如果你正在开发或使用 AI Agent,很可能遇到过这样的困境:模型本身能力不弱,提示词也经过了精心设计,但一旦投入实际业务,Agent 的表现就变得不尽如人意。
它可能“记不住”用户之前说过的话;或者,当你询问细节时,它给出的答案就像没读过相关资料一样不着边际;又或者,任务的 Token 消耗飞速上涨,成本难以控制,效果却依然平平。
问题往往不在模型本身,而在于哪里呢?答案是上下文管理没做好。
过去一年,我们的团队在字节跳动火山引擎专注于上下文工程、知识库和记忆库的开发,踩遍了各种“坑”。最终,我们决定自己动手,为 AI Agent 打造一个专用的“上下文数据库”—— OpenViking,并于今年初正式开源。
这篇文章,就和你聊聊我们打造 OpenViking 的初衷、它旨在解决的核心痛点,以及它与其他方案的本质区别。

🤯 开发AI Agent时,我们都踩过哪些“坑”?
实话实说,当前做 AI Agent,数据本身并不稀缺。真正稀缺的是高质量、结构合理、且能随时调用的上下文。
我们总结了开发过程中最常见的五个“坑”:
上下文碎片化
记忆散落在代码、数据库和向量库中;技能说明写在 README、Wiki,甚至注释里。当需要使用时,开发者不得不编写大量“胶水代码”来拼凑信息,维护成本极高。
上下文暴涨,成本失控
长任务每执行一步都会产生新的信息。如果简单地采取截断或粗暴压缩,要么丢失关键信息,要么让模型在大量的噪音信息中“迷路”。
传统 RAG 检索效果不佳
平铺式的向量检索只关注“语义相似度”,而无法理解“目录结构”和“业务归属”。结果往往是搜出一堆信息碎片,却拼不出一个完整、准确的答案。
检索过程是个黑箱
线上任务一旦出错,你根本无从得知 Agent 调用了哪些文档、又为何选择了某段上下文。调试只能靠猜测,排查错误的成本极高。
记忆仅限于“用户记忆”
大多数方案只记录用户的偏好和习惯,却忽略了 Agent 自身积累的“经验”:例如某个工具如何使用更稳定、哪种任务拆解方式更高效。这直接导致 Agent 很难实现“越用越聪明”的进化。
这些问题叠加在一起,导致许多 AI Agent 项目要么停留在 Demo 阶段,要么上线后因成本爆炸和体验不佳而难以维系。
💡 我们的解决方案:一个专为Agent设计的“上下文数据库”
