2026年2月17日,Anthropic发布了 Claude Sonnet 4.6,这是目前功能最强大的 Sonnet 系列模型。它在编程、计算机操作、长上下文推理、智能体规划、知识工作以及设计等方面实现了全面升级。在测试阶段,它提供了高达 100 万 token 的上下文窗口。
对于 Free 和 Pro 套餐的用户,Claude Sonnet 4.6 已成为 claude.ai 和 Claude Cowork 的默认模型。值得注意的是,其 API 价格与 Sonnet 4.5 保持一致,仍为每百万输入 token 3 美元、输出 token 15 美元起。
Sonnet 4.6 将显著提升的编程能力带给了更多开发者。在代码一致性、指令理解与执行等方面的改进,使得获得早期访问权限的开发者明显更偏好 Sonnet 4.6,而不是上一代模型。他们甚至常常更喜欢它,而不是 2025 年 11 月发布的最强模型 Claude Opus 4.5。
过去只有 Opus 级别模型才能胜任的性能表现——包括在真实、具备经济价值的办公任务中——现在通过 Sonnet 4.6 就可以实现。与以往的 Sonnet 模型相比,它在计算机操作方面也有了堪称飞跃的提升。
和每一代新 Claude 模型一样,开发团队对 Sonnet 4.6 进行了全面的安全评估。它与近期其他 Claude 模型一样安全,甚至在某些方面更安全。安全研究人员认为,Sonnet 4.6 “整体风格温和、诚实、具有亲社会倾向,偶尔还带点幽默感;安全行为表现非常强;在高风险场景下未发现明显的失控迹象。”
计算机操作能力的飞跃
许多组织都会使用一些难以自动化的遗留软件——例如在 API 等现代接口出现前开发的专用系统和工具。过去,想让 AI 使用这些软件,通常需要开发定制的连接器。但如果模型能像人类一样直接操作计算机,这个问题便迎刃而解。
