
人工智能领域的知名机构Anthropic在其官方博客上发布了这条消息:其顶级模型序列 Claude Opus 4.7 已正式开放使用。如果说之前的版本是得力助手,那么4.7在用户的第一波实测反馈中,更像是一位具备了“职业操守”与严密逻辑的资深专家。
根据早期测评用户和Claude Code项目负责人Boris Cherny的反馈,本次更新有几个核心亮点值得关注。
首先是“自动模式”的成熟。无论是Claude Code的Auto Mode还是网页端的自适应思考机制,Claude都在减少对人类频繁干预的依赖。Boris在社交平台X上分享道,Opus 4.7非常擅长处理复杂且耗时的任务,例如深度研究、代码重构、构建复杂功能,以及反复迭代直至达到性能基准。
其次是多模态能力的无缝融合。给它一张图片作为风格参考,它能据此设计出调性统一的完整网页。第三是审美能力的显著跃迁,多个测评案例显示,其生成的视觉内容在画质精细度与光影效果上有了肉眼可见的提升。

高级软件工程:向“无人值守”演进
现在,在处理高级软件工程任务时,你真的可以把手指从键盘上移开一会儿了。Opus 4.7在这方面的进步令人印象深刻。
- “无人值守”式编程:早期测试者反馈,那些曾经需要全程盯着的复杂代码编写任务,现在完全可以“脱手”交给模型。
- 内置“纠错脑”:4.7版本不再盲目输出代码,它学会了在交付前进行自我验证。这种增强的逻辑严密性,使其在处理长流程任务时异常稳定。
- 更严格的指令遵循:由于4.7的指令遵循能力大幅增强,它会更“死磕”你的字面意思。过去那些模糊的提示词可能需要调整了,因为它不再主动“猜测”你的意图,而是严格执行你的命令。
为了验证这些能力,YouTube博主Bowen进行了一系列测试,涵盖浏览器操作系统、3D游戏、手稿发布网页和《Seinfeld》公寓还原。以下是整理后的测试结果。

测试全程博主未进行任何手动调整或修改,产出质量相当惊艳。尤其是那个名为“PRIZM / OS”的浏览器系统项目,模型生成了超过1700行代码,且实现零Bug。