我们开发的 OpenViking,定位非常明确:一个专为 AI Agent 设计的上下文数据库(Context Database)。
它不仅仅是一个向量库,更是一套极简的上下文交互范式。其核心思想可以概括为一句话:
像管理本地文件一样,管理 Agent 的大脑。
具体来说,OpenViking 主要做了以下几件事:
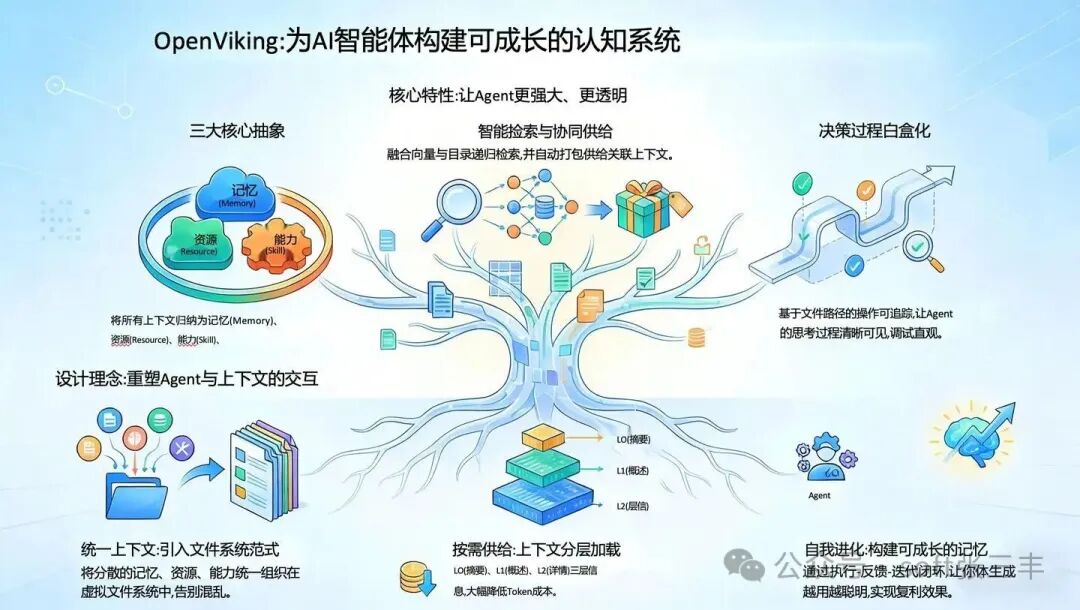
文件系统管理范式
它将所有上下文——包括记忆(Memory)、资源(Resource)、技能(Skill)——统一抽象成一个虚拟文件系统,并通过 viking:// 协议进行访问。这种设计让复杂的 人工智能 上下文管理变得直观。
viking:///
├── resources/ # 文档、代码、网页等资源
├── user/ # 用户偏好、习惯等长期记忆
└── agent/ # 技能、指令、任务记忆等
这样一来,Agent 可以使用像 ls、find 这样熟悉的指令来定位信息,而不再仅仅依赖模糊的语义匹配。
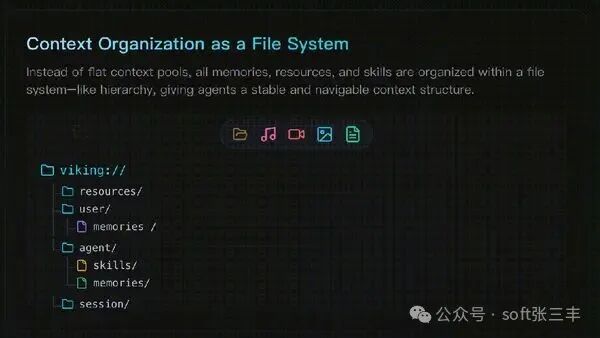
分层上下文按需加载(L0/L1/L2)
在内容写入时,系统会自动将其处理成三个层次:
- L0 (摘要):用一句话概括内容,用于快速判断相关性。
- L1 (概述):包含核心信息和使用场景,供 Agent 进行规划和决策。
- L2 (详情):完整的原始数据,仅在需要时加载。
这就像人类查阅资料:先看目录和摘要,确定相关后再阅读全文,从而大幅节省 Token 消耗。

目录递归检索
它结合了“语义搜索”与“目录结构”检索。先通过向量检索定位到最相关的目录,再在该目录内进行递归检索,最后汇总结果。这种方法能显著提升检索的准确性和语境完整性。
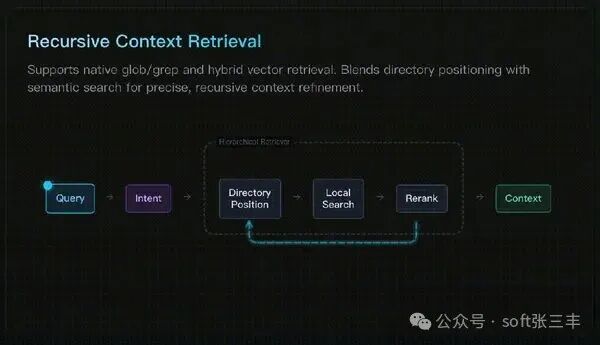
可视化检索轨迹
每次检索的路径都会被完整记录下来。开发者可以清晰地看到 Agent “查看了哪些目录、读取了哪些文件”,让黑盒过程变得白盒化,极大提升了排错效率。
会话自动管理与记忆自迭代
会话结束时,系统会自动压缩对话内容、工具调用记录等信息,提取出有价值的长期记忆,并更新到 user/ 和 agent/ 目录下,从而实现 Agent 的持续学习和进化。

🆚 OpenViking 与其他方案有何不同?
