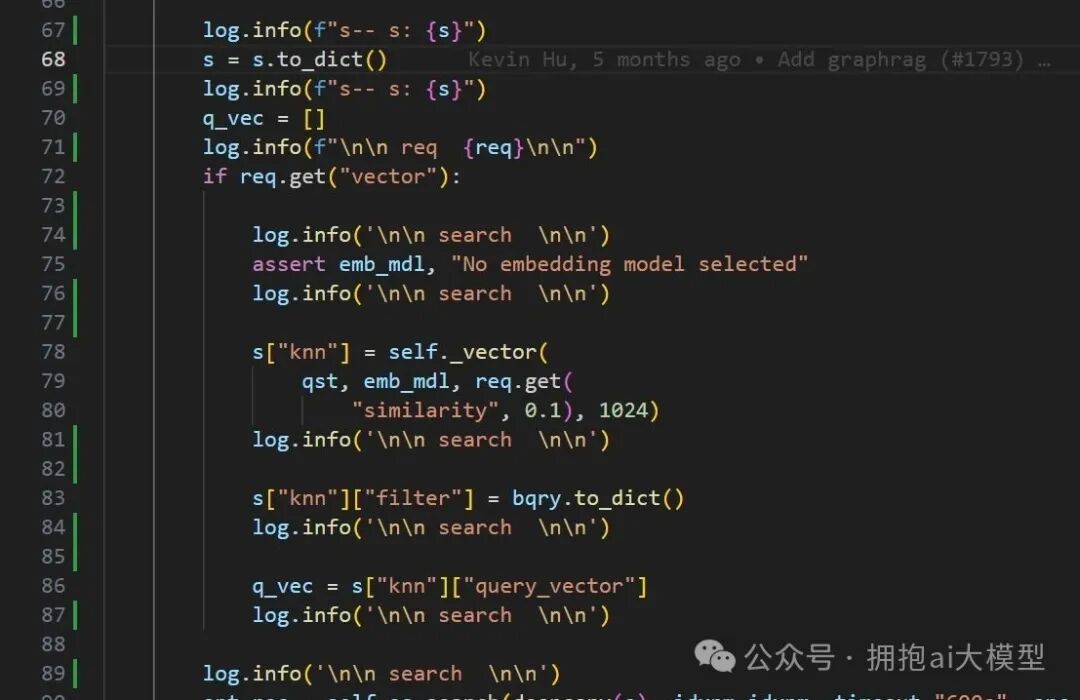
调试发现,程序确实进入了 _vector 方法,但在执行 emb_mdl.encode_queries(txt) 这行代码时似乎卡住或发生了未捕获的异常,导致后续日志没有输出,方法也没有正常返回。这直接使得外层的搜索请求因等待超时而失败。
错误根源排查与修复
尽管 _vector 方法疑似阻塞,但最初引起注意的仍然是关于“LifecycleConfig”的错误。为了系统性地解决问题,我们决定先解决这个明确的错误。
定位并修复缓存设置错误
最初的错误信息是:
Fail set expire cache: config must be LifecycleConfig type
通过在全项目代码中搜索错误日志中的关键词“Fail22”(一个自定义的错误日志标记),可以快速定位到抛出此异常的代码位置。
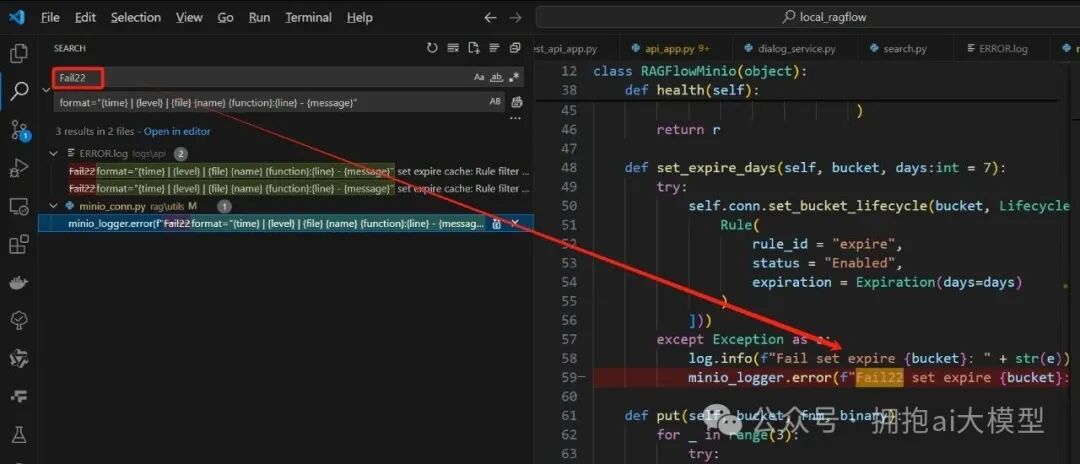
搜索结果显示,错误出自 minio_conn.py 文件中的 set_expire_days 方法。查看该方法代码:
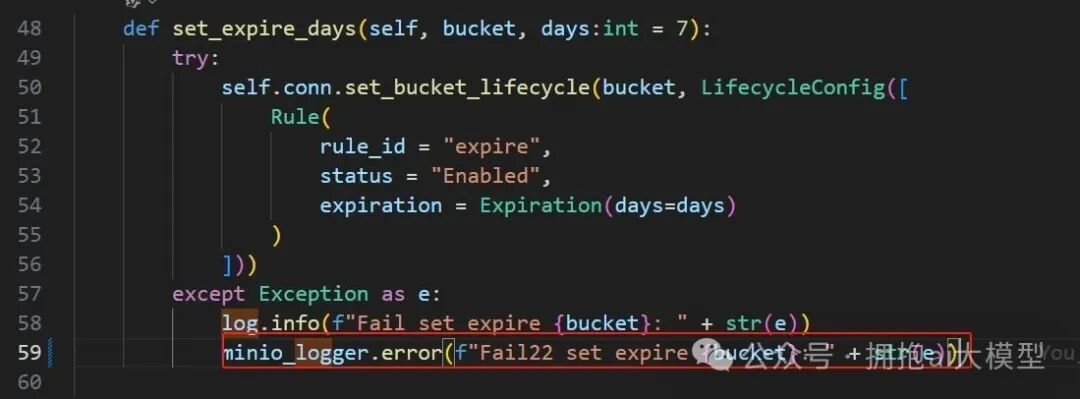
问题出现在为 MinIO(或 S3 兼容存储)设置生命周期规则时,Rule 对象缺少必需的 rule_filter 参数,导致创建的配置对象无效。最初的报错“config must be LifecycleConfig type”正是由此引发。
修复方案
根据存储服务 SDK 的要求,需要为生命周期规则提供一个过滤器(Filter),即使它是一个空过滤器。修改后的代码如下:
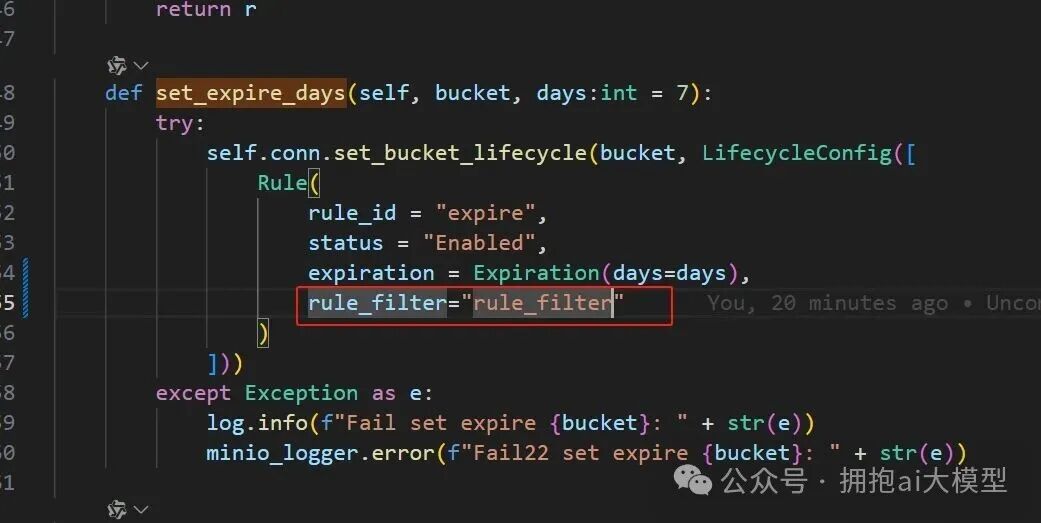
具体修改是添加了 rule_filter=Filter(prefix="") 参数:
def set_expire_days(self, bucket, days:int = 7):
try:
