在生成式AI席卷全球的今天,我们正处于一个极具迷惑性的技术节点:一方面,AI工具的普及速度前所未有;另一方面,真正能将其转化为核心生产力的人却寥寥无几。许多人认为,给ChatGPT、Claude或DeepSeek下个指令、拿回一段代码或文案,就是“掌握了AI”。但Anthropic最新发布的《AI流利度指数》(The AI Fluency Index)报告却给这种盲目乐观泼了一盆冷水。
这份报告不仅揭示了普通用户与“高手”之间的鸿沟,更提出了一个振聋发聩的警告:如果不具备“AI流利度”,AI不仅不能增强你的能力,反而可能导致你的技能退化。
由Rick Dakan教授与Joseph Feller教授构建、Anthropic联合发布的“AI流利度框架”,定义了在自动化、增强及智能体三种AI交互模式下,人类有效、高效、伦理且安全地使用AI开展工作所需的四大核心能力:委派(Delegation)、描述(Description)、辨识(Discernment)与勤勉(Diligence)。
通过对“AI流利度指数”的大规模实证研究以及关于“AI对技能形成影响”的深度分析,揭示了提升AI协作价值的关键路径:持续的迭代优化与批判性评估。研究指出,虽然AI能显著提升效率,但若缺乏主动的认知参与,可能导致技能退化;真正的AI流利度要求使用者超越“一键生成”的思维,将AI视为思考伙伴而非单纯的替代者。
这不仅是一套关于技术运用的教育资源,更是一份旨在构建以人为核心、责任导向的智能未来指南,指引我们在算法时代通过反思性实践与好奇心,实现人类智能与机器智能的深度共生与跨越式进化。

人们正以前所未有的速度将AI工具融入日常生活,这一进展即便在一年前也难以预测。然而,仅仅衡量“采用率”并不足以说明这些工具的实际影响。一个同样重要的问题是:当AI成为日常生活的一部分时,人们是否也在发展出高质量使用它的能力?
之前Anthropic教育报告研究了大学生和教育工作者如何使用Claude。发现学生使用它撰写报告、分析实验结果;教师则用它构建课程材料并自动化常规事务。同时也知道任何使用AI的人都可能逐步提升其工作能力。Anthropic希望进一步探究这一过程,理解人们在使用AI的过程中如何逐渐形成“流利度”(fluency)。
Anthropic通过对大量匿名对话样本进行分析,追踪一套被视为代表AI流利度的行为分类体系在对话中的出现情况。
与Anthropic近期发布的经济指数研究结果一致,发现最常见的AI流利度表现形式是“增强式”(augmentative)使用——将AI视为思考伙伴,而不是完全将工作委托给它。事实上,这类对话中展现出的AI流利度行为数量,是简单快速往返式对话的两倍以上。
Anthropic也发现,当AI生成具体产物(包括应用程序、代码、文档或交互工具)时,用户较少质疑其推理过程(下降3.1个百分点),也较少指出其缺失的上下文(下降5.2个百分点)。这一发现与Anthropic近期关于编码技能的研究结果一致。
基于这些初步发现,Anthropic建立了一个基准以追踪未来AI流利度随时间的发展变化。
一、什么是AI流利度(AI Fluency)?
