在量化交易、做市系统和风控分析等金融技术场景中,前端应用的响应速度与数据处理能力直接影响着业务决策的效率。如何在海量数据(例如百万级订单或行情记录)上实现实时加载、秒级响应与流畅的交互式分析,是这类系统面临的普遍挑战。
面临的核心挑战
当需要在前端处理日均百万量级的数据时,传统的技术方案往往会陷入两难境地:
- 纯前端内存方案的瓶颈:受限于浏览器的内存上限与 JavaScript 的单线程模型,即便采用虚拟滚动(Virtual Scrolling)技术,当数据量超过十万级别后,全量加载仍会导致内存占用飙升和垃圾回收(GC)卡顿。若在此基础上进行复杂的过滤、排序或聚合计算,UI线程极易被阻塞,导致页面响应迟缓甚至“假死”。即使使用indexedDB,其底层性能在处理百万级数据时依然难以胜任。
- 服务端分页的体验短板:将计算压力完全转移至服务端是常见做法,但在需要快速滑动浏览历史数据、频繁筛选的高频交互场景下,网络往返延迟(RTT)会带来不可避免的“白屏”或加载等待。这种交互不连贯的体验,对于需要快速洞察与决策的用户而言是难以接受的。
因此,我们需要的是一种新的架构,它必须同时满足三大诉求:承载百万级数据吞吐、保持如本地应用般的60FPS流畅交互,并支持强大的实时数据分析功能。
浏览器内的OLAP引擎:DuckDB-Wasm
针对上述痛点,我们借鉴并实现了一套基于 DuckDB-Wasm 与 AG Grid 的高性能前端数据展示与分析方案。其核心思想是 “数据本地化”与 “计算下沉” ,即利用 WebAssembly 技术,在用户的浏览器中直接运行一个高性能的OLAP(联机分析处理)数据库引擎。
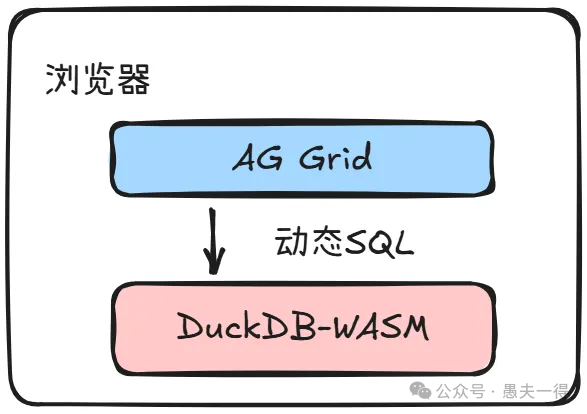
在这个方案中,DuckDB-Wasm 扮演了最关键的角色。它是高性能分析型数据库DuckDB的WebAssembly版本,本质上是将一个完整的、服务器级别的SQL OLAP引擎直接嵌入浏览器中运行。它支持Parquet、CSV等多种格式,并通过 WebAssembly 获得了接近原生的执行性能。
通过它,我们实现了以下效果演示:
- 数据规模:加载了100万条CSV格式的模拟订单数据。
- 加载耗时:约4秒完成数据解析与入库。
- 内存占用:Wasm模块内存稳定在550MB左右。
- 交互体验:无论是快速滚动浏览,还是执行聚合统计(如SUM、AVG),响应均为毫秒级,全程滚动无卡顿。
DuckDB-Wasm 的优势在于:
- 极致性能:采用C++编写的列式存储和向量化执行引擎,处理批量数据的速度通常比原生JavaScript逐行处理快10-100倍。
- 零网络延迟:所有数据查询、过滤、聚合计算均在客户端内存中完成,彻底消除了网络IO等待。
- 完整SQL支持:支持标准的SQL语法,包括复杂的JOIN、窗口函数(Window Functions)、公共表表达式(CTE)等,为前端数据分析提供了强大能力。
- 丝滑体验:用户在表格或图表上的任何交互操作都能得到即时反馈,告别了频繁的“Loading...”状态。
架构设计与实现
在UI层面,我们选用了 AG Grid 的 服务端行模型(Server-Side Row Model, SSRM)。这里需要特别注意,SSRM中的“服务端”是一个逻辑概念。在我们的架构里,本地浏览器中的DuckDB-Wasm实例就充当了这个“服务器”的角色。
整个数据流可以理解为一个高效的“翻译”层:
- 视图层 (View):用户滚动AG Grid表格,组件计算出当前视口需要显示的数据行范围(例如第200行到第300行)。
- 适配层 (Adapter):拦截AG Grid的数据请求,并将其转换为DuckDB能够理解的SQL查询语句。
- 数据层 (DuckDB):执行SQL语句,仅返回当前视口所需的“数据切片”给AG Grid进行渲染。
第一步:AG Grid发出的数据请求
当用户滚动时,AG Grid会发出一个包含分页、排序、过滤等信息的请求对象 IServerSideGetRowsParams,其核心结构如下:
// 前端AG Grid发出的请求参数
{
"startRow": 200, // 当前视口起始行号
"endRow": 300, // 当前视口结束行号
"sortModel": [], // 排序模型
"filterModel": {} // 过滤模型
}
第二步:关键:将请求“翻译”成SQL(核心逻辑)
