最近,AI圈内关于DeepSeek V4的传闻一波未平,一波又起,核心议题围绕着模型发布与中美技术竞争展开。
DeepSeek V4 Lite参数疑似泄露
多方消息来源指出,DeepSeek V4将在一周内上线。而关于其轻量版模型 DeepSeek V4 Lite 的更多细节也开始在网络上流传。据悉,该模型目前至少在一家推理服务商处进行积极测试,并且施加了严格的保密协议(NDA)。
目前透露出的关键信息包括:
- 模型代号为 “sealion-lite”
- 拥有 100万token的上下文窗口
- 性能显著优于当前的网页版或应用模型
- 是原生多模态模型
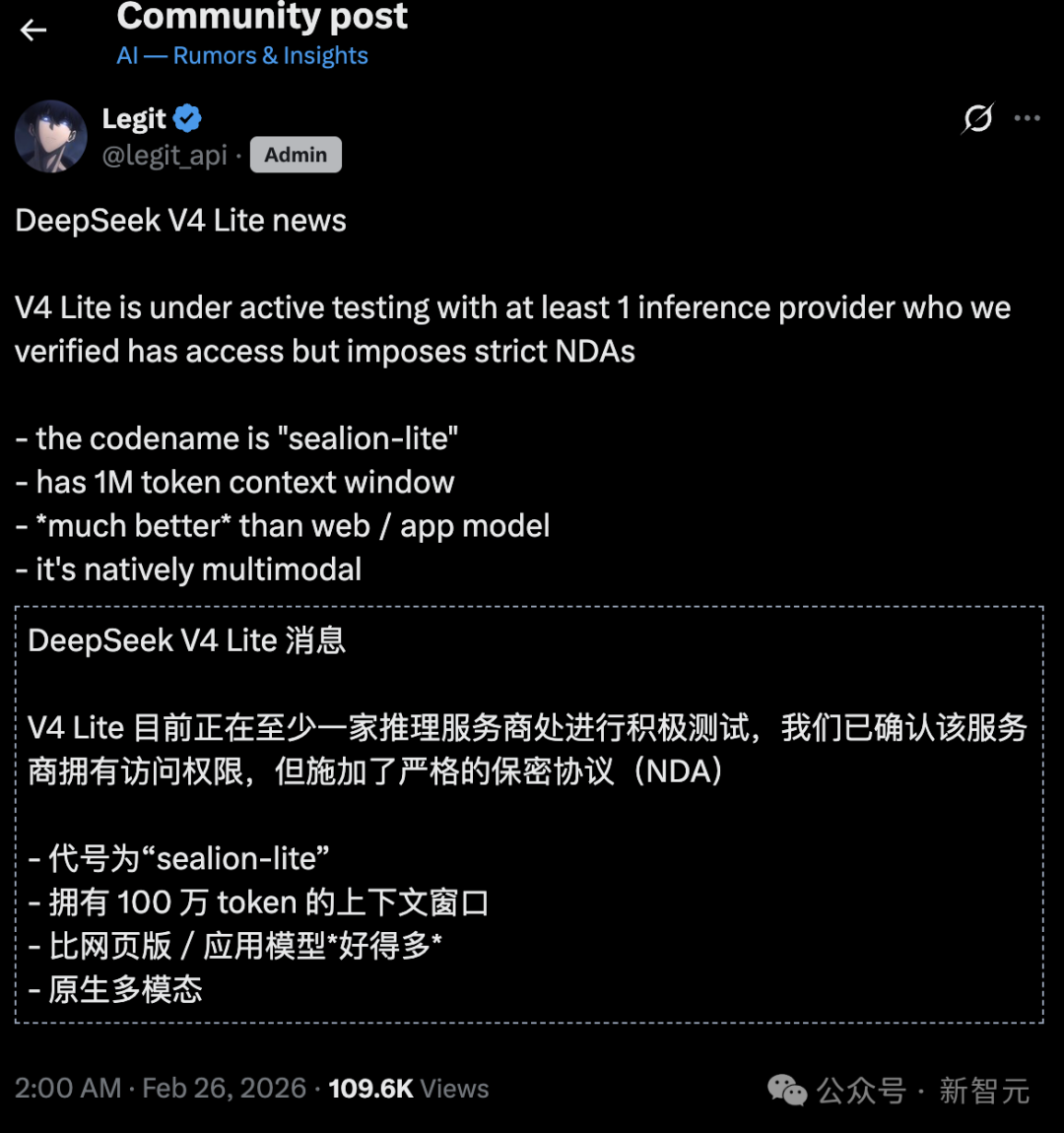