self.conn.set_bucket_lifecycle(bucket, LifecycleConfig([
Rule(
rule_id = "expire",
status = "Enabled",
expiration = Expiration(days=days),
rule_filter=Filter(prefix="")
)
]))
except Exception as e:
log.info(f"Fail set expire {bucket}: " + str(e))
minio_logger.error(f"Fail22 set expire {bucket}: " + str(e))
此修改后,关于生命周期配置的类型错误得以解决。
回归主问题:ES 查询超时
解决了缓存配置错误后,我们回归到核心的 ES 查询超时问题上。通过增强 _vector 方法的日志和异常处理,我们尝试获取更明确的线索。
增强日志与异常捕获
优化后的 _vector 方法加入了详细的日志和类型检查:
def _vector(self, txt, emb_mdl, sim=0.8, topk=10):
log.info(f"\n\n _vector \n\n")
log.info(f"\n\n emb_mdl {emb_mdl} \n\n")
if emb_mdl is None:
raise ValueError("Embedding model (emb_mdl) cannot be None")
try:
qv, c = emb_mdl.encode_queries(txt)
except AttributeError as e:
raise AttributeError(f"Invalid embedding model: {e}")
log.info(f"\n\n【QV】:{qv} \n\n")
log.info(f"\n\n【C】:{c} \n\n")
res = {
"field": "q_%d_vec" % len(qv),
