在B站,运营团队管理着大量UP主交流群,如品类扶持、成长训练营等。这些群组每天产生海量消息,传统的人工统计方式效率低下且易遗漏关键信息。早期基于关键词匹配的简单分析方法,无法理解上下文和语义,对新话题的捕捉能力也十分有限。
为此,我们构建了一套AI系统,旨在:
- 自动理解社群会话内容
- 洞察创作者的真实反馈
- 自动生成结构化的洞察报告与风险预警
整体架构:一套由LLM驱动的社群“AI中台”
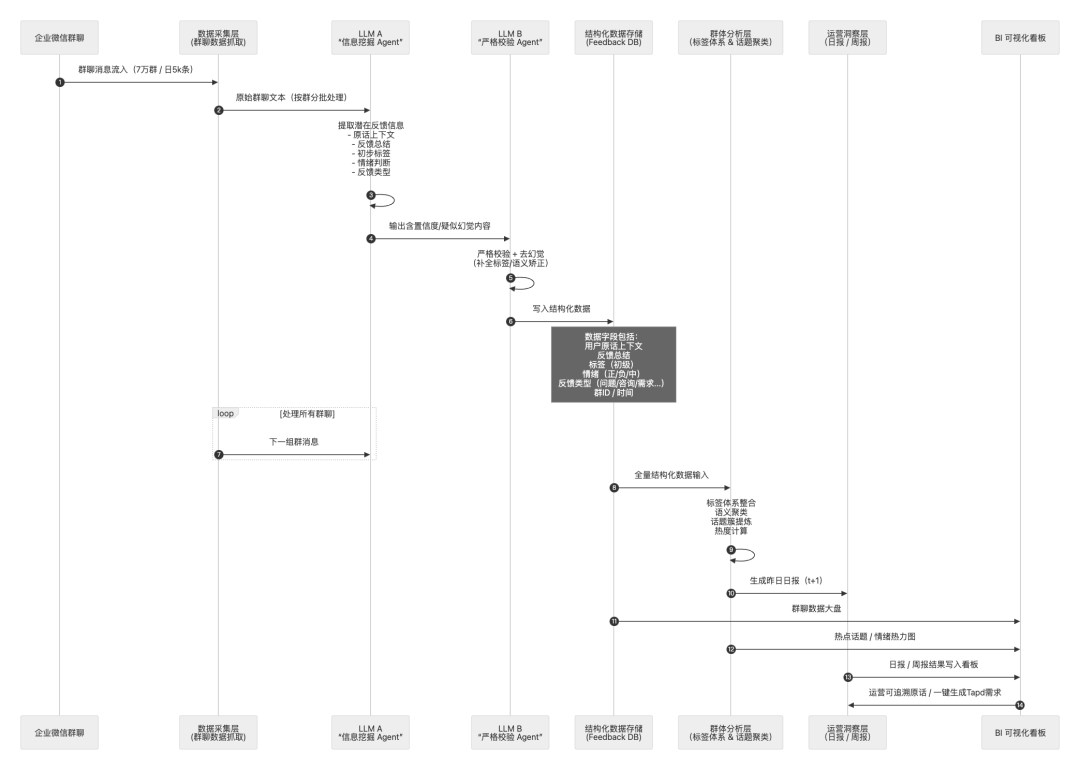
整个系统的处理流程分为四层:数据采集层 → AI结构化层 → 群体分析层 → 运营洞察层。

在落地实践中,我们不仅构建了由多个大模型驱动的Agent流程,更形成了一套可治理、可复用、可演化的Prompt工程与语义分析架构。
1. 分层Prompt Engineering体系:高召回与高精度的协同
我们将LLM处理链路拆分为四层Prompt,以实现可控、高可用且全链路可解释的输出。
- 信息挖掘层:用于高召回地提取所有可能的用户反馈,以固定Schema输出,并内置了业务语义空间(反馈类型、标签体系、情绪体系)。
- 内容治理层:用于高精度校验、去幻觉、去噪。引入了“模糊语句过滤 + 情绪×意图双因子校验”,合并重复反馈、剔除无效信息。
- 语义聚类层:基于大模型语义理解自动构建话题簇,统一标签命名,避免相似标签分裂,并能基于语义自动归并或生成新标签。
- 洞察生成层:自动生成社区热点摘要,并基于结构化数据生成包含环比变化与风险事件的日报/周报。
2. 双模型协作:在精准性与成本间寻求平衡
社群消息具有非结构化、口语化、强上下文依赖的特点。针对每日海量群聊,我们采用了“轻模型做召回 → 强模型做校验”的策略:
