当前各大模型的 API 即便用量很小,也是一笔可见开支。其实市面上几乎每一家主流 AI 厂商都提供了免费额度,但真要组合使用却让人头疼。接口格式五花八门,SDK 各自为政,限流规则也完全不一样,适配过程往往要堆一层又一层的 try-except 和轮询逻辑,一旦某家服务挂了还得手动切换。
有没有办法把这些免费额度叠在一起,像用一个统一接口那样调用呢?最近 GitHub 上冒出来的 freellmapi 正好解决了这个痛点。
项目简介
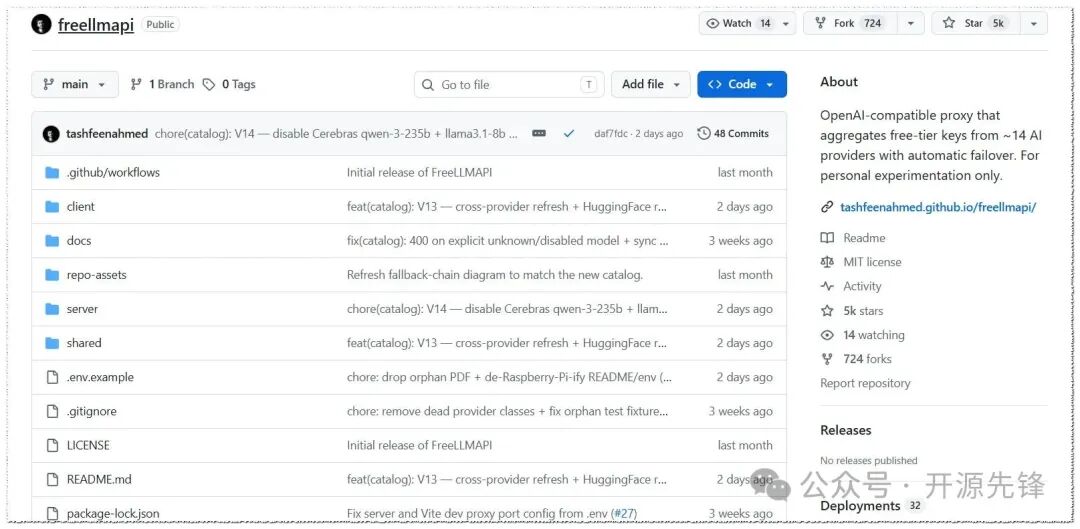
freellmapi 是一个自托管的 OpenAI 兼容代理网关。它把 Google Gemini、OpenRouter、Groq、GitHub Models、Z.ai (Zhipu) 等十几家 AI 平台 的免费 Tier 聚合到一起,配好 Key 之后每月能拿到合计约 10 亿 Token 的免费额度。
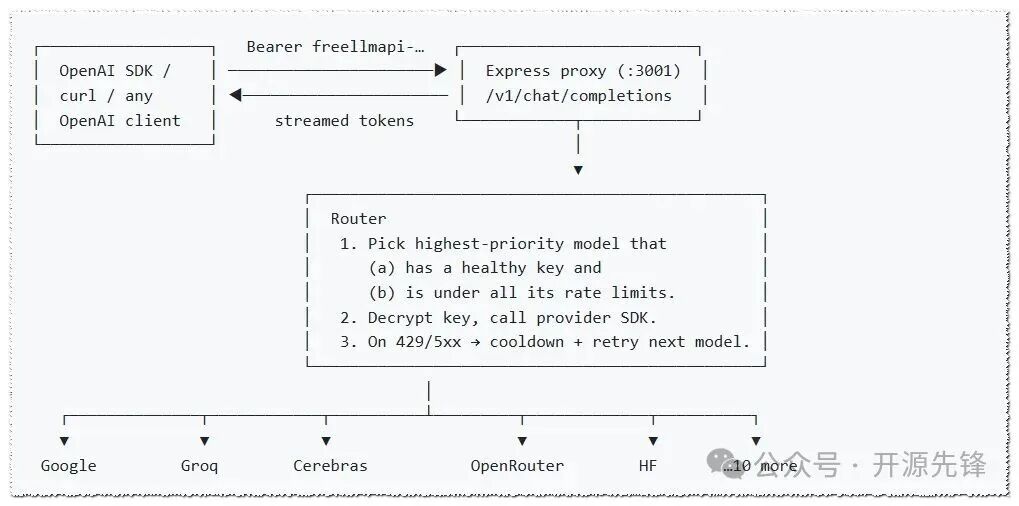
对外只暴露一个 /v1/chat/completions 端点,对内自动完成调度、切换和限速管理。你的代码完全不用改,继续使用 OpenAI SDK,只需把 base_url 指向本地代理即可。