早在 2024 年 10 月,Anthropic 就率先推出了通用型计算机操作模型。当时他们提到,它“仍处于实验阶段——在某些情况下操作繁琐且容易出错”,但预计会快速改进。作为 AI 计算机操作领域的标准基准,OSWorld 清晰地展示了模型的进步。该基准包含数百项任务,覆盖在模拟计算机上运行的真实软件(如 Chrome、LibreOffice、VS Code 等)。它没有提供专门的 API 或定制接口;模型只能像人类一样,通过点击(虚拟)鼠标和输入(虚拟)键盘与系统交互。
在过去 16 个月中,Sonnet 系列模型在 OSWorld 基准上的表现持续进步。这种提升不仅体现在冰冷的测试分数中。Sonnet 4.6 的早期用户反馈称,它在浏览复杂电子表格、填写多步骤网页表单,甚至在多个浏览器标签页之间整合信息等任务上,已非常接近人类水平。
尽管在计算机操作方面仍不及最熟练的人类专家,但其进步速度令人瞩目。这不仅意味着 AI 在更多实际工作场景中变得更有用,也预示着更强大的模型即将到来。
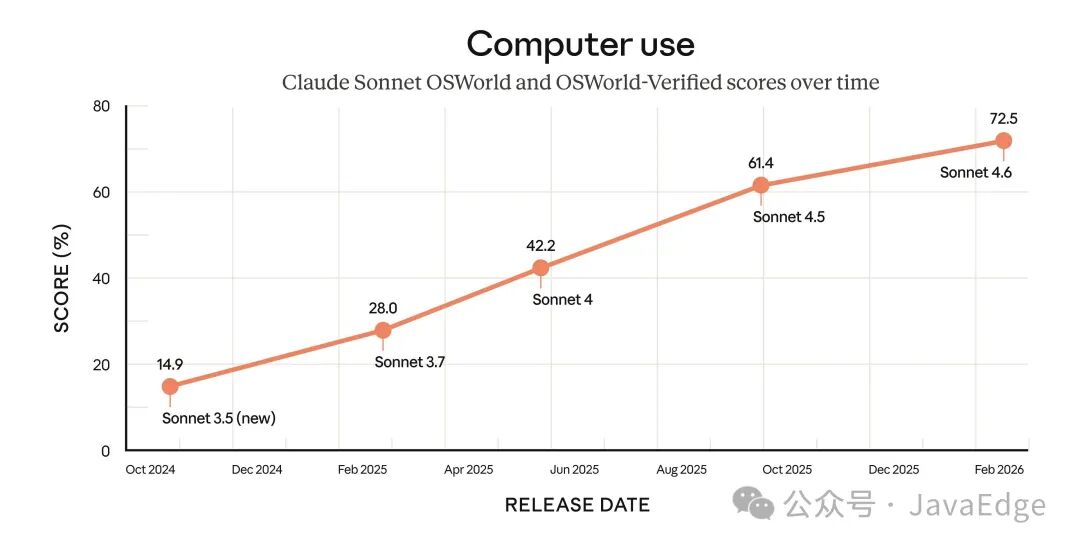
Claude Sonnet 4.5 之前的分数基于原始 OSWorld;从 Sonnet 4.5 开始使用 OSWorld-Verified。OSWorld-Verified(2025 年 7 月发布)是在原基准基础上的升级版本,改进了任务质量、评分方式和基础设施。
当然,强大的计算机操作能力也带来了新的安全风险。例如,恶意攻击者可能通过在网页中隐藏指令发起“提示词注入攻击”,试图劫持模型。开发团队一直在持续提升模型对这类攻击的防御能力。安全评估显示,与 Sonnet 4.5 相比,Sonnet 4.6 有明显改进,整体表现与 Opus 4.6 相当。
全面基准测试表现
除了计算机操作能力外,Claude Sonnet 4.6 在各类基准测试中都有显著提升。在更具性价比的价格下,它已经非常接近 Opus 级别的智能水平。下方表格简要总结了其与其他前沿模型的对比表现。
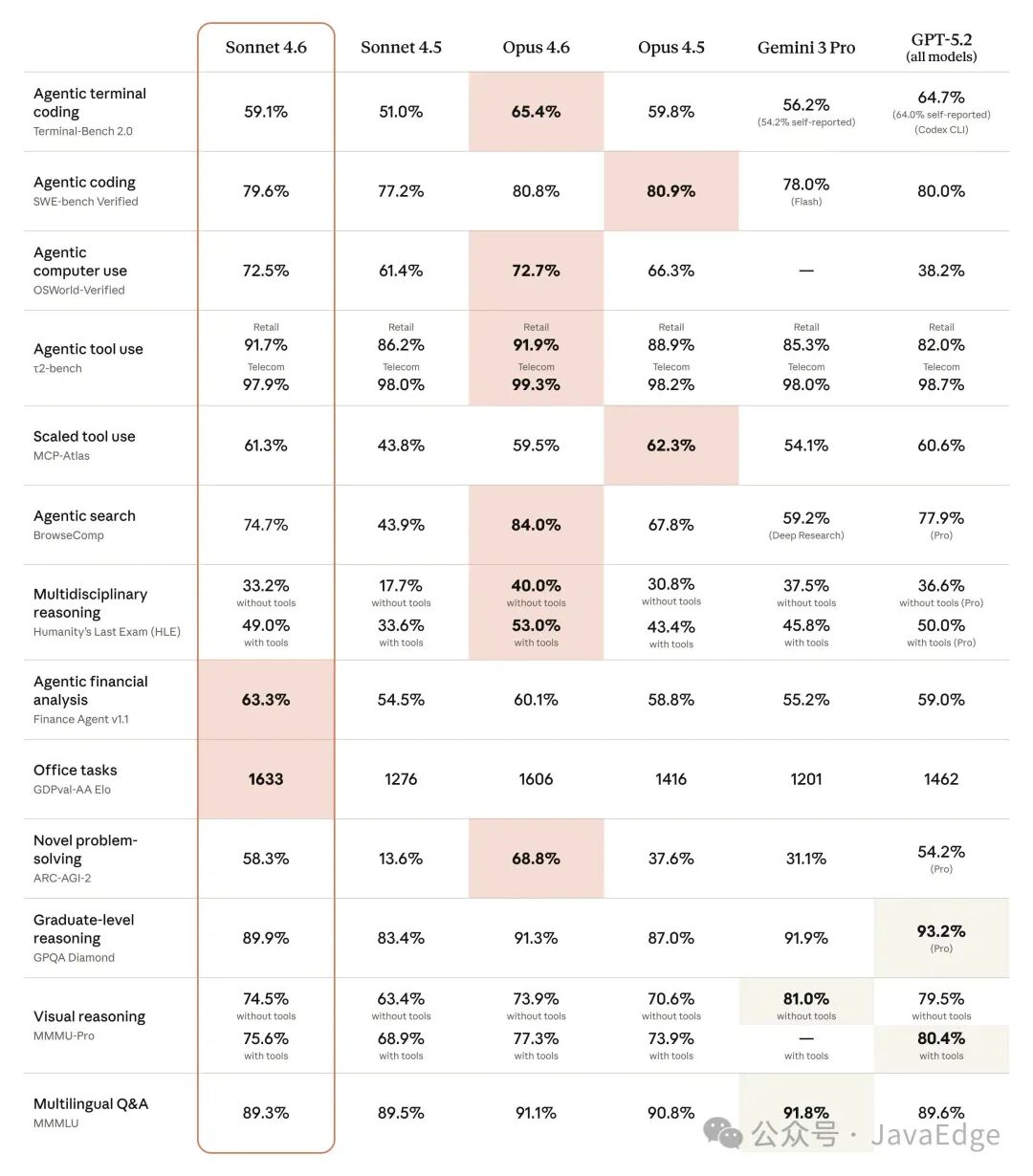
