自动科研(AI Scientists)已经能写代码、跑实验、写论文了,但画一张漂亮的流程图仍然是瓶颈。
现有方案的问题:
- 代码派(TikZ/Python-PPTX):太死板,画不出现代 AI 论文那种精致的视觉效果
- 生成派(直接调用 DALL-E/Midjourney):指令跟随能力差,经常出现“箭头乱飞”、“文字乱码”、“逻辑错误”
核心痛点:科学发现的价值需要通过有效的视觉传达来实现,但当前的 AI科学家在视觉沟通方面表现糟糕。
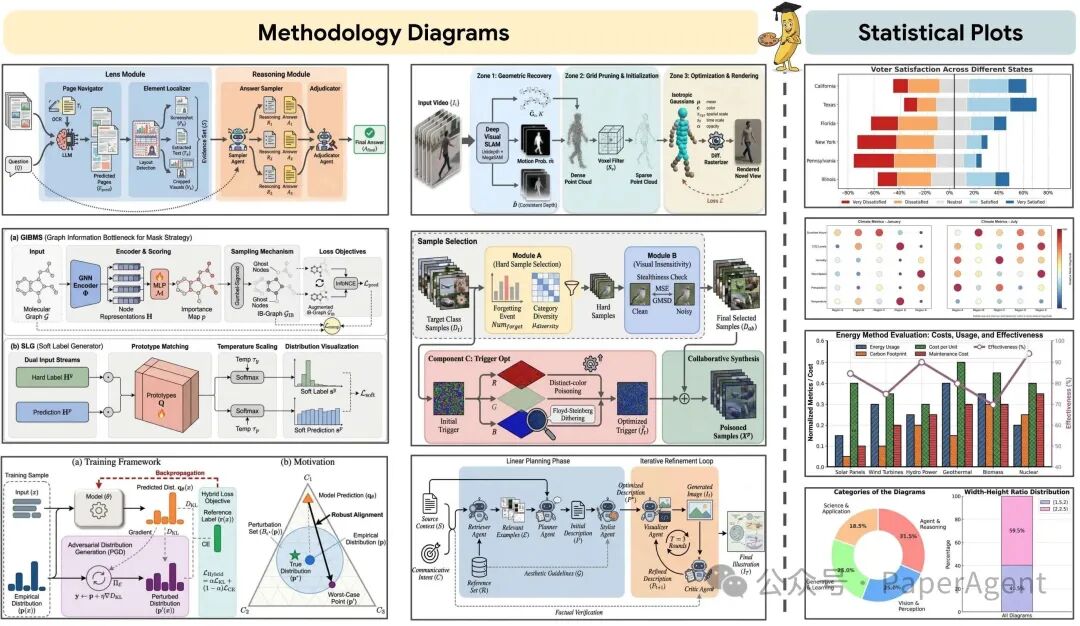
Figure 1: PaperBanana 自动生成的方法论流程图和统计图示例。注意:本论文中所有带 🍌 标记的图表都是由 PaperBanana 自动生成的。
二、PaperBanana 框架:五个智能体的协作艺术
PaperBanana 的核心思想是参考驱动+多智能体协作。它不直接生成图像,而是先理解、再规划、再美化、最后迭代优化。
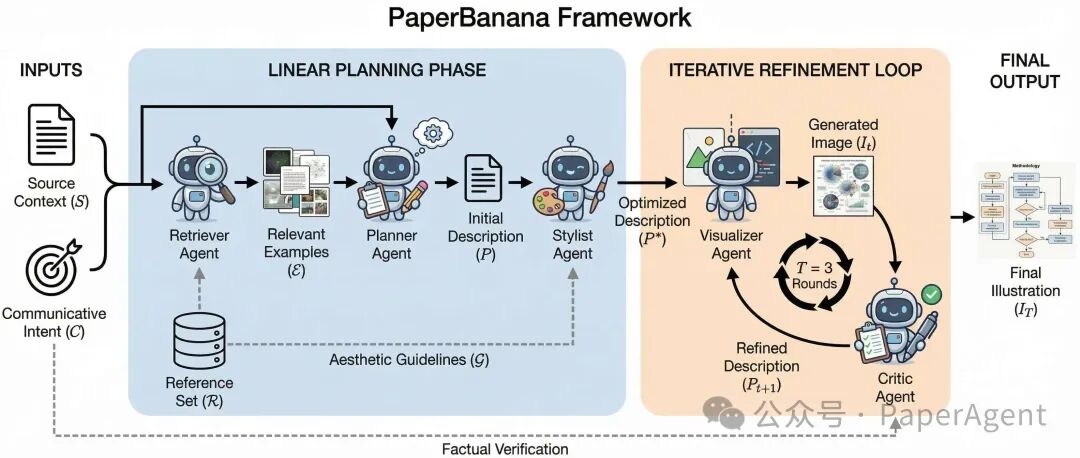
Figure 2: PaperBanana 整体架构。包含线性规划阶段(Retriever → Planner → Stylist)和迭代优化循环(Visualizer ↔ Critic)。