OpenViking 并非要取代现有方案,而是旨在解决一个更底层的问题:Agent 的上下文应该如何组织、如何供给、以及如何迭代更新。
OpenViking vs 传统向量数据库 / 简单 RAG
传统 RAG 擅长处理“问答”场景,但 AI Agent 需要的是对“记忆、资源、技能”的统一管理。OpenViking 在 RAG 的基础上,增加了分层加载、目录结构和可观测性,更适合复杂的、需要长期状态维护的 Agent 场景。
OpenViking vs 知识库产品
常见的知识库产品更偏向于提供“对外的问答服务”,而 OpenViking 定位为“对内的上下文底座”。它将技能、记忆等内部元素都纳入了统一的管理范式,是 Agent 运行时的核心基础设施。
OpenViking vs Agent 框架
像 LangChain 这类 Agent 框架主要解决“怎么做事”(例如规划、工具调用),而 OpenViking 则专注于解决“做事时需要的上下文从哪里来、怎么找到、以及如何高效地喂给模型”。两者是互补关系,可以协同工作。
🚀 快速上手:三分钟运行 OpenViking
OpenViking 的一大核心优势在于其极简的集成方式。我们深知开发者的时间宝贵,不应浪费在繁琐的配置上。你无需部署复杂的服务或学习新的 DSL,只需几行 Python 代码,就能为你的 Agent 赋予强大的“上下文大脑”。
以下示例将 OpenViking 项目的 README 文件作为资源写入,展示处理后的上下文目录结构、分层信息,并进行简单问答。
第一步:安装 OpenViking
pip install openviking
第二步:获取模型服务
OpenViking 需要视觉语言模型(用于多模态内容理解)和 Embedding 模型(用于向量化)的 API 访问能力。
我们支持多种模型服务:
- OpenAI 模型:支持 GPT-4V 等 VLM 模型和 OpenAI Embedding 模型。
- 火山引擎豆包模型:推荐使用,成本低、性能好,新用户有免费额度。
- 其他自定义模型服务:支持任何兼容 OpenAI API 格式的模型服务。
第三步:配置环境
创建配置文件 ov.conf:
⚠️ 重要提示:请将下方配置中的 <your-api-key> 等占位符替换为你在第二步获取的真实信息!
{
"vlm": {
"api_key": "<your-api-key>", // 模型服务的 API 密钥
"model": "<model-name>", // VLM 模型名称(如 doubao-seed-1-8-251228 或 gpt-4-vision-preview)
"api_base": "<api-endpoint>", // API 服务端点地址(如火山引擎 API:https://ark.cn-beijing.volces.com/api/v3)
"backend": "<backend-type>" // 后端类型(volcengine 或 openai)
},
"embedding": {
"dense": {
"backend": "<backend-type>", // 后端类型(volcengine 或 openai)
"api_key": "<your-api-key>", // 模型服务的 API 密钥
"model": "<model-name>", // Embedding 模型名称(如 doubao-embedding-vision-250615 或 text-embedding-3-large)
"api_base": "<api-endpoint>", // API 服务端点地址
"dimension": 1024 // 向量维度
}
}
}
设置环境变量指向该配置文件:
export OPENVIKING_CONFIG_FILE=ov.conf
第四步:运行体验
创建一个简单的 Python 脚本 example.py 并运行,通过写入 OpenViking 的 README 文档来体验完整的写入-检索-读取流程:
import openviking as ov
# Initialize OpenViking client with data directory
client = ov.SyncOpenViking(path="./data")
try:
# Initialize the client
client.initialize()
# Add resource (supports URL, file, or directory)
add_result = client.add_resource(
path="https://raw.githubusercontent.com/volcengine/OpenViking/refs/heads/main/README.md"
)
root_uri = add_result['root_uri']
# Explore the resource tree structure
ls_result = client.ls(root_uri)
print(f"Directory structure:\n{ls_result}\n")
# Use glob to find markdown files
glob_result = client.glob(pattern="**/*.md", uri=root_uri)
if glob_result['matches']:
content = client.read(glob_result['matches'][0])
print(f"Content preview: {content[:200]}...\n")
# Wait for semantic processing to complete
print("Wait for semantic processing...")
client.wait_processed()
# Get abstract and overview of the resource
abstract = client.abstract(root_uri)
overview = client.overview(root_uri)
print(f"Abstract:\n{abstract}\n\nOverview:\n{overview}\n")
# Perform semantic search
results = client.find("what is openviking", target_uri=root_uri) # Input query
print("Search results:")
for r in results.resources:
print(f" {r.uri} (score: {r.score:.4f})")
# Close the client
client.close()
except Exception as e:
print(f"Error: {e}")
运行脚本:
python example.py
若脚本成功运行并输出了目录结构、内容摘要和检索结果,恭喜!你已经成功运行了 OpenViking。
写在最后
如果你也在开发 AI Agent,并且正被以下问题所困扰:
- 上下文信息散落各处,维护成本高昂;
- 长任务导致 Token 消耗失控;
- 传统的 向量检索 效果不稳定,调试如同猜谜;
- 希望你的 Agent 能够“越用越聪明”,持续进化。
那么,不妨试试 OpenViking。它现已完全开源,其背后是字节跳动火山引擎 Viking 团队多年的工程实践与经验沉淀。我们正在持续迭代,也欢迎你来 GitHub 仓库和相关的技术社区(如 云栈社区)一起交流,分享你对 AI Agent 上下文管理的见解与想法。
 发表于 2026-3-3 08:44:38
|
查看: 188|
回复: 0
发表于 2026-3-3 08:44:38
|
查看: 188|
回复: 0