"k": topk,
"similarity": sim,
"num_candidates": topk * 2,
"query_vector": [float(v) for v in qv]
}
log.info(f"\n\n【RES】:{res} \n\n")
return res
运行后发现,日志只输出到 _vector 方法的开始,emb_mdl.encode_queries(txt) 调用之后的日志均未打印。
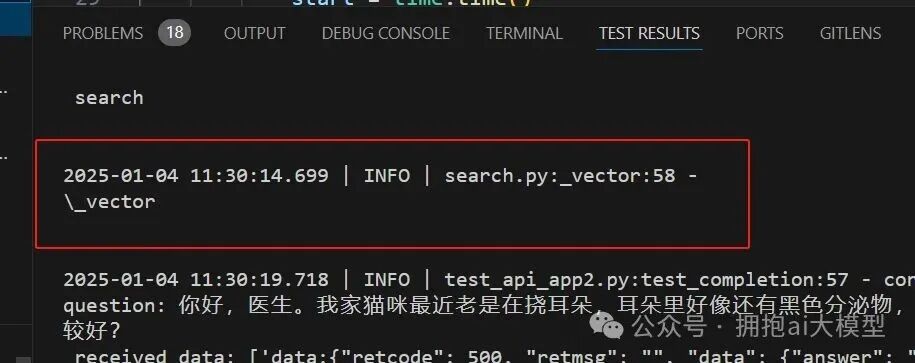
这强烈表明,性能瓶颈或阻塞发生在嵌入模型(emb_mdl)对查询文本进行编码的过程中。可能是模型加载缓慢、计算资源不足,或者是编码过程本身非常耗时。
结论与后续方向
本次排查明确了两个独立的问题:
- 缓存配置错误:成功定位并修复了 MinIO 存储桶生命周期规则设置时因缺少
rule_filter 参数导致的类型错误。
- ES 查询性能瓶颈:将查询超时的根本原因缩小到 文本向量化(Embedding) 阶段。
emb_mdl.encode_queries() 方法是主要的耗时点。
后续的优化应聚焦于嵌入模型:
- 检查模型状态:确认嵌入模型是否已正确加载、是否需要预热。
- 评估模型性能:当前使用的模型是否过于复杂,考虑替换为更轻量级的模型或在 GPU 上运行。
- 引入缓存:对于频繁出现的相似查询,可以考虑缓存其向量化结果,避免重复计算。
- 异步处理:将耗时的向量化过程改为异步,避免阻塞主请求线程。
通过这次对 RAGFlow 的代码追踪,我们不仅解决了表面错误,更重要的是揭示了在构建 人工智能 应用时,向量检索环节可能成为性能关键路径。在 Python 项目中,类似这样的深度日志分析和逐层排查是定位复杂系统问题的有效手段。
 发表于 2026-2-25 05:15:31
|
查看: 256|
回复: 0
发表于 2026-2-25 05:15:31
|
查看: 256|
回复: 0
