Dubbo 是一款开源的 RPC 框架,其核心工作流程主要围绕三个角色展开:提供者(provider)、消费者(consumer) 和 注册中心(registry)。
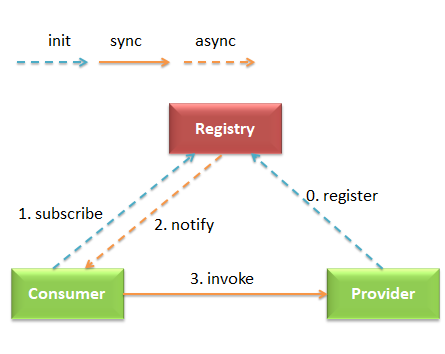
服务提供者启动时会向注册中心注册自己的服务地址,而消费者启动时则去订阅所需的服务,并利用获取到的提供者地址发起远程调用。当提供者的地址发生变更时,注册中心会主动将这一变更推送给相关的消费者。这就是 Dubbo 最基本的工作模式。
在 2.7.5 版本之前,Dubbo 仅支持接口级服务发现模型。从 2.7.5 版本开始,它引入了应用级服务发现作为另一种选择,而在 3.0 及之后的版本中,应用级服务发现更是成为了一个举足轻重的功能。
那么,为什么要引入应用级服务发现?Dubbo 在实现它时遇到了哪些难点?Dubbo 3 又是如何解决这些问题的?在深入探讨之前,让我们先回顾一下 Dubbo 最初的接口级服务发现到底是什么样子的。
接口级服务发现长啥样?
在 Dubbo 的设计中,服务注册与发现的最小粒度是接口,这个信息被抽象为一个 URL,其格式大致如下:
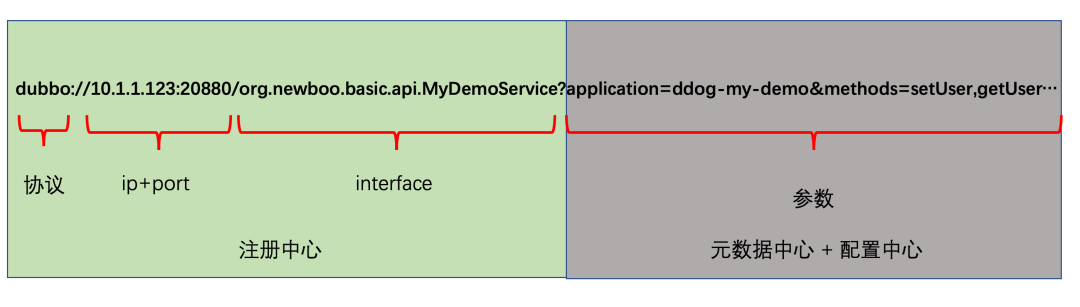
dubbo://10.1.1.123:20880/org.newboo.basic.api.MyDemoService?anyhost=true&application=ddog-my-demo&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.newboo.basic.api.MyDemoService&methods=setUser,getUser&owner=roshilikang&release=2.7.6&side=provider&threads=500
看起来有些复杂?我们来拆解一下它的结构:

- 协议:代表了提供服务的通信协议,例如注册的是 gRPC 服务,这里就会是
grpc://。
- IP 和 Port:指明了是哪台机器的哪个网络端口在对外提供服务。
- Interface:这是注册的接口全限定名,直接对应到代码中需要暴露的服务接口(Interface),例如:
package org.newboo.basic.api;
import org.newboo.basic.model.User;
public interface MyDemoService {
void setUser(User user);
User getUser(String uid);
}
- 参数:包含了服务的各类元数据和配置信息,例如应用名、方法列表、超时时间等。
这里需要稍作说明:一个“接口”(Interface)下可以定义多个方法,对应多个 Dubbo 服务,因此严格来说称为“接口级”服务发现可能不如“服务级”服务发现准确。但为了避免与应用(Application)概念混淆,并且 Dubbo 官方文档也常用此说法,我们沿用“接口级”这一更直观的称谓。
接口级服务发现有什么问题?