什么是流利度?它不是操作技巧,而是一种人类的胜任力。它定义了你是否能有效、高效、伦理且安全地在自动化(AI干活)、增强(人机协作)和代理(AI替你决策)这三种模式中自如切换。
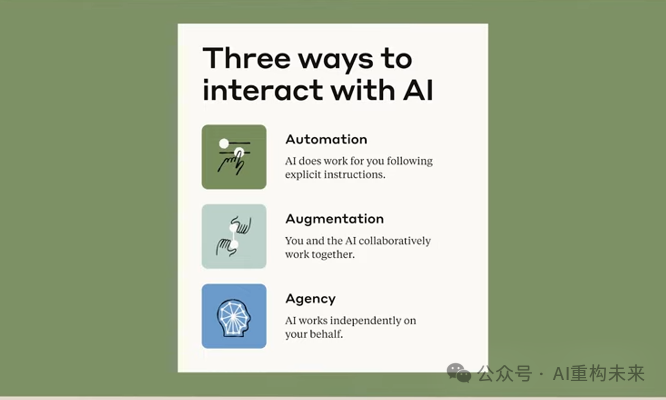
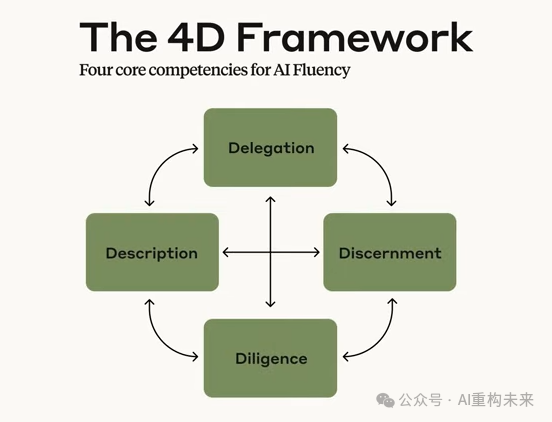
为了衡量这种能力,Rick Dakan和Joseph Feller教授构建了著名的“4D框架”。
-
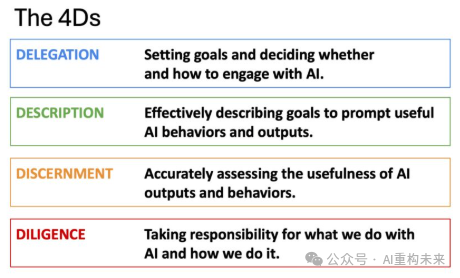
委派(Delegation): 核心在于创意愿景与工具选择。你是否能识别出哪些任务适合交给AI(比如数据分析),哪些必须由人类把控(比如价值观决策)?这要求使用者对AI的能力边界有精准的认知。
-
描述(Description): 并非简单的“写提示词”,而是愿景与任务的有效传达。这包括“产品描述”(定义输出目标)、“过程描述”(通过对话进行动态协作)以及“性能描述”(定义AI未来的行为模式)。
-
辨识(Discernment): 这是目前最稀缺的能力——准确评估AI输出的质量与逻辑。它要求你不仅看结果好不好看,还要通过批判性思维去识别幻觉、偏差与逻辑漏洞。
-
勤勉(Diligence): 这是伦理与责任的基石。无论AI参与了多少,人类必须为最终成果背书。这包括事实核查、偏见缓解以及对使用AI的过程保持透明。
AI流利度(AI fluency)与AI素养(AI literacy)区别:
AI素养(AI literacy)是知道AI能做什么;
AI流利度(AI fluency)是知道如何与AI一起工作。包括对输出进行迭代优化、质疑其推理过程、识别缺失的信息、设定协作规则等。
素养是被动的知识掌握;流利度是主动的实践能力。而这两者之间的鸿沟,正是大多数企业AI项目失败的关键。你可以参考专业的技术文档来系统提升这种实践能力。
二、如何衡量AI流利度
为了量化AI流利度,Anthropic采用了“4D AI 流利度框架”(4D AI Fluency Framework)。该框架由Rick Dakan教授与Joseph Feller教授与Anthropic合作开发,用于界定24种体现安全且有效的人机协作的具体行为。
在这24项行为中,有11项(如下图所列)可以在人类与Claude在 Claude.ai或Claude Code上的互动中直接观察到。其余13 项(例如是否诚实说明AI在工作中的角色,或是否考虑分享AI输出的后果)发生在对话界面之外,因此难以追踪。而这些不可观察的行为,可能正是AI流利度中最具影响力的维度之一。未来Anthropic计划采用定性研究方法对其进行评估。