2.1 五大智能体分工
| 智能体 |
职责 |
关键技术 |
| Retriever |
从参考库检索相似案例 |
VLM 语义检索(优先匹配视觉结构而非主题) |
| Planner |
将方法描述转为详细文本描述 |
上下文学习(In-context Learning) |
| Stylist |
应用学术美学规范优化描述 |
自动总结的美学指南(配色、布局、字体) |
| Visualizer |
将描述转为图像 |
Nano-Banana-Pro / GPT-Image-1.5 |
| Critic |
检查错误并提供改进建议 |
多轮自我批判(默认 3 轮迭代) |
关键创新点:
- 参考驱动:不是零样本生成,而是先找相似的顶会论文插图作为参考
- 风格自动学习:Stylist 遍历整个参考库自动总结学术美学规范,而非人工预设
- 闭环优化:Critic 和 Visualizer 形成闭环,逐步修正事实错误和视觉瑕疵
三、PaperBananaBench:首个学术插图生成基准
为了严格评估,作者从 NeurIPS 2025 论文中构建了专业基准:
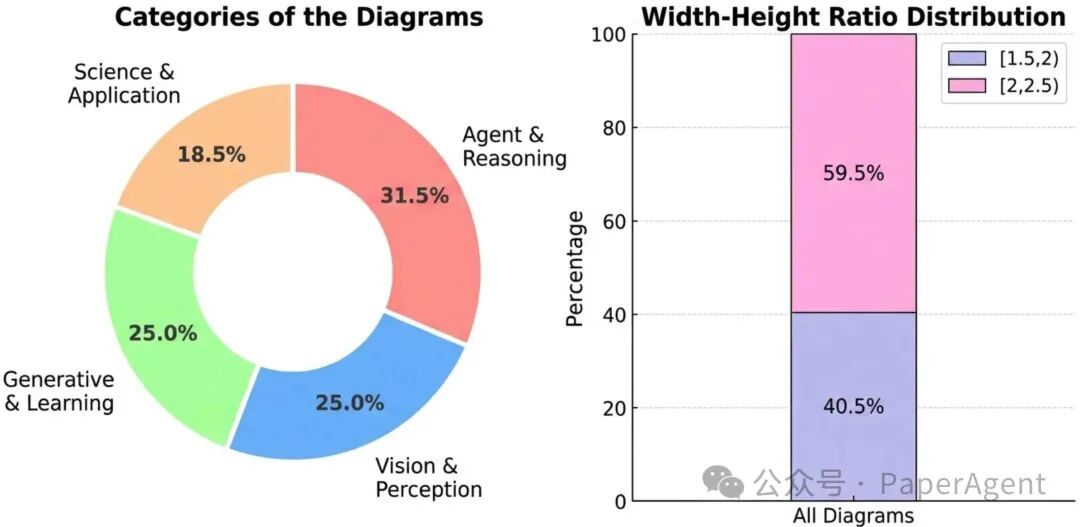
