刚刚,一个身在迪拜的朋友在群里吐槽:说是某云的阿联酋机房发生故障后,影响挺大,很多网银都不能用了。
于是,群内又是一番热烈的讨论。
这种“宕机”,大家也不是头一次见识了(虽然这次的原因比较特别)。无论是不可抗力还是人为因素,全球头部的云大厂们,几乎都轮番宕机上过热搜……
每到此时,关于高可用啊、SLA啊、上云不如自建稳啊,这类争论就会此起彼伏。
其实,每一次大规模宕机,都是偶然中的必然!
今天,我们就结合这次事件,再次聊聊这个话题:明明上了「高可用」为什么还会宕机?我们对IT「高可用」,都有哪些误解?
到底什么是高可用
高可用,High Availability,有人也缩写成HA。其实就是通过各种可靠性的设计,把一个系统不能正常提供服务的几率降到最低。
拿上面自贸区网站停摆来举例,如果有个影子版的「网站镜像」始终在旁边其他可用区候着,发现“正主儿”宕机以后,它立马无缝接管,访问不受任何影响(换成网银也一样,但网银设计会更复杂,对一致性要求更高)。这,就是所谓「高可用」了。

但是,需要提醒大家一点,高可用≠100%无故障。 无论我们如何未雨绸缪,如何进行各种冗余设计,宕机的概率依然存在。所以我们会看到任何系统、任何云服务,给出的SLA,都是多少个9(比如99.9999%),但从来没人承诺100% 😅。

为什么需要高可用
高可用是一项系统性工程。 拿在线式的软件服务为例:网络、主机、存储、系统、软件,以及相关联的数据库、API、各种组件,甚至托管机房的风火水电,都是影响最终高可用结果的因素。
既然是系统性工程,涉及到这么多方方面面,每个环节都要考虑周全,也就意味着更高的成本。
所以,高可用送给你的每个9背后,都暗中标好了价格 😄。

既然这么费钱,那么追求高可用的道路上,就应该适可而止,够用就好。
第一,从实际业务需求出发,来评估具体的可用性指标,业务连续性要求高的,就必须要“卷”起来。

第二,根据行业监管要求,达成相应的合规标准。 比如针对银行,就会有类似于《银行业信息系统灾难恢复管理规范》(JR/T 0044—2008)的监管规定,要求必须达到对应的高可用级别。
所以,对高可用指标的追求,往往都是掂量着业务需求+监管需求,再加上自己口袋里的预算,最终得到的一个平衡结果。
讲真,今天群里小伙伴说自贸区官网打不开了还好理解,但许多网银都不能用了,无论从业务还是监管层面看,都有点太草率了。

如何进行高可用架构设计
如果已经明确了高可用的需求,那么接下来就要深入了解下,高可用设计,具体应该怎么整?通常,高可用设计应该遵循6大原则。
❶ 少依赖原则
顾名思义,就是在高可用系统设计的时候,应当尽可能减少不同组件之间的依赖关系。彼此独立,能不依赖的,尽可能不依赖,越少越好。否则,一个组件挂掉,整个系统就可能“兵败如山倒”。
比如,一个多依赖系统,是这样的↓

一个少依赖系统,是酱婶儿的↓

❷ 弱依赖原则
一定要依赖的,尽可能弱依赖,越弱越好。如果组件A强依赖组件B,一旦B挂了,A也会翻车,反过来也一样。所以任何强依赖要尽可能转化为弱依赖,从而降低“翻车”的概率。

❸ 分散原则
化整为零,打散成N份,从而分散风险,避免把鸡蛋放在一个篮子里,一损俱损。

比如设计数据库的时候,不要所有的交易数据都放在同一个库的同一个表里,万一库挂了,就意味着所有交易都停摆。另外,更典型的还有多AZ设计、多云架构,以及大家最经常听到的异地容灾架构,这些,都是在遵循分散原则。
❹ 均衡原则
在打散拆分成N份的前提下,还要尽可能保证每份都是均衡的,这样风险也被均匀分担,避免某份的权重过大,造成影响的范围过大。

❺ 无单点原则
要有冗余设计,以免出现问题无路可退。比如支持切换、扩容等策略,链路故障时可以切换到新链路上,主机故障时可以切换到新扩容的机器上。
再比如支持回滚机制,某个操作失败后,可以回滚到上个版本,避免在错误的道路上越走越远,无法收拾残局。

