Google 近日正式推出了 Gemini 3.1 Flash-Lite 预览版,距离 2 月份的 Gemini 3.1 Pro 发布仅数月之遥。这款新模型被定位为面向企业级大规模智能处理场景的优化方案,标志着谷歌在其 AI模型 产品线上的分层策略已基本成型。
核心优势:为极速响应而设计
Flash-Lite 最突出的特点无疑是其速度。Google DeepMind 的研究副总裁 Koray Kavukcuoglu 将此归功于背后“令人难以置信的复杂工程”。从官方公布的数据来看,其性能提升非常显著:
- 首 Token 响应时间 比前代产品快 2.5 倍。
- 整体输出速度 提升了 45%,达到 363 tokens/秒。
- 部分第三方测评显示,其实际输出速度甚至能超过 400 tokens/秒。
此外,新模型还引入了“思考级别”功能,允许开发者根据任务复杂度动态调整模型的推理强度。这意味着,对于简单的文本分类或标记任务,可以调低级别以获得最快速度;而对于需要深度分析的复杂代码审查或逻辑推理,则可以调高级别以保证输出质量。
基准测试与性能表现
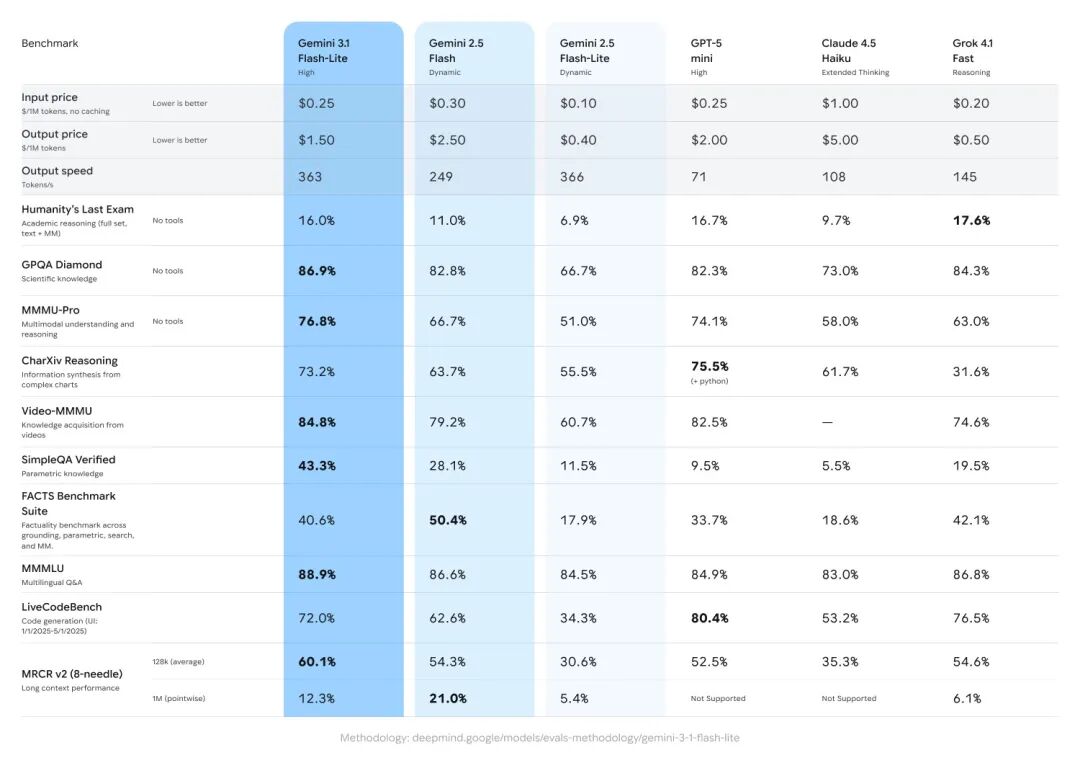
在多项标准基准测试中,Gemini 3.1 Flash-Lite 展现了均衡且强劲的性能。官方数据显示:
- Arena.ai 排行榜 Elo 得分:1432
- 科学知识 (GPQA Diamond):86.9%
- 多模态理解与推理 (MMMU-Pro):76.8%
- 代码生成 (LiveCodeBench):72.0%
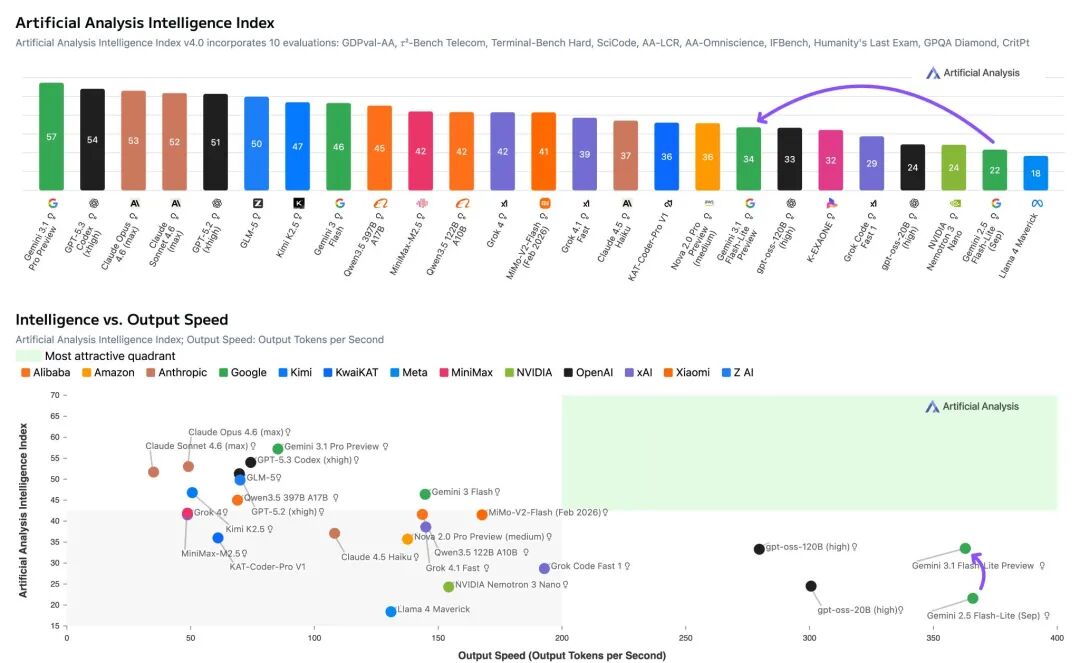
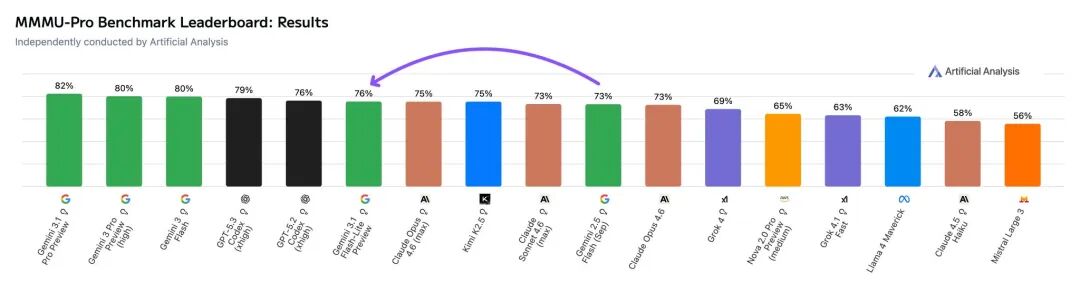
独立第三方机构 Artificial Analysis 的评测结果则提供了另一个视角。在其综合“智能指数”上,Flash-Lite 得分为 34 分,虽优于前代的 22 分,但在同价位模型中处于中等水平。不过,其在多模态推理(MMMU-Pro 76%)等特定项目上表现突出,甚至超过了 Claude Opus 4.6 和 Kimi K2.5 等竞争对手。