本研究聚焦于这11项可直接观察的行为。Anthropic使用隐私保护分析工具,在2026年1月的7天窗口期内,分析了9,830条包含多轮往返的Claude.ai对话。每条对话可能呈现多个行为特征。Anthropic还通过比较不同日期和不同语言样本的结果一致性来验证样本可靠性(结果显示一致)。最终,Anthropic构建了“AI流利度指数”:这一指数既是当前人们如何与AI协作的基准衡量,也为未来模型演进中的行为变化追踪提供了基础。
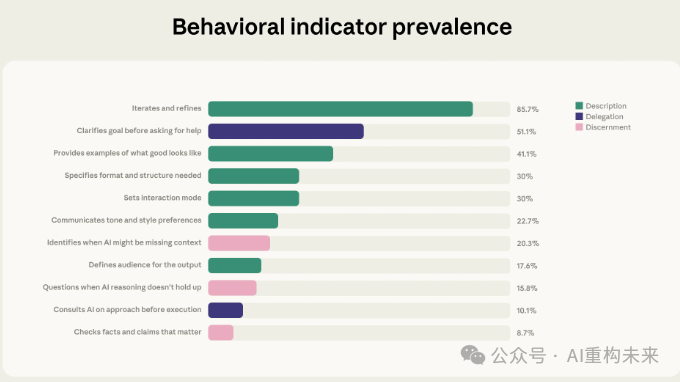
在9,830条Claude.ai对话中,各项AI流利度行为指标的出现比例,按从最常见到最少见排序,并按能力类别进行颜色编码标示。
上图中各行为指标及占比
1、Iterates and refines — 85.7%
迭代与精炼 —— 85.7%
2、Clarifies goal before asking for help — 51.1%
在寻求帮助前明确目标 —— 51.1%
3、Provides examples of what good looks like — 41.1%
提供“理想结果”示例 —— 41.1%
4、Specifies format and structure needed — 30%
指定所需格式与结构 —— 30%
5、Sets interaction mode — 30%
设定互动方式 —— 30%
6、Communicates tone and style preferences — 22.7%
说明语气与风格偏好 —— 22.7%
7、Identifies when AI might be missing context — 20.3%
识别 AI 可能缺失的上下文 —— 20.3%
8、Defines audience for the output — 17.6%
明确输出的目标受众 —— 17.6%
9、Questions when AI reasoning doesn't hold up — 15.8%
当 AI 推理站不住脚时提出质疑 —— 15.8%
10、Consults AI on approach before execution — 10.1%
在执行前与 AI 讨论方法路径 —— 10.1%
11、Checks facts and claims that matter — 8.7%
核查关键事实与主张 —— 8.7%
三、本次研究的关键结果
研究发现在Claude的使用模式中的两个主要特征:
其一,AI流利度与通过较长对话进行迭代与精炼之间存在显著关联;
其二,当用户进行编码或构建其他产出时,其流利度行为会发生变化。
1. 流利度与“迭代与精炼”高度相关