- LLM A:擅长高召回的信息挖掘。
- LLM B:擅长严谨判断,减少幻觉。
这种多模型协同校验的设计,让我们在成本、召回率与准确率之间取得了最佳平衡。
真实案例:单模型幻觉导致的误判
项目初期,仅使用单模型直接解析时,遇到某些短句或无明确意图的消息,模型会为了满足结构化输出要求而“脑补”不存在的反馈信息。
例如,某天群聊并无有效反馈,模型却输出了数十条结构化反馈。经人工复查,所有反馈均为模型幻觉生成。

这并非简单的技术Bug,而是足以误导业务决策的严重风险。因此,我们引入了第二阶段的严格复核节点。
双模型协作与反幻觉策略
我们设计了LLM A(高召回)→ LLM B(高精度)的协作机制。
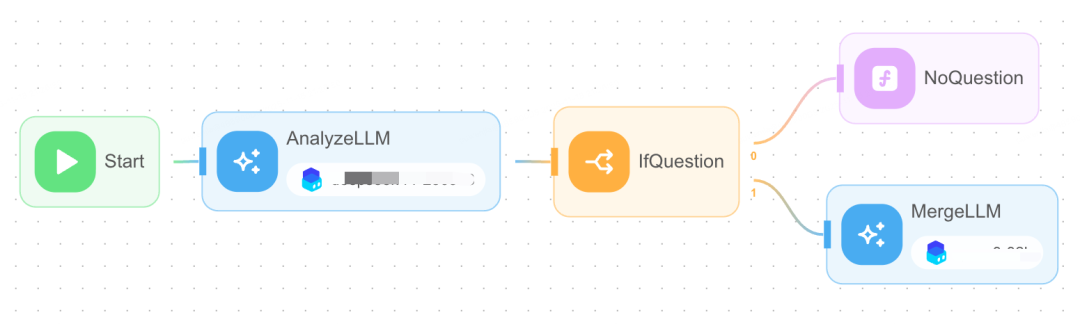
在复核节点,我们实施了专门的“反幻觉策略”:
- 严格禁止模型补充不存在的用户原话。
- 无对应原话时,必须输出「无反馈」。
- 结构化数据必须与原文一一对应,形成可追溯的“证据链”。
- 模糊语气(如“似乎”、“可能”)自动判定为高风险,进入复核流程。
效果增强:
- 幻觉率从早期的8–12%降至<1%。
- 假反馈基本消失。
3. 基于Few-shot的结构化输出稳定机制
在实际使用中,大模型的结构化输出易发生“格式漂移”。我们采用了一种轻量级的Few-shot Prompting方法,通过在Prompt中提供2~3个标准表格示例,让模型快速“记住”并沿用目标格式,从而显著稳定输出。
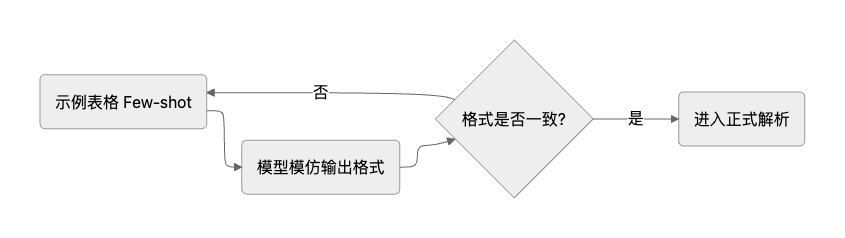
此方法成本极低,但稳定性提升明显,在某些场景下比复杂的结构化约束更实用。
