
论文题目:Deep active optimization for complex systems
论文链接:https://www.nature.com/articles/s43588-025-00858-x
发表时间:2025年8月25日
论文来源:nature computational science
为什么高维、有限数据的优化问题如此困难?
从有限数据中推导最优解,是科学发现与工程设计中的核心目标。在材料科学、生命科学和复杂工程系统中,研究者往往需要在极高维参数空间中寻找最优方案,而每一次性能评估都依赖昂贵实验或高精度仿真。人工智能因此被寄予厚望,期望通过更智能的试验选择策略显著降低试错成本,加速科学发现进程。
然而,现有优化方法在高维、数据稀缺场景下普遍受限。多数经典算法依赖大规模数据或对目标函数作出较强的连续性与平滑性假设,在真实复杂系统中难以成立。贝叶斯优化(Bayesian Optimization, BO)虽适用于黑箱问题,但其有效性通常局限于低维空间;基于蒙特卡洛树搜索(MCTS)或强化学习的方法则依赖累积奖励结构和大量交互数据,难以处理非累积目标和高成本评估问题。与此同时,传统代理模型在高维非线性条件下要么依赖强先验、要么易发生过拟合,进一步制约了优化性能。
一种面向有限数据的高维优化新框架:DANTE
针对有限数据、非累积目标条件下的高维复杂优化问题,研究提出了“深度主动优化结合神经代理引导树探索(DANTE)”算法。该方法并非试图精确重建目标函数,而是以“如何更高效地分配有限试错资源”为核心出发点,构建了一套数据驱动的闭环优化框架。
整体流程以深度神经网络(Deep Neural Network, DNN)作为代理模型,学习输入参数与目标性能之间的复杂映射关系;在此基础上,通过神经代理引导树探索(Neural-surrogate-guided Tree Exploration, NTE)策略,对高维搜索空间进行结构化探索;利用数据驱动的上置信界(Data-driven Upper Confidence Bound, DUCB)机制平衡探索与利用;最终将筛选出的高价值候选样本送入真实验证源(如实验、第一性原理计算或高精度仿真)进行评估,并将新获得的标注数据反馈至数据库,更新代理模型,形成持续迭代的优化循环。
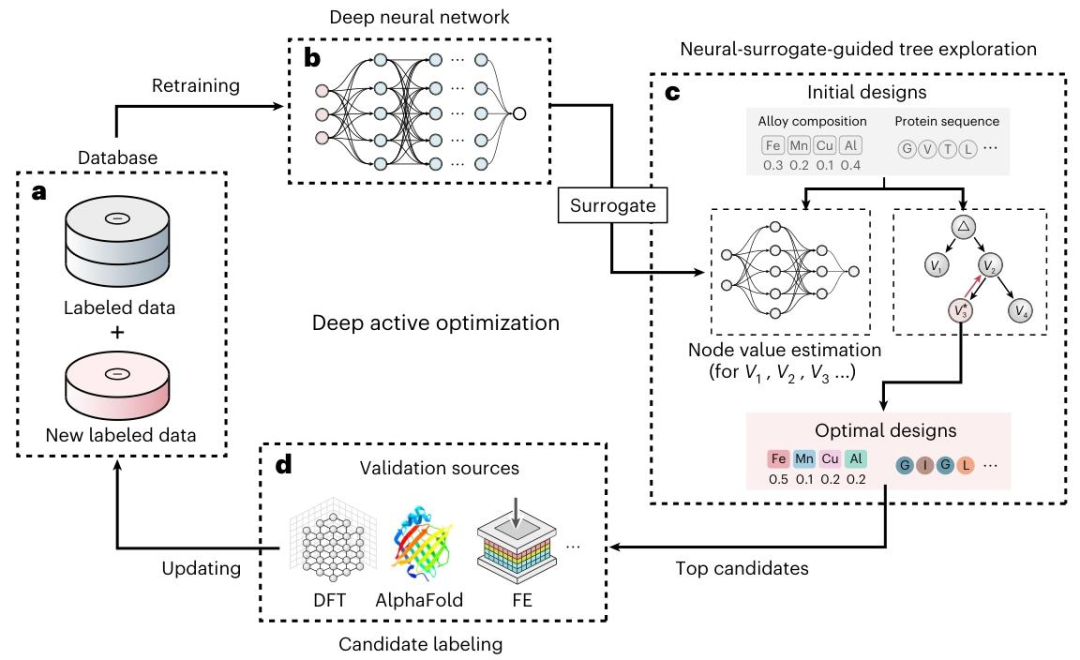
图1 整体框架示意:该图展示了 DANTE 的闭环优化流程:数据库中的初始样本用于训练深度代理模型;代理模型引导树搜索模块在参数空间中生成候选解;真实验证源对候选解进行评估;新数据回流至数据库并更新模型。该流程强调“模型—搜索—验证”的协同演化,是典型的主动优化(Active Optimization)框架。
值得注意的是,DANTE 在方法设计上突破了现有优化算法的维度限制。实验结果表明,该算法能够稳定处理高达 2000 维的优化问题,而多数主流方法的有效维度通常受限于 100 维左右。同时,DANTE 在样本利用效率上具有显著优势,能够在有限数据条件下持续逼近甚至达到全局最优解。
DANTE 如何在高维空间中避免“走错路”?
