无栈协程确实比有栈协程快,但它快的不是省内存,也不是少存了几个寄存器。
用一句话概括就是:无栈协程把挂起和恢复做成了编译器能看懂的状态机,走的是普通调用路径。有栈协程更多时候在做用户态上下文切换,走的是一段必须保守的切换路径。

无栈和有栈不是同一类工具。
有栈协程能在任意深度的调用栈里让出执行权,无栈协程做不到。你想在深层函数里 co_await,往往就得把整条调用链都协程化,这就是大家吐槽的 async 着色(async coloring)。这种能力差异决定了它们的成本结构本来就不一样。
一、性能差异从哪里来
有栈协程的切换更像用户态上下文切换。
在老派的有栈协程,比如 Boost.Context 或者一些开源的 fiber 库。它们通常会为每个协程预先分配一个独立的、完整的栈空间,比如 1MB。
当一个有栈协程需要挂起,把执行权交给另一个协程时,它执行的是一次上下文切换。这个过程通常不进内核,所以比线程切换轻,但依然是一套偏保守的底层操作。实现里基本绕不开汇编,因为它要直接操作栈指针和返回地址。
直观理解就是保存一部分寄存器和返回位置,保存栈指针,切到另一块栈,再把目标协程的上下文恢复回来。实现细节因库和 ABI 而异,但思路基本都是保守的。
可以用一段伪代码来感受一下这个黑盒式的切换。假设有一个切换上下文的底层函数。
struct StackfulCoroutine {
void* stack_pointer = nullptr;
};
StackfulCoroutine* g_current_coro = nullptr;
StackfulCoroutine* g_target_coro = nullptr;
extern "C" void swap_context(StackfulCoroutine* from, StackfulCoroutine* to);
void yield() {
StackfulCoroutine* self = g_current_coro;
g_current_coro = g_target_coro;
swap_context(self, g_current_coro);
}
对编译器来说,swap_context 这种函数几乎等价于黑盒。它不知道里面改了哪些寄存器,也不知道控制流会怎么回来,更做不到跨越切换点做指令级优化。这会让切换成本更接近固定成本,而且通常不低。
C++20 无栈协程的挂起恢复更像普通调用,它完全是另一条技术路线。它没有独立的栈,它的核心来自编译器在编译阶段的代码改写。
当你写下一个协程函数,编译器会把它改写成状态机。协程函数不再是原来的那个直线函数,它会变成一个隐藏的对象,加上一段 resume 入口。
这个隐藏对象通常被叫做协程帧。它经常在堆上分配,但不是语言保证,取决于返回对象设计、编译器优化和是否逃逸。协程帧里会保存跨挂起点仍然活着的状态,以及用来标记暂停位置的信息。
当协程执行到 co_await 时,发生的事情更像一次返回,把控制权交还给调用者或调度器。
- 保存跨挂起点仍然活着的状态。这不等于保存寄存器快照,而是编译器把活跃变量溢出到协程帧里,也就是把本来在栈上或寄存器里的东西搬到协程帧里。
- 返回。协程让出执行权,后面什么时候恢复由外部决定。
而恢复一个无栈协程,本质上就是一次对协程帧的调用。实现上可能是 switch,也可能是跳转表或计算跳转,但本质都是按状态号跳到对应的片段继续执行。
让我们用代码模拟一下编译器到底干了什么。这里我只用示意代码表达控制流,不追求可直接编译。
#include <coroutine>
#include <iostream>
DemoTask my_coroutine_function() {
std::cout << "Coroutine started\n";
int a = 1;
co_await std::suspend_always{};