数据量过大
随着服务规模增长,接口级服务发现在数据存储和变更通知推送方面都可能遇到瓶颈。数据过多主要体现在两方面:
-
单条注册数据体积庞大
这个问题相对容易解决:拆分存储。
从 Dubbo 2.7 版本开始,它支持了元数据中心和配置中心。注册 URL 中的参数被分类存储:那些持久不变的参数(如应用名、方法列表)存入元数据中心;而可能在运行时动态变化的参数(如超时时间、路由标签)则存入配置中心。
-
注册数据条目数量过多
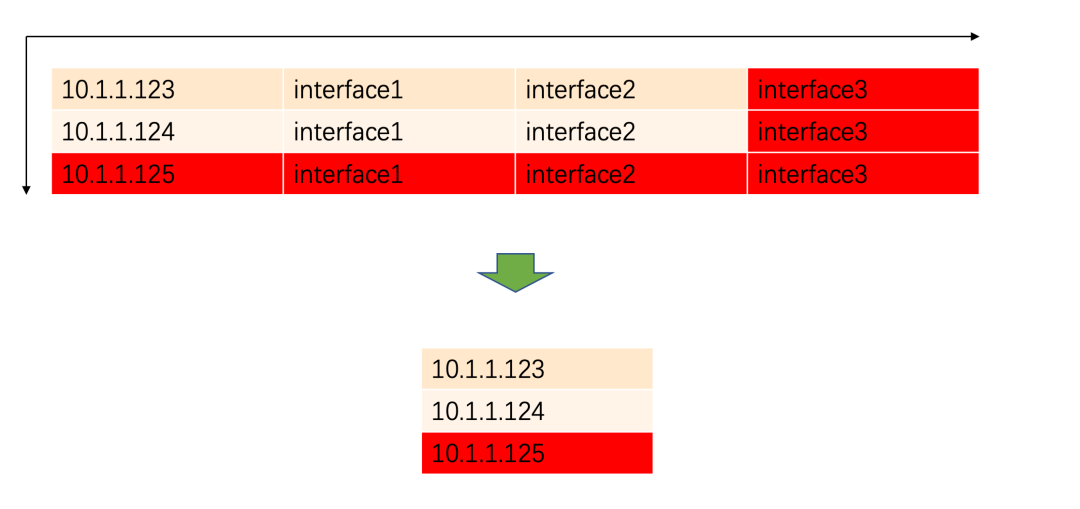
这个问题更为棘手。在接口级模型下,每增加一个服务实例(机器)或一个服务接口,注册中心的条目数量都是线性增长的。

试想一下,如果我们将注册信息中的“接口”信息剥离,只关注“应用”实例(IP:Port),那么数据量将得到显著简化。
与主流生态存在差异
对于长期使用 Dubbo 的开发者来说,接口级服务发现可能习以为常。但从整个微服务与 云原生 生态来看,情况并非如此。
无论是广泛使用的 DNS,还是 Spring Cloud 体系、Kubernetes 服务体系,主流的服务发现模式都是以应用为维度的。只有与这些主流体系对齐,才能更好地实现技术栈间的互通与融合。
据我所知,目前主流 RPC 框架中,仅有 Dubbo、SOFARPC、HSF 这几个同源的框架支持接口级服务发现。
接口级服务发现如何使用?
在接口级模式下,服务提供者(Provider)这样暴露服务:
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:service interface="org.newboo.basic.api.MyDemoService" ref="myNewbooDemoService"/>
服务消费者(Consumer)则这样引用服务:
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:reference id="myNewbooDemoService" interface="org.newboo.basic.api.MyDemoService"/>
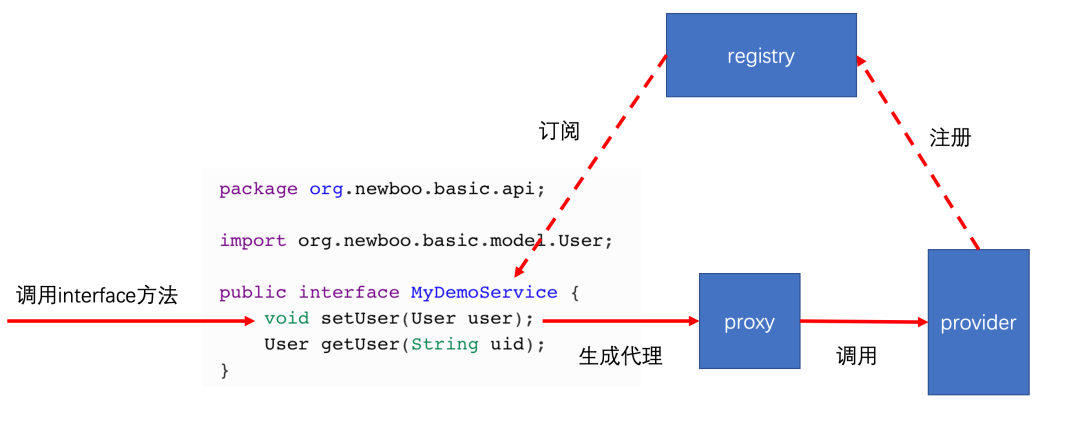
当我们在本地调用远程方法时,只需配置一个 reference,然后直接使用接口进行调用。我们无需自己实现这个接口,Dubbo 会自动为我们生成一个代理对象来处理底层的 RPC 通信。这种设计屏蔽了网络通信的复杂性,带来了 “像调用本地方法一样调用远程方法” 的体验,这也是 Dubbo 框架的一大优势。
从这里我们也能看出 Dubbo 最初设计成接口级服务发现的原因:要为每一个接口生成专属的调用代理,就必须能精准定位到该接口对应的服务提供者地址。采用接口级的注册发现,是实现这一目标最直接的方式。
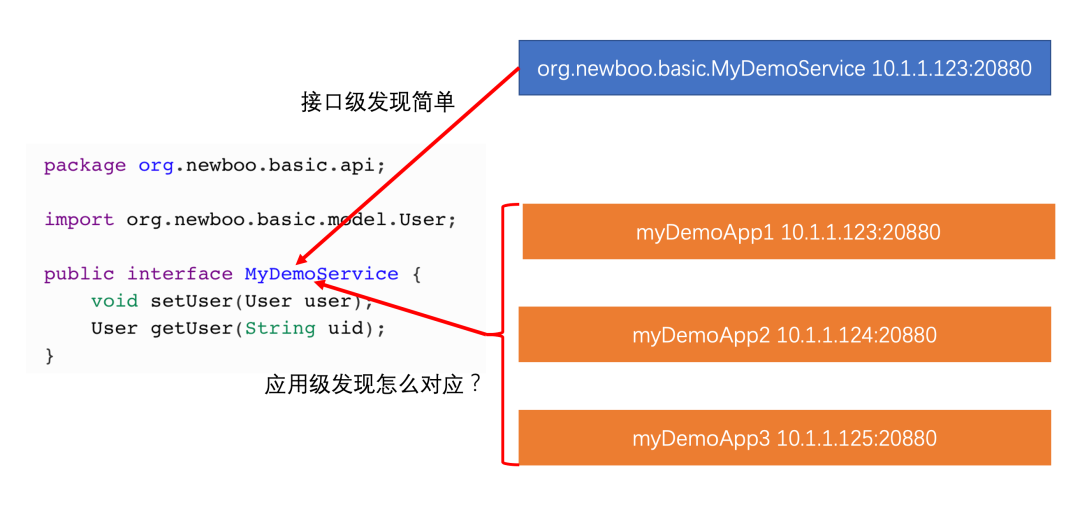
如果要实现应用级服务发现你会怎么做?
如果让我们来设计 Dubbo 的应用级服务发现,注册部分相对明确:服务提供者只需按应用名进行注册即可。
这里隐含了一个前提:应用名必须具有全局唯一性,并且需要被良好地管理。随意修改或重复的应用名都可能导致服务发现链路失效。