视觉能力升级:处理更高清的图像
Opus 4.7的视觉处理能力较上一代有了大幅提升,现在支持长边最高达 2,576像素(约375万像素)的高清图像输入。
这意味着它能处理许多此前无法胜任的任务。例如,复杂的图表或密集的手写稿现在可以被清晰识别并处理;密密麻麻的代码截图也能被看得一清二楚。
在博主的一项测试中,要求将一张静态场景图改造成第一人称射击游戏,AI完美地保留了原始地图的所有细节。


此外,得益于更精细的像素处理能力,它在UI设计方面的审美和创造力也更为专业,生成的幻灯片和文档高级感十足。

安全与对齐:为更强大的模型铺路
在上周Anthropic公布“Project Glasswing”计划后,AI的安全性问题再次成为焦点。有趣的是,Anthropic这次反其道而行之:故意削弱了Opus 4.7在某些高风险网络攻击(Cyber)方面的能力。

据官方文档解释,这一举措旨在为即将到来的“核弹级”模型 Mythos 进行铺垫和测试。4.7版本搭载了更新的自动拦截系统,专门用于封杀高风险的黑客攻击请求。当然,如果你是进行安全研究的“红队”成员,可以申请加入官方的 Cyber Verification Program 以获取特殊权限。
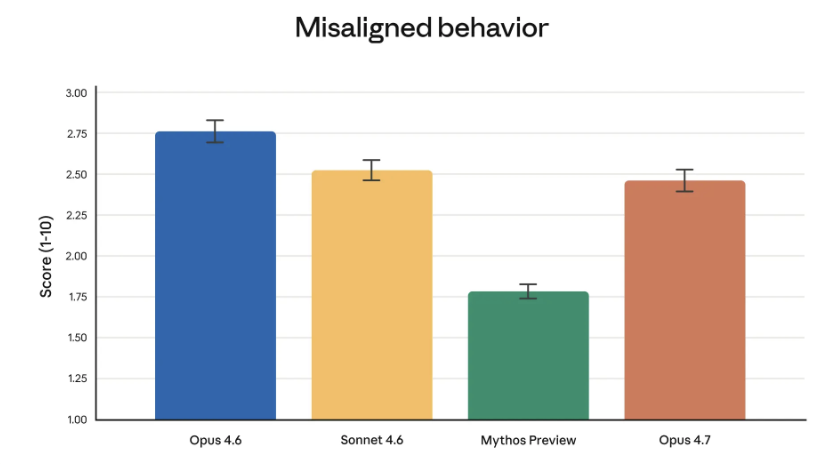
总体而言,Anthropic给出的安全评价是:该模型“总体上一致性良好且值得信赖,但其行为并非完全理想”。在诚实度和抵御“快速注入”攻击等指标上,Opus 4.7优于4.6;但在某些具体场景,如提供管制药物减害建议的详细程度上,4.7略有不足。
生产力工具套件更新
除了模型核心能力,其配套工具也迎来了重要升级:
- 新增 xHigh 努力等级:在原有的“高”和“最大”之间,新增了 Extra High 等级,为用户提供了更精细的思考深度控制选项。
- Claude Code 史诗级更新:
- 新增
\``/ultrareview`` 命令:能够像资深架构师一样进行深入的代码审查。
- Auto Mode 向 Max 用户开放:减少不必要的交互打断,让AI自动决策安全命令的执行。
- 记忆能力增强:模型能更好地利用文件系统来存储和调用记忆,使得跨会话的连续任务不再容易“断片”。
性能基准与市场定位
在多项专业基准测试中,Opus 4.7已经取得了行业领先的分数。虽然Anthropic谦虚地表示 Mythos Preview 在一致性上仍是其训练过的最佳模型,但在金融分析、法律咨询和复杂编码等实际应用领域,Opus 4.7无疑是当前的佼佼者。
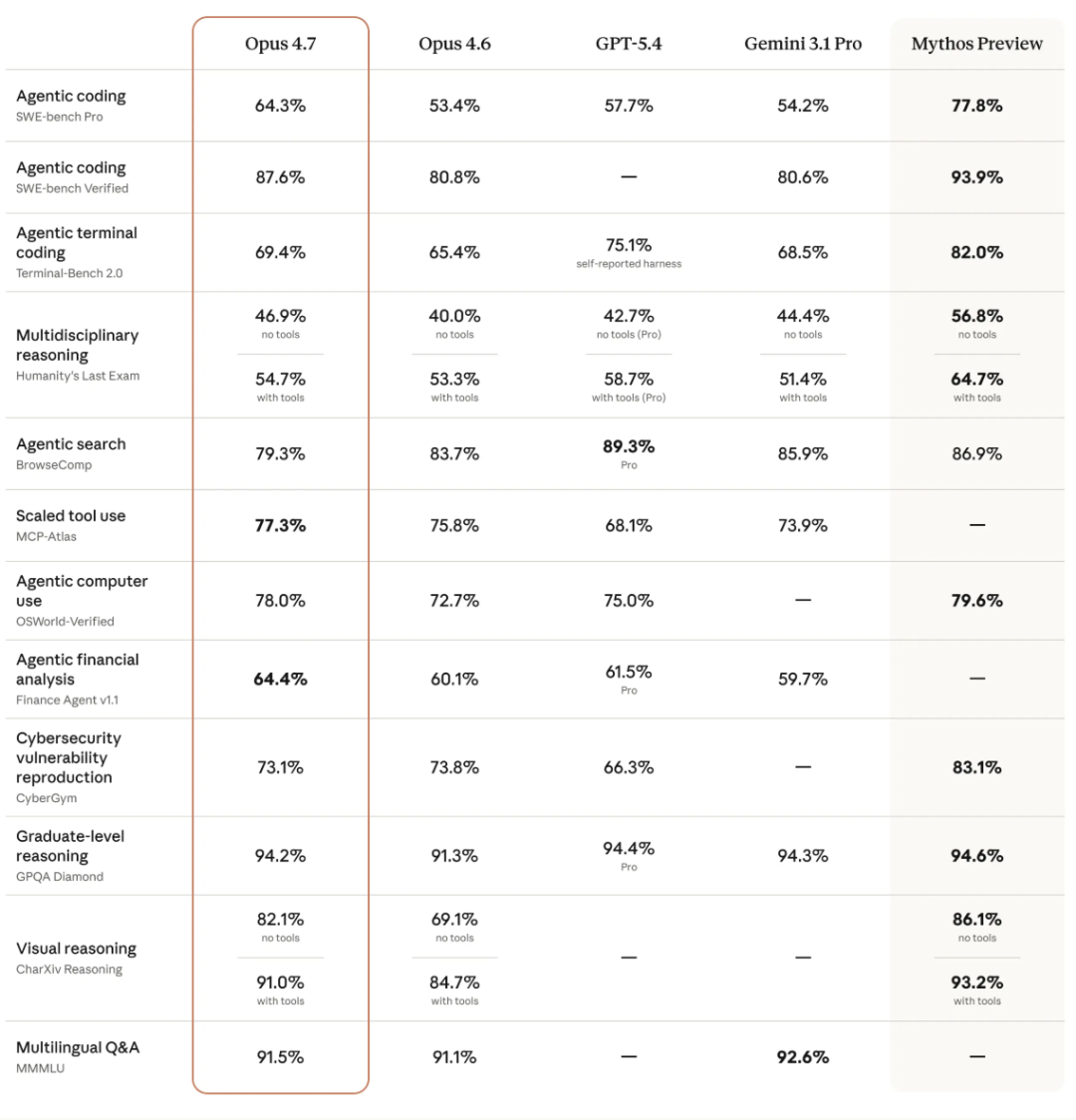
价格方面,Anthropic保持了“加量不加价”的策略:
- 输入:$5 / 百万tokens
- 输出:$25 / 百万tokens
需要注意的是,由于采用了全新的分词器(Tokenizer),同样的文本可能会比以前多消耗10%-35%的Token。但考虑到模型智能和效率的整体提升,这依然是笔划算的交易。
Claude Code 之父的6条实战技巧
Claude Code的创建者Boris Cherny在模型发布后,分享了持续“狗粮测试”Opus 4.7数周的经验。他特别强调了该模型在长时程智能体(Agent)任务中带来的生产力飞跃,并总结了6条实用技巧。
1. 开启自动模式,绕过安全命令的权限提示
Boris指出,过去用户要么在模型执行长任务时全程看守,要么使用 --dangerously-skip-permissions 参数来跳过所有权限检查。而新推出的自动模式是一个更安全的选择。在此模式下,权限请求会先经过一个基于模型的分类器进行安全判断,安全的命令将被自动批准。
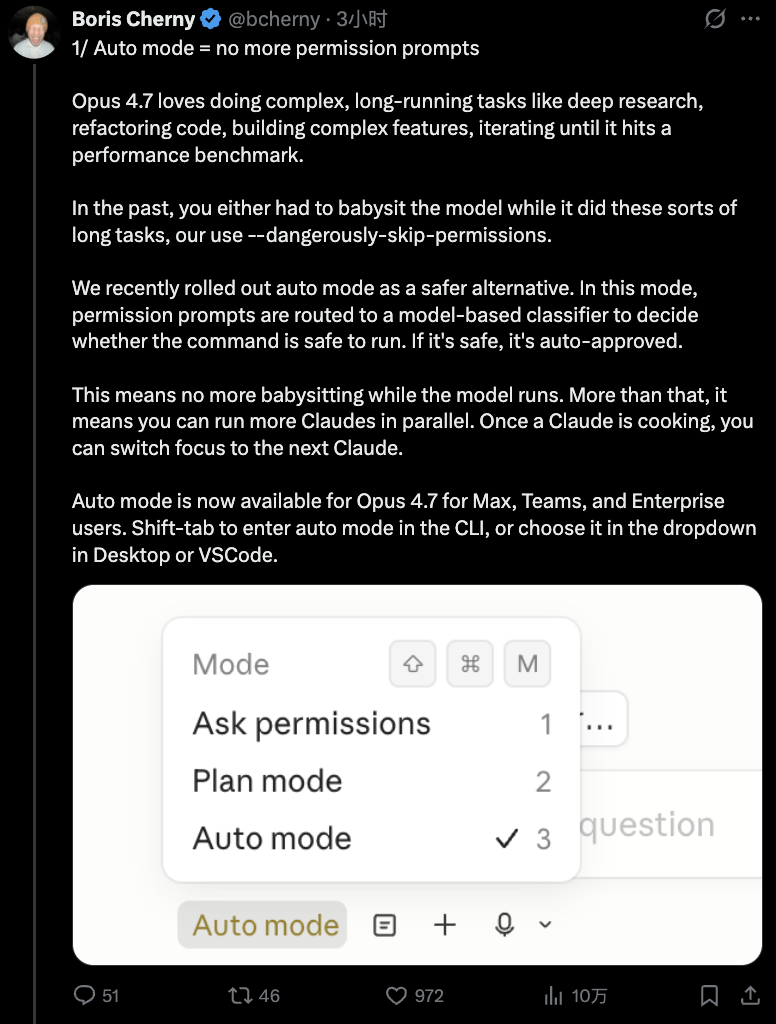