std::cout << "Coroutine resumed, a = " << a << "\n";
a = 2;
co_await std::suspend_always{};
std::cout << "Coroutine resumed again, a = " << a << "\n";
}
编译器看到这段代码,会生成一个类似下面这样的状态机类。这只是概念性的模拟,真实实现更复杂。
// 编译器生成的协程帧状态机伪代码模拟
struct __my_coroutine_function_frame {
int suspension_point;
int a;
void resume() {
switch (suspension_point) {
case 0:
goto suspend_point_0;
case 1:
goto suspend_point_1;
case 2:
goto suspend_point_2;
}
suspend_point_0:
std::cout << "Coroutine started\n";
this->a = 1;
this->suspension_point = 1;
return;
suspend_point_1:
std::cout << "Coroutine resumed, a = " << this->a << "\n";
this->a = 2;
this->suspension_point = 2;
return;
suspend_point_2:
std::cout << "Coroutine resumed again, a = " << this->a << "\n";
this->suspension_point = -1; // 标记结束
return;
}
};
看到了吧,co_await 在控制流上变成了一次返回,恢复则变成一次调用。这里最大的区别不是你有没有保存某个寄存器,而是这条路径编译器是否完全理解,是否能内联,是否能做寄存器分配和消除无用状态。
结论可以这么说:有栈协程更像一条保守的切换路径,无栈协程更像一条可被优化到接近普通函数调用的路径。但最终快不快,还要看 awaitable 和调度器到底做了多少事。
二、除了省内存,真正的性能红利
1. 缓存和工作集
无栈协程把跨挂起点的状态压进协程帧,协程帧通常更小、更集中,高并发 IO 下更容易吃到缓存命中。有栈协程带独立栈,切换时更容易把工作集打散,这在大并发下会拖尾延迟。
2. 编译器优化空间
无栈协程的控制流对编译器透明,很多优化有机会发生,比如把一部分 await 路径内联进去,比如在特定条件下消掉协程帧分配,比如更激进的寄存器分配。有栈协程的切换点更像黑盒,这类优化更难跨过去。
3. 工程边界
无栈协程不是万能,它换来的代价是你往往要把整条调用链协程化。有栈协程在接同步库、深层调用链让出执行权这些场景更省心。
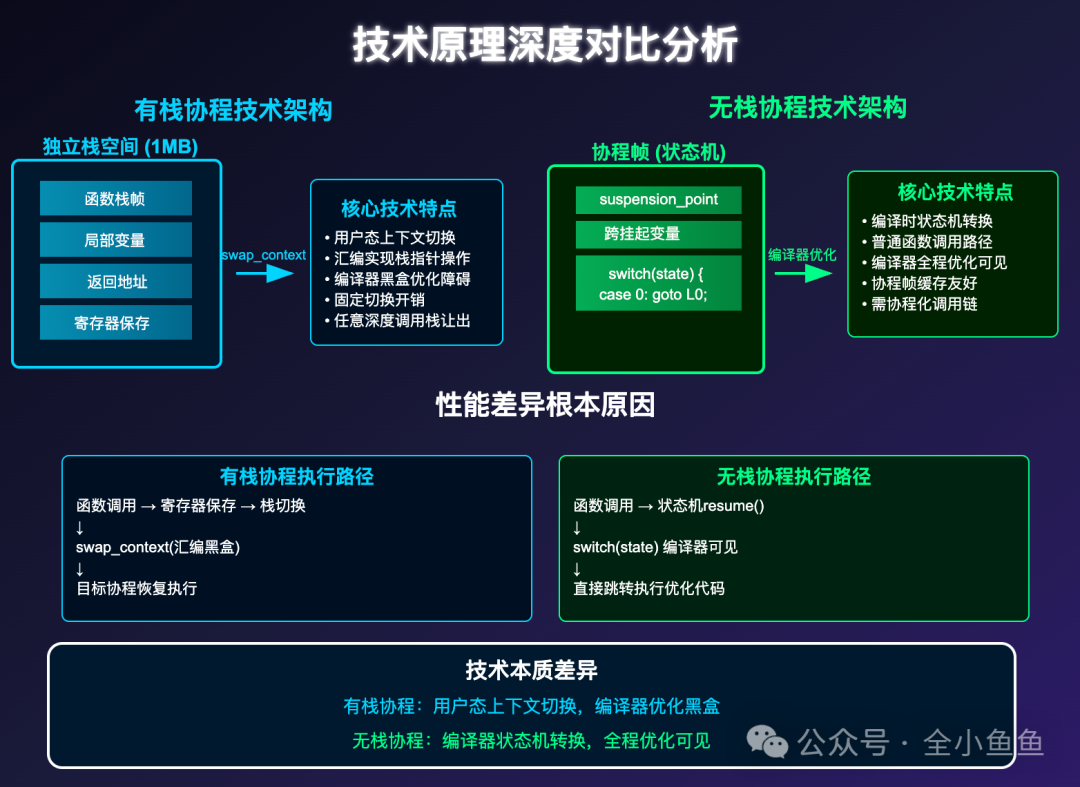
总结一下:C++20 无栈协程比有栈协程快,关键不是省了寄存器,而是它的挂起恢复是编译器能看透的状态机,执行路径接近普通函数,优化空间被完全打开。再加上协程帧把状态收得又小又集中,高并发 IO 下吞吐和延迟表现都更好。
所以,除了常说的省内存,它最大的性能优势在于编译器能优化、控制流组合也灵活。当然,代价也很实在:想在深层调用栈里让出执行权,有栈协程直接就能做到;而无栈协程得把整条调用链都改成协程,工程上会麻烦不少。希望这篇分析能帮助你更本质地理解C++协程的性能差异。想深入探讨更多底层技术细节,欢迎来 云栈社区 交流。
 发表于 2026-3-2 08:09:02
|
查看: 228|
回复: 0
发表于 2026-3-2 08:09:02
|
查看: 228|
回复: 0
