还记得2020到2021年那波SPAC(特殊目的收购公司)的狂热吗?那时候的路演PPT里,十年后百亿甚至千亿美金营收仿佛是标准配置。资本市场只要听见“市场规模(TAM)上万亿”、“复合增长率50%+”这样的宏大叙事,就愿意为一个尚未成型的故事提前买单。
几年过去,SPAC的泡沫已然退去,冷水浇在了每一家曾描绘过“十年百亿”蓝图的公司身上。而现在,一种极其相似的叙事方式,正在当下最火热的人工智能领域卷土重来。这一次,故事的主角换成了OpenAI,以及那份在业界流传甚广的“2030年达到2800亿美元年收入”的激进预测。
2800亿美元:这个数字意味着什么?
先抛开情绪,我们只看看这个数字本身。
- 年收入2800亿美元,大致相当于今天微软Azure云服务加上Office业务的总体量,或者接近“谷歌云加YouTube”的组合。
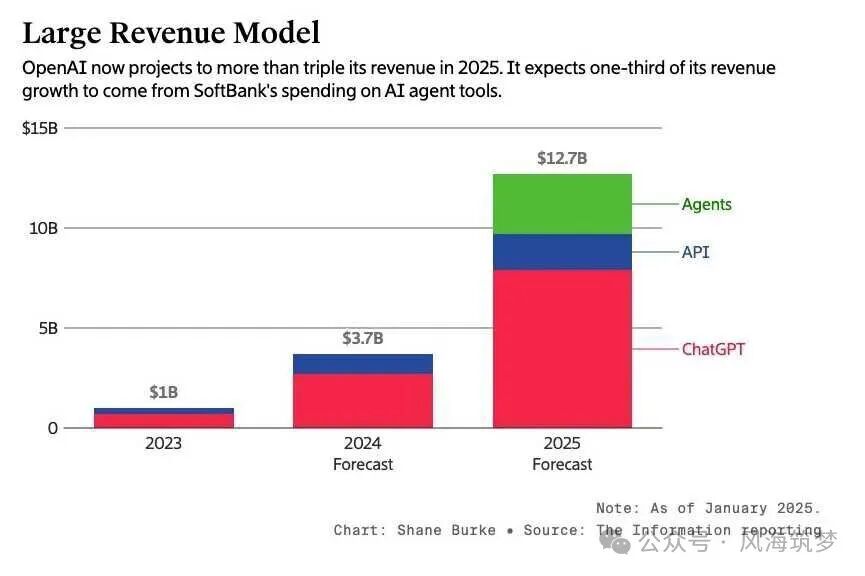
- 根据公开数据,OpenAI在2024年的收入大约在30到40亿美元的量级。要在2030年冲到2800亿,意味着在6年内放大近70倍。
- 这个目标背后隐含了三个苛刻的前提:
- 用户数量需要指数级扩张(流传的内部目标是达到27.5亿周活跃用户)。
- 平均客单价不能太低,必须通过“海量轻度用户+深度企业付费”的模式叠加,才能撑起数百亿的收入池。
- 最关键的是,市场竞争格局不能恶化,竞争对手不能把产品价格和行业毛利打穿。
问题随之而来:一个产品要覆盖超过20亿用户,通常需要满足“刚需、高频、极低门槛”的特性,这更像是微信、WhatsApp或YouTube的逻辑,而非当前形态下的ChatGPT。
“9.1亿周活”背后:用户活跃度与商业价值的错位
很多人看到“ChatGPT周活跃用户达9.1亿”这个数字时,会本能地感叹:“这已经是一个超级应用了。”
但如果我们拆解一下用户的使用深度,故事可能就没那么简单了。
- 有媒体披露,截至2025年,绝大多数ChatGPT用户的使用频率其实非常低:约80%的用户在其整个使用生命周期内发送的消息不足1000条,折算下来平均每天不到3条。
- 更关键的问题在于,这每天不到3条的互动中,有多少是“能够直接挂钩收入的商业场景”?
- 写一封邮件、润色一段文案、翻译几句话,这些确实有价值,但很难持续带来高客单价。
- 真正愿意且能够持续付费的,是企业客户:通过API进行大规模调用、将AI能力深度集成进业务流程、用以替换部分软件或人工成本。
换句话说,目前的ChatGPT,更像是一个“超大规模的工具型产品”,而非一个“用户深度经营、强留存的基础设施平台”。如果大部分用户都停留在“偶尔来问两句”的阶段,那么再漂亮的日活/周活数据,也很难自然生长出2800亿美元的年收入。
为何这波AI叙事,与SPAC时代如此相似?