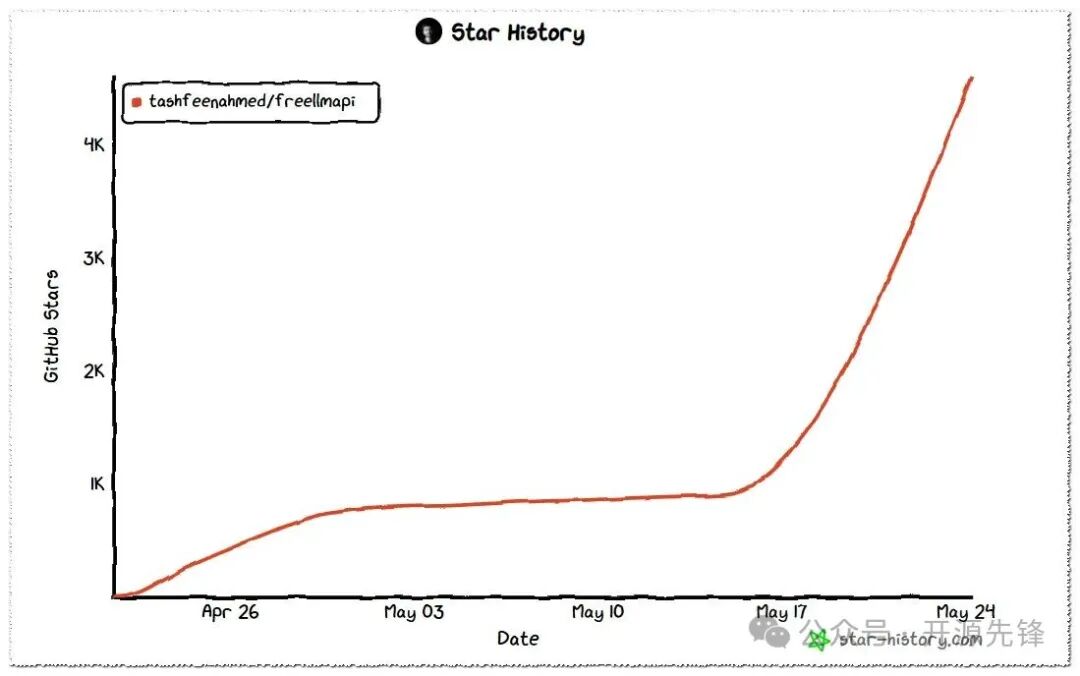
项目开源仅一个月,在 GitHub 上已经收获 5K+ Star,非常适合进行 AI 原型开发、Agent 实验以及个人小项目。
功能特色
- 一个接口统管:所有服务商收拢到同一个
/v1/chat/completions 端点,完全兼容 OpenAI SDK,改一个 base_url 就能直接用,不需要动业务代码。
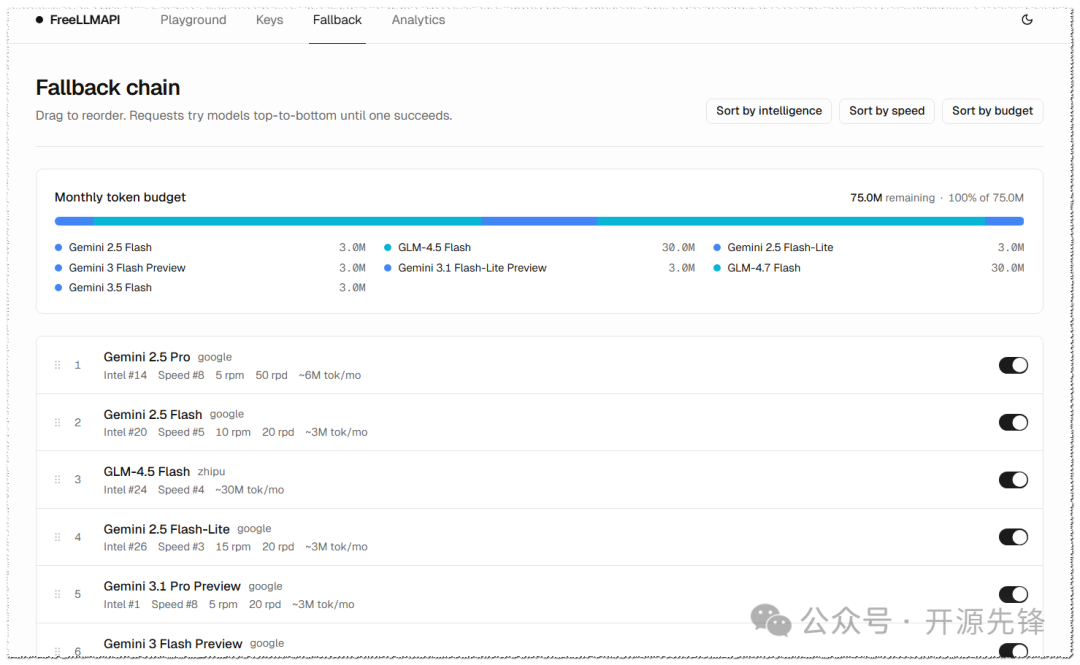
- 自动故障转移:某家出现限速、超配额或直接挂掉时,会自动跳到下一个可用节点,最多重试 20 次,整个切换过程对上层应用完全透明。
- 精准限速追踪:对每个
(平台, 模型, Key) 组合分别维护 RPM / RPD / TPM / TPD 计数器,路由器实时选出未超限的最优节点。
- 会话粘性:同一个对话在 30 分钟内固定走同一个模型,避免中途切换模型导致的上下文混乱。
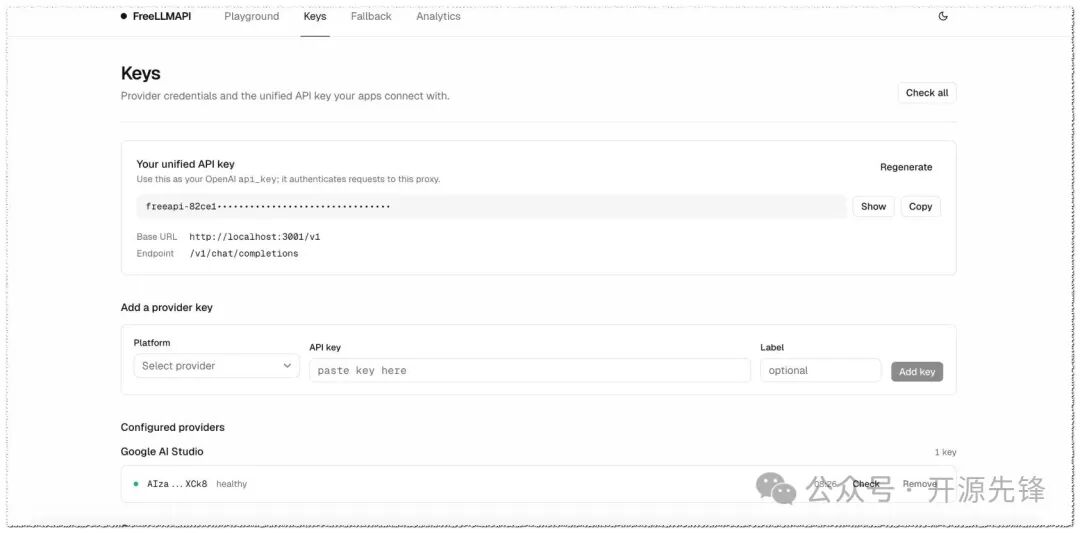