清晰的模型分层与市场策略
通过此次发布,谷歌的级联架构策略变得非常清晰。Gemini 3.1 Pro 更像一位“研究员”,在复杂规划、深度逻辑和知识密集型任务上表现卓越(如 ARC-AGI-2 得分 77.1%);而 Gemini 3.1 Flash-Lite 则定位为“高效助手”,专注于处理翻译、内容审核、数据标记等高并发、重复性但要求准确的任务。
这种分层带来了显著的成本差异。在高上下文长度的场景下,使用 Flash-Lite 的成本可比 Pro 版本低 12 至 16 倍。企业可以借此构建更经济的 AI 工作流:用 Pro 进行顶层架构设计和复杂创意,而用 Flash-Lite 来规模化处理日常任务,推动 AI 从昂贵的实验性工具转向可负担的生产力基础设施。
早期试用者的反馈也印证了这一设计的有效性。例如,AI 公司 Latitude 的测试显示,使用 Flash-Lite 后任务成功率提升了 20%,速度加快了 60%;时尚科技公司 Whering 则实现了数据标记任务 100% 的一致性。
定价与开发者社区的多元反应
谷歌为 Flash-Lite 设定的定价是每百万输入 token 0.25 美元,输出 token 1.50 美元。官方称,这相比 Claude 4.5 Haiku(输入 1.00 美元/百万 token,输出 5.00 美元)更具竞争力。
然而,开发者社区的反应却呈现多元化。支持者认为,其极致的速度结合多模态能力,对于需要实时响应的企业应用而言物有所值。但质疑声同样存在,许多开发者指出市场上存在更具价格优势的替代品,例如 Qwen 3 Turbo(输入 0.05 美元,输出 0.20 美元)和 DeepSeek V3.2(输入 0.28 美元,输出 0.42 美元)。
