
Anthropic 的工程师 Thariq 近日在 X 上正式宣布,Claude Code 已全面上线名为“Auto Memory”的新功能。
这意味着 Claude Code 最大的痛点之一——“失忆”问题,有望得到缓解。以往,每次开启新的会话,你都需要重新向它解释项目框架、测试流程和代码风格。项目越复杂,这种重复解释的成本就越高。
Auto Memory 的目标正是解决这个痛点。Claude 会在工作过程中,自动将有用的项目信息记录到一个本地文件——MEMORY.md中。该文件存储于 ~/.claude/projects/<项目名>/memory/ 目录下。每当启动新会话时,Claude 会自动加载此文件的前 200 行作为初始上下文。
整个过程无需任何手动配置,默认即为开启状态。
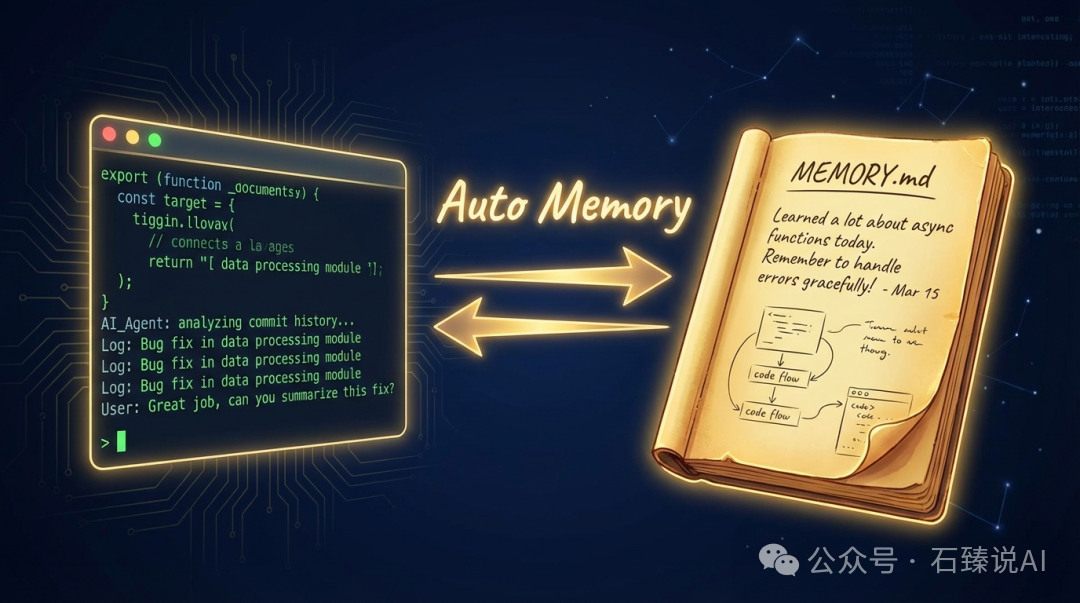
双层记忆体系:CLAUDE.md 与 MEMORY.md
这里有一个关键的设计区别,Thariq 在后续推文中专门作了解释:
CLAUDE.md 是你写给 Claude 的指令——它包含了项目规范、编码标准、工作流程等,相当于你给新同事准备的入职文档。这个文件需要你手动维护,并且可以提交到 Git 中与团队成员共享。MEMORY.md 是 Claude 自己的笔记本——它记录了 AI 在工作过程中自主发现的项目模式、踩过的坑以及你的个人偏好。这个文件由 Claude 自动读写,存储在本地,不纳入版本控制。
这种分离设计相当巧妙。指令和记忆本质不同:指令是确定性的规则(例如“我们使用 pnpm 而非 npm”),而记忆是经验性的积累(例如“上次 API 超时是因为连接池未正确释放”)。将两者分开管理,可以避免混乱。
记忆的层级结构
实际上,Claude Code 的记忆系统不止两层。根据官方文档,它拥有一套完整的层级结构:
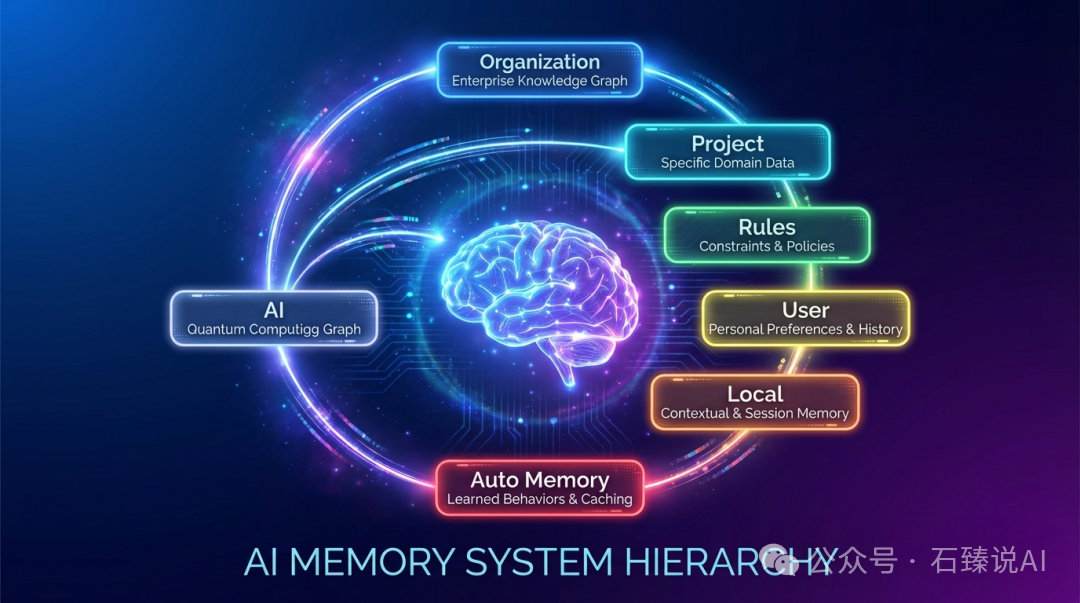
| 层级 |
位置 |
用途 |
共享范围 |
| 组织策略 |
/etc/claude-code/CLAUDE.md |
全公司编码规范、安全策略 |
组织内所有人 |
| 项目指令 |
./CLAUDE.md |
项目架构、编码标准 |
团队(Git) |
| 项目规则 |
.claude/rules/*.md |
按主题拆分的规则文件 |
团队(Git) |
| 用户指令 |
~/.claude/CLAUDE.md |
个人偏好(全局) |
仅自己 |
| 项目本地 |
./CLAUDE.local.md |
个人的项目特定配置 |