DANTE 的方法创新集中体现在神经代理引导树探索(NTE)模块及其配套机制上,这些设计均针对高维、有限数据场景下的核心难题进行优化。首先,算法引入条件选择机制与局部反向传播机制,以解决传统树搜索中常见的“价值衰减问题”和局部最优陷阱。条件选择通过比较根节点与子节点的潜在价值,避免搜索过程在低价值区域盲目扩展;局部反向传播则仅在有限范围内更新访问信息,减弱早期错误判断对后续搜索路径的长期约束。
其次,研究将传统上置信界(UCB)推广为数据驱动的 DUCB,将深度神经网络的节点价值预测直接纳入置信界计算中。这一改进有效避免了高维场景下 UCB 因访问次数为零而产生的无穷值问题,同时显著降低了对大量随机模拟的依赖,从而减少计算成本。进一步地,算法引入自适应探索机制,在发现高价值数据点时主动增强探索强度,实现探索与利用之间的动态平衡。
此外,DANTE 还提出了顶级访问采样策略,在候选样本选择阶段综合考虑模型预测性能与节点访问频率,从而提升代理模型在后续迭代中的泛化能力。在代理模型选择上,深度神经网络被证明是 DANTE 成功的关键因素之一。相比高斯过程、决策树等传统模型,DNN 更擅长拟合高维非线性分布,能够捕捉复杂系统中的隐含结构关系。
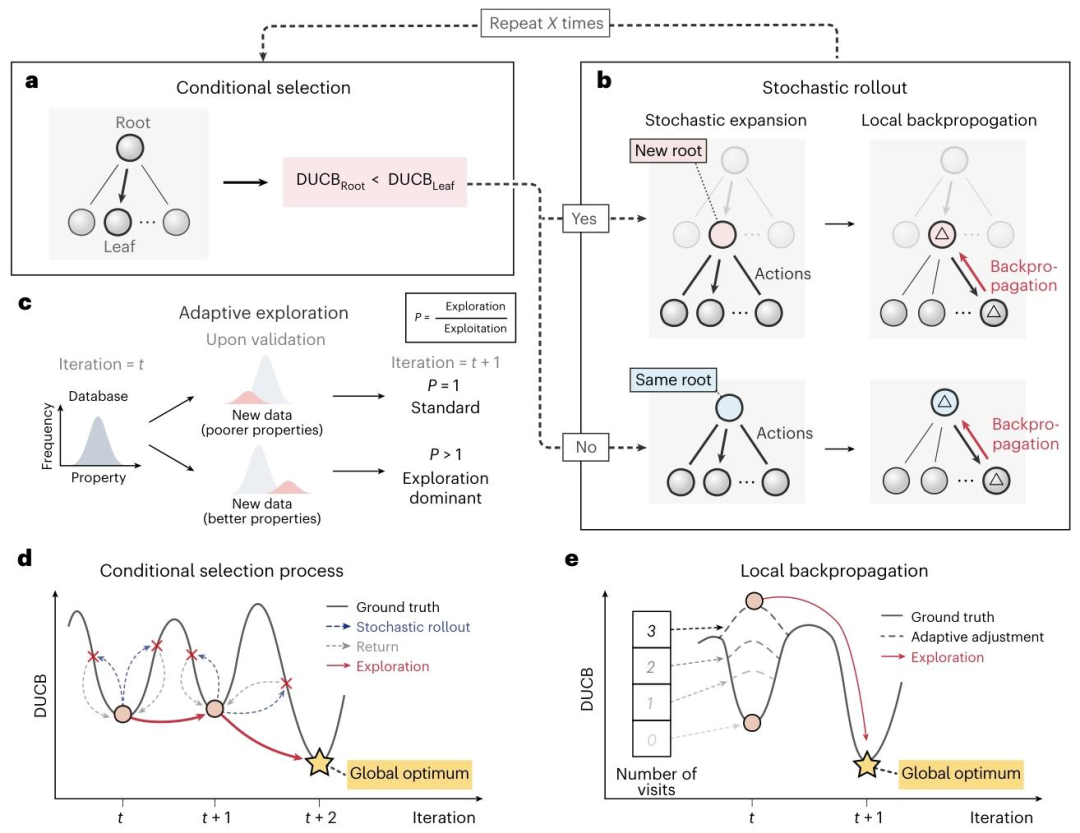
图2 神经代理引导树探索(NTE)机制示意:深度神经网络为搜索节点提供潜在价值评估,数据驱动的上置信界(DUCB)据此调控搜索方向。通过条件选择与局部反向传播机制的协同作用,算法能够避免在高维空间中陷入局部最优,并逐步向全局最优解推进。