❻ 自保护原则
一旦出现极端情况,要果断「丢车保帅」,牺牲不重要的部分,保护重要的部分。比如CPU过热保护,也可以看做是类似这样的机制,系统在检测到CPU温度过高后,自动降频,虽然整体处理性能下降了,却不至于完全宕机。

除了这些基础的高可用设计原则需要遵循,还有一个简单粗暴的硬道理:
公有云相比私有云、IDC托管、传统IT架构等等,天然更具备高可用的“潜质”。
首先,云计算的基因就是分布式的,跟传统集中式架构比拼RAS指标、用昂贵的硬件系统来提升高可用的思路完全不同。云计算把硬件故障当做“常规事件”,通过分布式架构来降低依赖、分散和均衡风险、消除单点并提供保护机制。

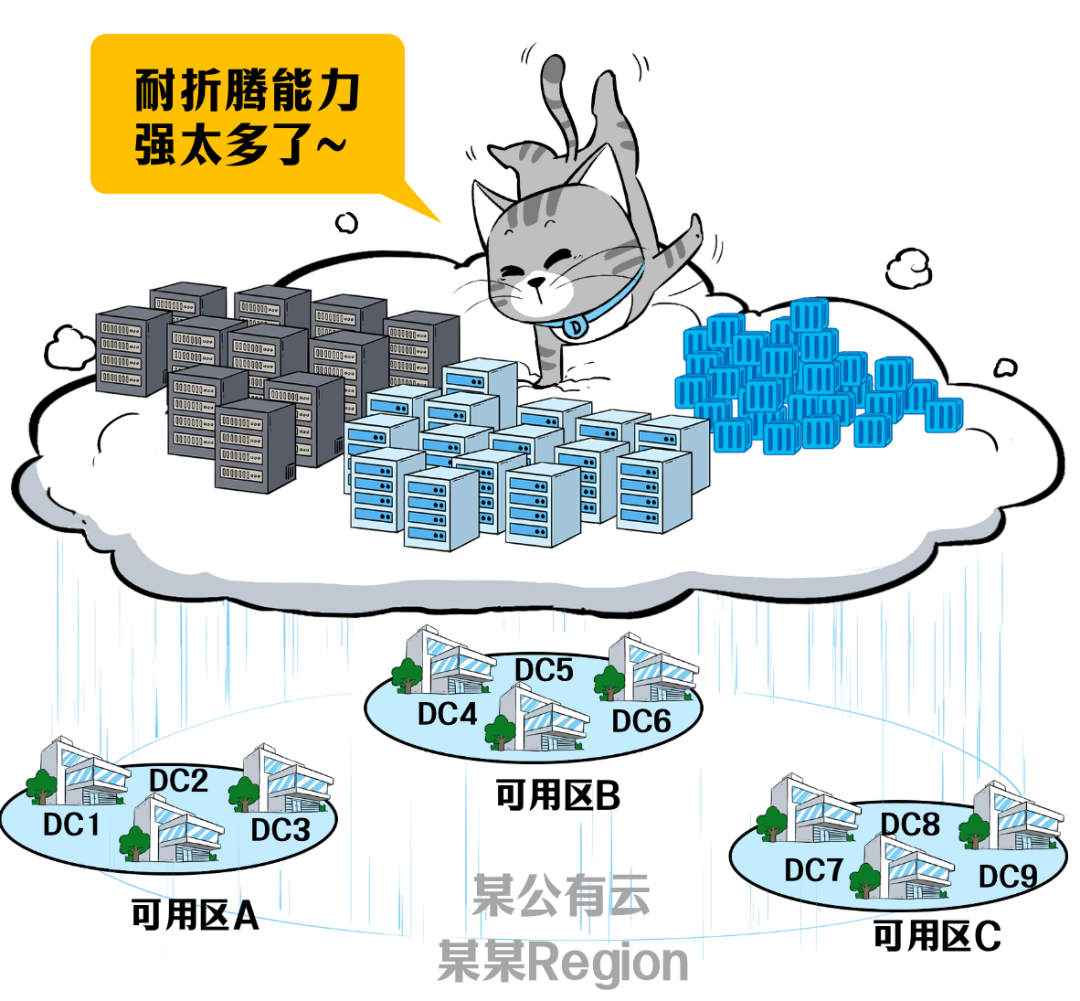
第二,同样都叫「云计算」,公有云相比私有云、本地虚拟化资源池,可以通过超大规模的资源优势,不断堆buff,堆出更好的伸缩性,遭遇极端场景时,具备更好的高可用潜质。
第三,公有云在底层基础设施层面,通过选址、数据中心级别(风火水电)、多线网络、多DC、多AZ、多区域,各种未雨绸缪,具备更耐折腾的高可用底盘。
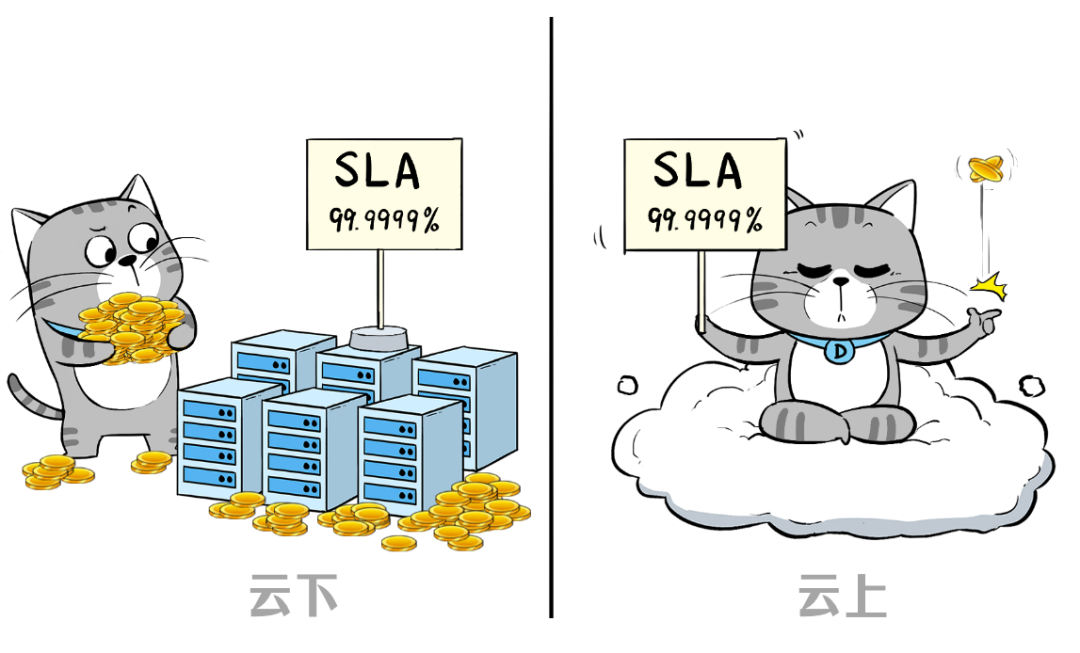
所以,当遇到高可用的需求时,优先选择上云,一般可以达到事半功倍的效果。换句话说,如果想要同样的SLA,对用户来讲,云下的成本要远高于云上。
为啥我上了云,还是挂了?
虽然我说公有云“天然高可用”,但吃瓜群众说“你看你看,常有云宕机上热搜!”
首先明确一点,相比云下IT系统成天此起彼伏故障,云宕机其实是小概率事件,只不过云宕机更具新闻性,所以几大头部云商但凡有点风吹草动,行业里就会草木皆兵。