Figure 3: PaperBananaBench 测试集统计(292 个样本)。平均方法描述长度 3020 词,涵盖四大研究领域。
构建流程:
- 从 5275 篇 NeurIPS 2025 论文中随机采样 2000 篇
- 使用 MinerU 工具提取方法章节文本和图表
- 筛选宽高比 [1.5, 2.5] 的方法论流程图(排除竖图和超宽图)
- 人工校验描述准确性和视觉质量
- 按视觉拓扑分为四类:Agent & Reasoning、Vision & Perception、Generative & Learning、Science & Applications
评估协议(VLM-as-a-Judge):
- 忠实度(Faithfulness):是否准确反映方法描述和标题意图
- 简洁性(Conciseness):是否聚焦核心信息,无视觉 clutter
- 可读性(Readability):布局清晰、文字可读、线条不交叉
- 美观性(Aesthetics):符合学术出版的美学标准
采用参考对比评分:VLM 法官比较模型生成图 vs 人工原图,判定 Model Win / Human Win / Tie(分别对应 100/0/50 分)。
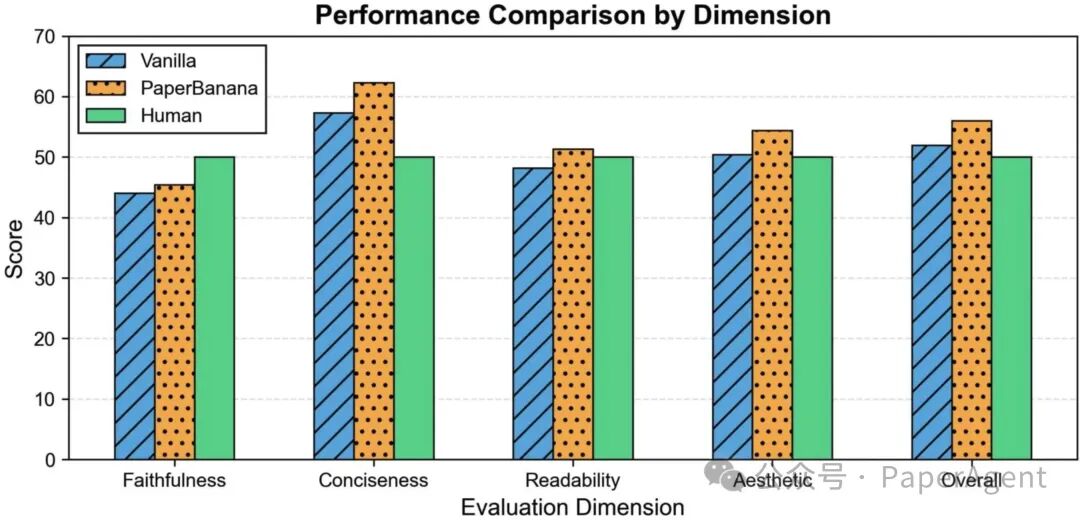