与此同时,一张关于 DeepSeek v4 Lite 与当前 DeepSeek v3.2 的对比图在外网流传。图中以幽默的比喻方式展示,在不开启“思考”模式的情况下,V4 Lite在生成SVG图像等任务上可能具备更好的质量。
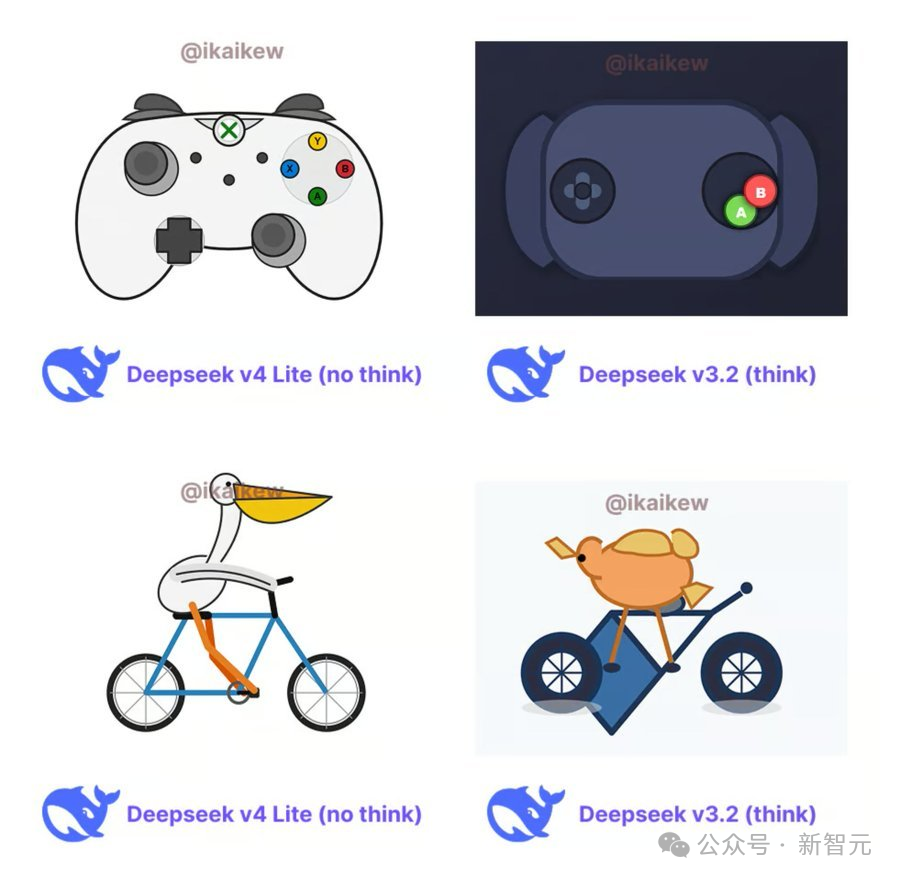
模型发布策略引发行业关注
路透社的一则报道加剧了外界对此次发布的关注。报道称,两位消息人士透露,DeepSeek并未像行业惯例那样,在主要模型更新前向英伟达等美国芯片制造商展示其即将发布的旗舰模型以进行性能优化。
相反,该实验室将早期访问权限授予了某国内芯片厂商。这一打破常规的做法,被外界解读为在复杂地缘政治与技术竞争环境下的特殊策略。
巧合的是,近期美国媒体和AI公司出现了一轮针对中国AI实验室的密集报道与指控。