仅自己 |
| Auto Memory |
~/.claude/projects/*/memory/ |
Claude 自动记录的笔记 |
仅自己 |
从上到下,优先级依次提高。组织级别的规则是兜底,项目级别的规则可以覆盖组织级别,而个人级别的设置则拥有最高优先级。
这个设计对团队协作非常友好。团队共享的知识通过 Git 管理(CLAUDE.md 和 rules/),而个人的经验和偏好则留在本地(CLAUDE.local.md 和 Auto Memory),互不干扰。
技术细节:它究竟如何工作?
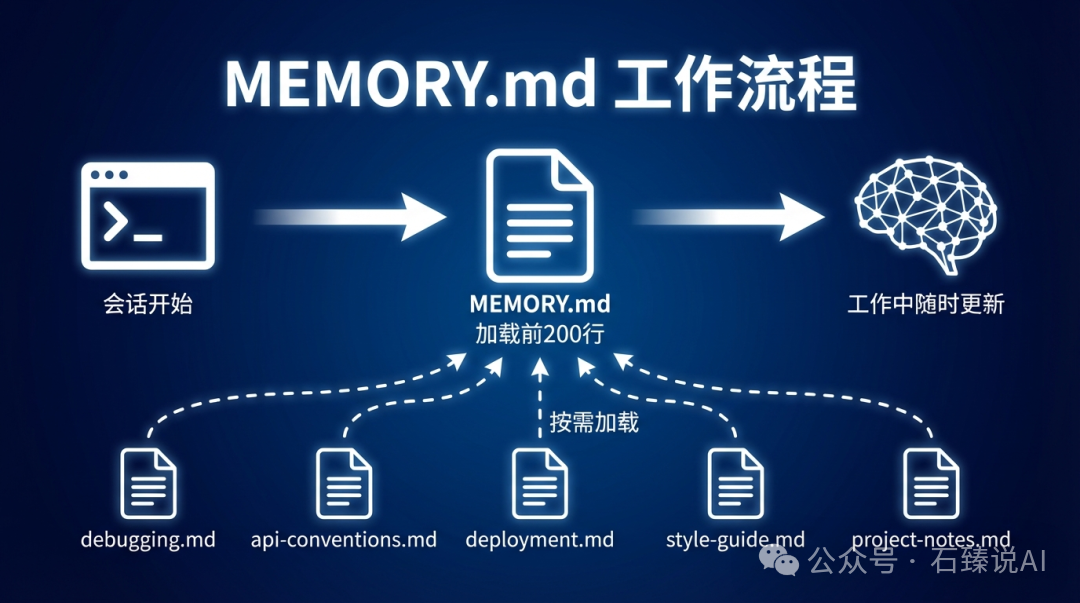
了解其工作机制的几个关键点:
存储结构:每个 Git 仓库对应一个独立的记忆目录。MEMORY.md 是入口文件,Claude 还会根据需求创建子文件(例如 debugging.md、api-conventions.md),此时 MEMORY.md 充当索引角色。
加载策略:只有 MEMORY.md 文件的前 200 行会在会话启动时自动加载到系统提示词中。子文件不会自动加载,只有当 Claude 认为需要时才会去读取。这是一个非常务实的设计——200 行足以容纳核心信息,而详细内容则按需加载,避免了浪费宝贵的上下文窗口。
读写时机:Claude 在会话过程中随时可能更新记忆文件。你可以在操作日志中看到它在工作间隙写入 MEMORY.md,这个过程是透明而非后台静默进行的。
开关控制:你可以使用 /memory 命令来临时切换该功能的开关。如果想全局关闭,可以在 settings.json 中设置 autoMemoryEnabled: false,或者使用环境变量 CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 进行强制覆盖。
社区反应:兴奋、质疑与深层思考
功能宣布后,开发者社区反响热烈,讨论大致分为三类。
第一类:终于等到了
许多开发者之前一直在手动维护类似的记忆系统。有人结合 CLAUDE.md 和日志文件来手动记录,甚至有人自己搭建了一套 JSON 文件系统来追踪项目上下文、失败模式和有效解决方案:
这充分说明,跨会话的持久化记忆确实是一个强烈的普遍需求。此前,社区中已经出现了像 Claude-Mem 这样的第三方插件,通过向量数据库实现持久化记忆,并在 GitHub 上获得了相当的关注。如今官方将此功能内置,无疑会挤压第三方方案的生存空间。
第二类:记忆管理才是真正的难题
几位开发者提出了同一个关键问题:Claude 知道何时该“忘记”吗?