4. LLM语义聚类:轻量级话题分组
用户表达高度自由,存在大量同义表述和新词汇。为避免关键词维护负担,我们采用LLM进行语义聚类:
- 基于语义相似度(而非关键词匹配)进行判断。
- 由模型生成统一标签,避免同类话题被拆分。
- 当识别到全新话题时,模型能自动生成新主题。
这是一种轻量但实用的Topic聚类方式,能让系统自动跟上社区语境的变化。以下是我们使用的Prompt核心部分(隐去业务细节):
你是社区运营团队的一员。你即将阅读到一批用户反馈内容,每条反馈都有唯一的“反馈ID”。你的工作如下:
主题聚类
- 对所有反馈进行语义聚类,将语义相近的反馈归为同一主题。
- 相同主题只保留一个统一标签。
标签命名
- 参考微博热搜命名方式,生成简洁有冲击力的标签(2~8字)。
事件提炼
- 为每个标签用一句话概括用户关注的焦点。
热度统计
- 统计该标签下的反馈数量,作为热度值。
反馈ID标注
- 列出与该标签相关的最多5个反馈ID。
排序输出
- 按热度从高到低,输出前10个标签的信息。
输出表格格式如下,请勿返回多余的注解:
| 标签 | 热议事件 | 热度 | 反馈ID |
5. 语义驱动的风控预警体系
我们结合语义聚类结果与反馈指标,构建了轻量级预警逻辑,包括量级分析、增速分析、负向占比、情绪突发检测与跨群体一致性判断。

当某个话题出现负向情绪急增、环比快速上涨或多个群同时出现类似反馈时,系统会自动判定为突发事件并标注风险等级。相比传统人工轮询,这种基于AI的应用能更早发现潜在风险。
实际效果与业务收益
引入AI智能分析系统后,我们在反馈洞察的效率、覆盖面和准确性上均获得显著提升。