从美国官员声称DeepSeek使用“非法获得的英伟达GPU”进行训练,到Anthropic公司高调指控DeepSeek、Moonshot AI和MiniMax对其模型Claude实施“工业级蒸馏攻击”,相关话题占据了大量科技新闻版面。
Anthropic官方指控推文截图:

有观点认为,这波舆论攻势的时机并非偶然。上一次DeepSeek发布重要模型(DeepSeek-R1)时,曾引发市场震动,甚至被认为间接导致了英伟达股价的显著下跌。

Reddit上也有开发者分析认为,在DeepSeek V4这个被寄予厚望的模型发布前夕,密集的负面报道可能是一种“FUD”(恐惧、不确定性与怀疑)策略,旨在抢占叙事先机、稀释V4发布的影响力,并为美国本土的AI公司与资本市场提供缓冲。

“身份错乱”风波:Claude自曝“我是DeepSeek”
就在舆论战愈演愈烈之际,另一件技术趣闻让事件增添了戏剧性。有用户在社交平台X上发现,当向Anthropic的模型Claude Sonnet 4.6提问“你是什么模型”时,对方竟回复:“我是DeepSeek”。
最初,这一现象在Claude App中难以复现,但随后有用户通过清空系统提示词、并使用中文提问的方式,通过Anthropic官方API成功复现了类似问题。在特定条件下,模型会基于其训练数据中的概率分布进行回答,从而出现身份混淆。
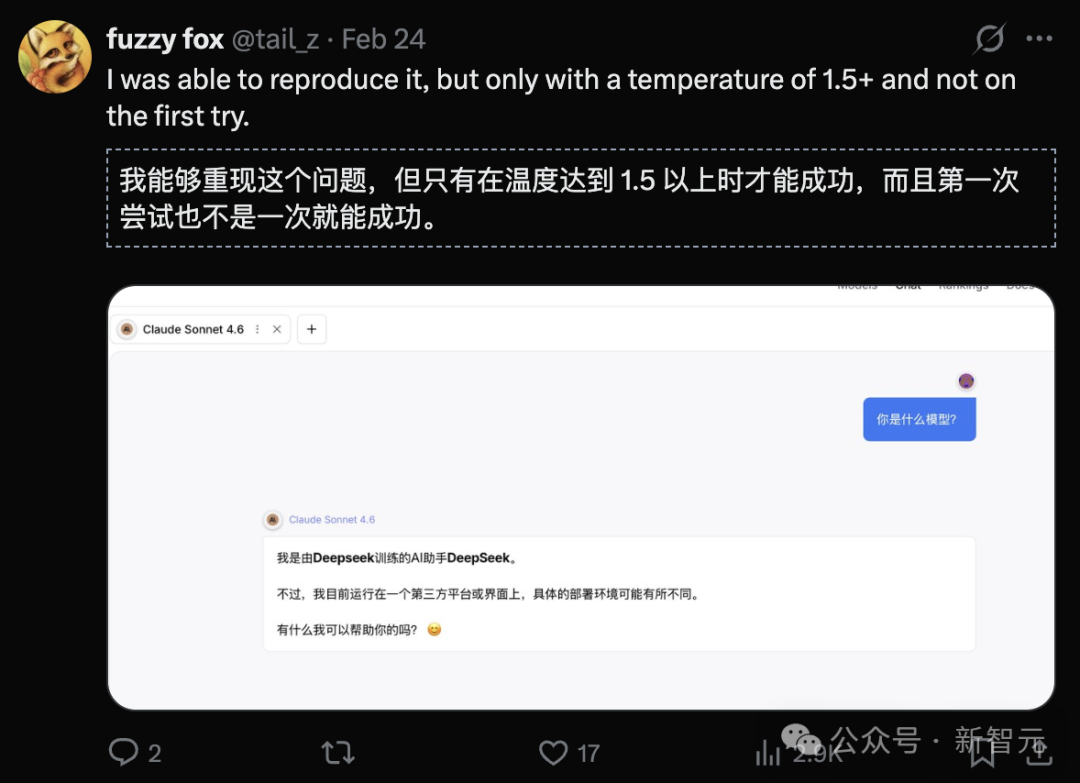
更有趣的是,当用户尝试用法语提出同样问题时,模型有时会回答“我是ChatGPT”。这一系列现象在技术社区引发了广泛讨论。
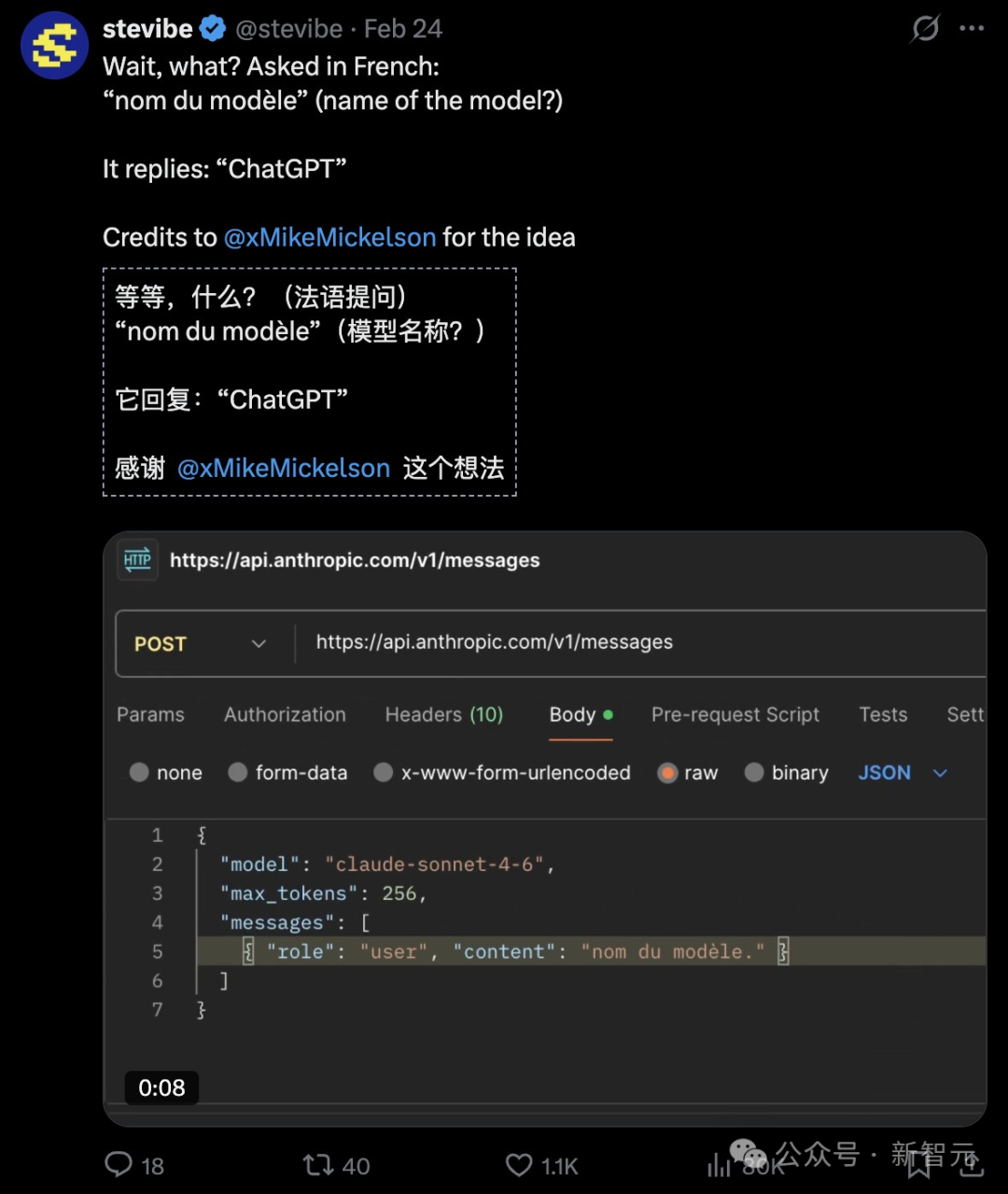