数据中最显著的模式,是“迭代与精炼”行为与其他所有AI流利度行为之间的强相关关系。
在样本中,85.7%的对话呈现出迭代与精炼特征——即用户基于之前的交流,优化用户的工作,而不是接受第一个回复然后转向新任务。这些对话显示了其他流利度行为的显著高比例,如下图所示:
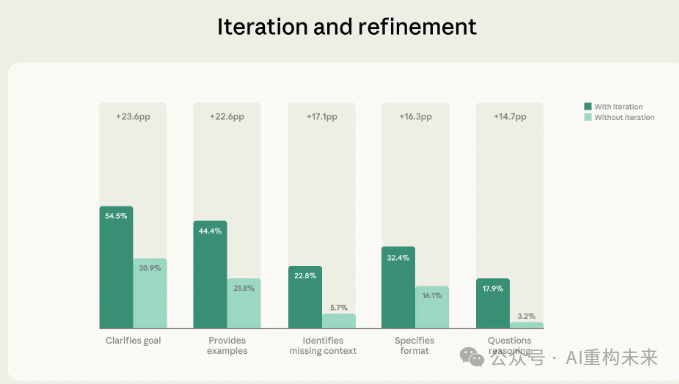
在用户进行迭代与精炼的对话(n=8,424)与未进行迭代与精炼的对话(n=1,406)中,各行为指标的出现比例对比。结果显示,在包含迭代与精炼的对话中,所有行为指标的出现频率均显著更高。
这类对话中,平均多出现2.67项额外的流利度行为,约为非迭代对话(1.33项)的两倍。特别是在评估AI输出方面差异明显:
- 更可能质疑Claude的推理(提升5.6倍)
- 更可能指出缺失的上下文(提升4倍)
2. 生成具体产物时:更具指令性,但更少评估
在样本中,12.3%的对话涉及生成产物(代码、文档、交互工具等)。在这类对话中,用户的行为模式明显不同。
用户在“描述”与“委托”方面更加积极:
- 明确目标(+14.7个百分点)
- 指定格式(+14.5个百分点)
- 提供示例(+13.4个百分点)
- 进行迭代(+9.7个百分点)
换言之,用户在任务初期对AI的引导更加清晰。
但这种“指令性增强”并未带来更高程度的评估行为,反而出现下降:
- 指出缺失上下文(-5.2个百分点)
- 事实核查(-3.7个百分点)
- 质疑模型推理(-3.1个百分点)
考虑到经济指数显示复杂任务恰恰是Claude最易出错的领域,这一趋势尤为值得关注。
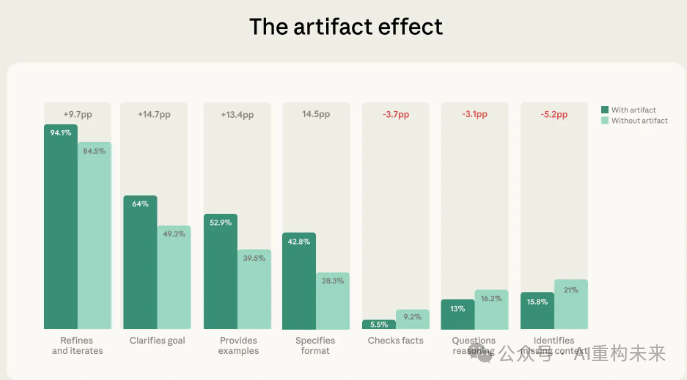
在包含产出物的对话(n=1,209)与不包含产出物的对话(n=8,621)中,各行为指标的出现比例对比。结果显示,在生成产出物的对话中,“描述类”和“委派类”行为有所增加,而三项“辨别类”行为则均有所下降。
对于这一模式,可能存在多种解释。
1)Claude生成的输出看起来经过打磨、功能完整,因此用户觉得没有必要再进一步质疑:如果成果看起来已经完成,用户往往就会按“已完成”对待。
2)生成产出物的对话所涉及的任务,其事实精确性的重要性低于美观性或功能性(例如设计用户界面,而不是撰写法律分析)。
3)用户通过Anthropic无法观察到的渠道对这些产出物进行评估——例如运行代码、在其他环境中测试应用、与同事分享草稿——而不是在最初的对话中直接表达他们的评估过程。
无论原因如何,这个模式都值得关注。随着AI模型越来越能产出精致的输出,无论是直接对话还是其他方式,批判性评估这些输出的能力将变得更有价值,而非更低。
四、 如何培养你自己的AI流利度?
