北京时间 3 月 2 日晚 19:49,无数开发者和用户发现,他们常用的 AI 助手 Claude 无法访问了。
截至次日 16:24,网页端服务仍未完全稳定。用户访问 claude.ai 时,页面会弹出“Claude is currently experiencing a temporary service disruption”的提示。客户端登录频繁失败,开发者控制台(Console)返回 500 错误。事故高峰期,近 2000 名用户同时报告故障。消息在社交媒体上迅速发酵,用户社区一片哀嚎。
与此同时,另一条爆炸性新闻正在全球科技媒体刷屏:伊朗无人机袭击了 AWS 在阿联酋的数据中心。
两件看似毫不相干的事件在时间上撞车,一个极具戏剧性的叙事立刻成型——“AWS 中东机房被炸,导致依赖其服务的 Claude 全球宕机!”包括 Bloomberg 在内的媒体争相报道,全球程序员在调侃中不免担忧:“难道第三次世界大战的先兆,是打掉我的 AI 编程助手?”
但这个被广泛传播的叙事,其逻辑链很可能站不住脚。让我们抛开表象,基于技术事实进行一次深度复盘。
事实一:故障模式分析——什么挂了,什么没挂?
这是分析任何 服务中断 的起点,也是本次事件中多数人未厘清的关键。
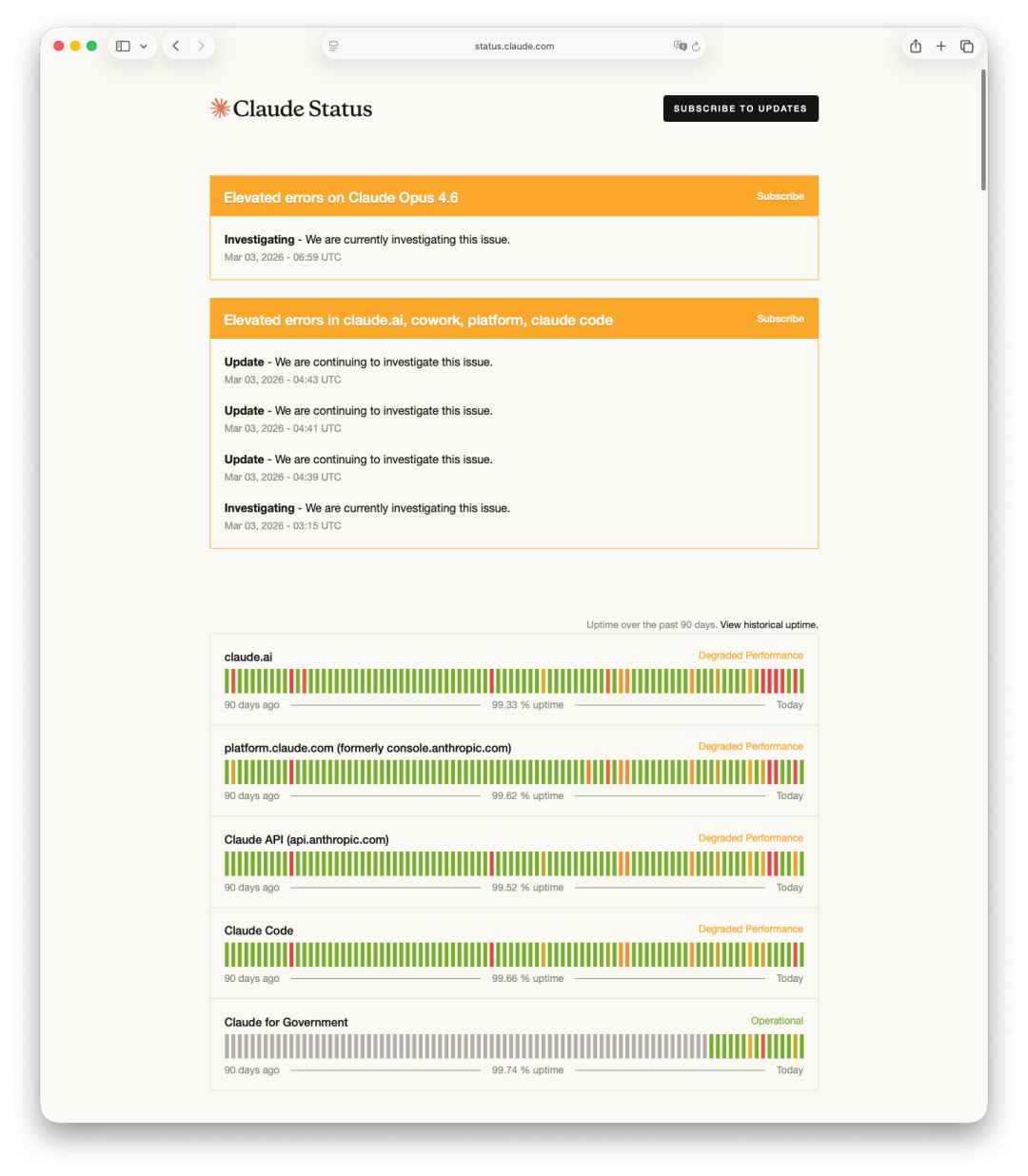
事故发生后,Anthropic 官方迅速确认了一个重要事实:Claude API(api.anthropic.com)在整个事件期间工作正常。真正出现问题的是以下服务组件:
请注意这个清晰的故障模式:后端核心的模型推理服务安然无恙,而出问题的是前端的用户界面和认证系统。
Claude Code(IDE插件等)的情况比较特殊——其核心推理功能走的是正常的 API 通道,但在用户认证、会话初始化管理等环节,依然依赖前端基础设施。这完美解释了它为何表现为“错误率升高”而非完全不可用。如果你在故障期间直接通过 API 密钥调用 Claude,甚至可能完全感知不到这次全球性的服务中断。
这个模式提供了至关重要的线索:故障更像是从“认证与流量入口”这个节点开始爆发,再向后端相关依赖扩散,而绝非“核心推理计算集群被物理摧毁”所致。
事实二:AWS中东区域究竟遭遇了什么?
根据公开报道,我们来简要回顾 AWS 中东区域的情况:
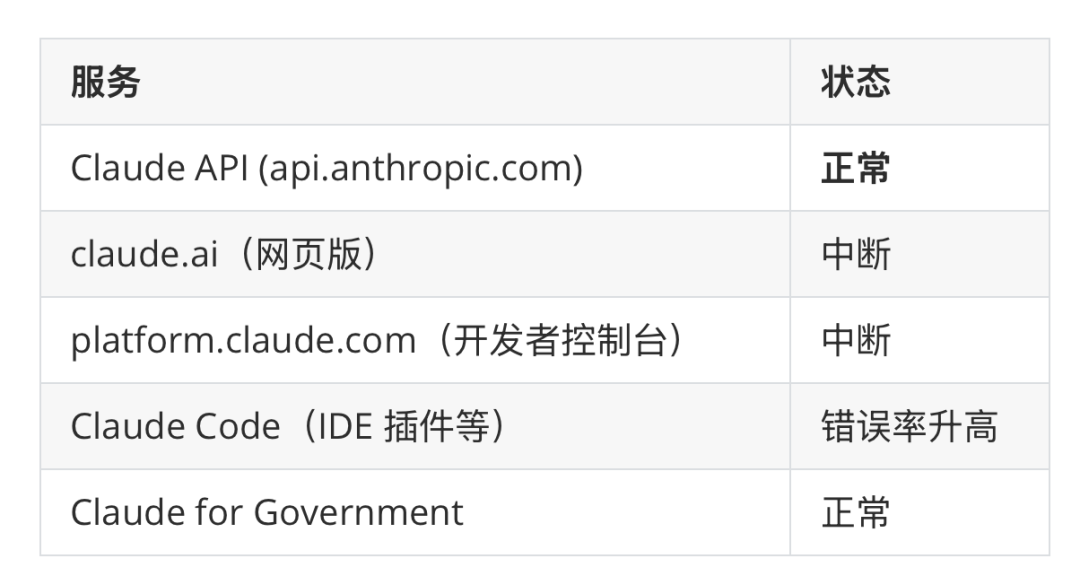
3 月 1 日,伊朗对阿联酋和巴林发动了无人机/导弹袭击,AWS 在当地的数据中心遭遇直接打击:
- 阿联酋(me-central-1 区域):3 个可用区(AZ)中,2 个陷入瘫痪(mec1-az2 被直接命中起火,mec1-az3 因连锁反应电力中断)。
- 巴林(me-south-1 区域):3 个可用区中,1 个受损(mes1-az2 因附近打击造成物理损伤)。
- 以色列(il-central-1 区域):未受影响。
中东地区总计 9 个运营中的可用区,有 3 个在此次袭击中丧失服务能力,占比高达33%。其中阿联酋区域更是丧失了三分之二的容量。这确实是云计算史上一次前所未有的物理基础设施灾难。但问题随之而来:Anthropic 的 Claude 服务,其核心真的部署在中东区域吗?
事实三:Claude的核心基础设施不在中东
这个问题的答案是否定的。Anthropic 是一家总部位于旧金山的 AI 公司,其核心资产——Claude 大模型所需的推理集群,依赖的是大规模、集中的 GPU 算力(如 H100/H200 集群)。这些昂贵的硬件资源通常部署在 AWS 的美国本土核心区域,例如 us-east-1(弗吉尼亚)或 us-west-2(俄勒冈),而不是中东。
AWS 的中东区域(如 me-central-1, me-south-1)主要定位是服务中东本地的企业客户,提供标准的云计算服务(EC2、S3、RDS等),而非专为大规模 AI模型推理 设计的 GPU 集群。AWS 官方的区域故障隔离原则也明确指出:各区域之间设计上是相互隔离的,单个区域的故障原则上不应拖垮其他区域。
一个最直接的反证是:如果 Claude 的核心推理引擎真的跑在中东,那么其 API 端点(api.anthropic.com)理应一同挂掉。但事实是 API 完全正常——这直接否定了“导弹打掉 Claude 后端”的假说。
有人可能会提出一种迂回的可能性:“也许 AWS 在全球层面做了流量重路由,导致其他区域过载?”理论上存在这种可能,但如果是后端计算资源过载,受影响的首当是 API 的响应延迟和可用性,而不是前端的登录认证系统。而实际情况恰恰相反。
真正的原因:“成功税”——意料之外的流量洪峰
那么,导致 Claude 前端服务崩溃的更可能原因是什么呢?让我们把时间线往前推移 48 小时。
背景:五角大楼合同风波
2月底,一起政治风暴席卷了美国 AI 行业:
- 五角大楼要求 Anthropic 开放其模型用于军事用途(包括自主武器和监控系统),被公司联合创始人兼CEO Dario Amodei 拒绝。
