大家过去总觉得,AI 负责写东西、写代码,安全团队负责拦风险。这条线现在开始混在一起了。
很多人聊 AI Agent,还停留在“能不能帮我点点按钮、写写脚本”这个层面。
但企业环境里,真正麻烦的事从来不是按钮不够快,而是系统太多、规则太碎、风险太高。你可以让 agent 去做事,可一旦它碰到浏览器策略、数据外发、插件权限、设备状态这些问题,事情就不再是“自动化”三个字那么轻松了。
这也是为什么我觉得,浏览器安全和 AI agent 走到一起,是一个很值得注意的信号。
因为它说明一件事:企业并不满足于让 AI 当个聊天窗口,他们开始想让 AI 真正进入管理面,碰生产环境里的真实规则。
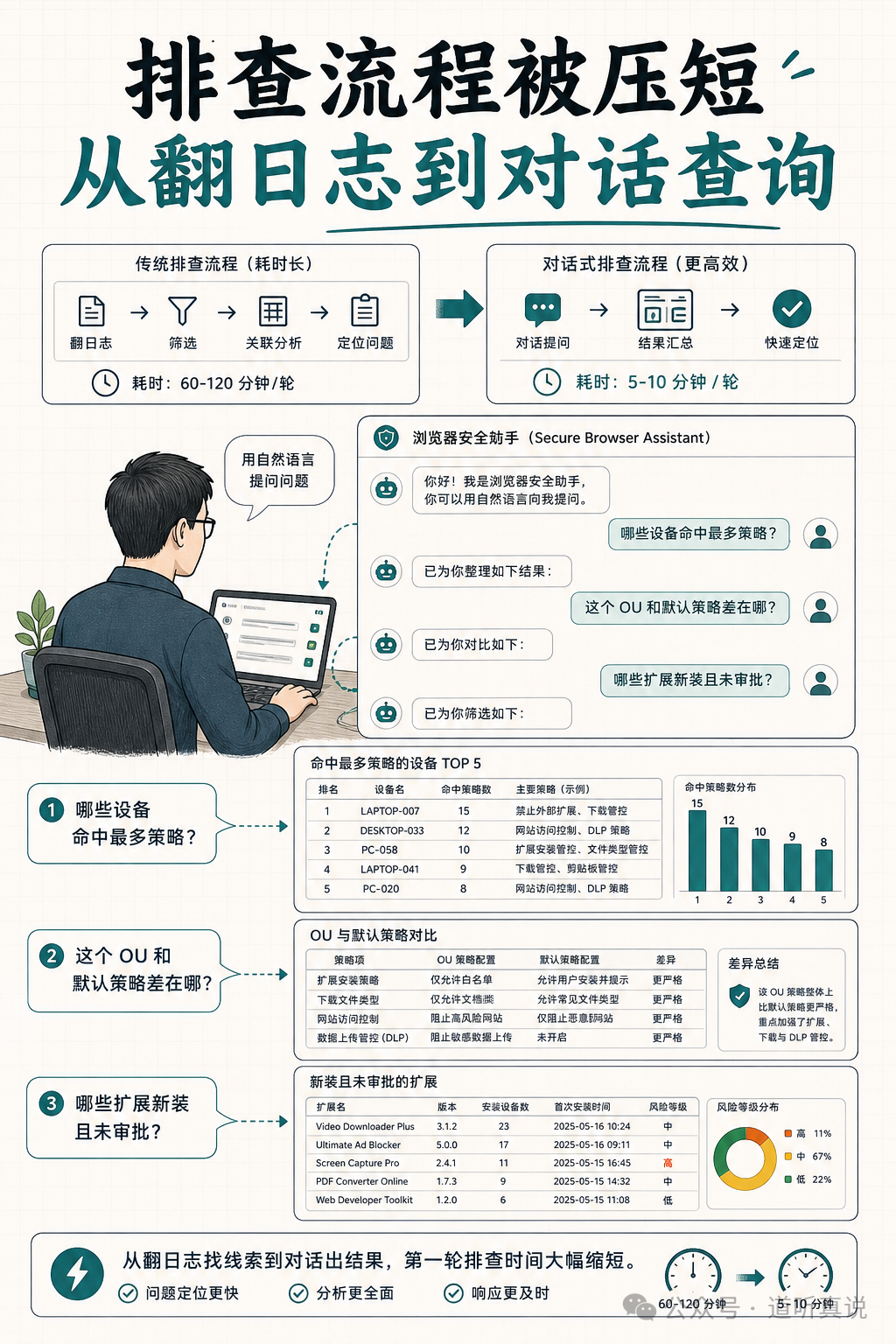
以前卡住 IT 团队的,不是不会配,而是来不及看
企业浏览器这件事,外行看着挺普通,内行其实都知道水很深。
一个浏览器背后,连着访问控制、插件审计、文件下载、内部站点、身份登录、DLP 策略、终端状态。员工每天开着它办公,安全团队每天盯着它担心。
问题在于,数据太多了。
谁装了不该装的扩展?谁在把敏感内容复制到不该去的地方?哪些策略根本没生效?哪些设备已经偏离了基线?这些信息不是没有,而是散在控制台、日志和各种管理页面里。很多团队不是做不到,而是看不过来。
这时候如果 agent 只能写文案、总结会议,其实帮不上真正的忙。
但如果它能读浏览器安全状态,理解企业策略,再用自然语言帮管理员查问题、定位问题,味道就变了。
它开始像一个能上手的运维助手,而不是一个只会“解释概念”的 AI。
MCP 放进企业浏览器安全里,价值不在新名词
最近这波变化,表面上看是把 MCP Server 接进了企业浏览器安全体系。
不少人第一反应是:又来了,一个新缩写。
我反而觉得,重点不在缩写本身,而在接口边界终于更清楚了。
过去很多 agent 要接企业系统,常见做法要么是堆一层私有脚本,要么是直接暴露后台 API,再加上一堆零散权限控制。能跑是能跑,但很难优雅,也很难让安全团队放心。
MCP 的好处,是它把“AI 可以调用什么、看到什么、做到什么”这件事,放到一个更标准的连接层里。浏览器安全这类系统一旦愿意通过这种方式对接,就意味着它准备认真处理 agent 接入,而不是把 AI 当成一层临时演示壳子。
说白了,这不是多了一个炫技入口,而是企业开始给 AI 开正式门禁。
真正实用的地方,是它把排查流程压短了
这类能力最有意思的,不是发布会上的描述,而是管理员以后怎么用。
你可以想象一个很实际的场景。
同事反馈某个团队最近频繁触发下载限制,业务部门又说自己并没做危险操作。以前管理员大概率要先翻策略,再查设备,再看日志,最后去猜是扩展冲突、身份策略误判,还是数据防护规则过严。
现在如果 agent 能直接接入这套企业浏览器安全能力,很多第一轮排查就能变成对话式流程:
“最近一周哪些设备命中过最多的数据防护策略?”
“这个用户所在 OU 的浏览器策略和默认策略有什么差异?”
“哪些扩展是新装的,且没有经过白名单审批?”
这类问题以前当然也能查,但路径很长。现在如果能缩成几句自然语言,管理员节省下来的不是一点点点击次数,而是决策速度。