第二,上了云,不等于宕机的锅就可以完全甩给云服务商了,云用户和云服务商需要权责明确,责任共担。前面我们说过,高可用是一个系统性工程,涉及到服务边界的问题,云服务商没法成为云保姆,大包大揽把所有的事情都兜底。
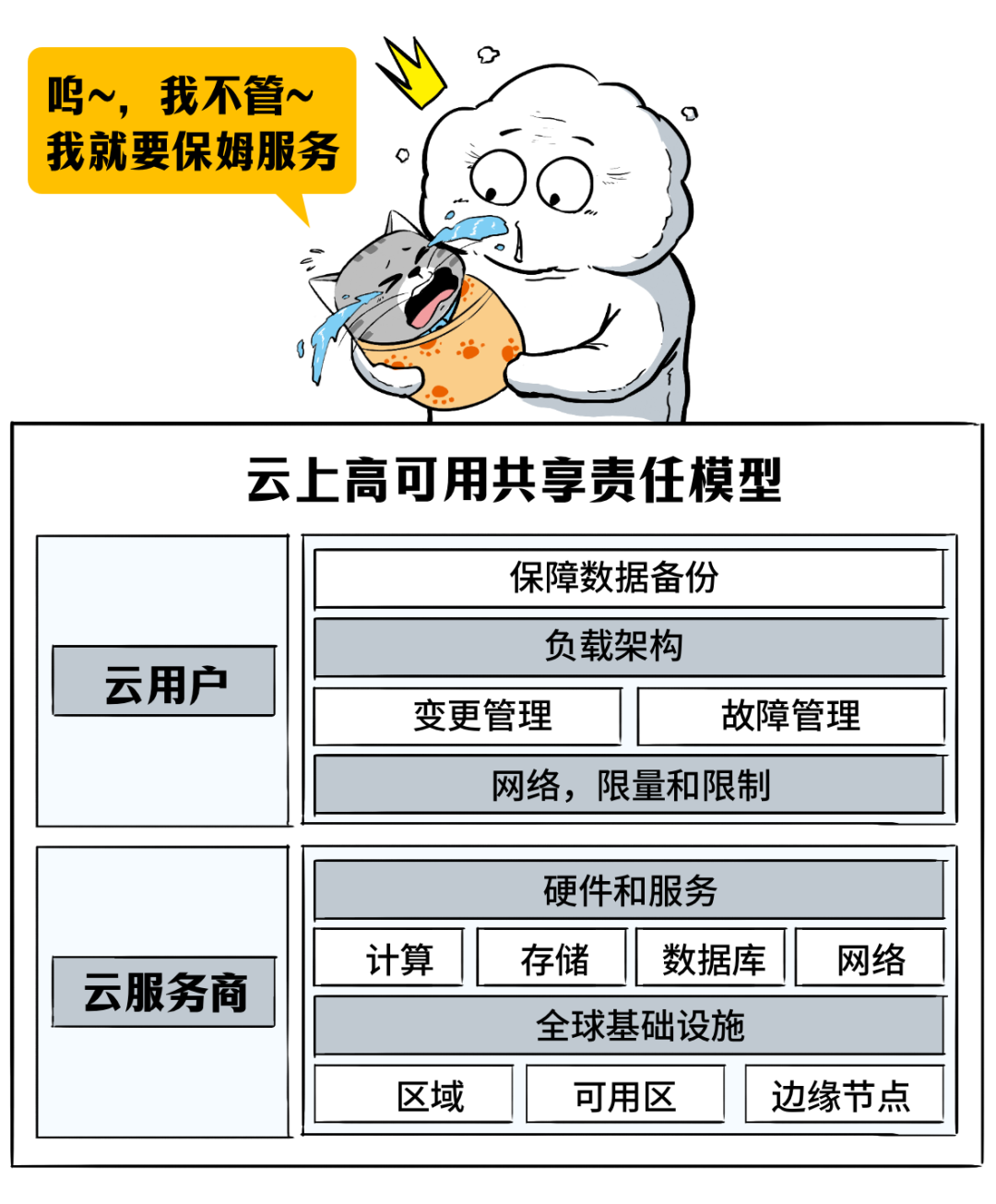
如果「成熟」的云服务商和云用户,都能把各自的“门前雪”扫干净,那么,云上高可用的效果,就可以发挥到极致。
既然话说到这个份上了,我们就要搞清楚,作为云用户,云上有几大雷区必须要规避,否则可能「上线一时爽,宕机火葬场」。
❶ 如果业务需要高可用,一定要在采购之前就设计好高可用架构,无论是线下的IDC还是正经公有云产品,都需要提前设计,一旦部署了业务再回头想要高可用,改造起来可就伤筋动骨了。
❷ 为了确保整体的可用性,每一个环节都得具备高可用,一个组件出了问题就可能前功尽弃。