正如一位开发者在论坛上的评论所说:“360 tokens/秒 的速度固然惊人,但真正的瓶颈可能已经变成了人类的阅读速度。” 这反映出社区在惊叹技术指标之余,也在理性审视其实际应用价值与成本效益。
技术规格与挑战
技术规格摘要:
- 上下文窗口:100 万 token
- 输入支持:文本、图像、语音、视频
- 输出格式:仅文本
- 知识截止日期:2025 年 1 月
- 获取方式:Google AI Studio 和 Vertex AI
尽管性能亮眼,Flash-Lite 仍面临典型的市场定位挑战。追求极致性价比的个人开发者或初创公司拥有众多更廉价的选择,而大型组织则可能更看重谷歌提供的企业级技术支持、稳定性和安全保障。有开发者尖锐地指出:“速度是一方面,但在处理长达百万 token 的上下文时,能否保持稳定的性能和准确性,这才是决定用户流程是否会中断的关键。”
结语
Gemini 3.1 Flash-Lite 的发布,标志着谷歌完成了其 AI 模型在“深度”与“广度”上的分层布局。通过 Pro 与 Flash 系列的组合,谷歌押注于下一代竞争将由那些既能深入思考又能大规模高效执行的 AI 系统主导。
然而,市场并非只有一位玩家。面对众多价格更具侵略性的替代方案,Flash-Lite 若想成功,必须将其速度优势与谷歌的整个生态(如 Vertex AI 平台、云服务)形成难以替代的协同效应。最终,是追求极致效率的企业用户,还是关注综合成本的广大开发者,将成为其成功的关键,这需要谷歌进行更精细化的市场运作。至少从当前步伐看,谷歌正坚定不移地推动着 AI 技术的基础设施化进程。
在 云栈社区 的讨论中,技术爱好者们经常就不同 AI 模型的选型与 模型训练 成本展开热议,这种来自实践场景的反馈,对于理解像 Flash-Lite 这类新产品的真实定位颇具参考价值。
 发表于 2026-3-5 03:57:43
|
查看: 141|
回复: 0
发表于 2026-3-5 03:57:43
|
查看: 141|
回复: 0