- Key 加密存储:服务商 Key 写入数据库前统一用 AES-256-GCM 加密,对外仅暴露一个统一的 Bearer Token。
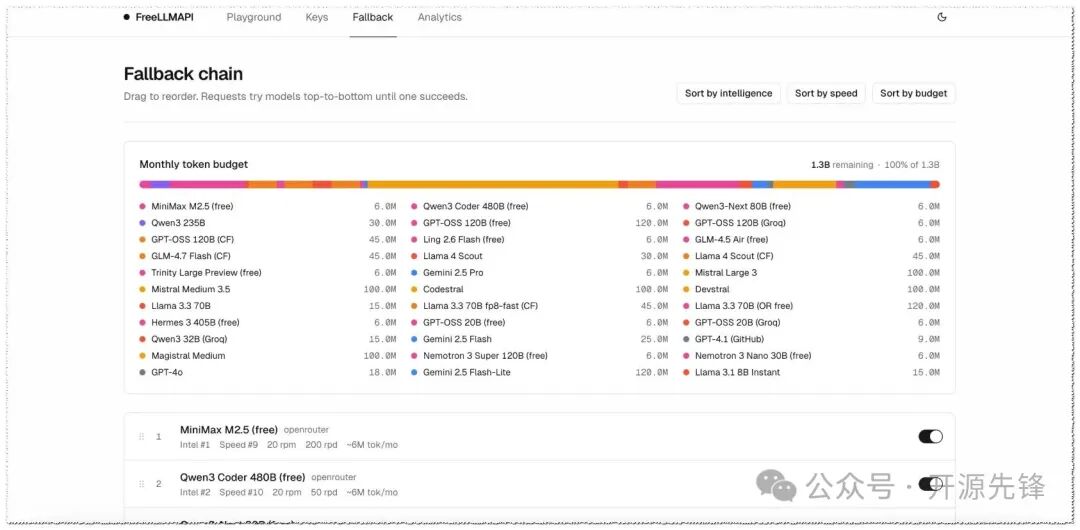
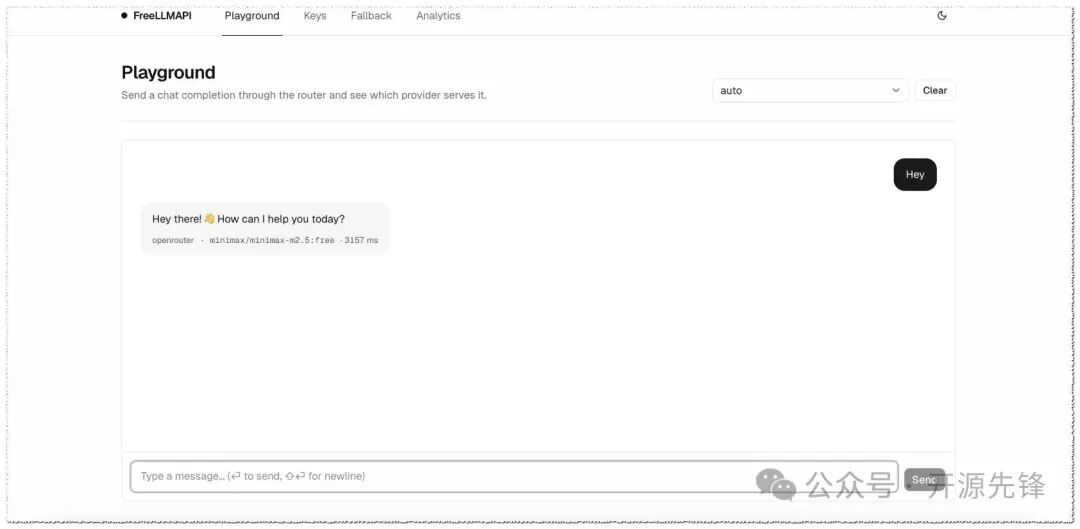
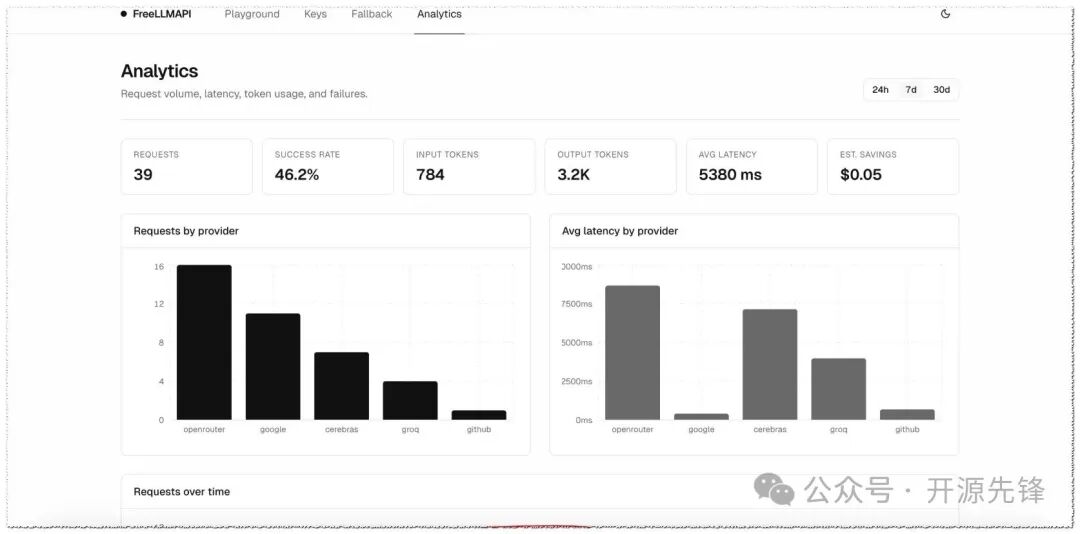
- 内置管理面板:基于 React + Vite 搭建的后台,涵盖 Key 管理、Fallback 链排序、Playground 测试和请求分析(成功率、延迟、Token 用量),并且支持深色模式。
快速安装、使用
环境要求:Node.js 20+ 和 npm。
第一步,克隆项目并安装依赖
git clone https://github.com/tashfeenahmed/freellmapi.git
cd freellmapi
npm install
第二步,生成加密 Key 并配置环境变量
cp .env.example .env