❸ 在使用云厂商或托管服务之前,要提前调查好各项功能的兼容性和需求是不是匹配,比如权限管理等。
❹ 明确云厂商提供产品的可用区,很多云厂商提供了多可用区灾备能力,但也有少数产品因为性能等原因只支持单AZ。
❺ 架构的设计和交付务必要对齐,效果图和施工落地不一致的惨案太多太多了。
❻ 业务软件尽量做到无状态,这样可以利用云服务的多AZ算力及支持多AZ的PaaS产品,在不大幅增加成本的情况下,支持业务跨可用区的容灾能力。
❼ 单元化设计,确保一次用户请求能够在一个可用区完成闭环,不要跨可用区。
典型云上高可用,长啥样
我们来看个实际的例子吧,底层咱不说了,云服务商已经帮你把坑填完了,只看用户侧如何填坑。
先看错的,这是一个典型的「伪高可用」,各种组件看着都是冗余的,但是却忽略了一个最重要的地方,那就是所有的鸡蛋都在一个篮子里(单可用区架构)。
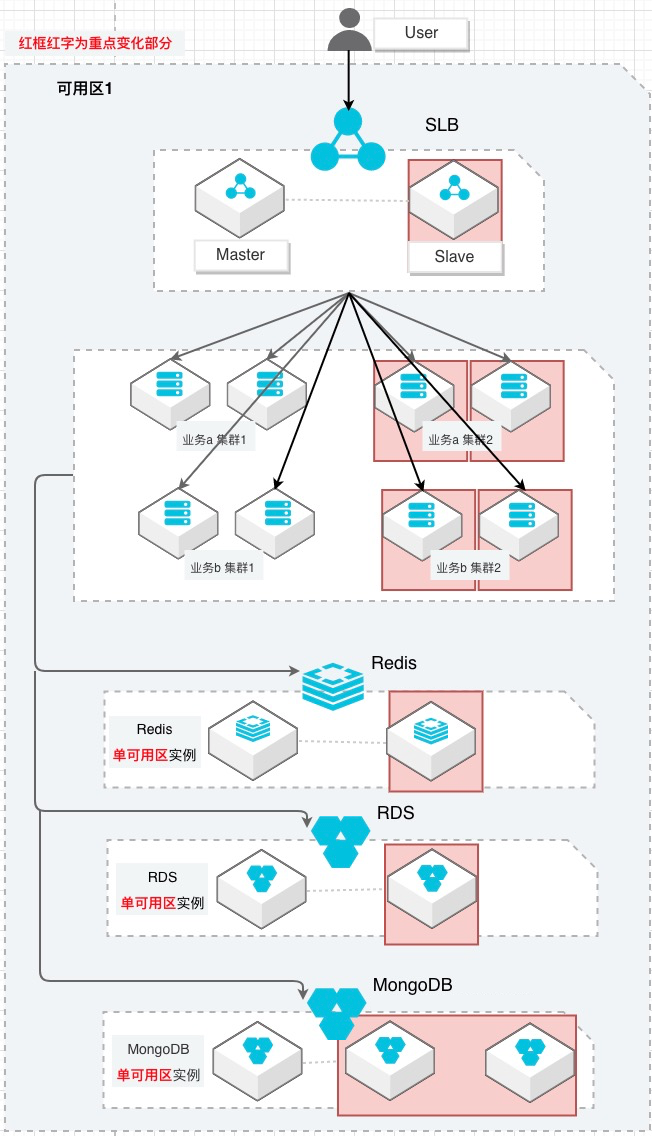
这种设计,看似做足了功夫,可一旦“可用区不可用”,高可用设计立马失效。
所以,正确的云上高可用设计,一定要把云的优势能用尽用,云的羊毛能薅尽薅…比如,把上面的设计重来一遍,全部更改为多AZ模式,SLB主备设计,前端业务集群双AZ,缓存、数据库也选双AZ版本,文档存储选3AZ高可用。
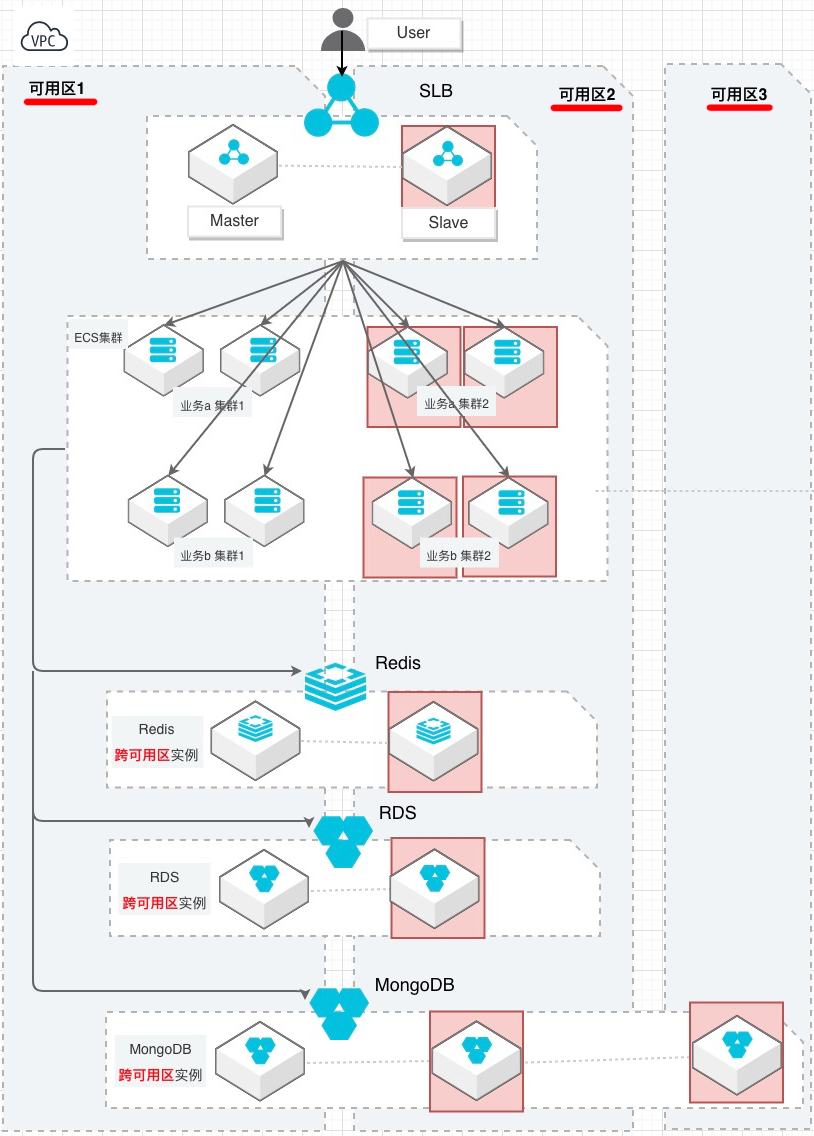
这样的高可用设计,就是相对靠谱的,单个AZ故障,不会让业务受到任何影响。
当然,还要注意高可用设计和实际交付要对齐,比如设计的时候数据库是跨区高可用,交付的时候却买了单AZ版本;购买对象存储的时候,思想开了个小差,本来该选3AZ版本,却点了单AZ版本。一个小环节的疏漏,就能让“千里之堤溃于蚁穴”了。