这意味着你不再需要“ babysit ”(看守)运行中的模型。更重要的是,这使并行运行多个Claude实例成为可能。当一个Claude任务启动后,你可以立即将注意力切换到下一个。目前,自动模式仅对Opus 4.7的Max、Teams和企业用户开放。在CLI中按 Shift-tab 进入,或在桌面端、VSCode扩展的下拉菜单中选择。
2. 使用新的 /fewer-permission-prompts 技能
Anthropic同步发布了一个名为 \``/fewer-permission-prompts`` 的新技能。它会扫描你的会话历史,找出那些安全但频繁触发权限提示的常见Bash和MCP命令,然后推荐一个可加入权限白名单的命令列表。
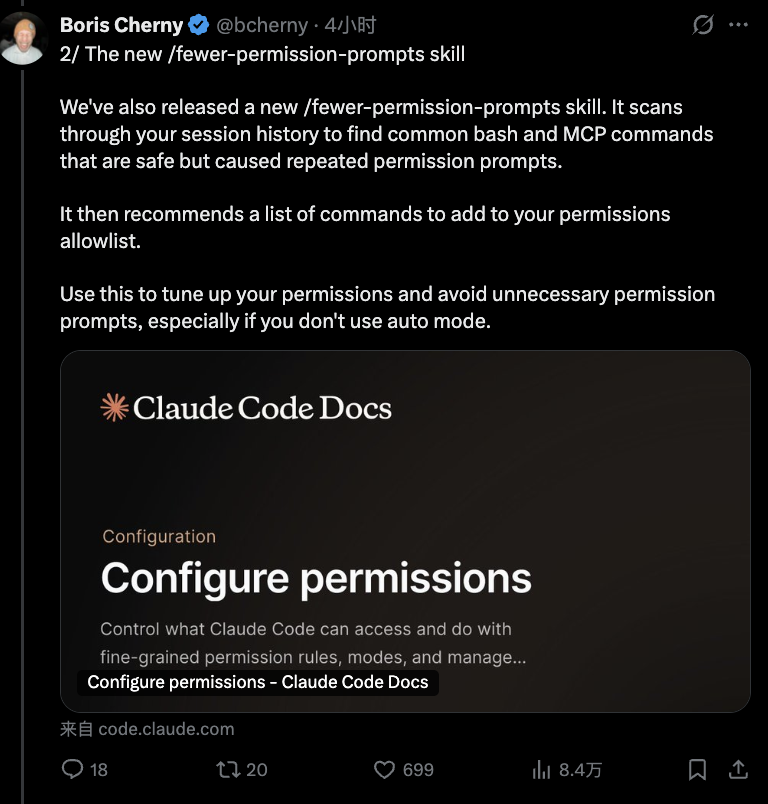
这个技能非常适合那些不使用自动模式的用户,帮助你精细化调整权限设置,避免不必要的打断。
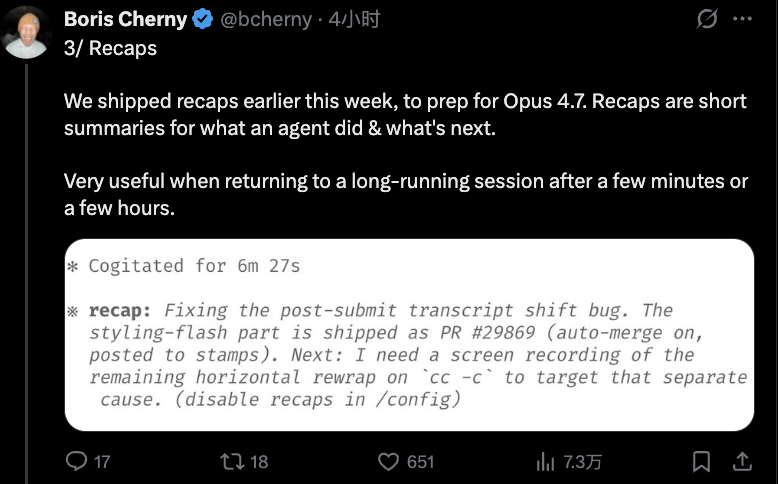
3. 利用进度回顾(Recaps)功能
为了配合Opus 4.7,Claude Code本周早些时候上线了“进度回顾”功能。Recaps是一份简短的摘要,说明智能体已经完成了什么以及接下来的计划。当你离开几分钟或几小时后,重新回到一个长时间运行的会话时,这个功能非常有用。
4. 尝试专注模式(Focus mode)
Boris表示他非常喜欢CLI中新增的“专注模式”。该模式会隐藏所有中间思考和工作过程,只向你呈现最终结果。“模型现在已经进化到了让我产生信任感的阶段:我通常相信它能运行正确的命令并进行正确的修改。我只需看最终产出。” 你可以通过 /focus 命令来切换此模式的开关。

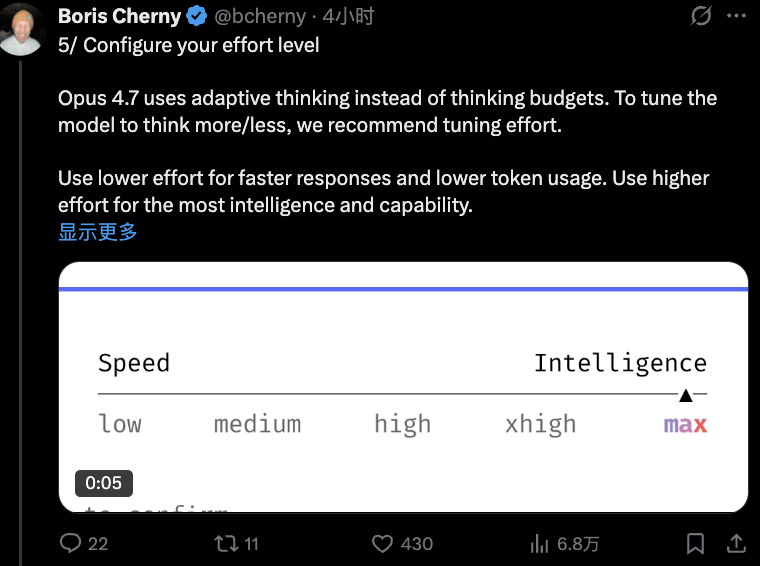
5. 配置你的“努力程度”(Effort level)