echo "ENCRYPTION_KEY=$(node -e "console.log(require('crypto').randomBytes(32).toString('hex'))")" >> .env
第三步,启动服务
npm run dev
启动后,浏览器访问 http://localhost:5173 进入管理面板。在 Keys 页面添加各家服务商的 API Key:
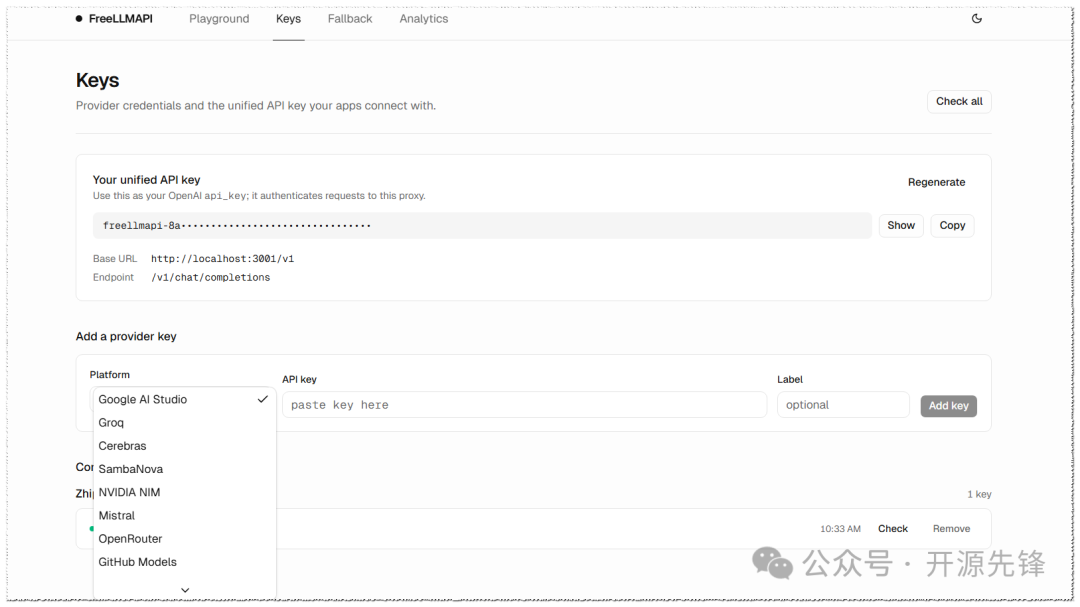
调整 Fallback Chain 的优先顺序:
然后复制页面顶部的统一 API Key。
第四步,把代码指向本地代理
Python 示例:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:3001/v1",
api_key="freellmapi-你的统一key",
)
raw = client.chat.completions.with_raw_response.create(
model="auto",
messages=[{"role": "user", "content": "你好"}],
)