在 Claude Code 中的早期 A/B 测试显示,用户约有 70% 的时间更偏好 Sonnet 4.6,而不是 Sonnet 4.5。用户反馈称,它在修改代码前更善于理解上下文,也更倾向于整合共用逻辑,而不是重复编写相同代码。因此,在长时间、复杂的编码任务中,其使用体验明显优于以往版本。
甚至在与 2025 年 11 月发布的前沿模型 Opus 4.5 对比时,用户也有 59% 的时间更偏好 Sonnet 4.6。他们认为 Sonnet 4.6 明显减少了过度设计和“偷懒”现象,在执行指令方面更准确。虚假的成功声明更少,幻觉现象更少,在多步骤任务中的执行也更稳定可靠。
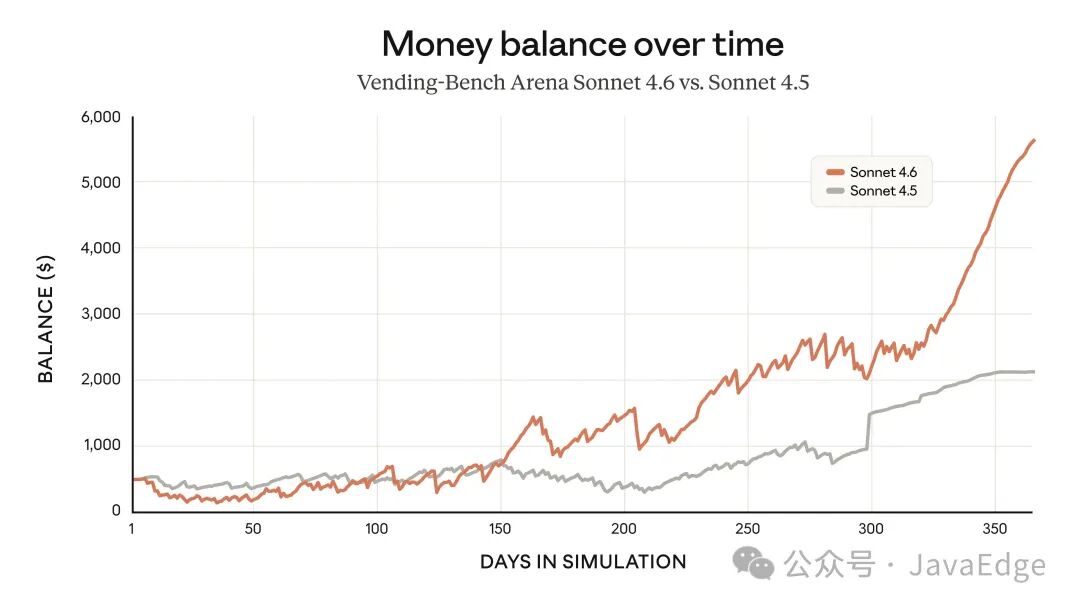
Sonnet 4.6 提供 100 万 token 的上下文窗口,足以在一次请求中容纳一个完整的代码库、一份冗长的合同或数十篇研究论文。更重要的是,它能够在如此庞大的上下文中进行有效推理,这显著提升了其长期规划能力。在 Vending-Bench Arena 评测中,这一点尤为明显。该评测测试模型在一段时间内运营(模拟)企业的能力,并引入竞争机制,让不同 AI 模型比拼最终的利润表现。
Sonnet 4.6 展现了一个有趣的新策略:在前十个模拟月份中大幅投入产能建设,支出远高于竞争对手;随后在后期迅速转向利润优先策略。正是这种精准的转型时机,使它最终明显领先于其他模型。
早期企业客户也反馈了模型的整体提升,尤其在前端代码生成和财务分析方面表现突出。多位客户独立表示,Sonnet 4.6 生成的视觉输出更加精致,布局、动画和设计感都优于以往模型。同时,为达到可投入生产环境的质量,所需的迭代次数更少。
产品与API更新
在 Claude 开发者平台上,Sonnet 4.6 支持以下高级功能:
- 自适应思考(adaptive thinking)
- 扩展思考(extended thinking)
- 测试阶段提供上下文压缩(context compaction)功能。当对话接近上下文上限时,系统会自动总结较早的内容,从而有效提升可用上下文长度。