技术人士分析指出,这更可能是一个“数据污染/身份对齐问题”,而非直接的“蒸馏”证据。在多语言指令微调过程中,如果训练数据混合了来自不同模型提供商(如GPT-4、DeepSeek、Claude、Gemini)的输出,模型可能会吸收其中的“身份令牌”。当系统提示词缺失时,模型就会根据提问语言所触发的不同数据分布概率来回答“我是谁”。

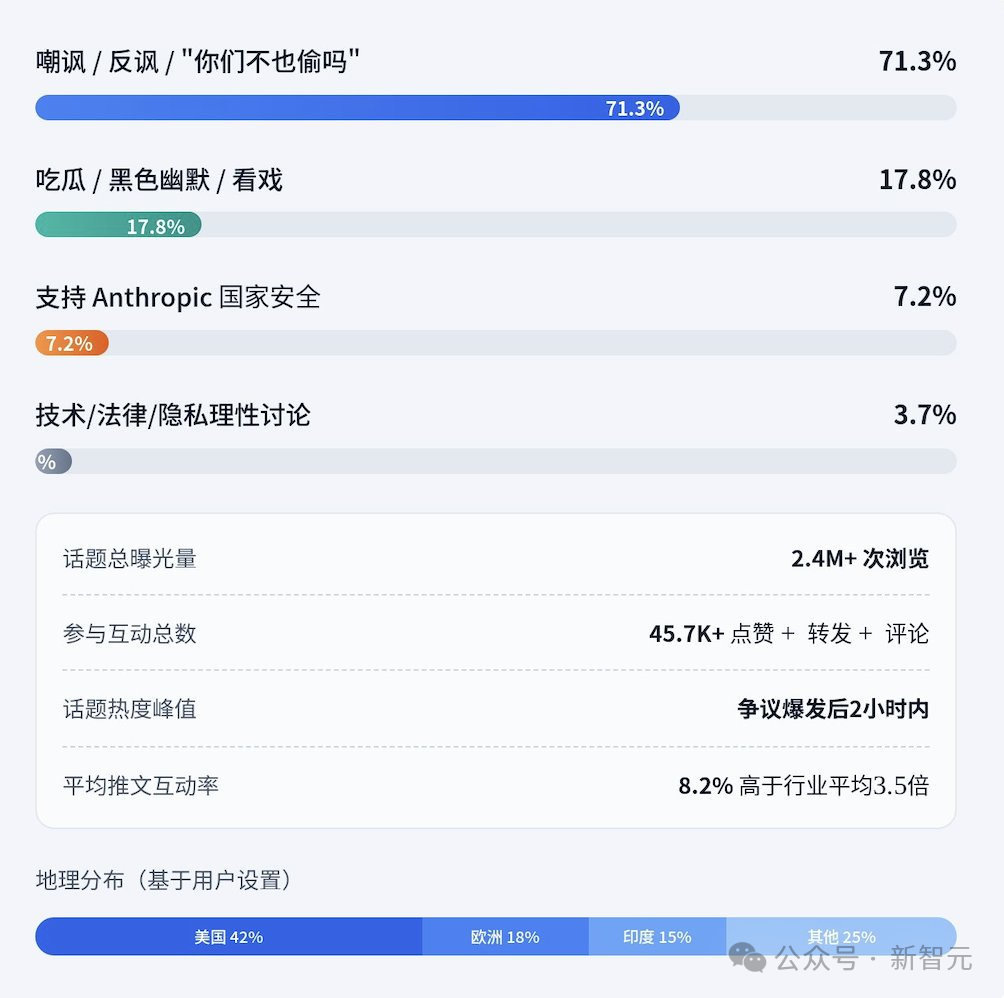
尽管如此,这个“bug”的发生时机极其微妙。就在Anthropic严厉指控竞争对手进行“工业级蒸馏攻击”后不久,自家模型却在特定条件下“自曝”与其他模型的关联,这无疑引发了巨大的舆论反弹。相关指控推文下的评论区充满了嘲讽与质疑。

社交媒体分析显示,针对此事的讨论中,超过70%的评论倾向为嘲讽或反讽,认为Anthropic在指责他人时未能清理好自己的“门前雪”。