从方法论角度看,DANTE 与 BO、MCTS、RL 形成了明确区分:其无需训练策略网络,不依赖累积奖励结构,且在高维、大初始数据集条件下表现出更优的收敛特性。
从数学基准到真实系统:DANTE 的效果如何?
为系统评估 DANTE 的性能,研究从合成函数基准测试和真实世界任务两个层面展开了大规模实验,对比对象涵盖 11 类主流的启发式、贝叶斯及树基优化算法。在合成测试中,研究选取了 20 至 2000 维范围内的 6 类经典非线性非凸函数(包括 Ackley、Rastrigin、Rosenbrock 等)作为验证基准。结果显示,DANTE 在 80%–100% 的测试案例中,以极少样本成功达到全局最优,而多数对比算法在样本受限条件下无法收敛至全局最优。
在无噪声、数据易获取的真实任务中,DANTE 被应用于神经网络架构搜索、复杂合金性能优化、月球着陆最优控制以及透射电子显微镜(TEM)图像分辨率优化等跨学科问题。实验结果表明,DANTE 在关键性能指标上普遍优于现有方法 10%–20%,在部分场景中(如 TEM 参数优化)甚至超越了人类专家的经验选择。在与强化学习算法(如 PPO)的对比中,DANTE 在初始阶段表现出明显优势,体现了其对有限数据场景的适配能力。
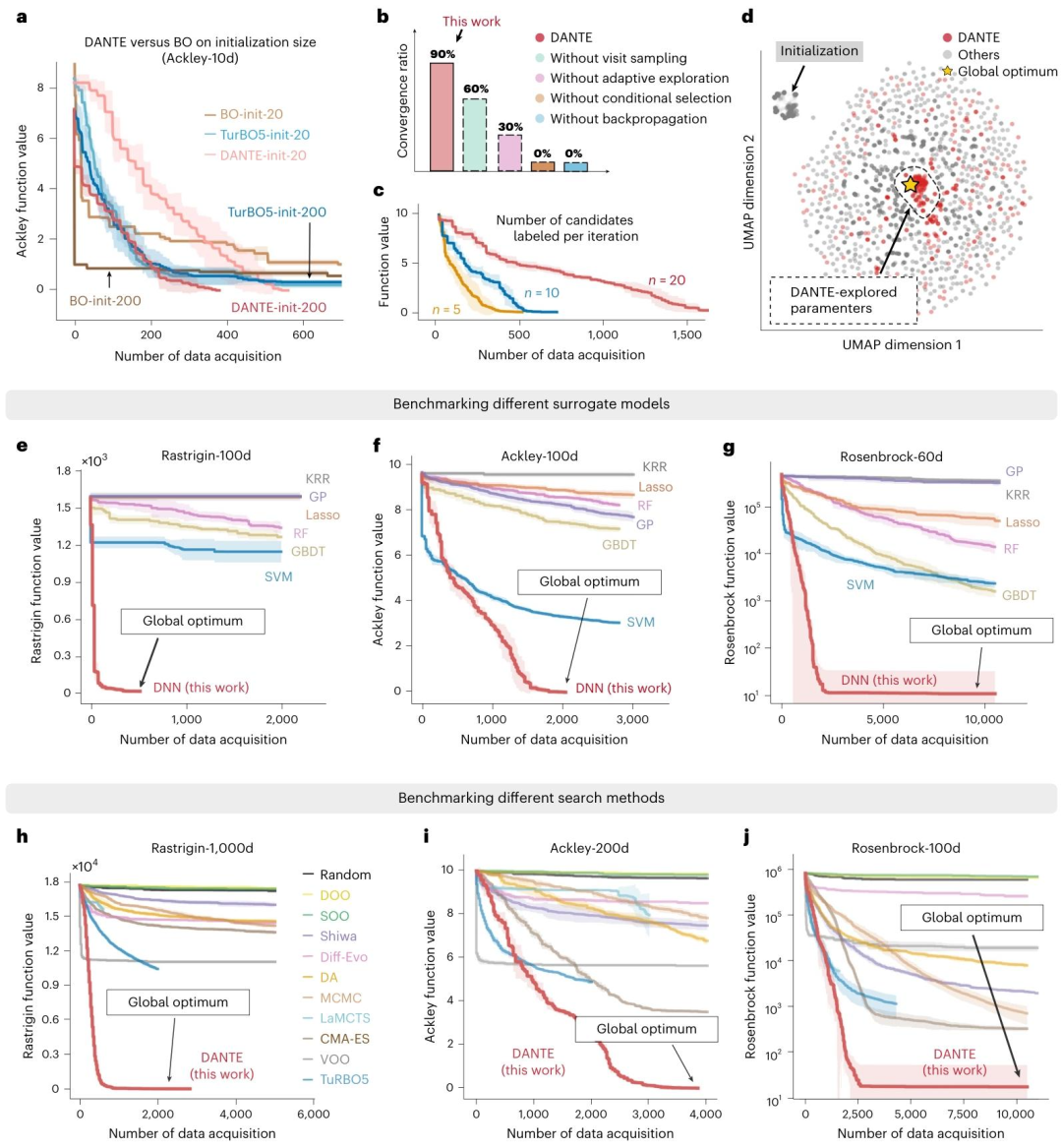
图3 基准测试与真实任务结果:该图系统展示了 DANTE 在高维合成函数和真实科学任务中的收敛行为。相比其他方法,DANTE 在更少样本下更快逼近最优解,验证了其在数据效率与高维适应性方面的优势。
