大语言模型所展现的上下文学习(In-Context Learning)能力令人印象深刻。通过提示词中的指令或示例,模型无需更新参数即可快速调整行为。然而,这种能力存在一个根本性的缺陷:知识是瞬态的。
设想这样一个场景:模型在解决一系列数学问题后,总结出了一套宝贵的解题经验。可一旦对话结束、上下文被清空,这些经验便随之丢失。下次面对类似问题时,模型又不得不“从零开始”,无法利用之前的“实战”经验。这就引出了一个核心问题:如何让模型“记住”这些宝贵经验,实现真正的“吃一堑,长一智”?
上下文蒸馏(Context Distillation) 正是为解决这一问题而生的技术方向。其目标是将上下文中的知识有效地压缩并固化到模型参数中,使得模型能永久“记住”这些知识,在推理时无需再依赖冗长的上下文。近期,微软研究院提出了OPCD(On-Policy Context Distillation),一种将上下文知识内化到语言模型参数中的新方法,为我们提供了新的思路。

二、核心方法:OPCD框架解析
2.1 核心思想:从自己的经验中学习
OPCD 的核心创新在于其学习策略:它让学生模型从自己生成的轨迹中学习,而非教师的轨迹。这是一种“On-Policy”(同策略)的方法,与传统的“Off-Policy”(异策略)上下文蒸馏形成对比。
在传统的蒸馏中,学生模型通常学习教师模型基于某些数据(可能与学生无关)产生的输出。而OPCD则让学生模型基于当前输入进行“推演”,生成自己的回答,然后再将其与拥有更丰富上下文知识的教师模型的判断进行对齐。这模拟了人类从自身实践中反思学习的过程。
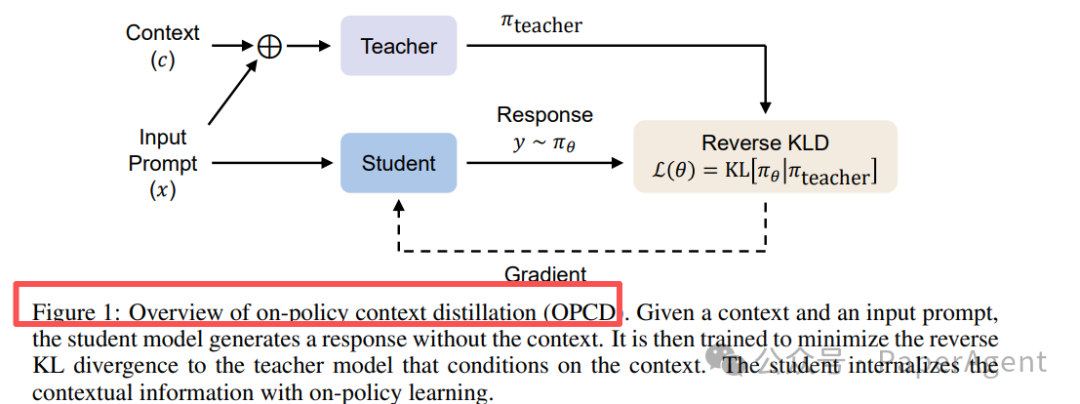
Figure 1: OPCD框架概览。给定上下文和输入提示,学生模型在不看上下文的情况下生成响应。随后,它被训练去最小化其与基于上下文的教师模型之间的反向KL散度,从而实现将上下文信息通过同策略学习内化。
2.2 技术细节:反向KL散度的应用