- 随后,特朗普政府将 Anthropic 列为“激进左翼 AI 公司”,并下令联邦机构在6个月内停用其服务。
- 国防部长甚至将 Anthropic 定性为“供应链安全风险”。
- 与此同时,OpenAI 签下了一份价值2亿美元的五角大楼合同,接过了Anthropic拒绝的生意。
这一系列事件在普通消费者中引发了剧烈反响。大量用户对 OpenAI 与军方合作感到不满,转而用脚投票支持坚守原则的 Anthropic。
用户迁移数据佐证
市场数据清晰地反映了这场用户迁移:
- 2月28日:ChatGPT 在美国的日卸载量环比暴涨 295%(通常日环比仅9%)。
- 2月28日:Claude 的下载量环比增长 51%。
- 2月28日:Claude 历史上首次在美国 App Store 的免费应用下载榜上超过 ChatGPT,登顶第一。要知道,此前其在超级碗广告投放后,排名也仅在第42位。
- 自2026年初以来,Claude 的免费活跃用户增长了 60%,日注册量更是 翻了两番。
Reddit 和 X 等社交平台掀起了 “#CancelChatGPT” 运动,用户自发撰写从 ChatGPT 迁移到 Claude 的教程。一场由政治事件引发的、史无前例的 AI 产品用户大迁移正在发生。
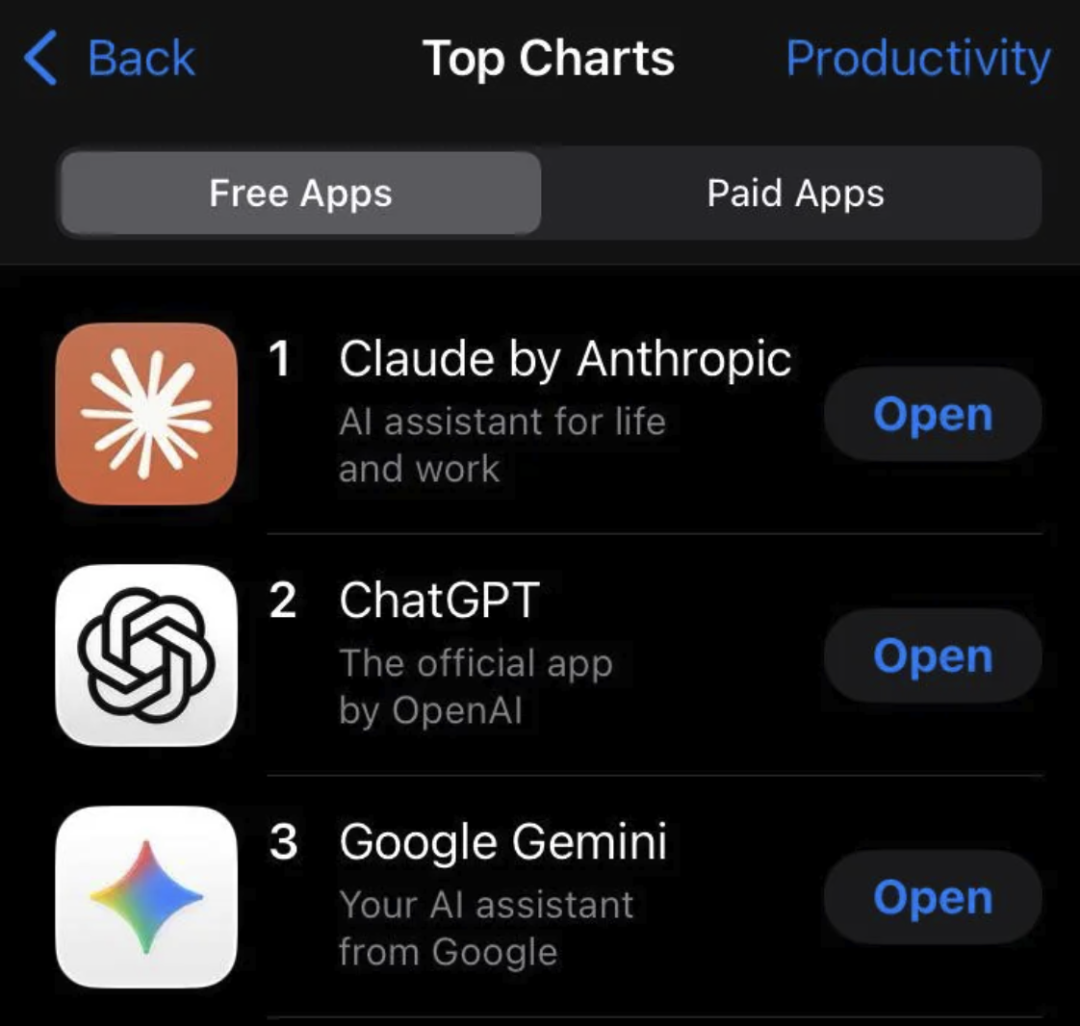
然后,Claude 的服务就迎来了考验
想象一下:从 App Store 第 42 名火箭般蹿升到第 1 名,日注册量激增数倍。海量的新用户在同一个周末涌入系统。任何有经验的系统工程师看到这组数据,都能预见到接下来可能发生什么。
前端服务——包括 Web 界面、用户认证系统、会话管理服务——其容量规划通常不会按照“48小时内用户量暴增数倍”的极端场景来设计。后端的 GPU 推理集群尚可通过任务队列、动态限流等机制来缓冲压力,但前端的登录验证、Session 创建、WebSocket 连接建立等环节,面对的是瞬时、高并发的冲击。
这完美解释了本次故障的所有现象:
- API 没挂:API 用户群体相对稳定,且本身就有完善的限流和弹性伸缩机制。
- 前端挂了:海量新用户同时涌向 claude.ai 进行注册和登录,击穿了认证系统的容量上限。
- Claude Code 部分受影响:因为它依赖前端认证链路来初始化会话,但核心推理走的是正常的API。
- Claude for Government 没事:作为面向政府客户的独立部署版本,其用户量不受消费级市场波动影响。