在 API 中,Claude 的网页搜索(web search)和网页抓取(fetch)工具现在可自动编写并执行代码,对搜索结果进行筛选和处理,仅保留最相关的内容,从而提升回答质量并提高 token 使用效率。
此外,代码执行(code execution)、记忆(memory)、程序化工具调用(programmatic tool calling)、工具搜索(tool search)以及工具使用示例功能现已全面开放。
Sonnet 4.6 在不同思考强度下都能保持强劲表现,即使关闭扩展思考功能也依然出色。建议在从 Sonnet 4.5 迁移时,根据具体应用场景,在推理速度与输出稳定性之间找到最佳平衡。
当然,对于需要最深层推理能力的任务,如大型代码库重构、多智能体工作流协调,以及对结果精确度要求极高的问题,Opus 4.6 仍是更强的选择。
对于使用 Claude in Excel 的用户,插件现已支持 MCP 连接器,让 Claude 可与 S&P Global、LSEG、Daloopa、PitchBook、Moody’s 和 FactSet 等日常数据工具协同工作。用户可以在不离开 Excel 的情况下调用外部数据。如果你已在 Claude.ai 中配置了 MCP 连接器,这些连接会自动在 Excel 中生效。该功能适用于 Pro、Max、Team 和 Enterprise 套餐。
如何开始使用
目前,Claude Sonnet 4.6 已在所有 Claude 套餐、Claude Cowork、Claude Code、API 以及主流云平台上线。Free 套餐已默认升级为 Sonnet 4.6,并支持文件上传、连接器、技能和上下文压缩功能。
开发者可以通过 Claude API,使用模型 ID claude-sonnet-4-6 来快速开始集成和测试。对于希望深入探讨最新 AI 模型技术细节和应用实践的开发者,欢迎在 云栈社区 的相关板块交流分享。
 发表于 2026-2-25 09:32:30
|
查看: 260|
回复: 0
发表于 2026-2-25 09:32:30
|
查看: 260|
回复: 0