OPCD 的优化目标是最小化学生模型与教师模型之间的反向KL散度(Reverse KL Divergence)。这一选择至关重要,因为反向KL散度具有“mode-seeking”的特性,它会迫使学生模型的概率分布集中到教师模型的高概率区域,从而更稳定地学习到核心知识。
其损失函数定义如下,它将序列级别的散度分解为词元级别散度的和:

关键训练步骤可以概括为三点:
- On-Policy采样:学生模型
π_θ 在无上下文 c 的条件下,仅根据输入提示 x 生成完整响应 y。
- 教师评估:教师模型
π_teacher 在有上下文 c 的条件下,评估学生生成序列中每个后续词元 y_t 的概率分布。
- 反向KL对齐:计算并最小化每一步的词元级反向KL散度,使学生模型的输出概率向教师模型的高置信区域对齐。
以下是OPCD训练算法的伪代码,清晰地展示了这一流程:

2.3 教师模型配置:两种模式
OPCD支持两种灵活的教师模型配置,以适应不同场景:
| 配置 |
说明 |
适用场景 |
| Teacher-Student |
教师与学生是不同模型(教师通常更大或同规模但参数冻结) |
默认配置,训练信号更稳定,性能更优 |
| Self-Distillation |
教师与学生共享模型权重,在训练中同步更新 |
单模型自我提升与迭代,但训练可能不稳定 |
三、实验应用一:经验知识蒸馏
3.1 任务设定:让模型固化自己的解题经验
这是论文提出的一个核心且有趣的应用场景,模拟了模型“总结经验、持续成长”的过程。整个过程分为三个阶段,且完全自监督,无需任何人工标注:
- 经验提取:模型解决一个问题后,从自己的完整解题轨迹(思考、步骤、答案)中,提炼出可迁移、泛化的经验知识(例如“遇到此类问题可先分解条件”)。
- 经验积累:将多个独立问题的经验知识拼接起来,形成一个丰富的“经验上下文”,作为解决新问题的参考。
- 经验固化:使用OPCD方法,将这些存在于上下文空间中的经验知识,蒸馏并永久内化到模型自身的参数中。