关键时间线对不上
再看整个事件的时间线,疑点更加明显:

AWS 中东数据中心遭遇袭击是从 3 月 1 日凌晨开始的。如果 Claude 的全球故障是由此直接引起的,为何延迟了 长达27个小时 才爆发?并且爆发的不是后端计算故障,而是前端认证崩溃?
一个更符合逻辑的时间线是:经过周末的舆论发酵和病毒式传播,到了周一(3月2日)工作日开始,全球用户(尤其是美国用户)密集上线尝试使用 Claude。前端系统在北京时间周一晚上(对应美东时间周一早晨)迎来了流量峰值,然后——不堪重负,崩溃了。
故障开始时间(11:49 UTC)恰好是美东时间早上 6:49——正是美国东海岸用户开始新一天工作的时间点。这绝非巧合。
Anthropic 官方的表态
Anthropic 在事后的官方声明中,将其归因于应对 “unprecedented demand”(前所未有的需求)。
这句话本身几乎就是答案。他们没有提及 AWS 中东区域故障,没有提及导弹袭击。他们强调的核心词是——需求太大。
在基础设施运维领域,宕机大致可分为两类:
- 需求不足导致的宕机:没多少人用,服务却挂了。这通常意味着系统本身存在严重质量或设计缺陷。
- 需求过载导致的宕机:太多人想用,服务被“挤”挂了。这往往意味着产品取得了超出预期的市场成功。
Claude 本次遭遇的,显然是第二种。这并非一次纯粹的工程灾难,更像是一次 “成功税”(Success Tax)——为突如其来的巨大成功所支付的短期代价。
当然,“成功税”不代表可以不交或无需反思。此次事件暴露了 Anthropic 前端基础设施在面对用户量指数级激增时的弹性不足。这也给所有 快速发展的AI公司 上了一课:
- 前端和认证系统的弹性扩展与后端同等重要——不是只有 GPU 集群才需要关注容量和弹性。
- 消费级产品的流量特征与纯API服务截然不同——前者可能因社会事件呈现指数级、突发性增长。
- 容量规划必须考虑极端黑天鹅事件——包括由政治、舆论引发的用户迁移潮。
截至发稿:服务仍在波动中恢复
截至北京时间 3 月 3 日,Claude 官方状态页显示事故仍在处理中:
- 06:59 UTC:Claude Opus 4.6 模型端点出现错误率升高(正在调查)。
- 03:15 - 04:43 UTC:claude.ai、cowork、开发者平台(platform)、Claude Code 等服务持续出现错误率升高。