难点在于订阅(消费)侧。在保持 Dubbo 现有“面向接口编程”的体验下,我们必须告诉消费者:你想调用的每个接口,具体是部署在哪个应用上的。只有这样,消费者才能通过应用名找到对应的服务实例地址。
实现难点是什么?
为 Dubbo 实现应用级服务发现,主要面临两大挑战:
- 兼容性问题:除了服务发现机制本身,其他部分的改动应尽可能少,并且需要平滑支持从接口级到应用级的迁移与过渡。
- 接口与应用的映射关系:在接口级模式下,调用方无需关心一个接口部署在哪个应用上。但在应用级模式下,这成了必须知道的元信息。如何让开发者几乎无感知地使用,是一个需要巧妙设计的难题。
Dubbo 3 是如何解决这些问题的?
1. 兼容性方案
Dubbo 3 选择保留接口级服务发现机制,并且在默认情况下采用双注册策略(同时向注册中心注册接口级和应用级信息),以确保对老版本的兼容。用户可以通过配置显式指定使用哪种服务发现模型,例如以下配置将启用应用级服务发现:
<dubbo:registry address="zookeeper://127.0.0.1:2181?registry-type=service"/>
这里使用了 service 作为应用级服务发现的关键字,虽然容易与“服务”概念混淆,但这是 Dubbo 3 的官方配置项。
2. 如何查找接口对应的应用
Dubbo 3 提供了两种主要方案来解决映射关系:
-
方案一:手动配置
在服务提供者和消费者的配置中,显式指定接口所属的应用名。这种方式实现简单,架构清晰,但增加了开发者的配置负担。Dubbo 3 已经支持这种模式。
<dubbo:service service="ddog-my-demo-p0" interface="org.newboo.basic.api.MyDemoService" ref="myNewbooDemoService"/>
-
方案二:服务自省(Service Introspection)
这个名词听起来高级,但原理很直观:让 Dubbo 框架自动去发现和匹配。服务提供者在注册时,将“接口名-应用名”的映射关系存储起来(通常放在元数据中心)。消费者在消费接口时,先根据接口名查询到它所属的应用名,再根据应用名去进行服务发现。

这种方案对用户最为友好,使用体验与接口级模式完全一致。但它引入了对元数据中心的依赖,架构变得更复杂一些。此外,如果一个接口被部署在多个不同的应用中,Dubbo 默认的策略是订阅所有这些应用,这在某些特定业务场景下可能需要额外的控制逻辑。
总结
本文从 Dubbo 接口级服务发现的工作原理出发,分析了其面临的数据膨胀和生态融合挑战,进而引出了应用级服务发现的必要性。我们探讨了在 Dubbo 现有架构下实现应用级发现的难点,并详细解读了 Dubbo 3 所提出的双注册、手动配置与服务自省等解决方案。理解这两种模型的差异与演进,对于在 微服务 架构中合理选用和配置 Dubbo 至关重要。希望这篇解析能帮助你在技术选型和架构演进中做出更明智的决策。如果你想深入探讨更多分布式系统与后端架构的实践,欢迎在 云栈社区 交流分享。
 发表于 2026-3-7 04:06:39
|
查看: 157|
回复: 0
发表于 2026-3-7 04:06:39
|
查看: 157|
回复: 0