和所有技能一样,AI流利度也有程度之分——对我们大多数人而言,仍然有很大的提升空间。基于报告的发现,Anthropic给出了三条具体的实操建议,旨在打破“低效协作”的恶性循环:
-
留在对话中(Stay in the conversation): 永远不要把AI的第一遍回答当成终点。把它当作一个草稿,通过不断的追问、反驳、调整角度,逼出AI的深度逻辑。
-
建立“预设契约”: 在对话开始前,明确告诉AI你的协作风格。例如:“请在我假设错误时提出反驳”、“在给出结论前先推导逻辑”或“列出你回答中不确定的部分”。目前只有30%的用户会这样做,但这却是建立“主动协作”的关键。
-
对抗“成品偏见”: 当你看到ChatGPT、Claude或DeepSeek吐出一个非常完美的图表或程序时,先别急着喝彩。强制自己问三个问题:这里面少了什么?这个逻辑在极端情况下会崩溃吗?这真的是最优解吗?
五、本研究报告的局限性
本研究存在一些重要的限制条件:
1、样本局限性:
研究样本来自2026年1月某一周内在Claude.ai上进行多轮对话的用户。Anthropic认为AI工具的普及仍处于相对早期阶段,这些用户很可能偏向于已经熟悉AI的早期采用者——也就是说,他们未必能代表更广泛的人群。因此,本样本应被视为该特定群体的基准,而非普适性的标准。此外,由于数据仅来自单周,无法反映季节性或长期变化趋势。而且因为研究聚焦于Claude.ai,未能覆盖用户在其他AI平台上的互动情况。
2、框架覆盖不完整:
本研究仅评估了24项行为指标中可在Claude.ai对话中直接观察到的11 项。所有与AI输出的负责任与伦理使用相关的行为,都发生在对话之外,因此未被纳入本次分析。
3、二元分类方法:
对于样本中的每一段对话,Anthropic将每种行为简单划分为“出现”或“未出现”。这种方法可能忽略了大量细微差别——例如行为的部分体现、程度差异,或不同信号之间的重叠。
4、隐性行为:
用户可能在心理层面展现流利度行为(例如将Claude的陈述与自身知识进行比对核查),但并未在对话中表达出来。这一点在涉及产出物的对话中尤为重要——用户可能通过实际测试和应用来评估Claude的输出,而不是通过对话中可见的行为来体现评估过程。
5、相关性而非因果性:
Anthropic识别出的关系属于相关关系。无法确定某一行为是否导致另一行为,或二者是否共同反映某种潜在因素,例如任务复杂度或用户偏好。
六、未来展望
本研究为评估AI流利度随时间变化提供了一个基准。随着AI能力不断演进、应用范围持续扩大,Anthropic希望进一步了解:用户是否正在形成更加复杂成熟的行为模式,哪些技能会随着经验自然涌现,哪些则需要有意识地培养。
在未来的研究中,Anthropic计划从多个方向拓展分析:
首先,开展“群组分析”(cohort analyses),比较新用户与经验用户,以理解对AI的熟悉程度如何与流利度发展相关联。
其次,采用定性研究方法,评估那些无法在Claude.ai对话中直接观察到的行为。
第三,探索本研究提出的因果问题——例如,是否鼓励用户进行迭代式对话会提升其批判性评估能力,或是否存在更有效的干预方式。
此外,Anthropic还计划研究Claude Code平台中的AI流利度行为。该平台主要面向软件开发者。为此,Anthropic已进行了一些初步分析,发现Claude Code与Claude.ai对话之间存在一定一致性。但这些结果仍属早期阶段。鉴于Claude Code的用户群体与功能特性存在显著差异,仍需更深入的研究。
Anthropic预计,AI流利度的内涵将随着时间发生显著演变。通过当前及未来的研究,Anthropic的目标是使这一发展过程变得可见、可衡量、并可付诸行动。
结语:
AI流利度不是一种可以通过阅读说明书获得的技能,而是一种反思性的实践(Reflective practice)。
如Anthropic教育报告所言,随着模型能力的进一步增强,AI产出的结果会越来越像“魔法”。但这种魔法是有代价的——它极易剥夺人类的判断力。在这个算法主导的时代,保持AI流利度的核心,其实是保有一颗永不妥协的好奇心。我们要学会利用AI这个“思考杠杆”去撬动更广阔的创造力,而不是躺在AI编织的便捷温床里,任由思维肌肉萎缩。
真正的AI高手,从不把AI当作提词器,而是把它当作磨刀石。 唯有如此,我们才能在人机协作的浪潮中,实现人类智慧与机器智能的跨越式进化。想了解更多关于人工智能的前沿动态和实践技巧,欢迎来云栈社区交流讨论。
附录:11项可观察AI流利度行为详解
1、Iteration and Refinement — Building on previous exchanges to refine work rather than accepting the first response and moving on (most common, found in 85.7% of conversations)
迭代与精炼 —— 基于之前的交流不断改进工作,而不是接受第一次回答后就继续进行其他任务(最常见,出现在 85.7% 的对话中)
2、Clarifying Goals — Explicitly stating what you're trying to achieve before or during the interaction
明确目标 —— 在互动开始前或过程中清楚说明你想要达成什么