服务在“部分恢复”与“再次波动”之间反复。这种渐进式、波动性的恢复曲线,非常符合“因容量不足而逐步扩容、调优”的故障恢复特征,而非“物理设施损毁等待重建或切换”所应有的恢复模式。
结论
AWS 中东数据中心被伊朗无人机袭击,是确凿的事实。Claude 发生全球性服务中断,也是确凿的事实。但简单地将这两件事画上等号,则是一种偷懒且不严谨的归因。
现有的证据链清晰地指向一个更合理的判断:Claude 本次全球故障,本质上是一次 由突发性用户流量洪峰引发的容量过载事故。其直接诱因是 OpenAI 签署五角大楼合同所引发的用户道德反感,从而触发了一场大规模的用户迁移。从 App Store 第42名跃升至第1名,日注册量翻两番——几乎没有哪个前端系统能在毫无准备的情况下,安然无恙地接住这种量级和速度的流量冲击。
导弹炸毁的是中东区域的物理机房,受影响的是部署在该区域的中东客户业务。用户洪流冲击的是全球登录认证入口,崩溃的是 claude.ai 的前端服务体系。
这是两件独立的事件,拥有两个不同的原因,遵循两条平行的因果链。只是它们非常巧合地撞在了同一个周末。
对 Anthropic 而言,这次故障背后反而隐藏着一个微妙的好消息:你的竞争对手(OpenAI)用一纸合同,帮你完成了一次自己花巨额市场费用都难以企及的用户增长。而代价,仅仅是一次前端服务的暂时宕机,和一个忙于扩容修复的周末。
这个“成功税”,恐怕会让 Dario Amodei 在复盘时,露出复杂但终归欣慰的笑容。
声明:本文旨在基于公开信息进行技术推演与分析。
参考资料:
[1] Anthropic confirms Claude is down in a worldwide outage - BleepingComputer: https://www.bleepingcomputer.com/news/artificial-intelligence/anthropic-confirms-claude-is-down-in-a-worldwide-outage/
[2] Anthropic's Claude Chatbot Goes Down For Thousands of Users - Bloomberg: https://www.bloomberg.com/news/articles/2026-03-02/anthropic-s-claude-chatbot-goes-down-for-thousands-of-users