安全工作里,很多时候慢半小时,代价就完全不一样。
它最该被关注的,不是智能,而是边界
我对企业 agent 一直有个很朴素的判断:它聪不聪明是第二位,边界清不清楚才是第一位。

因为只要 AI 真碰管理系统,大家最担心的就不是“它会不会答错”,而是“它会不会碰错”。
所以这类浏览器安全 agent 真正能不能落地,关键不是模型多能讲,而是权限怎么收、审计怎么留、默认动作是不是足够保守。
比如默认先从只读查询开始,而不是一上来就允许修改策略。
比如每次调用都能追踪。
比如高风险动作仍然要人工确认。
比如 agent 看到的是经过筛选的管理面,而不是整个后台裸奔给它。
这些东西听起来不性感,但企业买单靠的就是这个。
没有这些约束,agent 进管理后台就像把一个实习生直接给了 root 权限,大家嘴上说创新,心里都发毛。
这对 AI agent 行业也是个提醒
这波变化还有一层意思,很多做 AI 产品的人最好早点看懂。
现在大家都爱讲 agent 落地,讲从“会说”走向“会做”。但真进企业,最难的从来不是生成一段自然语言,也不是自动点网页。
最难的是接入真实系统之后,你有没有能力尊重原来的治理结构。
企业不是没有自动化工具,也不是没有 API。它缺的是一种新东西:既保留原本的安全边界,又让自然语言成为新的操作入口。
谁能把这两件事同时做好,谁的 agent 才更像基础设施。
只会演示“帮你打开十个标签页”“自动填一堆表单”,看着热闹,离企业级还差得远。

普通用户也能从这件事里看出未来方向
你就算不是企业管理员,这件事也很值得看。
因为它说明,AI 下一阶段不会只停在个人效率工具。它会越来越多地进入那些原本很讲究权限、流程、责任归属的地方。
浏览器安全只是一个开始。后面大概率还会看到更多类似变化:终端管理、身份系统、云权限、代码托管、内部知识库,都会慢慢长出专门给 agent 用的接口层。
到那时,评判一个 AI 产品靠不靠谱,标准也会变。
不再只是“模型强不强、回答快不快”,而是它接系统时稳不稳,权限设计细不细,审计链条全不全。
真正能进办公室核心流程的 AI,最后拼的不是想象力,而是工程纪律。
最后说句更实际的
如果你在公司里负责 IT、终端、安全,或者正准备把 agent 接进日常工作流,这件事可以记住一个判断标准:
别先问 AI 能替你做多少。
先问它接进来之后,谁能看见,谁能控制,谁来兜底。
这个顺序错了,后面大概率要补课。
浏览器安全开始拥抱 agent,不代表风险自动消失了。它只是把一个更成熟的问题正式摆到台面上了: 当 AI 进入企业管理面,速度和安全到底怎么一起拿。
谁先把这个问题答好,谁才更有机会把 agent 真正用起来。
在云栈社区里,关于 运维与 DevOps 的讨论也常提到类似的观点:自动化工具最终要服务的是人,而不是取代所有判断。只有把流程、权限和审计链路设计清楚,AI 才能真正成为值得信赖的基础设施。
 发表于 2026-6-2 23:39:38
|
查看: 98|
回复: 0
发表于 2026-6-2 23:39:38
|
查看: 98|
回复: 0