四、实验结果:全面碾压基线
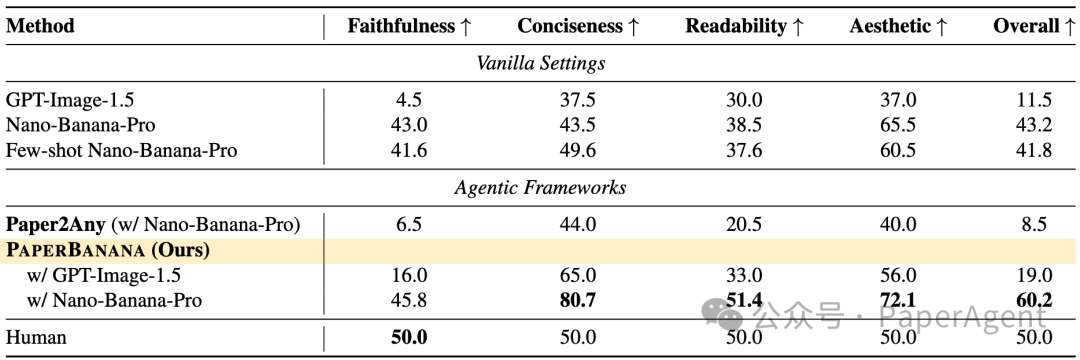
Table 1: PaperBananaBench 主实验结果。使用 Nano-Banana-Pro 作为图像生成模型。
关键发现:
- Overall 得分:PaperBanana 68.6% vs Vanilla 51.6%(+17.0%)
- 简洁性提升最显著:+37.2%(Stylist 代理成功去除了冗余元素)
- 各领域表现:Agent & Reasoning 领域得分最高(69.9%),Vision & Perception 相对较低(52.1%)
对比基线:
- Vanilla:直接提示词生成,效果最差
- Few-shot:提供 10 个示例,略有提升但仍不足
- Paper2Any:现有 SOTA 方法,但专注于呈现高层思想而非忠实还原方法流程,忠实度较差
人类盲测:3 位人类评委对 50 个样本进行盲评,PaperBanana 胜率为 72.7%,平局 20.7%,失败仅 6.6%。
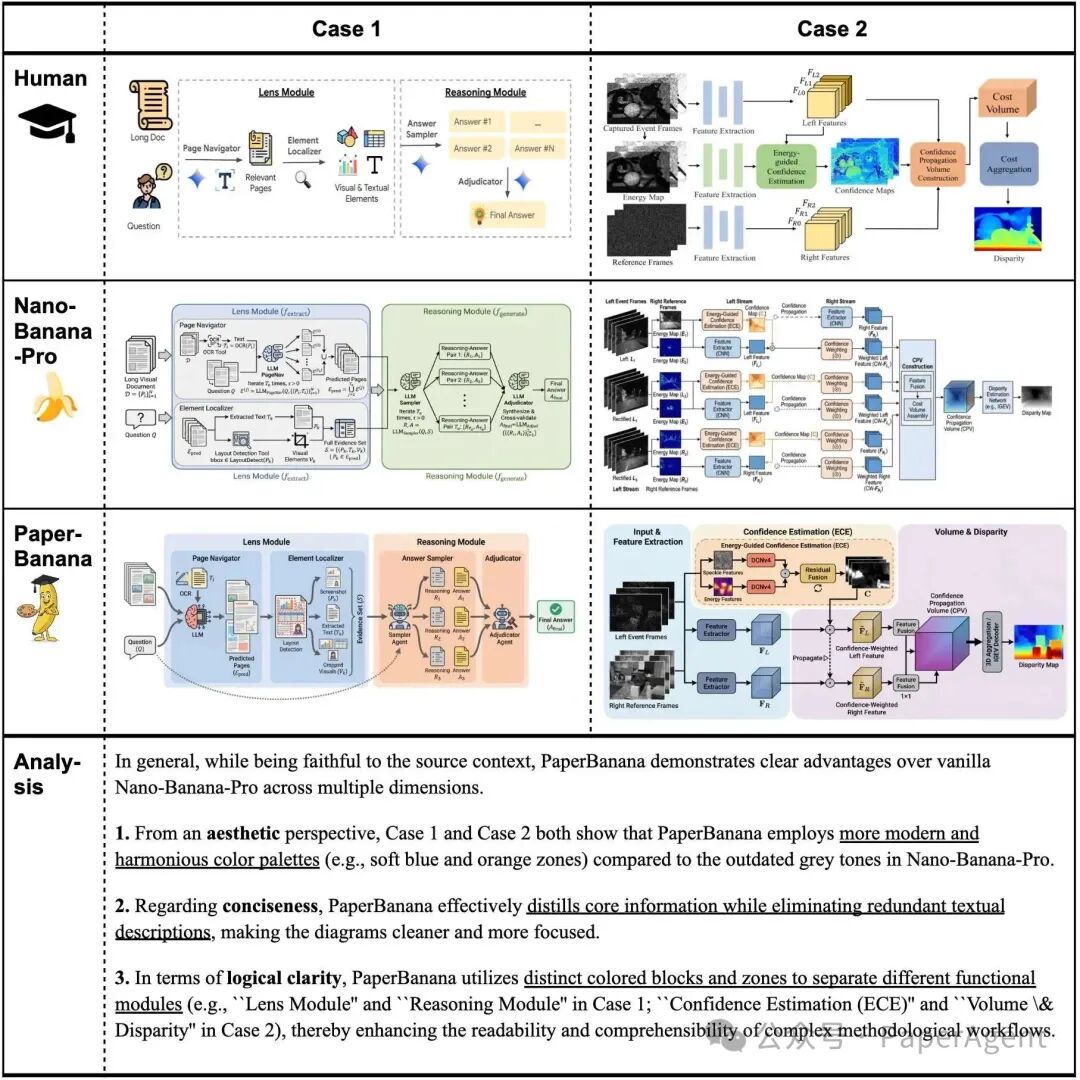