print("Routed via:", raw.headers.get("x-routed-via"))
resp = raw.parse()
print(resp.choices[0].message.content)
model 填 "auto" 就让路由器自动选择,也可以指定具体模型名,比如 "glm-4.5-flash"。
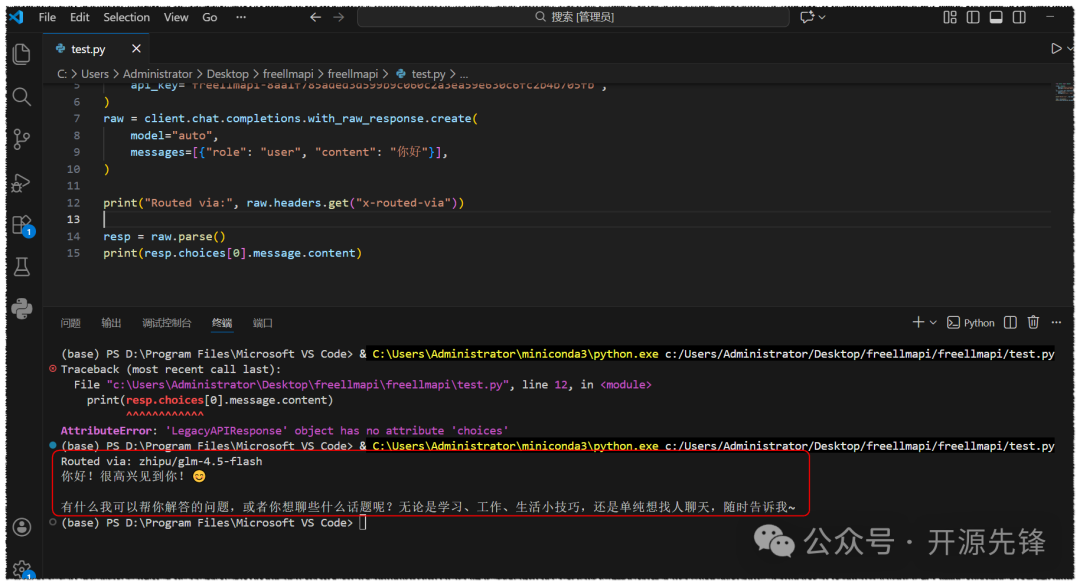
每次响应的 Header 里还会带上 X-Routed-Via 字段,告诉你这次请求实际由哪一家服务商负责,非常直观。
如果需要部署到生产环境,也可以使用:
npm run build
node server/dist/index.js
服务和面板都跑在 3001 端口,作者提到在树莓派 4 上运行也毫无压力,空闲时内存仅占用 40MB 左右。
小提醒
freellmapi 虽好,但并非万能,以下几点需要心里有数:
- 没有顶级模型,免费层止步于 Gemini 2.5 Pro、Llama 3.3 70B 这个级别,GPT-5、Claude Opus 之类就不要指望了。
- 额度越用越弱,头部模型配额少,用完后会自动降级,深夜体感质量可能下滑,UTC 零点重置。
- 仅限个人本地使用,不要暴露到公网,不能分享给他人,更不要当成生产后端。
- 免费套餐随时可能收紧,出现大量 429 错误时需要手动更新配置。
- 大多数服务商个人自用没问题,Cohere 条款明确禁止,建议跳过;NVIDIA NIM 和 GitHub Models 限定“实验用途”,需留意。具体请以各家最新条款为准。
- 别拿它搞生产:这玩意儿适合个人实验、原型验证、跑跑 Agent 玩玩。真要上线赚钱,还是建议去付费。
小结
freellmapi 做的事情说白了就一件:把分散的免费资源统一管起来,让用的人省心。十几家服务商、10 亿 Token、自动切换、加密存储、管理面板,一个本地代理全搞定。对于还在“白嫖阶段”的开发者来说,这已经是目前见过最省事的聚合方案之一。
更多细节功能,可前往项目地址查看:
https://github.com/tashfeenahmed/freellmapi
 发表于 2026-5-26 01:47:58
|
查看: 1366|
回复: 0
发表于 2026-5-26 01:47:58
|
查看: 1366|
回复: 0