- 处理规模倍增:过去人工日均回收约50条有效反馈,现在系统可自动回收近600条,覆盖范围扩大十倍以上,大量“弱信号”得以被捕捉。
- 主动风险洞察:系统能识别创作流程、审核体验等领域的情绪异常聚集,在问题扩散前提前预警,实现早期介入。
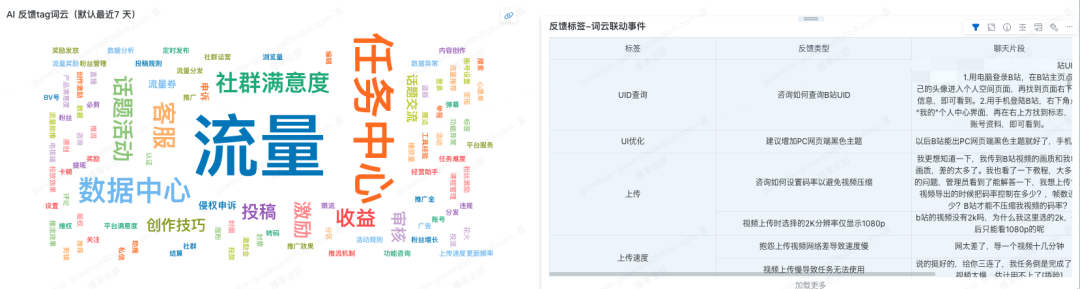

- 数据资产沉淀:结构化后的群聊信息成为重要知识资产,可用于:
- 生成每日/每周事件简报。
- 输出典型案例与话题热度,辅助优先级判断。
- 自动创建需求工单,推动问题闭环。
- 为产品团队提供真实的用户“原声证据”。
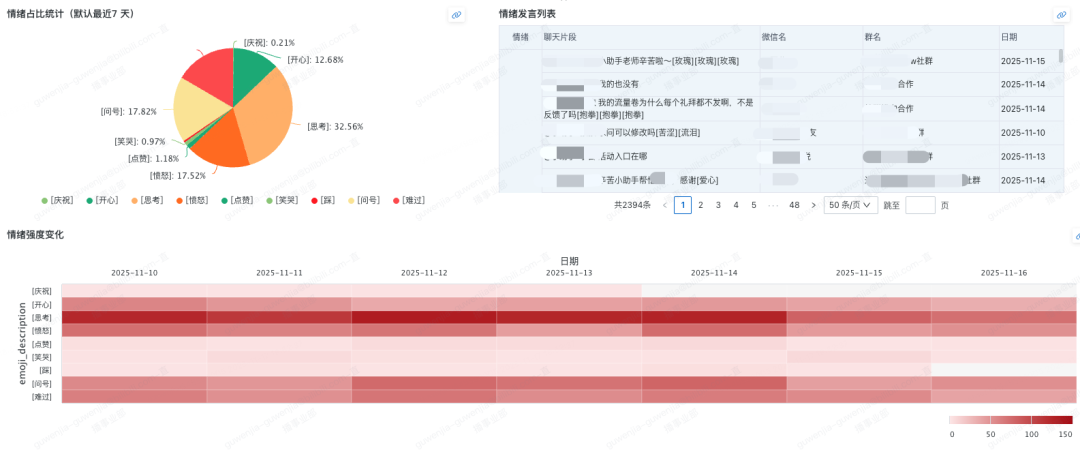
在BI看板上,情绪趋势、话题聚类、风险事件等核心指标一目了然,助力实现数据驱动的运营决策。这套系统架构让我们从被动响应走向了主动洞察。
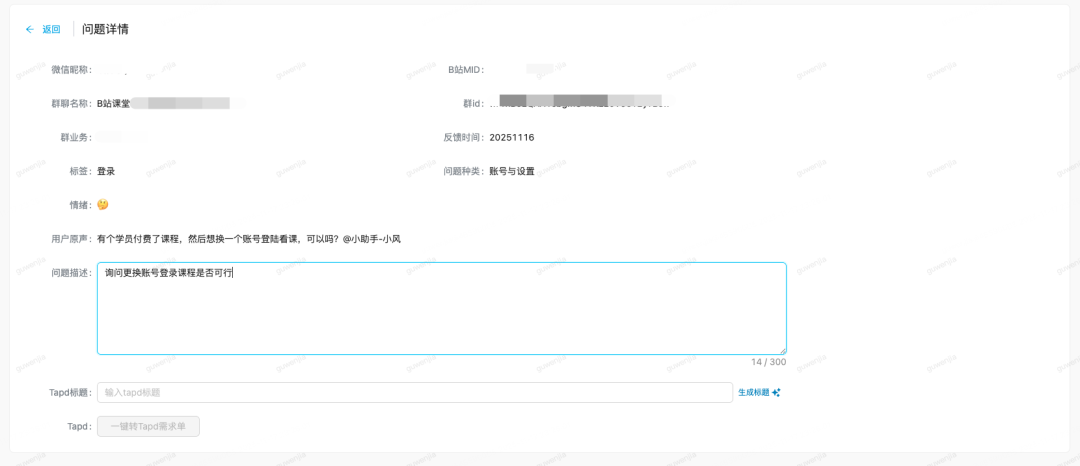
总结
这套社群信息AI分析体系的落地,带来了多层面的提升:
- 效率跃升:自动化取代大量重复分析工作。
- 全面覆盖:大模型的语义理解能力显著降低反馈遗漏率。
- 情绪量化:用户情绪变为可观测指标,提供及时风险提示。
- 话题聚合:语义聚类帮助准确把握社区关注点。
- 推动闭环:结构化数据顺畅进入需求流转体系。
AI让我们从“人工盯岗”进入“主动洞察”时代,实现了对创作者声音的规模化记录与分析。未来,我们将继续加强模型在风险识别与创作支持等方向的能力,为平台构建更智能的基础设施。
 发表于 2025-12-7 22:02:27
|
查看: 165|
回复: 0
发表于 2025-12-7 22:02:27
|
查看: 165|
回复: 0