回顾SPAC时代的典型“故事配方”,大概是这样几步:
- 画一个尽可能大的市场:“我们瞄准的是万亿级市场,未来所有XX领域都会被我们颠覆或替代。”
- 给出一条平滑陡峭的“十年收入曲线”:每年翻倍增长,看起来既激进又似乎“合乎逻辑”。
- 用几页PPT把故事拆解到多个赛道:“ToB SaaS + 广告 + 金融科技 + 国际扩张”,听上去无所不包,总有一个能成。
把这个配方套用在今天的OpenAI身上,你会发现惊人的契合:
- 大市场叙事:“通用人工智能将重塑所有行业,软件、内容创作、搜索、办公、教育……都是我们的潜在服务市场。”
- 激进的收入曲线:“收入从几十亿到几百亿再到几千亿,用户从几亿到十几亿再到二十几亿。”
- 多元化的赛道布局:“个人/团队订阅、API服务、企业级解决方案、自研芯片、乃至可能的硬件终端……”
逻辑上当然说得通,而且与当年的SPAC公司相比,OpenAI至少已经拥有了真实且可观的收入与强大的产品影响力。但两者的相似之处在于一个核心点:当一家公司的市场估值开始需要依赖“十年后2800亿收入”这样的远期预测来支撑时,叙事本身就成了其资产负债表中最重要、也最脆弱的一部分。
被高估的技术护城河与被低估的行业竞争
另一个被反复讨论的核心问题是:OpenAI的护城河究竟在哪里?
通常被提及的几点包括:模型效果与迭代速度的领先、强大的算力与资金支持(背后有微软)、品牌与先发优势(ChatGPT几乎成了AI对话的代名词)。
这些优势固然重要,但在商业史上,单凭“技术领先+资本充足”并不足以垄断一个广阔的市场。云计算时代,亚马逊AWS曾一度遥遥领先,但如今Azure、Google Cloud等玩家依然将市场撕扯成了多极格局。搜索时代,谷歌近乎统治,但在中国诞生了百度,在俄语世界有Yandex,在各类垂直场景下也存在着大量专业搜索引擎。
回到AI领域,情况可能更加复杂:
- 大模型技术在开源社区正飞速演化,头部公司与追赶者之间的能力差距在不断收窄。
- 本地化部署、行业专用小模型、垂直领域的SaaS解决方案,正在瓜分“大模型技术普及”之后产生的实际应用价值。
- 市场价格战已然开启,企业客户越来越看重实际的投资回报率(ROI)和供应商的可替代性,而非单纯的技术品牌情怀。
这意味着,即便人工智能真的创造出了一个万亿级别的庞大市场,其价值也几乎不可能被某一家“单点公司”全部独占。OpenAI那2800亿美元营收的宏伟蓝图,其隐含的前提是一个越来越不现实的、高度集中的市场格局。
我们该如何看待这份“2800亿预测”?
我更倾向于把它看作三样东西:
- 一个对外的叙事工具:要支撑起庞大的融资需求、惊人的算力投入和全球性的业务扩张,资本市场需要一个可以想象、足以令人兴奋的“终局数字”。
- 一个内部的动员口号:对于内部团队、潜在合作伙伴和供应链而言,“我们要成为下一个操作系统级的平台”远比“我们要做一个好用的工具网站”更能驱动资源的倾斜与投入。
- 一面反映市场情绪的照妖镜:它会持续暴露市场对AI领域的预期温度:
- 当所有人(包括投资人、媒体、公众)都无条件买账时,说明乐观情绪和泡沫成分仍在积聚。
- 当理性的质疑声开始越来越多时,则可能预示着市场情绪正在从狂热回归冷静区间。
从投资或创业的实用角度出发,我觉得有几点是值得借鉴和思考的:
- 不要被任何一个“终局数字”吓到或者过度兴奋,首先要问的是:“在这个宏大故事最终落地之前,真正稳定、可持续、可复利的现金流在哪里?”
- 真正能沉淀长期商业价值的,不一定是掌握最顶级通用模型技术的团队,而往往是那些最懂某个具体行业、最擅长将AI能力无缝嵌入现有业务流程的人。
- 历史表明,每一轮重大的技术浪潮都难以避免被过度金融化:故事会跑在技术成熟的前面,估值会跑在实际收入的前面,市场情绪会跑在商业理性的前面。
OpenAI的2800亿故事,或许有一天会成为现实,也或许只是SPAC时代狂热的一个更高级、更技术化的版本。无论结果如何,保持一份清醒的观察和独立的思考,总是有益处的。对于这类前沿技术的商业动态,你也可以在 云栈社区 的开发者广场找到更多有趣的讨论和不同视角的解读。 |  发表于 2026-2-25 05:13:28
|
查看: 221|
回复: 0
发表于 2026-2-25 05:13:28
|
查看: 221|
回复: 0