Opus 4.7采用了自适应思考机制,而非固定的思考预算。为了调节模型的思考深度,Boris建议通过调整“Effort”参数来实现。调低Effort可以获得更快的响应速度和更低的Token消耗;调高Effort则能激发模型最强的智能和问题解决能力。
6. 赋予Claude自我验证的能力
最后,Boris强调,一定要确保为Claude提供验证其工作成果的途径。他认为这一直是将其效用提升2-3倍的秘诀,在4.7时代这一点更为关键。“对于长耗时工作,验证至关重要。这样当你回到任务中时,你就能确信代码是能正常运行的。”
验证方式因任务类型而异:
- 后端任务:确保Claude知道如何启动你的服务器/服务以进行端到端测试。
- 前端任务:使用Claude Chromium扩展,赋予它控制浏览器进行测试的能力。
- 桌面应用:使用Computer Use(电脑使用)功能。
对此,Boris分享了他的个人提示词技巧:“Claude do blah blah /go”。 其中,\``/go`` 是一个他自定义的组合技能,它会让Claude执行以下三步:
- 使用Bash、浏览器或Computer Use进行端到端自测。
- 运行
\``/simplify``(简化)技能,优化代码或方案。
- 直接提交一个PR(拉取请求)。
结语:长时程Agent时代已至
正如Boris所感叹的,Opus 4.7标志着一个重大的飞跃。从它的特性可以清晰看到,大语言模型(LLM)自身正向更强大、更通用的长时程智能体(Agent) 进化。
对于开发者而言,当务之急是主动调整工作流,充分挖掘这些模型运行时间更长、自主性更高的新特性。是时候逐步舍弃那些需要频繁人工干预的旧有模式,去体验由Claude Opus 4.7这类模型带来的“无人值守式”高效协同了。如果你对人工智能领域的模型应用与实践有更多想法,欢迎在云栈社区与大家交流探讨。
参考链接:
 发表于 2026-4-20 11:14:16
|
查看: 203|
回复: 0
发表于 2026-4-20 11:14:16
|
查看: 203|
回复: 0