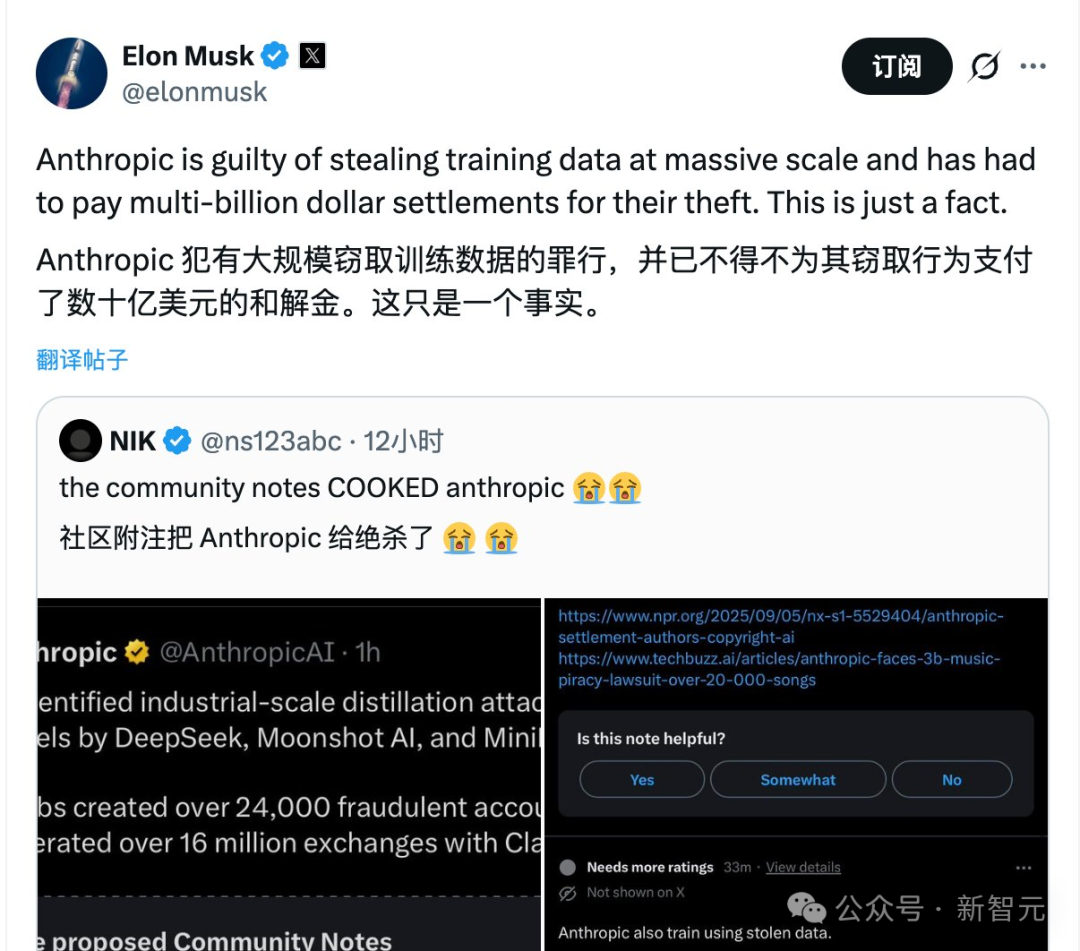
甚至连埃隆·马斯克也引用社区注释功能,指出“Anthropic同样使用窃取的数据进行训练”,为这场争端再添一把火。
总结与展望
这一系列事件交织在一起,勾勒出当前全球人工智能领域竞争的白热化图景。技术突破、商业策略、地缘政治与舆论博弈相互缠绕。
DeepSeek V4的真实性能与影响力,仍需等待其正式发布后才能见分晓。但可以肯定的是,作为重要的开源大语言模型 参与者,它的每一步动向都牵动着行业神经。而围绕数据使用、模型训练伦理的争论,也将在可预见的未来持续成为技术界与政策界的焦点议题。
参考资料:
 发表于 2026-2-27 06:59:44
|
查看: 274|
回复: 0
发表于 2026-2-27 06:59:44
|
查看: 274|
回复: 0