3.2 实验数据集
研究团队在多个需要复杂推理的任务上进行了验证:
- DAPO-Math-17K:包含约1.4万道答案可验证的英文数学题。
- Frozen Lake:一个3×3网格的导航文本游戏,需要规划路径避开陷阱到达目标。
- Sokoban:经典的6×6“推箱子”文本游戏,需要复杂的空间关系推理。
3.3 实验结果
实验结果表明,无论是在测试时即时固化经验,还是对经验进行筛选后再固化,OPCD方法均取得了显著提升。
Test-Time 经验知识固化(无筛选)
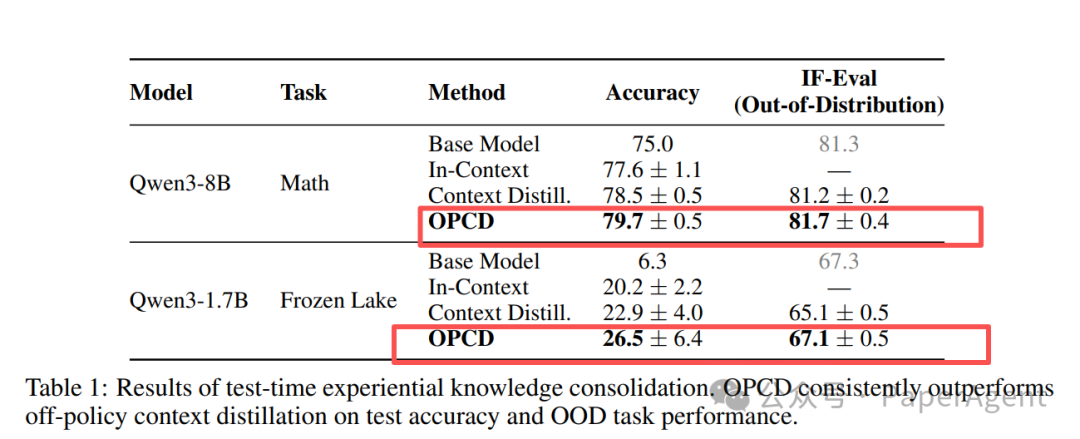
Table 1: 在测试时进行经验知识固化的结果。OPCD在测试准确率和分布外(OOD)任务性能上均持续优于离策略上下文蒸馏方法。
筛选后的经验知识固化
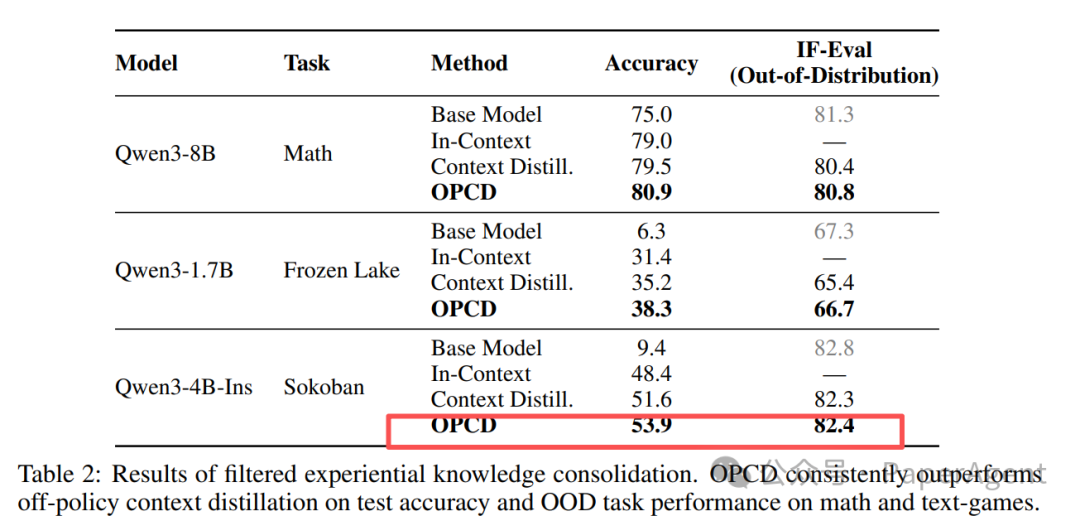
Table 2: 对经验知识进行筛选后再固化的结果。OPCD在数学和文本游戏任务上的测试准确率与OOD性能均优于基线方法。
四、实验应用二:系统提示词蒸馏
系统提示词(System Prompt)常用于引导模型在特定领域(如医疗问答、安全审核)的行为模式。然而,冗长的提示词会增加每次推理的计算与存储开销。OPCD可以有效地将这些行为模式“蒸馏”进模型,实现“去提示词化”的高效推理。
4.1 实验结果
医疗系统提示词蒸馏(基于MedMCQA数据集):
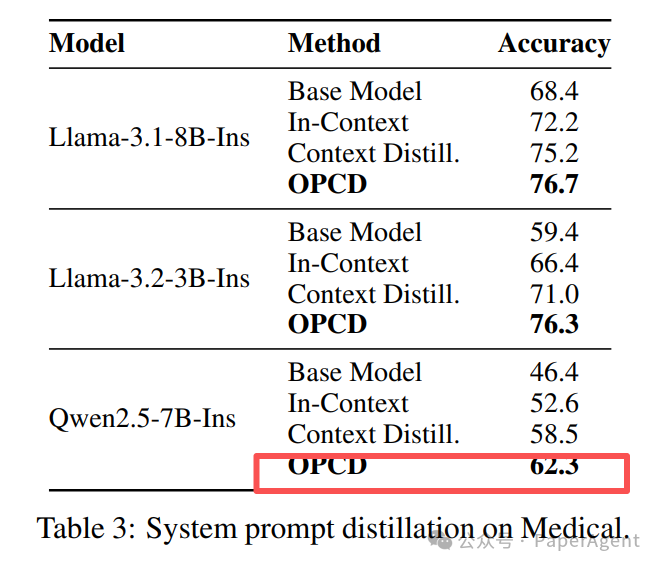
Table 3: 在医疗任务上进行系统提示词蒸馏的结果。OPCD方法显著提升了模型在遵循医疗系统提示后的性能。
安全系统提示词蒸馏:
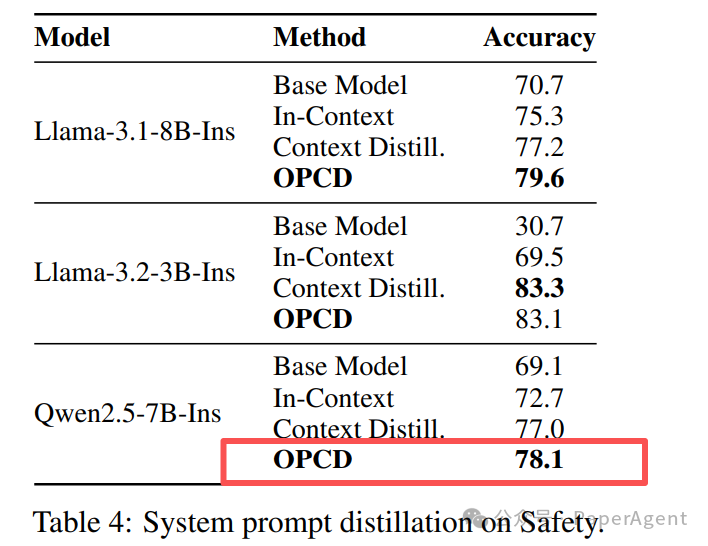
Table 4: 在安全任务上进行系统提示词蒸馏的结果。OPCD同样表现出色,尤其是在较小模型上提升显著。
五、深度分析与洞察
5.1 跨尺寸蒸馏:小模型如何安全吸收大模型经验?