我们需要编写一个 QueryBuilder,将上述JSON参数动态拼装成高效的SQL。这是实现高效分页的关键。
import { IServerSideGetRowsParams } from "ag-grid-community";
export class QueryBuilder {
// 主入口:构建完整SQL
public buildQuery(params: IServerSideGetRowsParams): string {
const { request } = params;
// 1. 基础查询语句
const baseQuery = `SELECT * FROM orders`;
// 2. 动态添加WHERE条件(过滤)
const whereSql = this.buildWhere(request.filterModel);
// 3. 动态添加ORDER BY(排序)
const orderBySql = this.buildOrderBy(request.sortModel);
// 4. 动态添加LIMIT/OFFSET(分页)
const limitSql = this.buildLimit(request.startRow, request.endRow);
// 5. 最终拼装
return `
${baseQuery}
${whereSql}
${orderBySql}
${limitSql}
`;
}
// 构建分页子句
private buildLimit(startRow: number, endRow: number): string {
const limit = endRow - startRow; // 需要取多少行
const offset = startRow; // 跳过多少行
return ` LIMIT ${limit} OFFSET ${offset}`;
}
// 构建排序子句(分页必须稳定排序)
private buildOrderBy(sortModel: any[]): string {
if (!sortModel || sortModel.length === 0) {
// 若无排序要求,必须指定一个默认排序列以保证分页稳定
return ` ORDER BY order_id ASC`;
}
const sorts = sortModel.map(s => `${s.colId} ${s.sort}`).join(", ");
return ` ORDER BY ${sorts}`;
}
// 构建过滤子句(根据实际过滤模型实现)
private buildWhere(filterModel: any): string {
// 此处简化,实际需根据AG Grid的过滤模型复杂转换
if (!filterModel) return '';
// ... 转换逻辑
return ` WHERE ...`;
}
}
第三步:生成的最终SQL与执行
假设用户滚动到第200行,并且要求按price降序排列,经过QueryBuilder翻译后,发送给DuckDB执行的SQL将是:
SELECT * FROM orders
ORDER BY price DESC
LIMIT 100 OFFSET 200
LIMIT 100:对应 endRow - startRow,表示获取100行数据。OFFSET 200:对应 startRow,表示跳过前200行。
得益于DuckDB的列式存储和向量化执行引擎,即使面对百万行的源表,这种切片查询的耗时也仅在毫秒甚至微秒级别,从而确保了前端滚动的极致流畅性。
总结
通过将 DuckDB-Wasm 与 AG Grid 深度集成,我们成功在浏览器内部构建了一个微型的 客户端/服务器(C/S)架构。前端不再仅仅是被动展示数据的“终端”,而是具备了强大的本地化数据处理与分析能力。
该方案巧妙地解决了金融、BI等场景下海量数据前端展示中“性能”与“功能”的根本矛盾,实现了百万级数据的秒级加载与丝滑交互。其应用场景不仅限于交易系统,在任何需要在前端进行大规模、交互式数据分析的领域(如在线数据探索、报表平台)都有广阔的用武之地,代表了 前端工程化 与 数据库 技术融合的一个前沿方向。
参考实现:ag-grid-duckdb-datasource
 发表于 2025-12-7 23:04:35
|
查看: 244|
回复: 0
发表于 2025-12-7 23:04:35
|
查看: 244|
回复: 0