3、Specifying Format — Telling the AI how you'd like the output structured or presented
指定格式 —— 告诉AI你希望输出以何种结构或形式呈现
4、Providing Examples — Giving the AI sample inputs or outputs to guide its response
提供示例 —— 向AI提供示例输入或输出以引导其回应
5、Questioning the Model's Reasoning — Asking the AI to explain its rationale or pushing back on its logic
质疑模型的推理 —— 要求AI解释其推理依据,或对其逻辑提出质疑
6、Identifying Missing Context — Recognising and flagging gaps or omissions in the AI's response
识别缺失的上下文 —— 发现并指出AI回答中的空缺或遗漏
7、Fact-Checking — Verifying the accuracy of the AI's claims within the conversation
事实核查 —— 在对话中验证AI所作陈述的准确性
8、Setting Interaction Preferences — Telling the AI how you'd like it to behave (e.g. "push back if I'm wrong" or "be concise")
设定互动偏好 —— 告诉AI你希望它如何与您互动(例如:“如果我错了请反驳”或“请简洁表达”)
9、Delegating Tasks — Assigning a clear task or subtask to the AI with defined scope
委派任务 —— 向AI分配范围明确的具体任务或子任务
10 Describing the Problem — Providing detailed background or context so the AI understands the situation fully
描述问题 —— 提供详细背景或上下文,使AI能充分理解情境
11、Evaluating Outputs Critically — Assessing whether the AI's response meets the actual need, not just whether it looks complete
批判性评估输出 —— 判断AI的回答是否真正满足实际需求,而不仅仅是看起来完整
参考材料:
1:Anthropic Education Report: The AI Fluency Index
https://www.anthropic.com/research/AI-fluency-index
2:AI Fluency: Framework & Foundations
https://anthropic.skilljar.com/ai-fluency-framework-foundations
3:AI Fluency: Framework & Foundations Course Trailer
https://www.youtube.com/watch?v=-UN9sNqQ0t4
2:AI Fluency Framework
https://aifluencyframework.org/
3:Framework for AI Fluency (Practical Summary Document), Version 1.1
https://ringling.libguides.com/ai/framework
4:Anthropic Unveils AI Fluency Index to Measure Human–AI Collaboration
https://aidatainsider.com/news/anthropic-unveils-ai-fluency-index-to-measure-human-ai-collaboration/
5:The AI Fluency Framework
https://www-cdn.anthropic.com/334975cdec18f744b4fa511dc8518bd8d119d29d.pdf?ref=hackshackers.com
6:https://x.com/rkjat65/status/2025978982538314153/photo/2
7:Anthropic’s New AI Index Shows What Sets Top AI Users Apart
https://www.forbes.com/sites/danfitzpatrick/2026/02/23/anthropics-new-ai-index-shows-what-sets-top-ai-users-apart/
 发表于 2026-2-26 03:44:20
|
查看: 185|
回复: 0
发表于 2026-2-26 03:44:20
|
查看: 185|
回复: 0