一个反直觉的发现是:直接将大模型(如Qwen3-8B)产出的经验知识作为上下文塞给小模型(如Qwen3-1.7B),反而会损害小模型的性能。
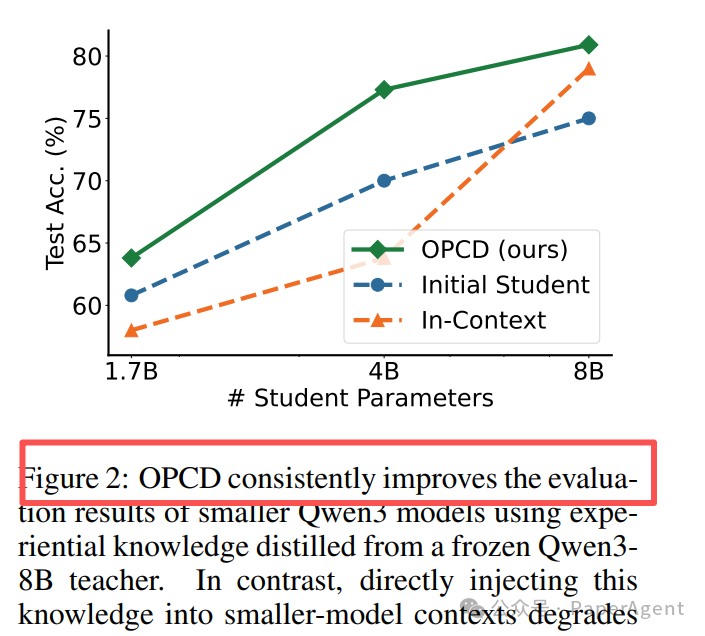
Figure 2: OPCD能持续提升较小规模Qwen3模型的评估结果(使用从冻结的Qwen3-8B教师模型蒸馏的经验知识)。相比之下,直接将此知识注入小模型的上下文(橙色虚线)会导致性能下降。
如上图橙色虚线所示,这种直接的“知识灌输”效果甚至不如基线。这深刻说明,知识必须与消费它的模型能力进行“On-Policy”对齐。OPCD通过让小模型基于自身能力生成响应,再与教师知识对齐,完美解决了这一对齐问题,使小模型能安全、高效地吸收大模型的经验。
5.2 缓解灾难性遗忘
在深度学习的Fine-tuning中,灾难性遗忘是一个常见难题。OPCD在提升模型在目标领域(如安全)性能的同时,表现出了更好的分布外(OOD)泛化能力保持性。
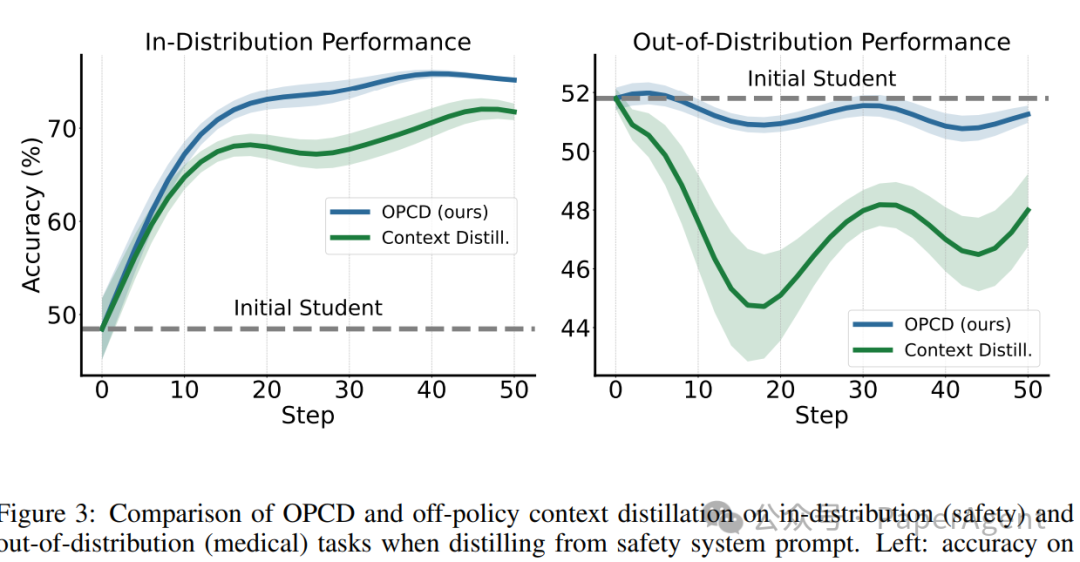
Figure 3: OPCD与离策略上下文蒸馏在领域内(安全)和分布外(医疗)任务上的对比。左图:安全任务准确率;右图:医疗任务准确率。OPCD在实现更优领域内性能的同时,缓解了对OOD任务的遗忘。
分析上图可知:
- 左图(领域内):OPCD和离策略蒸馏都提升了安全任务性能。
- 右图(OOD):离策略蒸馏导致医疗任务性能大幅下降(出现了遗忘),而OPCD则基本保持了模型的初始能力水平。
5.3 教师-学生架构 vs 自我蒸馏
哪种配置更优?实验给出了明确答案。
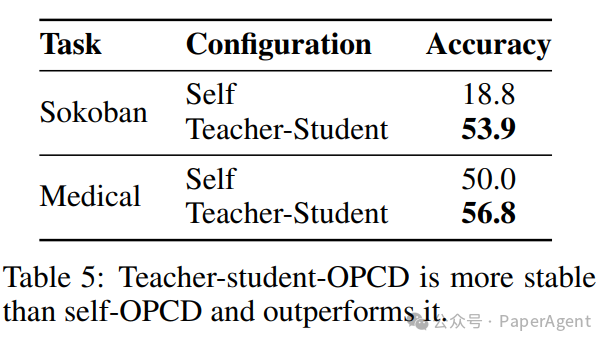
Table 5: 教师-学生架构的OPCD比自我蒸馏的OPCD更稳定且性能更优。