[3] ChatGPT uninstalls surged by 295% after DoD deal - TechCrunch: https://techcrunch.com/2026/03/02/chatgpt-uninstalls-surged-by-295-after-dod-deal/?type=AI
[4] Claude beats ChatGPT in U.S. app downloads - Axios: https://www.axios.com/2026/03/01/anthropic-claude-chatgpt-app-downloads-pentagon
[5] Anthropic's Claude overtakes ChatGPT in App Store - Fortune: https://fortune.com/2026/03/02/anthropic-claude-dario-amodei-number-one-app-store-openai-chatgpt-sam-altman-department-war/
[6] AWS says drones hit two of its datacenters in UAE - The Register: https://www.theregister.com/2026/03/02/amazon_outages_middle_east/
[7] Claude Goes Down Globally as AWS Data Centers Burn - Awesome Agents: https://awesomeagents.ai/news/claude-outage-march-2026-aws-middle-east/
[8] Claude Status Page: https://status.claude.com/
[9] Why Is Claude Not Working? - Techloy: https://www.techloy.com/why-is-claude-not-working-everything-we-know-about-the-anthropic-outage/
[10] AWS Global Infrastructure: https://aws.amazon.com/about-aws/global-infrastructure/regions_az/
 发表于 2026-3-4 10:15:31
|
查看: 258|
回复: 0
发表于 2026-3-4 10:15:31
|
查看: 258|
回复: 0