在高成本、高维、带噪声的复杂真实任务中,如结构材料设计、环肽结合体设计以及高维合金输运性能优化,DANTE 在样本数量更少的前提下,实现了 9%–33% 的性能提升,进一步证明了其方法的通用性与稳健性。
从算法到范式:高维优化的新可能
通过系统的理论设计与多维度实验验证,研究表明,深度学习与树搜索机制的有机结合能够有效应对有限数据、高维非线性优化问题。DANTE 的核心优势在于其对高维场景的高度适配性,以及在样本受限条件下稳定收敛的能力,使其成为解决复杂系统优化问题的一种高效工具。
研究同时指出,当前 DANTE 的性能瓶颈主要受限于代理模型的表达能力和计算机内存资源,而非算法框架本身。未来,随着更先进代理模型的引入以及计算资源的提升,DANTE 有望进一步突破 2000 维以上的优化限制。在应用层面,该方法不仅适用于材料科学、物理和计算机科学等基础研究领域,也可扩展至金融优化等多种量化场景。尤其是在与机器人系统和自动化实验平台相结合后,DANTE 有潜力推动自主化实验室的发展,加速材料发现与药物研发等科学过程的智能化进程,成为跨学科高维非线性优化的重要通用方法。
对前沿技术优化与人工智能应用感兴趣?欢迎访问 云栈社区 ,这里汇聚了众多开发者与技术爱好者,共同探讨从算法到工程化的最新实践。
 发表于 2026-3-4 11:15:51
|
查看: 170|
回复: 0
发表于 2026-3-4 11:15:51
|
查看: 170|
回复: 0