再比如把计算资源和PaaS类服务(如RDS等)整到了不同的可用区。这样,用户的一次请求无法在一个AZ形成闭环,要跨可用区调用,既让性能打折,还增加了故障概率(任何一个可用区停摆,业务就会挂掉)。
所以,有些云大厂虽然不做“云保姆”,但还是尽可能帮用户“避坑”,比如提供一些专业的可视化设计部署平台。基于这样的平台,云用户在规划阶段做好高可用设计,并在部署时进行一致性检查,彻底解决设计与交付脱节的问题。
如果必须专有云,该咋整
现在大家都知道了关键点:上云更容易实现高可用,建设更简单,总体拥有成本(TCO)更低。遗憾的是,确实还有很多场景因为监管、合规等问题,暂时不能上云。
此时如果要建设高可用怎么办?❶根据业务属性合理分级。❷低等级就适当降低标准。❸高等级就付出更多成本。

高可用级别与成本之间成正比,所以,根据业务属性,合理设定可承受的风险范围+对业务恢复时间的要求,是弹性/韧性受限的专有云场景建设高可用的关键。
本地冗余架构: 可以接受机房级风险,在单一主机、网络、系统、服务故障时,可以快速恢复业务。
同城容灾架构: 可以接受区域级风险,但是在机房级风险发生时,能快速恢复业务。
异地容灾架构: 除了能承受机房级风险,还要能承受区域级风险,但对快速恢复业务需求不强。
两地三中心架构: 除了能承受机房级风险,还要能承受区域级风险,同时对快速恢复业务也有强需求。
小结一下:
- 高可用不等于100%可用,高可用级别跟付出的成本成正比;
- 先评估业务卷到什么程度,再决定高可用卷到什么程度;
- 上云仍是建设高可用的捷径,云上高可用的TCO成本更低;
- 但云上高可用和云上安全类似,要注意责任共担模式,并要做到设计和交付对齐。
最后,祝大家永不宕机 😉

(旧文重发,但常看常新😁)
关于高可用架构设计和云原生底盘下的运维实践,你还有哪些经验或困惑?欢迎在评论区留言,或前往云栈社区与更多同行交流探讨。
 发表于 2026-3-4 09:04:09
|
查看: 176|
回复: 0
发表于 2026-3-4 09:04:09
|
查看: 176|
回复: 0