图表生成案例研究。在相同的源上下文和标题条件下,基础版 Nano-Banana-Pro 生成的图表往往存在色调过时、内容过于冗长的问题。相比之下,我们的 PaperBanana 生成的结果更加简洁美观,同时保持了对源上下文的忠实度。
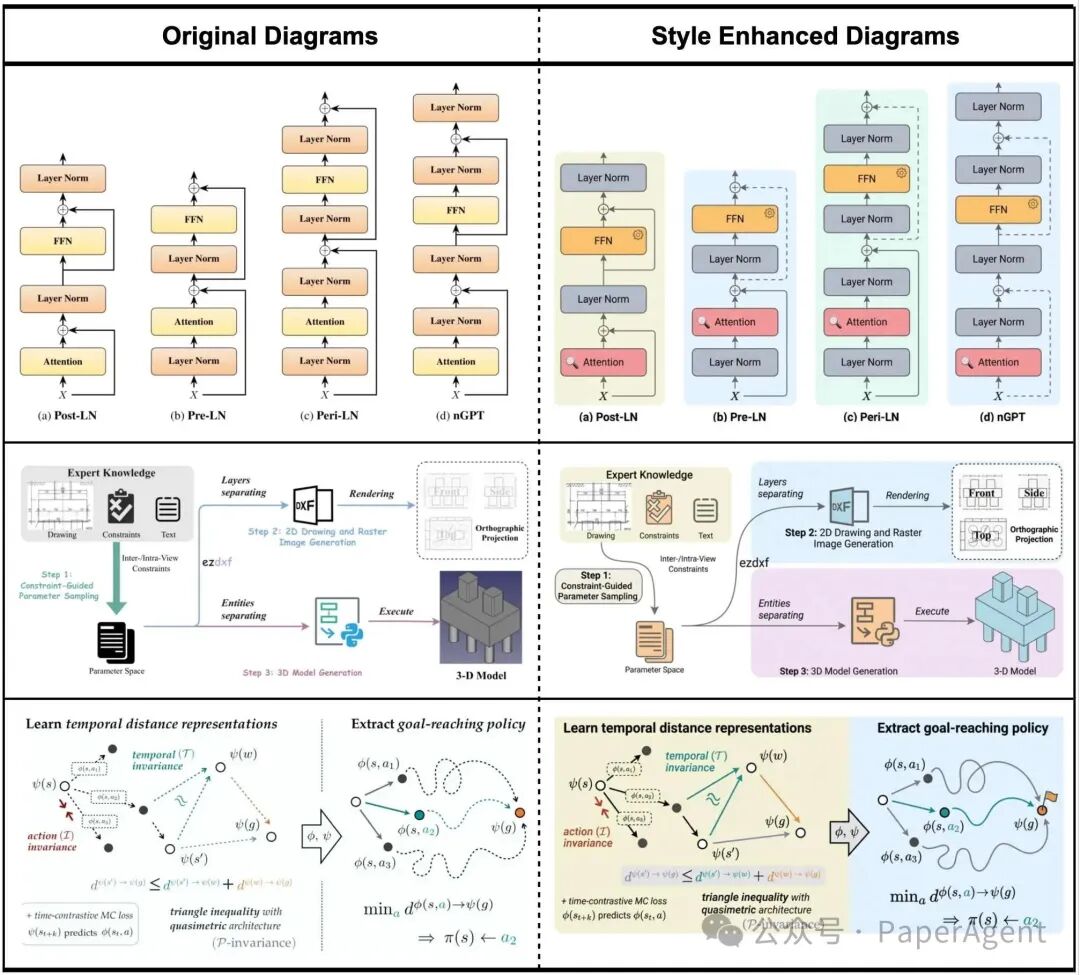
美学增强。展示使用我们自动总结的风格指南来提升人工绘制图表美感的更多案例。优化后的图表在配色方案、字体排版、图形元素等方面展现出显著的风格改进。
五、总结
PaperBanana 代表了学术插图自动化的重要里程碑。通过多智能体协作和参考驱动学习,它首次实现了接近人类水平的自动化方法论流程图生成。
https://arxiv.org/pdf/2601.23265
https://dwzhu-pku.github.io/PaperBanana/
PaperBanana: Automating Academic Illustration for AI Scientists
对于研究AI在内容生成领域应用的朋友来说,这项进展无疑将自动化科研的边界又向前推进了一步。如果你想了解更多关于人工智能的前沿项目与实战应用,可以关注 云栈社区 的相关板块。 |  发表于 2026-2-25 07:29:33
|
查看: 234|
回复: 0
发表于 2026-2-25 07:29:33
|
查看: 234|
回复: 0