这或许是构建智能代理记忆系统中最具挑战性的部分。如果三周前的项目上下文仍被记忆,并错误地应用于今天的代码,其后果可能比完全没有记忆更糟。有开发者询问是否存在“衰减机制”来自动清理过时信息。从目前来看,官方似乎没有提供自动过期功能——MEMORY.md 本质上是一个纯文本文件,由 Claude 自行决定何时更新或删除内容。
这意味着记忆的质量在很大程度上依赖于 Claude 自身的判断力。长期使用后,MEMORY.md 是否会变成一个臃肿的“信息垃圾场”?这个问题目前尚无定论。
第三类:企业级应用的担忧
有开发者指出了一个更深层次的治理问题:
Auto Memory 是基于用户级别的,记忆文件散落在每个开发者的本地机器上,无法通过 Git 追踪。对于个人开发者而言这没有问题,但对于企业来说,成千上万台开发者笔记本电脑上散布着自动更新的 .md 文件,这可能构成一个治理上的噩梦,造成知识孤岛并带来合规风险。
此外,还有关于 Git 追踪的疑问被提出:
CLAUDE.md 可以纳入 Git 实现团队共享,但 MEMORY.md 是个人的、非版本控制的。那么,团队成员之间的实践经验如何同步?如果 Claude 在开发者 A 的机器上学到了一个关键的调试技巧,开发者 B 将完全无从知晓。
坦率地说,这个问题短期内不易解决。Anthropic 当前的方案是将共享知识置于 CLAUDE.md(手动维护),将个人经验置于 MEMORY.md(自动积累),但两者之间缺乏有效的桥梁。
横向对比:在AI编程工具中处于什么位置?

- ChatGPT 很早便推出了 Memory 功能,但它侧重于对话级别——记住你喜欢的回答风格、你的职业背景等。
- Cursor 拥有
.cursorrules 文件,其他工具也有类似配置,但这些更接近 CLAUDE.md 的定位——是用户写给 AI 的指令,而非 AI 自主积累的经验。
Claude Code 的 Auto Memory 独特之处在于:它不是你命令 AI 去记住什么,而是由 AI 自己判断什么值得被记住。这种从“被动接收指令”到“主动积累经验”的转变,是 AI 编程工具进化过程中的一个重要信号。
实际使用建议

如果你已经开始使用 Claude Code,这里有一些实用建议:
- 先试用,再决定:不要急着关闭此功能。让它运行几天,观察
MEMORY.md 中记录了哪些内容。在大多数情况下,它所记录的信息是有实际价值的。
- 定期审查 MEMORY.md:你可以使用
/memory 命令直接打开并编辑该文件。定期删去过时的信息,补充它可能遗漏的重要上下文。不妨将其视为你和 Claude 共同维护的项目笔记。
- CLAUDE.md 与 MEMORY.md 明确分工:将确定性的规则写入
CLAUDE.md(例如“所有 API 必须包含错误处理”),而将经验性的知识交由 Claude 自动记录到 MEMORY.md(例如“上次 Redis 连接超时是因为未设置 maxRetries 参数”)。
- 注意 200 行限制:只有
MEMORY.md 的前 200 行会被自动加载,因此保持该文件的精简至关重要。详细的、分类的记忆内容,应让 Claude 拆分到相应的子文件中。
Auto Memory 并非一项革命性功能,它解决的是一个非常实际且朴素的问题:让 AI 编程助手不再每次都从零开始。
然而,其背后所代表的趋势值得每一位关注开发者广场动态的从业者注意。AI 工具正在从“无状态的问答机器”演变为“有记忆的协作伙伴”。当 AI 能够记住你的项目上下文、编码习惯以及曾踩过的坑时,它就不再仅仅是一个高级的代码补全工具,而是一个真正与你共同成长的工作搭档。
当然,记忆是一把双刃剑。记住的越多,出错的可能性也相应增大。如何平衡“记住有用的”和“忘掉过时的”,这不仅是 Claude 需要面对的挑战,也是所有 AI 编程工具都必须解答的命题。
参考链接
 发表于 2026-2-28 07:20:50
|
查看: 162|
回复: 0
发表于 2026-2-28 07:20:50
|
查看: 162|
回复: 0