自我蒸馏(教师与学生权重共享、同步更新)虽然概念简洁,但训练过程不稳定,容易发散。这是因为持续变化的教师模型为学生提供了高方差、不一致的学习信号。而固定的教师-学生架构则能提供稳定、可靠的监督信号。
5.4 经验知识 vs 原始轨迹:提炼的价值
并非所有“经验”都同样有效。研究对比了使用提炼后的结构化经验知识与直接使用原始响应轨迹作为上下文的效果。
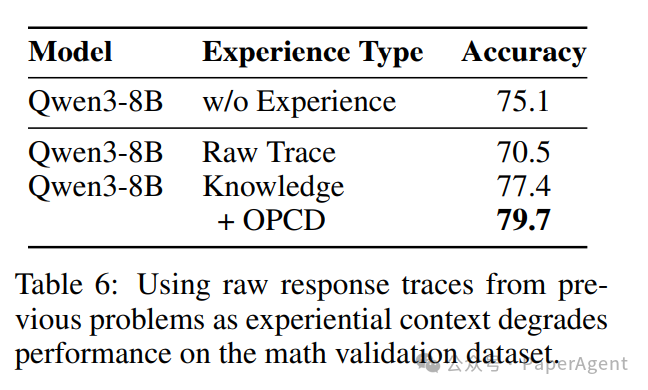
Table 6: 使用原始响应轨迹作为经验上下文会降低在数学验证集上的性能。
关键结论:提取结构化的经验知识(Knowledge)比直接使用原始轨迹(Raw Trace)效果更好。原始轨迹包含了过多的解题细节和可能的错误噪音,而经过提炼的经验知识更具概括性和迁移性,这才是模型需要内化的核心“智慧”。
总结
OPCD 为大语言模型提供了一种新颖且高效的持续学习范式。它让模型能够像人类专家一样,从自身的“实战经验”中反思、提炼规律,并将这些智慧永久内化到自身的“神经网络”中,而不是每次遇到问题都“从零开始”。这项研究为降低模型对长上下文的依赖、实现模型能力的持续进化以及高效的知识迁移打开了新的大门。
一句话总结:OPCD让大模型真正实现了“吃一堑,长一智”。
https://arxiv.org/pdf/2602.12275
On-Policy Context Distillation for Language Models
对LLM持续学习、上下文蒸馏等前沿技术感兴趣的朋友,欢迎在云栈社区进行更深入的交流与探讨。
 发表于 2026-3-2 04:22:27
|
查看: 254|
回复: 0
发表于 2026-3-2 04:22:27
|
查看: 254|
回复: 0
